一种以站点首页结合动态时间阀值的会话识别方法
2014-05-05朱寿华黄保华
朱寿华,黄保华
(1.广西大学 计算机与电子信息学院,广西 南宁 530004;2.广西中医药大学 信息网络中心,广西 南宁 530001)
0 引言
人们在访问Web站点时,服务器的Web日志文件会自动保留其访问信息,而Web日志挖掘就是通过分析服务器Web日志文件信息,试图发现用户的上网行为模式,了解用户的访问习惯和兴趣,以便能更好地为用户提供个性化服务和构建自适应站点等[1]。Web日志挖掘的过程主要分为三个阶段:数据预处理、模式识别和模式分析[2]。数据预处理阶段会根据不同情况、不同业务,从大量未经处理的原始数据中提取出所需要的信息进行处理。模式识别阶段的主要作用是采用数据挖掘算法对预处理后的数据集合进行挖掘,从而发现用户潜在的访问规律及模式。模式分析阶段会对模式发现阶段所产生的模式和规则进行分析过滤,提取出对用户有用的或者感兴趣的模式和规则,并转化成用户所能接受的知识呈现出来。
笔者首先对目前较为常用的用户会话识别方法进行分析研究,然后在此基础上提出一种新的用户会话识别方法并进行实验。提取一段真实的Web日志信息,在数据预处理过程中采用新的用户会话识别方法进行处理,实验证明了新的方法比目前常用的方法更为有效。
1 数据预处理
服务器的Web日志文件是日志挖掘的主要对象。但是由于防火墙、代理服务器、本地缓存的存在,使得Web日志文件中的信息数据通常是冗余的、不完整的、有错误的,这对后续挖掘算法的分析结果产生了直接的影响。还有就是原始数据的数据模型与挖掘算法中所需的数据模型之间有明显的差异,因此需要对原始数据进行提取和转化工作。这时,数据预处理过程就显得尤为重要了。
数据预处理过程包括数据清洗、用户识别、会话识别、路径补充、事务识别5个步骤[3]。数据清洗是把与后续挖掘算法不相关的Web日志信息数据删除掉;用户识别的主要作用是分辨出浏览站点的每个用户;会话识别是分解用户在一定时间段内的访问记录序列,从中得到每个用户相应的会话;路径补充的主要作用是对用户会话进行优化,这样能够对用户的访问请求进行更加客观准确地描述;事务识别是把前面识别出的用户会话进一步实施语义分组,同时生成挖掘算法所需要的事务。
2 会话识别分析
用户会话是指用户从进入站点到离开站点期间所访问的一系列页面序列集合[4]。公式表示为:

在公式1中:UserID——用户标识,SessionID——会话标识,{(Pid1,time1),(Pid2,time2),…,(Pidk,timek),…,(Pidn,timen)}——用户在某一个时间段内的页面访问序列,Pid——Page id访问页面的URL(标识),time——请求页面的时间。(Pid1,time1)——用户在本次会话中的第一个访问页面和访问时间,(Pidn,timen)——用户在本次会话中的最后一个访问页面和访问时间。
2.1 常用的会话识别方法介绍
目前,会话识别的方法主要有两种:一种是基于时间阀值的方法,另一种是基于参引页和站点结构的方法。
2.1.1 基于时间阀值方法
(1)设定页面访问时间阀值β[5]。假设在一个用户访问序列中有任意相邻的两条访问记录(Pidi,timei) 和 (Pidi+1,timei+1)。 只有当满足 timei+1-timei≤β 时,可认定记录(Pidi,timei)和(Pidi+1,timei+1)是在同一个用户会话中。当timei+1-timei>β时,则说明(Pidi,timei)和(Pidi+1,timei+1)不属于同一个用户会话,(Pidi,timei)是前一个会话的末尾一条记录,而(Pidi+1,timei+1)则是新会话的首条记录。业内一般把β取值为10分钟。
(2)设定一次会话持续时间阀值θ[6]。该方法设定用户在站点上的总停留持续时间不得超过时间阀值θ,如果持续时间超过阀值θ,则说明开启了一个新的会话。研究者实验得出θ的值设定为25.5分钟为最佳,但是目前业内一般把30分钟作为θ的缺省值。
2.1.2 基于参引页和站点结构的方法
(1)参引页和访问历史的识别方法。假如一个用户的请求无法从参引页上的URL地址进入,则该请求记录可能不属于当前会话。只有在前面所有访问过的页面中没有出现当前请求的参引页时,就可认定是一个新会话的开启。
(2)最大向前序列法。该方法对会话划分的依据是判断用户的访问行为。人们浏览网站的习惯通常都是向前访问的,一旦用户发生了后退的访问行为,即点击了“返回”按钮。这时则说明当前会话已结束,同时开启了一个新的会话。
2.2 常用的会话识别方法评估
在基于时间阀值的识别方法中,没有对用户个体的差异性进行充分地考虑。方法(1)是识别不出超过30分钟的会话,而且如果存在两个连续时间较短的会话也不能很好地识别出来。方法(2)中,假如用户在浏览网站期间突然有事离开,一段时间(10分钟)后回来继续访问该站点,这种情况其实都是同一个会话,但是该方法会误认为已经开启了一个新会话。
基于参引页和站点结构的方法总体来说太过于机械,不能很真实地模拟出用户的访问行为,对文本信息的考虑有所欠缺,最终降低了会话识别的准确度。
3 改进的会话识别方法
3.1 会话划分思考
要确定出每一个用户会话的关键在于发现两个相邻会话间的分割点。即上一个用户会话的最后访问页面和下一个用户会话的首次访问页面。其实只要能准确识别出新用户会话的首次访问页面,即说明前一个会话的结束。
绝大多数用户在浏览某站点时一般会从该站点的首页进入,用户可以点击IE浏览器收藏夹中的收藏记录,或者直接在地址栏中输入网站的URL访问。通过查看服务器的IIS日志文件信息,判断用户访问的URL是否为网站的首页面。只要用户访问的URL地址是站点首页面,则可认定这是一个新会话的开始。但当用户浏览完毕退出网站时,本次会话结束,但服务器日志并不能判断出用户此刻的行为。而当该用户再次打开首页访问网站时,这标志着上一个会话已经结束,从本条记录开始是一个新的会话。
如果单纯的以首页作为划分标准显然是不够严谨的,没有充分考虑到用户的浏览兴趣和上网习惯,忽略了用户的差异性。因此在以站点首页作为划分标准的基础上,提出一种采用以站点首页结合动态时间阀值的新会话识别方法。
3.2 改进的会话识别方法
本算法先是以打开网站的首页面作为一个新会话开始的标志,再引入一个动态的会话持续时间阀值θ。如果该会话在持续时间θ内出现用户访问URL是首页的记录,则认为用户开启了一个新的会话;否则就采用动态时间阀值的方法来确定用户会话的边界。动态时间阀值的识别算法是,首先定义两个初始的时间阀值θ和β。其中,θ为一个会话的持续时间,在本方法中取值30min;β为相邻两个页面的浏览时间间隔,经研究证明最佳的取值为10min。假如有任意两个相邻的页面访问时间间隔 T1、T2,当 T2-T1>β,可以动态调整θ的值,进行均值处理:
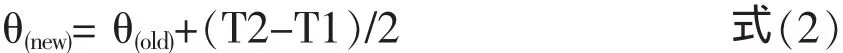
改进的会话识别算法具体步骤如下:
(1)设置初始值 θ=30min,β=10min。把用户访问序列中的第一条访问记录加入第一个会话中,作为第一个会话的首条访问记录;
(2)读取用户访问序列中的下一条访问记录,直到处理完毕序列中所有记录;
(3)判断本条访问记录的URL是否为站点首页。如果是首页,则当前会话结束,并开启一个新会话,同时把本条访问记录加入新的会话访问序列中,然后跳转到步骤(2)。否则,跳转到步骤(4);
(4)把本条访问记录的页面访问时间间隔T(n)加入当前用户会话持续时间θ(new),若θ(new)大于θ,则当前会话结束并开始一个新会话,同时把本条访问记录作为新会话的第一条记录,然后转步骤(2)。 否则,转步骤(5);
(5)计算本条访问记录的页面访问时间间隔T(n)与上一条访问记录时间间隔T(n-1)的差,若T2-T1>β,执行式(2)动态调整θ的值。把本次访问记录加入当前用户会话,并跳转到步骤(2)继续处理下一条记录。
4 实验与结果分析
实验采用某网站(http://www.gxtcmu.edu.cn/)的日志数据,由于数据量比较大,本实验只选取了2013年7月13日的数据,经过数据清理后共有12 042条有效的访问记录存入SQL中,如图1所示。
图1 经过数据清理后的Web日志记录
下面用4种会话识别方法进行实验分析:
方法1:页面访问时间阀值法,时间阀值β取10min。
方法2:会话持续时间阀值法,时间阀值θ取30min。
方法3:基于访问站点的首页方法。
方法4:以站点首页结合动态时间阀值的新会话识别方法。
由于真实的用户会话很难得到,在识别出每种方法的实验会话后,再通过手工检测出真实的会话,实验结果如下表1。
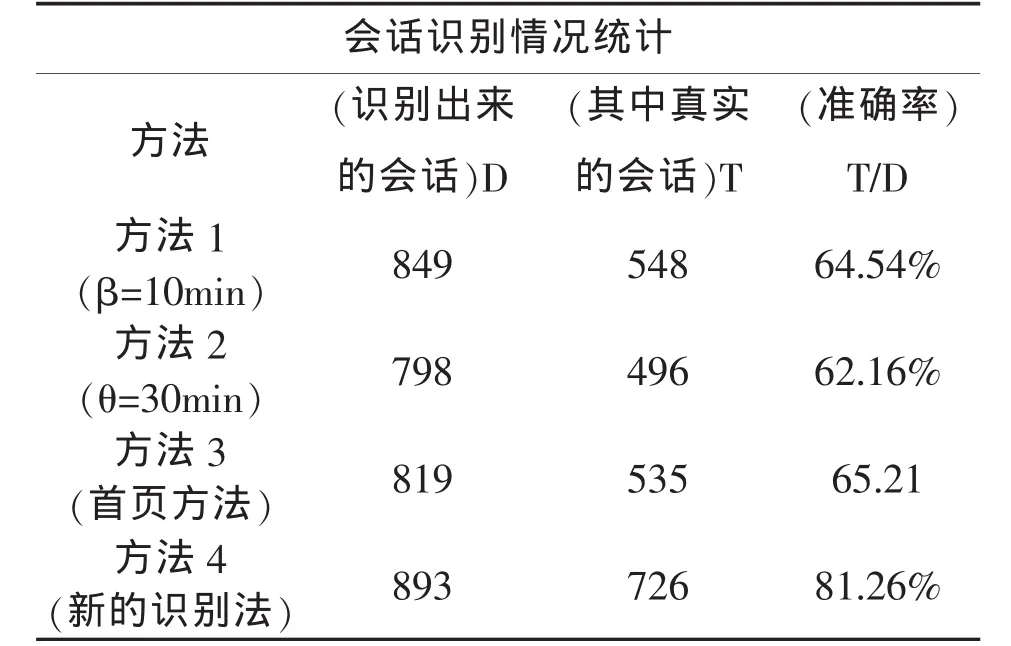
表1 实验结果
5 结语
在数据预处理中,用户会话识别是较为重要的环节。本文对Web日志挖掘数据预处理阶段的会话识别方法进行了探索,在现有方法的基础上提出一种采用站点首页结合动态时间阀值的新会话识别方法。实验表明,新的会话识别方法能够识别出更多的真实用户会话,且有效地提高了会话识别的准确率。
[1]赵全明,朱启莹.Web数据挖掘技术浅析[J].信息产业,2012:108.
[2]王听忠,王辉,武新梅,等.基于协同推荐的Web日志预处理过程[J].微计算机信息,2006(22):150-151.
[3]Wang Chao,Lu Jie,Zhang Guangquan.Mining key information of web pages:A method and its application[J].Expert Systems with Applications,2007(33):425-433.
[4]Facca F M,Lanzi P L.Mining interesting knowledge from Webblogs:a Survey[J].Data and Knowledge Engineering,2005,53(3):225-241.
[5]Spiliopoulou M,Mobasher B,Berendt B.A framework for the evaluation of session reconstruction heuristics in web usage analysis[J].Informs Journal of Computing,2003,15(2):171-179.
[6]Bayir M,Toroslu I,Cosar A.A new approach for reactive web usage data processing[C]//Proceedings of the 22nd International Conference on Data Engineering Eorkshops,Atlanta,Georgia,USA,2006:44.
