脏话文本语料库建设
2014-04-03朱晓旭钱培德
朱晓旭 钱培德
ZHU Xiaoxu, QIAN Peide
苏州大学 计算机科学与技术学院,江苏 苏州 215006
School of Computer Science & Technology, Soochow University,Suzhou, Jiangsu 215006, China
1 引言
随着Web2.0的发展深入,论坛、博客和微博等发布与交互平台的普及,用户从被动接受信息转而可以制造信息,大量的用户参与到网络信息的主动发布中来,信息在以爆炸的速度增长。尤其是以微博为代表的社交网络工具,它们具有简单便捷、互动性和时效性极强的特征[1],对这些用户主动发布的文本进行分析与挖掘具有非常大的实际意义与应用价值。
脏话作为一种非正规的语言现象,在现代社会中已经无处不在[2]。脏话表示了表达者一种愤怒的情感,明显具有侮辱、辱骂、攻击他人的意味,但是脏话往往缺乏逻辑性,而且由于网络很多场合是非实名制的,它也是一种不负责任的贬损,显然这与网络的文明背道而驰。在2012年2月的“方舟子与韩寒的大战”中,大量的粉丝蜂拥到对方的博客中用脏话进行谩骂回复;2012年4月的“甄子丹和赵文卓的争论”中,再次出现了该不文明的现象。因此自动识别用户文本中是否包含脏话句子并进行干预处理是一个非常有实用意义的研究课题。
2 相关工作
目前一些在线游戏、论坛中已经提供了类似脏话检测的功能,主要的手段是通过脏话词典进行机械匹配,通常的步骤是:首先对用户输入文本进行分词,然后对分词结果进行脏话关键词机械匹配,如果匹配到明显的脏话关键词,则禁止该语句的提交,或者将认为的敏感内容替换为星号,图1就是国内某知名游戏平台上对用户的发布文本进行处理后的结果。但是由于查准率和查全率都不是特别高,而且经常误识别,因此会影响用户正常信息的发布,图1中的最后一句话就是一个典型被误识别的例子。

图1 国内某知名游戏平台对用户脏话文本的处理结果例子
脏话识别可以看成是文本情感分析的一个具体的应用。Pang[3]首次将情感分类任务和机器学习相结合,使用了不同的特征,采用 NB(Naive Bayesian)、ME(Maximum Entropy)、和 SVM(Support Vector Machine)三种方法进行了分类,并发现使用 unigram作为分类特征效果最好,同时他们发现在文本情感分析问题上使用“0-1”值作为权重比tf-idf方法要好。Cui[4]的实验证明,当训练语料少时,unigram作用明显,但当训练语料的增多时,bi-gram和 tri-gram以及n-gram(n>3)发挥越来越重要的作用。Ng[5]也通过实验也发现将bi-gram和tri-gram加入unigram项后能够提高SVM的分类性能。
Swapna Somasundaran[6]详细介绍了人工标注情感语料库的注意事项、规范,和对标注者的培训,以及评价标注者之间的标注统一程度的评价方法。Wiebie[7]描述了MPAQ(multiple-perspective QA)语料库的手工标注的详细流程。但是显然纯粹依靠人工来标注语料,耗时耗力,有些不需要深度标注的场合,完全可以采用人工与机器相结合的方法节约成本并提高效率。
3 脏话语料库建设
目前国内外尚无专门用于文本情感分析脏话语料库的报道与文献,本文借助海量的真实评价文本,通过半监督学习的方法,构造了一个高质量的较大规模脏话语料库。
3.1 脏话的定义
按照廖德明的总结[2],脏话可以归纳为如下五类:1)以男性、女性的性器官和性行为为对象的脏话;2)以家庭谱系成员为对象,在辈分上占便宜;3)把对方比拟成动物或者牲口;4)把对方比拟成肮脏物、污秽物或无价值的东西;5)渎神与诅咒。本文认为1)、3)、4)和5)属于显式脏话,而2)属于隐式脏话,这里主要进行显式脏话的处理与分析。
3.2 语料的采集
为了便于研究,本文需要采集大量的脏话文本进行分析。百度贴吧是百度旗下的中文社区,它结合搜索引擎建立了一个在线的交流平台,让那些对同一个话题感兴趣的人们聚集在一起,方便地展开交流和互相帮助[8]。百度贴吧中具有海量的真实人物评价文本语料,其中也包含了大量的脏话。
在对百度贴吧网页数据分析的技术上,本文实现了一个百度贴吧语料自动采集工具。该工具让用户指定一个起始页面,将会自动抓取该贴吧内所有主题的网页数据。在去除一些纯西文的句子、和超长的无意义“水帖”后,以句号、感叹号、问号标点符号和换行符作为分句依据,对文本进行了分句。接着删除长度大于1000的句子,删除不包含中文的句子,替换
、 和等字符串。本文在 “芙蓉姐姐”、“凤姐”、“甄子丹”、“赵文卓”等贴吧中合计采集了1736722句评价文本。
3.3 设计思路
由于自然语言的字词具有歧义性,并且搭配变化多,显然仅仅根据关键字词,难以实现较高质量的脏话识别。在海量文本中提取出脏话文本构造高质量脏话语料库有利于挖掘出脏话的特征。,本文采用半监督学习的思路设计了一个少量人工干预的可迭代的脏话语料采集方法,该方法的具体步骤参见图2。

图2 自动扩展脏话典型特征的结构图
如图2所示,本文首先人工采集了少量的典型脏话特征构成脏话特征库,然后利用一个高精度的脏话分类器对海量的文本集合进行处理,如果脏话分类器的分类值大于一个阈值,则加入到脏话子集,如果分类值为0则加入到非脏话子集,其余的情况放到不确定集合。显然由于一开始脏话特征的数量少,此时分类出的非脏话集合中其实也包括了很多脏话,然后本文利用脏话和非脏话两个集合进行特征筛选,找出部分显著的脏话特征添加到脏话特征库中。然后多次迭代上述过程,随着迭代的进行,脏话集合不断扩大,非脏话集合不断缩小,当脏话集合的规模达到一个合适的大小,就停止迭代。
经过统计与观察,本文发现脏话句子的词性特征和句法特征与普通句子区别不大,因此本文主要是以词组和词组间的二元、三元搭配作为特征进行分析。
3.4 高精度的分类器
按照廖德明的总结的规则[2],在百度贴吧中人工查看并标注网页,合计找到400句脏话。首先用斯坦福分词系统[9]对400句脏话就行分词,然后利用SRILM[10]进行一元统计分析,找到了40个高频的词条。由五位自愿者对这些词条进行了 1-10的权值标记,越高的数字代表是脏话的可能性越大,然后对五位志愿者的标注权值计算平均后取整,得到了每个词条的权值,40个基础特征词以及权值参见表1。
本文设计了一个简单的高精度分类器,设Sentence代表一个句子,Words={w1,w2,…wn}代表一个句子中词组的集合,Features={(fea1,value1),(fea2,value2)…(feam,v aluem)},它是一个二元组集合,代表脏话特征库中的特征以及特征的权值,fvalue(feaj)函数用于获取指定特征feaj的权值。那么判断一个句子是否脏话的算法如下:

当采用表1中的40个典型脏话特征,以20作为阈值时,高精度脏话分类器的准确率为96.29%,查全率为20.47%。

表1 初始脏话特征以及权值
3.5 语料的预处理
为了便于统一处理,本文将待处理的文本全部转换为UTF-8编码。因为日期中经常出现“2”和“日”这样的字符,因此用正则表达式匹配出一个句子中的日期,并替换为空,然后用斯坦福分词系统对1736722句评价文本进行分词。
3.6 特征的选择
使用前述的高精度的分类器,在1736722句评价文本中第一轮找到284句脏话,本文对这些分词后的句子用 SRILM 工具对它们进行一元、二元、三元统计,去除现有特征库中的特征,并删除停用词,然后对统计的结果按照出现频度各取出前5%、%2和%1,接着利用卡方(χ2)检验对这些特征进行计算,对计算结果从大到小排序,将排序后的前50个特征作为候选特征,然后人工对前50个进行筛选与确定权值,合计进行了6轮,每一轮找到的句子数量以及筛选出的特征参见表2。这里使用人工筛选主要基于两个考虑,第一,每次只需要对50个特征筛选,工作量不大,切实可行;第二,人工筛选的准确性非常好,有利于保证语料库是在可靠质量的前提下增长。
卡方(χ2)检验是统计中最为常用的方法之一,它的公式如下所示:

其中 N表示训练集合中脏话与非脏话句子的总数,Cj为具体一个类别,Cj∈{脏话、非脏话}。Featurei表示特定的特征,A表示属于Cj类且包含Featurei的句子频数,B表示不属于 Cj类但是包含 Featurei的句子频数,C表示属于Cj类但是不包含Featurei的句子频数,D表示既不属于 Cj也不包含Featurei的句子频数。
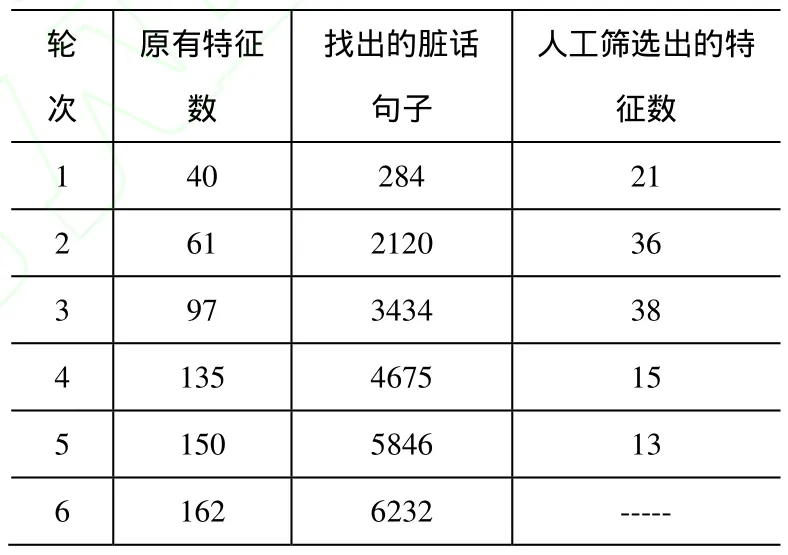
表2 迭代6次的实验过程
4 实验结果以及分析
结合找到的6232句脏话文本,本文从百度百科人物介绍中采集了6656句文本作为非脏话文本集合。首先对文本进行分词,然后进行一元、二元和三元统计,按照频度分别找出前 5%、2%和 1%作为候选特征,计算它们的卡方(χ2)检验值,进行排序,分别取前 200、400、600、800、1000、1500和2000个特征作为分类特征,使用SVM和最大熵分类器分别进行训练后分类,采用了5折交叉测试,并对五折交叉测试的结果取平均,实验结果参见表3。

表3 SVM和最大熵使用不同数量的特征分类结果

通过表3可以看出,随着特征数量的增加,准确性在略微提高,但是查全率也在同步微微降低,而F值稳定在98%以上。在实际应用中可以根据需要在准确率、查全率和计算复杂度和之间寻找一个平衡点。
实验结果显示,利用机器学习的方法进行脏话的自动识别是一种切实可行的方法,在良好语料库支撑的基础上SVM和最大熵方法都能取得很好的效果。
5 结论与进一步工作
本文对网络评价中的脏话进行了介绍与分析,设计了一种半监督的多次迭代的方法从海量文本中找脏话文本和脏话文本的特征,构建了一个高质量的脏话语料库,并利用该语料库进行了脏话文本自动分类试验,取得了很好的效果。如果与具体系统相结合,可以实现论坛、博客和微博发布与回复的脏话过滤。也可以利用脏话识别的结果来辅助分析评价文本的褒贬极性。
[1]袁纳宇. 图书馆应用微博客的价值分析[J]. 图书与情报, 2010,3:104-106.
[2]廖德明. 脏话的性意识指向剖析[J]. 辽东学院学报(社会科学版), 2009,11(4):25-30.
[3]Pang B,Lee L,Vaithyanathan S.Thumbs up?Sentiment classification using machine learning techniques[C]//Proc of the EMNLP 2002. Morristown: ACL, 2002.79-86.
[4]Cui H,Mittal VO,Datar M. Comparative experiments on sentiment classification for online product reviews[C].//Proc.of the AAAI 2006.Menlo Park:AAAI Press,2006.1265-1270.
[5]NgV, Dasgupta S, Arifin SM N. Examining the role of linguistic knowledge sources in the automatic identification and classification of reviews[C]//Proceedings of the COLING/ACLMain Conference Poster Sessions,Morristown,NJ,USA:Association for Computational Linguistics, 2006: 611-618.
[6]Swapna Somasundaran, Janyce Wiebe,等. Manual annotation of opinion categories in meetings[C]//Proceedings of the Workshop on Frontiers in Linguistically Annotated Corpora 2006. Sydney, Australia. Association for Computational Linguistics.
[7]Wiebe J,Wilson T,Cardie C. Annotating expressions of opinions and emotions in language[J]. Language Resources and Evaluation,2005,39(2-3):164-210.
[8]百度百科.贴吧百科名片[OL].[2012-07-15].http://baike.baidu.com/view/2185.htm
[9]Huihsin Tseng, Pichuan Chang, Galen Andrew,Daniel Jurafsky, Christopher Manning. 2005. A Conditional Random Field Word Segmenter for Sighan Bakeoff 2005[C]. //Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, 168-171. Jeju Island,Korea.
[10]Andreas Stolcke. SRILM—an extensible language modeling toolkit[C]//In International Conference on Spoken Language Processing,Denver, Colorado,September 2002.
