基于感知机模型藏文命名实体识别
2014-04-03华却才让姜文斌赵海兴
华却才让 ,姜文斌 ,赵海兴 ,刘 群
HUA Quecairang1,2,JIANG Wenbin3,ZHAO Haixing1,LIU Qun3
1.陕西师范大学 计算机学院,西安 710062
2.青海师范大学 藏文信息研究中心,西宁 810008
3.中国科学院 计算技术研究所,北京 100190
1.Computer Science School of Shaanxi Normal University,Xi’an 710062,China
2.Tibetan Information Research Center,Qinghai Normal University,Xining 810008,China
3.Institute of Computing Technology,Chinese Academy of Sciences,Beijing 100190,China
藏文命名实体识别(Named Entity Recognition,NER)是确定藏文文本中人名、地名、机构名和数词等名词短语的过程。它是藏文分词、机器翻译、跨语言检索和文档摘要等自然语言处理中应用的关键技术,也是目前藏文自然语言处理中亟待解决的问题。藏文作为典型的逻辑格语法体系的复杂拼音文字之一[1],首先句子中最基本的单元为音节(字),一个或多个音节构成词语,词与词之间没有明显标记;其次,具有严格的格词接续规则,部分格词与前一个词存在粘着和形态变化等关系[2],导致与音节的后置字符及又后置字符间存在歧义;第三动词在时态上具有屈折变化。这些复杂性使得藏文分词已成为藏文信息处理中的一个难题[3],而藏文命名实体的识别更为困难,也是必须要解决的问题。
藏文中命名实体类似中文命名实体没有区分标记,其基本单元一个音节类似中文的一个字,没有英文中的大小写特征,它们和非命名实体没有形态上的区别。大部分藏族都有姓,包括古代庄园名、家族名、部落名和地名等,也有寺院和封号名。常见的藏族人名按音节长度有2个(1个词)、3个(1个或2个词)和4个音节(2个词),个别有1个和6个音节,加上姓和封号后甚至有26个音节长度的姓名。而藏文地名、机构名同汉语类似,都有一些开头和结尾特征,但用词特点不同[4]。此外藏文中汉族以及外国人名、地名和机构名均类似汉语中的命名实体。
藏文命名实体识别模块是藏文分词和藏汉翻译系统中不可或缺的组成部分,然而国内外对其研究很少,文献[5]中首次提出了基于规则和HMM模型藏语命名实体识别方案。文献[6]中研究了藏族人名汉译后的识别方法,提取藏族人名用字(串)特征和命名规则,结合词典(3千条)采用串频统计和频率对比策略,以及人名前后一个词为单位共现概率作为可信度的藏族人名识别模型,需给出预先定义的阈值。在新华网藏族频道文本和《人民日报》(2000-01)上实验的召回率分别为85.54%和81.73%。
本文只讨论藏文人名、地名和机构名的识别方法,提出的基于音节的藏文命名实体识别方案,采用基于音节特征训练模型,准确识别藏文人名、地名和机构名,识别综合性能达到86.03%。
1 总体框架
由于藏文句子中词与词之间没有明显的分隔符,使得自动分词中难免存在分词错误,使命名实体开头、结尾音节或词与上下文词语的切分歧义,影响分词基础上识别命名实体的正确率。况且组成词语的音节具有自身的特征,特别是其字母组合上有很多拼写规则和规律,3/4的藏文音节是依据藏文文法规则来拼写的[7]。而音节间关系不仅反映了词的内部结构特征,还反映了词语的接续特征。采用基于音节的藏文命名实体识别方案,即音节识别、再用感知机模型和词典解码获得n-best结果,最后利用知识库获得最佳(权重最大)识别结果。整体数据流程及框架见图1。
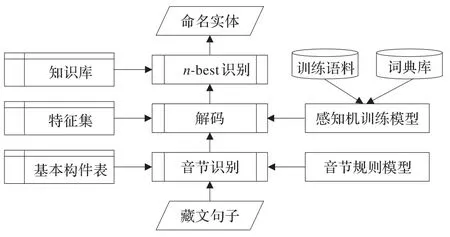
图1 藏文命名实体识别流程图
2 藏文音节及识别
藏语文本中绝大部分音节可由音节分隔符“·”划分,但由于藏语文法中存在的六种紧缩格(),导致这六种格与其前的音节间存在黏着关系,甚至存在紧缩关系。文献[8]提出了藏文紧缩词及还原法,利用藏文紧缩词的添接规则还原分词后的藏文原文。利用组成音节的字根、前置字、后置字等字母构件集和字母拼写规则,识别实际拼写音节,校对音节[8]。本文考虑到有效获取音节间实际上下文特征,只要将黏着紧缩音节划分为两个音节,能准确判断出黏着紧缩关系即可。图2中实际拼写切分为本文采用的方法。

图2 紧缩词还原切分和实际拼写切分比较
本文首先按藏语音节分隔符“·”分隔为准音节,准音节分为紧缩准音节和非紧缩准音节,而紧缩准音节包括三种,分别为直接分隔紧缩准音节、可还原紧缩准音节和歧义紧缩准音节;其中非紧缩准音节(譬如:)可直接划分为一个音节;紧缩准音节可划分为两个音节,其中直接分隔紧缩准音节(譬如:)可直接分隔为一个音节()和可分黏着格();可还原紧缩准音节(譬如)可直接还原为一个还原音节()和一个(还原)黏着格();歧义紧缩准音节()可能为一个音节()和一个黏着格(),或者可能为一个单音节名词(),同时可能存在还原()问题。为获得藏文实际拼写时的上下文音节特征,本文没有按照严格分词方法处理。当用非紧缩音节表1和紧缩词,判断一个音节为紧缩准音节后根据格助词直接分隔即可,譬如:()确定为紧缩关系,则划分为形式,中间加个空格来划分。歧义紧缩准音节根据建立的排歧词表1来划分,当前歧义紧缩准音节与第一个左部或右部出现的音节同时出现在歧义词表时将其直接划分为一个音节,否则划分为两个音节。经测试,在25 MB藏文语料中紧缩词的识别准确率达99.91%。此外,当抽取命名实体词典时对特殊紧缩边界作还原,譬如,“”抽取并还原为“

表1 非紧缩音节和排歧词表
3 命名实体的序列标注规范
在应用机器学习算法之前,首先将语料中标注好的命名实体的单词序列转换成音节标注序列。根据音节与命名实体的关系,将音节标注为13个标注规范中的一个。标注详细信息见表2。比如,可以将词级别人工标注好的命名实体句子(1)转换为命名实体音节序列标注句子(2)。
如果在识别过程中发生歧义,则句子中的某些音节会有多个可能的标注。比如,对于上述句子(1)中的组成人名的每个音节可能存在多个标注(3),下面只给出了前三个词的标注结果:
这和词性标记相似,一个音节的标注会受前面音节的标注影响。比如,当 标注为LR时,则其后面的音节只能被标注为MR或RR;而当 被标注为OW时,其后的音节只能被标注为 OW、LR、LS、LT、NR、NS和NT。同样,同样一个音节的标注也会受该音节周围音节的影响。这与词性标注任务相似,记载特定的上下文中,从多个可能的标注中选择正确的标注。接下来是从1.3万句标注好的训练语料中训练得到感知机在线平均权重训练模型,以对新出现的句子进行自动标注。

表2 标注规范信息
4 模型及特征训练
4.1 模型
感知机方法是利用错误分类对决策权向量进行修正至收敛的方法。基于感知机文本序列标注方法在句法分析[9]中取得了比较好的效果,具有容易定义特征、训练速度快和分类效果好等特性。此方法同样在Unicode编码藏文文本自动分词和词性标注中得到了验证[1]。设输入句子xi∈X,输出标注序列 yi∈Y,X表示训练语料中的所有句子,Y表示对应标注命名实体标记的音节序列。本文采用项目组制订的命名实体音节标注规范见表2,其中藏文音节标注代码包括13个。那么最佳命名实体音节标注序列为:

其中 f(xi,yi)表示输入句子和产生标注序列的特征向量,w表示训练后得到的特征权重。
4.2 特征

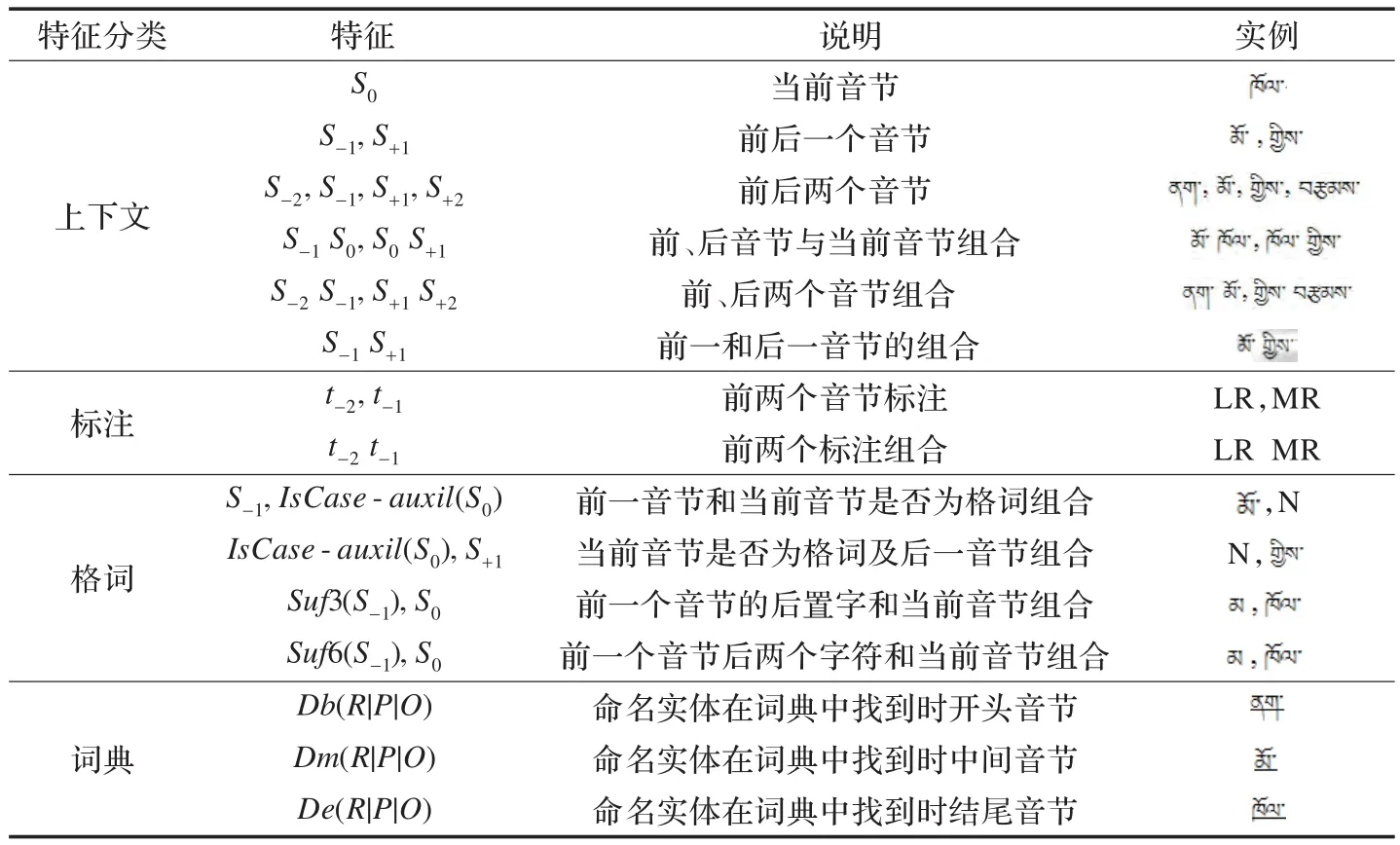
表3 藏文音节特征模板表1)
使用的特征包含了四类上下文信息:(1)音节化上下文。对于句子中的每个音节,只考虑当前音节,前面两个音节和后面两个音节。譬如,人名“中的第一个音节“”的标注可能为OW、LR或RS,但由于它前面两个音节为“和,受这两个音节的影响它被标注为RR。如果其前面为“ ”则被标注为OW。(2)前面出现的标注。这类信息对于预测当前音节的标注是非常有用的。譬如,如果前面的音节被标注为LR,则表示前一个单词是某人名的起始音节,则当前音节是该人名的中间或结束音节,应该被标注为MR或RR。(3)格词接续规则。主格、属格、于格和从格等主要格词类具有固定的接续特征,且与形态动词相关[7]。接续规则与前一个词的最后一个音节的后置字相关,譬如,主格的接续要参照词“的后置字“若符合则当前音节被标注为OW,而表示前一个音节的标记可能为RR、RS或RT。(4)命名实体词典特征。命名实体在相应词典中出现的特征信息类似上下文和标注信息,这类训练权重同样可用来正确标注命名实体的当前音。
4.3 在线训练
本文采用感知机在线的学习权重,并获取平均向量权重的方法[11],该算法具有鲁棒特性,在短语结构句法分析中,该算法拟合训练结果获得了最佳近似拟合效果[12]。在线训练算法中当完成一个单独训练实例的拟合过程后,权重向量w就会更新一次。算法1中Y=为训练集,训练集中每条句对(xi,yi)由句子xi和其正确的序列标注yi的句对构成。
算法1在线平均感知机权重训练算法

利用在线学习算法对感知机模型训练结束后,每个特征及对应的权重将被用来自动标注新出现的句子中的命名实体。
5 解码
感知机模型解码算法是寻找权重最大的音节标注序列,从式(1)可以推导出最大权重音节序列标注生成模型,可以定义为:

其中si为序列标注句子 y中的第i个音节,fk(si)为根据特征模板获得的第k个特征,wk为该特征在训练样本上第m次迭代后得到的平均权重,表示每个特征对命名实体音节类别的贡献,决定命名实体的边界。使用柱搜索算法,按从左到右的顺序标注句子中的每个藏文音节,见算法2。然后可以通过回溯得到最优标注结果以及n-best命名实体音节序列标注结果。
算法2命名实体标注解码算法

算法中chart表示音节标注搜索图,每个顶点Node(POS,POS_1,score,prior)包含四个属性,分别为当前音节属性标记;前驱音节属性标记;从起始顶点至当前顶点的累加分值,以及其前驱顶点序号。s[i]表示当前音节,psbPOSs包含当前藏文音节在训练语料中出现过的标注规范集,preTags包含所有可能的前驱顶点。SORTINSERT(curNode,chart[i])函数完成当前顶点的筛选和前驱的路径的剪枝功能,在实验中直方图剪枝,堆栈空间大小设为20,按递减排序当前堆栈,只保留前20个标注假设,其余标注分值较差的部分将被剪枝;柱搜索剪枝[13]所定义的搜索宽度为2,兼类音节引起存在多条路径到当前节点,而且路径中当前节点的第一个前驱节点和当前节点的标注一致时,则剪枝分值低的路径。通过剪枝降低解码的复杂度后,算法复杂度公式可以简化为:

tag options为标注规范的数量,sentence length为句子中的音节数。当搜索图中形成终点,获取所有可能序列标注路径或标注结果后,可以通过回溯算法生成权重分值最高的音节格式命名实体标注句子。
6 实验和分析
6.1 语料
采用的训练和测试语料来自藏文网站上相关命名实体的各个领域,包括新闻、小说、法律、人物介绍等。语料加工分两步,(1)进行自动分词、词性标注后,经人工修改其中切分和标注错误的命名实体。(2)将完整的词性标注好语料转换为基于藏文音节标注模式语料,见图1。训练语料和测试语料的基本情况见表4。为获取训练语料中的词典特征,项目组整理了2.6万条人名、1.8万条地名和2千条机构名。
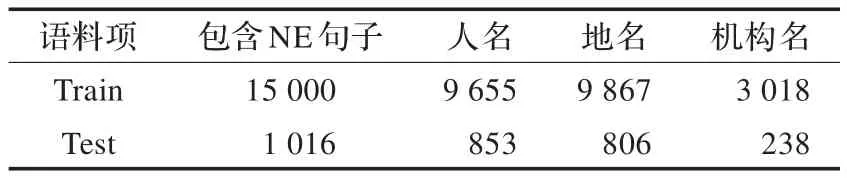
表4 该语料概况
6.2 实验
在本实验中,为比较切分粒度对藏文命名实体的影响,使用基于分词基础上识别藏文命名实体的方法为基线系统,在表4给出的训练和测试集语料上,采用了相同的序列标注规范、特征向量抽取模板、在线感知模型学习和解码算法。藏文命名实体识别的评价指标包括准确率(Precision)、召回率(Recall)和F值(F-Measure)三个指标[14]。各项指标越高说明命名实体的找出能力和判别能力越强。分别基于分词[15]和音节特征感知机藏文命名实体识别性能见表5。

表5 藏文命名实体识别实验结果 (%)
从实验结果可以看出基于音节特征识别NE的F值相对于分词方法高出10.52个百分点,这是因为测试语料中的命名实体对分词系统来说,很多都是未登录词,切分时容易出现未登录词与上下文切分错误,引起命名实体识别错误,比如“意思为“他在成都经营格桑多杰唐卡工艺馆。”,分词结果为本文切分分隔符为空格的音节切分结果为基于音节特征方法中被正确识别的命名实体为而分词方法中只有识别这是错误的,分词时把分为了一个词,导致命名实体识别错误。由于训练语料规模,本文提出的藏文命名实体识别效果比英文(F=93.87%)[4]和中文(F=91.18%)[16]偏低,但是对于一般藏文文本中出现的命名实体的识别依然达到了可以接受的标准。
7 结语
藏文人名、地名和机关名等命名实体的专门识别是一项比较基础,但很重要的工作,可是国内外的相关研究较少。本文根据藏文命名实体的构词规律,以及其基本组成单位音节特征出发,提出了基于藏文音节特征的藏文命名实体识别方法。采用感知机方法训练命名实体标注语料,结合词典和训练模型用动态规划算法获得命名实体标注权重最大的n-best,最终输出最佳命名实体识别结果。藏文命名实体识别综合性能达到86.03%。在现有的研究基础上,将进一步研究扩充知识库,对未能正确识别的命名实体采用知识库指导或统计和规则混合模型识别的方法。
[1]孙萌,刘群.基于判别式分类和重排序技术的藏文分词[C]//第十二届全国少数民族语言文字信息处理学术研讨会论文集,2011.
[2]格桑居冕.实用藏文文法[M].成都:四川民族出版社,1987.
[3]孙萌,华却才让,刘凯,等.藏文数词识别与翻译[J].北京大学学报:自然科学版,2013(1):75-80.
[4]孙镇,王惠临.命名实体识别研究进展综述[J].现代图书情报技术,2010(6):42-47.
[5]金明,杨欢欢,单广荣.藏语命名实体识别研究[J].西北民族大学学报:自然科学版,2010(3):49-52.
[6]罗智勇,宋柔,朱小杰.藏族人名汉译名识别研究[J].情报学报,2009(3):475-480.
[7]珠杰,李天瑞,乔少杰.藏文音节规则模型及应用[J].北京大学学报:自然科学版,2013(1):69-74.
[8]才智杰.藏文自动分词系统中紧缩词的识别[J].中文信息学报,2009(1):35-37.
[9]Collins M.Discriminative training methods for hidden markov models:theory and experiments with perceptron algorithms[C]//Proceedings of the Empirical Methods in Natural Language Processing Conference,Philadelphia,America,2002:1-8.
[10]华却才让,姜文斌,赵海兴,等.基于词对依存分类的藏语树库半自动构建研究[J].中文信息学报,2013,27(5).
[11]McDonald R,Pereira F.Online learning of approximate dependency parsing algorithms[C]//Proceedings of EACL,2006:81-88.
[12]Collins M,Roark B.Incremental parsing with the perceptron algorithm[C]//Proc ACL,2004.
[13]Koehn P.统计机器翻译[M].宗成庆,张霄军,译.北京:电子工业出版社,2012.
[14]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008.
[15]孙萌,华却才让,姜文斌,等.藏文分词及其在藏汉机器翻译中的应用[J].信息技术快报,2013,11(4).
[16]冯元勇,孙乐,李文波,等.基于单字提示特征的中文命名实体识别快速算法[J].中文信息学报,2008(1):104-109.
