面向教育视频资源的垂直搜索引擎设计与实现
2014-04-03魏刃佳吴振强
魏刃佳,吴振强
WEI Renjia, WU Zhenqiang
陕西师范大学 计算机科学学院,陕西 西安 710062
School of Computer Science, Shaanxi Normal University, Shanxi Xi’an 710062, China
1 引言
自 1990年蒙特利尔大学学生 Alan Emtage发明的 Archie,到如今 Google、百度等通用搜索引擎的广泛使用,搜索引擎的价值已越来越高。据艾瑞资讯统计,2012年第一季度中国搜索引擎市场规模已达到54.9亿元,同比上升68.2%[1]。但随着互联网上网页数量的倍增,通用搜索引擎已不能满足用户个性化、专业化的搜索需求,针对其检索结果信息量大、搜索范围过于宽泛、主题相关度低、检索深度不够、信息时效性差等问题,垂直搜索引擎应运而生。
自2000年,国外就开始研究垂直搜索引擎,国内对垂直搜索引擎的研究虽起步较晚,但发展迅速,现有的垂直搜索引擎已涉及图书搜索、职位搜索等方面,但针对网络中海量的教育资源,学习者仍需花费大量的时间在多个网站中搜索所需信息,搜索效率较低。为此,本文顺应教育信息化发展的要求[2],结合我国教育资源利用率低的问题,将垂直搜索引擎与教育资源相结合,以教育视频资源为例,通过对开源软件Heritrix和Lucene进行扩展以及对精品课程资源网的分析[3],提取视频资源名、资源描述以及资源链接,实现了教育视频资源的整合及搜索,使得学习者可以通过视频资源搜索引擎更快地获取所需信息,并将其运用在移动校园系统中,提高教育视频资源利用率。而且,针对Heritrix与Lucene串行组合方案难以实现信息抓取、分析过程与索引过程同时进行的问题,对实现流程进行优化,使网页抓取、网页内容分析筛选和建立索引三个过程同时进行,降低系统IO开销和磁盘空间占用率。
2 基础知识
垂直搜索引擎[4]是针对某个特定领域的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户,向用户提供个性化、专业化的搜索服务,有效地解决了通用搜索引擎存在的检索结果信息量大、主题相关度低、检索深度不够、信息时效性差等弊端。垂直搜索引擎与通用搜索引擎的最大区别在于对网页信息进行结构化信息抽取,即将网页的非结构化数据提取成特定的结构化信息数据,将结构化的数据作为最小单位。在我国,大家所熟知的垂直搜索引擎主要有针对 IT领域的赛迪 IT罗盘(http://itsearch.ccidnet.com),以酷讯为代表的生活搜索引擎,以去哪儿网为代表的旅游搜索引擎等。
我国自从20世纪80年代大力发展教育信息化建设以来,已建立了基础教育资源库、高等教育精品课程资源库等一批优秀的资源共享系统。但由于经济状况、地理位置以及硬件设施的限制,这些共享资源并没有得到很好地应用,造成了教育资源的浪费。而且,面对海量的教学资源,学习者需要花费大量的时间和精力从各个网站上筛选出所需资源,其资源搜索模式如图1所示,学习者在搜索资源时首先需要浏览每个网站的信息,然后进行筛选。由于信息量大而且每个网站都存在很多冗余信息,使得最终搜索到的资源质量也很难保证。如何使学习者在短时间内快速浏览相关信息并且准确定位所需资源已经成为教育资源搜索引擎的研究热点之一。

图1 资源搜索模式
目前我国已存在一些面向教育资源的搜索引擎,比如中国第一教育资源网站Edugo(http://www.edugo.cn/),华南理工大学的木棉搜索引擎(http://search.scut.edu.cn/)。但这些搜索引擎存在搜索内容准确性不高,难以满足用户需求等不足[5]。
3 垂直搜索引擎的设计与实现
移动校园系统主要是为了满足目前人们对移动学习日益增长的需求而设计开发的一个学习资源网站系统。它使得学习者能够利用各种浏览器或者终端设备在任何时间任何地点简单快捷地获得学习资源。
为了提高学习者的搜索效率,本文利用垂直搜索思想,以教育视频资源为例,设计并实现了面向教育视频资源的垂直搜索引擎,对教育视频资源进行整合,学习者只需通过与垂直搜索引擎进行交互,就能实现检索需求,新的资源搜索模式如图2所示,搜索引擎对每个网站的资源进行整理,将与学习者搜索需求相关的链接呈现给学习者,众多的网站相对于学习者来说是透明的,学习者只需要关注搜索引擎提供的资源信息即可,极大地提高了学习者的搜索效率。

图2 新的资源搜索模式
3.1 设计思想
开源网络爬虫框架 Heritrix[6,7,8]将网页抓取过程作为一个独立的模块,其抓取过程为首先从待抓取的URI中选择一个,然后根据URI获得网页信息,对网页信息分析归档后写入磁盘镜像目录,最后再从分析的网页信息中选择符合要求的URI加入到URI等待队列中,递归执行上述操作,直到等待队列中所有URI完成信息的处理。在串行组合情况下,Heritrix完成全部抓取工作后才会对网页内容进行分析,待网页抓取和网页内容分析两个过程均完成之后再调用全文检索引擎框架 Lucene[8]的索引建立功能对所有文档进行索引工作,串行组合流程如图3所示。这样将三个过程完全独立的设计方案虽然增强了各部分的独立性和灵活性,但是文档的IO读写会消耗大量的资源和时间,特别是在抓取海量数据时,文本文档的创建、写入和保存占据了大量的处理时间。
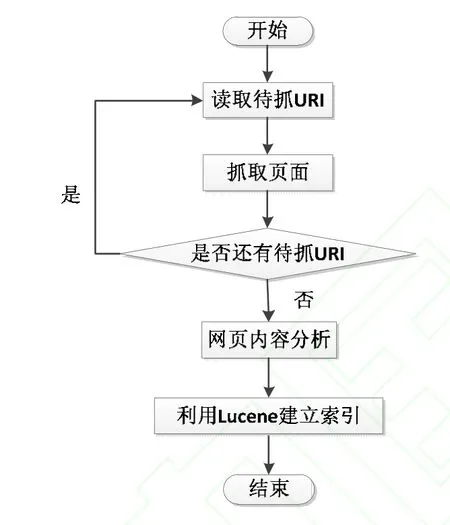
图3 串行组合方案流程图
针对Heritrix抓取结束后再利用Lucene建立索引的串行组合方案存在的问题,本文提出一种流程优化组合方案,将网页抓取、网页内容分析筛选、建立索引三个过程同时进行,实现Heritrix和Lucene的紧耦合,如图4虚线框中所示,即对一个网页完成抓取后,立即对其内容进行提取和筛选,然后将其加入到索引中,最后将建立好的索引文件写入磁盘。此方案降低了系统的IO开销和磁盘空间的占用率。因为 Lucene建立索引的过程在内存中进行,最后仅需要将索引文件写入磁盘中,这样IO资源的开销几乎为零。在通常情况下,能达到较好的抓取和索引效果。紧耦合组合方案流程如图4所示:

图4 紧耦合组合方案流程图
3.2 网页内容分析、筛选和提取过程
3.2.1 判断网页是否需要保存
由于本搜索引擎只需要保存含有视频播放的网页,因此通过对精品课程网的网页进行分析可知,精品课程网站中有两种网页含有视频,一种是资源网页,网址的形式http://resource.jingpinke.com/details?XXXX,另一种是视频网页,网址形式为http://video.jingpinke.com/details? XXXX,问号后面的部分以参数形式代表了这个网页的内容等信息。此处,采用正则表达式表示以上两种形式的网址:

3.2.2 网页内容提取
网页中包含许多与主要内容无关的文本、链接、图片等噪声信息。在进行检索时,这些噪声信息会严重影响检索结果的准确性和检索速度,而且会使索引结构的规模变大。因此,本文通过HTML Parser[9]提取建立索引时所需的信息,舍弃噪声区域,提高搜索的准确性。需要提取的内容项目如表1所示:

表1 提取的网页项目
(1) 视频标题及描述信息的提取
① 标签名为meta;
② 标签含有name属性;
③ 属性值为keywords或description;
前两个条件可以通过构造Node Filter实现:Node Filter filter=new And Filter(new Node Class Filter(Meta Tag.class),new Has Attribute Filter("name"));
在筛选出符合前两条规则的节点后,可以使用循环,通过get Attribute()方法判断属性值是否匹配,如果匹配的话,则将标签的content属性的值取出,从而得到此网页的关键字。
(2) 视频播放链接的提取
网页中 Flash视频的播放通常用
①
② 子标签的 name参数值为flashvars的标签,其value属性的值表示播放视频时需要给播放器的必要参数;
HTTP请求通常通过在 URL后面加问号的方式表示提交的请求的参数,对于flash视频播放器也不例外。因此可以通过“播放器地址+‘?’+播放器参数”的形式通过HTTP访问来播放视频。
这样获得的链接就可以使用一个
3.3 索引建立过程
Lucene[8]建立索引可分为三个步骤:将数据转化为文本,分析,保存至索引。根据3.1的设计思想,本文将索引的建立与页面抓取分析同时进行,首先利用Heritrix对抓取的链接进行分析筛选,然后利用 Lucene建立索引,最后将索引文件存入外存,降低IO读写开销。
Lucene使用IndexWriter类进行索引的写操作,对于每次抓取到的页面,使用IndexWriter对象加入索引,待全部抓取完成之后,关闭 IndexWriter对象。通过分析可知,IndexWriterProcessor继承的 Processor类中有两个未实现功能的方法,因此,可以通过重写这两个方法来实现 IndexWriter的初始化和关闭操作。
Heritrix每次抓取到一个页面之后,都会调用IndexWriterProcessor的innerProcess()方法,在这个方法中实例化一个 Lucene的Document对象,通过 WriteFilterJPK类的getAttribute()方法获得通过页面解析得到的视频内容描述关键字、播放链接信息,将其加入到 Document对象中,然后使用IndexWriter执行addDoc()方法,将这个包含了资源信息的文档对象加入到索引中去。
3.4 实验测试
本文采用的实验环境是WindowsXP操作系统,1G内存,Intel(R) Core(TM)2 CPU 6320 @1.86GHz。设置线程数为20,使原始的Heritrix与改进后的Heritrix在相同的时间内分别在两台配置相同的计算机上同时运行。图 5为原始 Heritrix与改进后的Heritrix在平均抓取速度方面的对比。

图5 平均抓取速度对比图
从图中可以看出,在Heritrix运行过程中嵌入索引建立操作,对运行效率影响不大,能够满足实际需要,达到了预期要求。
3.5 实现效果
Heritrix运行结束以后,在磁盘上生成索引文件,如图6所示,其中segments_*文件描述一组索引的参数,segment.gen存储索引创建参数,fdx是文档域值索引文件,fdt是文档域值存储文件,fnm是索引域描述文件,tis文件存储每个索引在文档中的分布信息,tii文件是tis文件的索引和精简,frq和prx文件均为tis文件的扩展和延伸。然后利用 Lucene建立的索引文件进行检索,得到链接地址,即可播放视频。如图7所示:

图6 索引文件

图7 视频播放效果
3.6 关键算法
由文献[8,10]可知,Heritrix抓取结果的处理过程由 Writer处理器链实现,所有Writer类均继承自 Processor这个抽象类。Processor这个类中最主要的执行处理任务的方法名称为 innerProcess(),因此论文在IndexWriterProcessor类中重写该方法实现提取视频内容、播放链接和建立索引的功能。处理过程的算法描述如下:该算法对待抓取的URI队列uriQueue进行处理,当队列不为空时,弹出队首URI并对其对应的网页文件进行分析、建立索引。


4 结束语
本文针对Heritrix与Lucene串行组合方案存在的问题,通过改进Heritrix的抓取过程,使网页抓取、网页内容分析和建立索引三个过程同时进行,实现Heritrix与Lucene的紧耦合,降低了系统运行的IO开销和磁盘空间的占用率,并且针对我国现存的教育资源利用率较低的问题,设计并实现了面向教育视频资源的垂直搜索引擎,达到了预期的效果。下一步工作将研究网络爬虫的通用性问题。
[1]刘大龙.2012Q1中国搜索引擎市场规模54.9亿市场集中度进一步提高[EB/OL].http://search.iresearch.cn/14/20120426/170800.sht ml.2012-4-26/ 2012-6-20.
[2]中华人民共和国教育部.《教育信息化十年发展规划(2011-2020年)征求意见稿》.2012-01-29.
[3]李开灿,程平,张祖伟.关于精品课程网络资源利用率的统计分析[J].湖北师范学院学报(自然科学版),2010,30(3):11-14.
[4]林伟.垂直搜索引擎关键技术的研究与实现[D].广州:华南理工大学,2011.
[5]邵蕾.基于Lucene的教学资源垂直搜索引擎的研究与实现[D].北京:北京邮电大学,2012.
[6]Heritrix官方网站.http://webarchive.jira.com/wiki/display/Heritrix/Heritrix.
[7]郭艳芬.利用Heritrix构建特定站点爬虫[EB/OL].http://www.ibm.com/devel operworks/cn/ opensource/ os-cn-heritrix/#major2,2010-11-29/2012-3-10.
[8]邱哲,符涛涛,王学松.开发自己的搜索引擎-Lucene+Heritrix[M].北京:人民邮电出版社,2010.
[9]李亮.基于Lucene和Heritrix的职位垂直搜索引擎的设计与实现[D].北京:中国地质大学,2010.
[10]Heritrix源码分析[EB/OL].http://www.docin.com/p-15016 7879.html , 2011-3-16/2012-3-1.
