基于二进制排班算法的血液透析中心管理系统的设计与实施*
2014-03-23张俊杰
许 源,张俊杰,杨 艺,胡 珊,刘 燕
(中山大学中山医学院生物医学工程系,广东 广州 510080)
随着饮食生活习惯和生活环境的变化,我国肾功能损害的患者正逐年增加,有报道称“我国成年人中每10人就有1人患有慢性肾脏病,全国有超过300 万青少年患有慢性肾脏病,每年以13%的速度增长”[1]。在肾功能障碍的治疗中血液透析是一种最为普遍的治疗方式,但由于需要透析的人数多,透析机器种类繁杂,数据统计收集量大,大大地增加了血液透析中心医务工作者的工作强度。依托广州市红十字会医院血液透析中心的医疗环境和合作需求,本文开发出一套能够改善透析中心工作效率,减少医生工作量的网络化前端应用系统。
1 系统设计
1.1 系统需求分析与功能模块规划
广州市红十字会医院血液透析中心固定患者人数约为200余名,该中心每周需进行一次周透析机排班与病人数据统计等事务性工作。由于以往排班均为人工操作,数据均为人工记录,工作量繁重,同时很多临床数据因不便于收集而无法二次利用。因此,新建系统要求包括以下几方面的主要业务需求:
1)可方便地收集病人基本信息以及各类临床透析数据;
2)可录入病人每周的评估信息;
3)对系统管理的所有病人信息可进行查询与统计;
4)根据病人以及透析机的实际情况进行智能排班,并提供打印本周排班情况表;
5)软件可布设于医生工作站以及透析室的管理工作站。
根据血液透析中心信息系统的业务需求,该系统功能模块结构图设计如图1所示,共分为6个功能模块。

图1 血液透析系统功能模块图
1)病人基本信息管理。包括病人基本信息的录入,病人临床信息的录入,病人排班信息录入以及病人信息的增删改查。
2)病人评估信息管理。可以按批次添加病人的评估信息。并在数据图表中进行数据的统计。其中nPcr、Kt/v等数据均由后台算法自动产生。
3)病人透析信息管理。该功能可为病人添加透析记录,医生可在数据字典中调整透析信息录入中的用药信息以及病人状态,如透析液、抗凝剂等,以满足不同医院的需求。同时在管理每次透析记录时能为每次透析记录添加多次监测记录,方便医生护士记录下详细的透析过程。
4)病人数据统计管理。该功能主要是根据各类不同条件搜寻相应的数据后生成统计图表。可根据病人基本信息,病人评估信息,病人透析信息这三类数据的相应字段进行查询,最后以点线图,柱状图或饼图的形式展现出来。该功能模块的目的是辅助医生进行决策,同时通过统计数据的展示帮助病人对自己的病情数据有直观的了解。
5)智能排班管理。该功能模块旨在减少血液透析中心医务工作者大量的手动排班工作,减少不必要的事务性工作,提高工作效率的同时也提高了透析机的利用率与排班准确性。
6)数据字典管理。医生能够自行管理下拉菜单中的提示选项,包括传染疾病、疾病诊断、透析机类型、治疗模式、抗凝模式以及评估批次等。医生可根据科室的实际情况以及需求对这些数据字典进行增删改查,使系统的可重用性更高。
1.2 系统架构设计
综合考虑上述项目背景、系统各项功能需求以及该透析中心的信息化现状,血液透析中心信息系统项目决定搭建一个基于B/S框架的平台,平台的开发技术框架为SSH集成框架,同时整个系统的设计采用基于MVC模式进行设计,其中Struts作为系统的整体基础架构,负责MVC的分离,控制业务跳转,利用Hibernate框架对持久层提供支持,而Spring则作为容器对javaBean进行管理[2]。具体系统架构设计如下:
持久化层:建立数据库、关系表以及视图,然后创建Hibernate配置文件hibernate.cfg.xml,配置连接数据库和所操作实体类对应配置文件信息的参数,利用Myeclipse开发工具集成的Hibernate功能,对数据库进行“反转工程”,生成实体类和实体映射文件*.hbm.xml,使实体类与数据库关系表一一对应。
业务逻辑层:通过JSP页面实现交互界面,负责传送请求(Request)和接收响应(Response),根据Struts配置文件(struts-config.xml),将ActionServlet接收到的Request委派给相应的Action处理。在业务层中,管理服务组件的Spring IoC容器负责向Action提供业务模型(Model)组件以及数据处理(DAO)组件来完成业务逻辑,并提供事务处理、缓冲池等容器组件以提升系统性能和保证数据的完整性。Action处理后返回给Struts配置文件,并由Struts来返回处理结果。
表现层:表现层主要由html页面以及JSP页面组成,html页面主要实现静态展示,JSP页面用于输入数据以及展示由后台返回的数据。同时运用JavaScript,Ajax,以及JQUERY等技术实现一些较为复杂的动态交互功能[3-4]。
2 系统关键技术和实现
本系统采用B/S架构以及MVC的设计模式,使系统的所有业务集中在服务器上运行,以便于开发者的管理和维护,并使系统具有更好的可扩展性和重用性。同时考虑到数据库的安全可靠性,采用SQL Server 2005作为系统后台数据库,java做为后台业务逻辑以及数据处理语言,Jsp页面作为前台显示。开发环境为Myeclipse 9,运行环境为JRE 7,服务器为Apache Tomcat 7,操作系统为Windows 7。
2.1 系统数据库设计
2.1.1 整体数据库结构设计 本系统主要由8张数据表以及8张字典表组成。其中病人信息表(patient)保存病人基本标志性信息,透析表(dialysis)保存病人的透析记录、监测信息表(monitoring)保存病人透析过程中的监测信息、评估表(assess)保存病人治疗状态评估记录等。由于一些数据项的不确定性,例如病人信息表中的诊断(diagnosis)可包含各种类型的诊断,因此设计了8张字典表,可供医生根据实际情况对数据字典进行录入删除,最大程度地保证系统的可重用性。为了保证系统数据库的正常运行,防止垃圾数据生成,本系统设计了一系列触发器以及事务。例如当对病人信息进行删除时,病人删除触发器会删除与该病人相关的评估信息记录、监测信息记录以及透析信息记录等。系统各数据表结构和关系图如图2所示。

图2 系统数据表关系图
2.1.2 排班模块数据表设计 本系统用五张数据表来准确记录所有透析机以及病人的排班工作情况,分别是病人表(patient)、透析机表(dialyser)、病人排班表(patientschedule)、透析机类型表(dialysertype)以及透析机疾病表(dialyserdisease)。病人表中的infection表示该病人携带的传染性疾病,frequence表示该病人周透析频率。透析机表中的disease表示该透析机对应的传染性疾病的类型,schedule表示该透析机当前的排班情况的二进制数,status表示透析机是否排满,若排满则设置为1,有空闲位置则为0。病人排班表中patientid对应病人表中的id,dialyserid对应透析机表中的id,schedule表示某一条透析记录的二进制数。透析机类型表以及透析机疾病表中的type则分别对应透析机表中的机器类型和传染病类型。5张数据表的结构和关系图如图3所示。
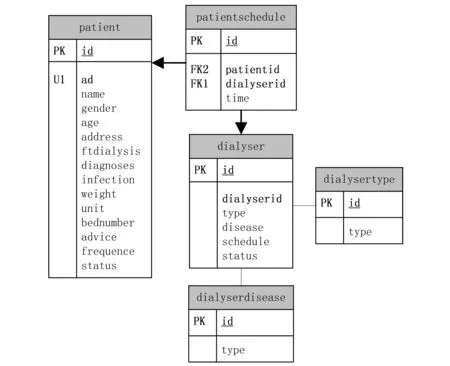
图3 排班模块数据表关系图示
2.2 智能排班算法设计
目前主要的排班算法有模拟退火算法、遗传算法等。遗传算法(genetic algorithm)基于达尔文适者生存、优胜劣汰的进化原则,对包含可能解的群体反复使用遗传学的基本操作,并使用全局并行搜索技术搜索群体中满足要求的最优个体,与其它优化方法相比,遗传算法的主要优点在于它的鲁棒性、全局最优性和广泛适用性。但在实际的使用中,退火算法每次迭代必须进行多次目标函数计算,因而在处理实际资料时计算效率不高[5]。而遗传算法易发生成熟前收敛,对优良个体的选择也不能满足多目标优化的要求[6]。
由于上述算法应用复杂且不易调整,针对所开发系统的复杂度和可灵活调控性的需求,本文设计了一种基于二进制的排班算法,采用此方法可以自动选出最优的排班位置并最大限度地节约透析机的使用。同时该方法相比于采用数组对排班信息进行存储的方式省去了循环判断该透析机排班情况等步骤,因此提高了运算效率以及稳定性[7-10]。
2.2.1 排班二进制数定义 由于各透析中心接收的患者以及各自实际工作情况不同,因此透析排班有以下数种情况:
1)透析中心工作时间分为一周七个工作日或六个工作日的两种形式,每天的透析班次也分为两班或者三班的两种形式,要求允许用户选择。
2)透析患者分为一周透析一次,一周透析两次,以及一周透析三次的三类患者。
3)导致肾功能障碍的疾病有可能存在传染性,因此某类传染病的患者只能排入相对应传染病的机器。
基于上述分析,一台透析机对某类病种患者的最大饱和工作排班是一周7天3班次的满负荷运转[10]。
用一个二进制位表示排班中的一个班次,一台透析机的排班二进制数定义如下:
其中,&符号代表串接二进制位运算符号,bi=1表示已排班,bi=0表示空闲,i=0,1,…,20表示7天工作日3个班次共21位二进制位,则二进制排班算法将一个排班周期中的班次转换为二进制数b20b19…b1b0中相应的位置,例如周一早班的二进制位为b0,周一下午班则为b1,周一晚午班则为b2,依次类推。当一台透析机按一周7天,每天3个班次的频率排班,若该透析机排班二进制数等于221-1221-1,则说明该透析机已经排满;若该透析机排班二进制数为0,则该透析机排班情况为空。
2.2.2 排班算法流程设计 由于周工作时间存在两种形式,日排班存在2班和3班的排班间隔形式,所以透析机进入自动排班前必须根据用户使用需求初始化排班二进制数。该算法约定透析机排班二进制数的初态值按以下规则设置:①当周工作日为7天时周日为空闲,当周工作日为6天时周日为占用;②当一天三班时晚班为空闲,当一天两班时晚班为占用。例如,透析机若选择一天两班和一周六个工作日的工作情况时,其排班二进制数初态设为1984804(111100100100100100100)。
当透析机的排班工作日初始化完成后进入患者排班流程,患者的首次排班可选择对应透析机的任意空闲位置,当患者进行第N(N>=2)次排班时则根据上一次的排班位置加上与其对应的排班间隔。例如第N次排班的位置二进制值为0000000000000000001,若排班间隔为6则第N+1次排班的位置二进制值则是00000000000001000000。对应三类透析患者,周透析频率分为1、2、3。如果一天3班,每周7个工作日,则一共有21班次。当周透析频率为2时,最佳透析间隔为21/2=10.5。当周透析频率为3时最佳透析间隔为21/3=7。同时考虑到透析间隔应有一定的冗余且存在一周六个工作日、一天两班的情况,有四个班次无法排入而导致排班循环陷入死循环的情况,因此在设置排班可用间隔时其范围应至少为4。因此,算法约定患者透析间隔按以下规则设置,①每周透析频率为2时,可选透析间隔为9至13;②每周透析频率为3时,可选透析间隔为5至9。
为保证全体智能排班后能尽可能的冗余不必要的透析机,因此在排班时先对透析频率高的患者进行排班,最后再对每周透析一次的患者进行排班,已达到最大冗余的效果。
综上所述,二进制排班算法描述如下:
1)透析机排班二进制数初始化算法:设排班组合表为(d,n),其中d代表每周工作天数,n代表每天排班数,故而透析机有4种排班组合:(7,3)、(7,2)、(6,3)、(6,2),则对应4种排班组合的排班二进制数初态值设置
2)患者透析间隔设置与透析时间排班算法:设透析间隔为T,患者透析频率为f,则患者透析时间间隔的设置是应用依次探查法在医嘱透析频率对应的排班间隔区间内寻找可排班间隔值,在探查中同时确定透析的时间。

智能选择患者透析时间模块算法流程:

图4 患者透析时间排班算法模块流程图
2.2.3 系统排班功能实施流程图 用户进入排班界面后可选择单人排班或是自动全体排班。
单人排班:用户可选择手动或自动单人排班。手动单人排班中,用户可直接选择可排班的位置排入患者。自动单人排班将按照排班算法进行排班。
全体排班:首先进入排班参数的初始化流程,选择工作日和班次,后台将自动配置排班参数并删除原记录。初始化结束后进入病人循环,首先获取优先级较高的病人(即设置对透析机和时段有特殊要求的病人),根据病人初始信息中提供的透析机编号以及时段进行优先排班。再获取优先级较低(即无透析机以及时段要求的病人),获取该类病人的透析频率以及传染病类型,根据传染病类型选择合适的透析机列表。接着进入透析机循环,获取该透析机的当前排班情况(schedule)并赋值给变量tempSchedule。
排班流程如下:若该次排班为该病人第一次排班则设置排班指针(schedulepoint)归0并开始查找该透析机中是否存在空闲位置,如果tempSchedule&1等于0则该位置为空闲,若不为0则继续循环,每次循环将tempSchedule右移一位,即指向下一个班次。找到可排位置后用排班指针(schedulepoint)记录下该位置后将排班次数加1并保存至病人排班表(patientschedule),同时判断保存后该透析机是否已经排满,若排满则设置透析机的状态位(status)为1。若该次排班并非第一次排班,则获取上一次排班的排班指针(schedulepoint),将排班指针加上最小排班间隔后除21得到的余数作为起始排班位置,并查找该透析机是否在起始位置后三个位置之内存在空闲位置,若存在则效仿第一次排班进行保存操作,若不存在则跳出继续查看下一个透析机内是否存在合适位置。当所有排班次数大于该病人的周透析频率时则说明该病人已完成排班可进行下一个病人的排班。
基本排班流程如图5所示。
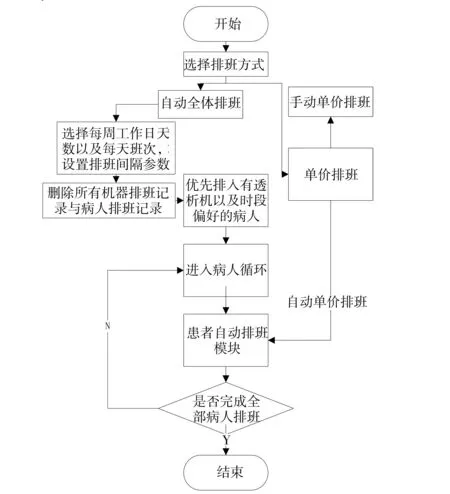
图5 排班系统流程
2.3 统计图表与辅助决策
透析医疗业务需要对基本信息、评估信息以及透析信息的三类数据进行统计,因此,系统提供三种统计图表功能如下[11-13]。
1)基本信息统计。提供对病人状态、诊断、年龄、性别以及传染疾病等信息进行分类统计,并以饼图图表展示统计结果,使医生可直观快速了解不同类型病人所占的比例。
2)评估信息统计。统计方式分为全体统计、批次统计以及个体统计三类。全体统计对指定时间段的所有病人各项评估信息进行均值统计,按批次生成各项评估指标均值的数据折线图,展示指定时间段病人某项数据的总体趋势。批次统计对某一批次的全部病人评估信息进行统计,并根据字典表提供的统计项的最小值和最大值范围生成饼图,让医生可通过该图了解某一评估批次所有病人达到正常数值的比率,进而了解该批次病人的透析效果。个体统计向医生提供自行选择病人以及时间范围,对筛选病人在指定段时间范围内生成所有统计项数据折线图,医生可根据该折线图对病人透析用药进行调整。
3)透析监测信息统计。统计方式分为全体统计和个体统计。个体统计提供按选择透析时段、查看项目以及时间范围生成病人数据折线图,通过该图展示病人透析过程中详细的生理数据变化情况。全体统计提供按选取病人群体与统计项目对每一病人进行指定项目的均值统计,并参照数据字典提供的临床数据范围,对同级项目均值的数据进行判断分组,生成分组饼图;同时对分组后的数据进行均值计算,并生成分组统计项均值柱状图。通过该图表展示一定时间范围内特定病人集合的某一生理数据过高或过低的人次以及比率,辅助医生调整整体透析方案。
该功能模块的设计均采用反射机制的设计思想,通过前台传递所需字段名,后台根据规则生成方法名,通过上下文(context)在Spring容器中查找并产生对应Bean,反射机制的应用提高了代码的可重用性的同时减少了代码冗余,具体代码如下:
ApplicationContext context = new ClassPathXmlApplicationContext(“applicationContext.xml”);
String itemcomment = itemInfoDAO.findById(itemid).getComment();
String itemname = itemInfoDAO.findById(itemid).getName();
String tablename = com.hdcenter.function.StringMutiply
FirstLetterUpper(tableInfoDAO.findById(tableid).getName());
Object oDAO = context.getBean(tablename + “DAO”);
PatientDAO pDAO=(PatientDAO) context.getBean(“PatientDAO”);
2.4 操作界面
登录血液透析中心信息系统后,用户可在顶部导航栏选择进入需要的功能模块。在病人管理操作界面,医生可对病人基本信息进行增删、改查以及变更病人的状态,如图6所示。若病人为死亡或出院状态时,病人列表将不再显示病人。病人查询模块按资源管理器窗格结构布局查询和显示病人详细信息的操作界面,如图7所示,医生可对某个病人信息进行查询,同时可对病人进行透析效果评估、透析记录管理等操作。在图表模块中,用户可选择对基本信息、评估信息以及透析信息三类数据进行统计并生成相应的图表,如按治疗病人性别进行统计,性别比率饼图如图8所示。选择透析机管理菜单后就能选择单人排班以及全体自动排班功能,排班操作界面如图9所示。

图6 病人管理界面

图7 评估信息录入界面

图8 数据统计界面

图9 透析机管理以及排班界面
3 系统测试
由于该系统仅供中心内部人员使用,访问量较小且数据存储结构较为简单,因此服务器部署于医生办公室中的一台计算机中,通过内网可对该平台进行访问,无需在客户端安装软件,运行良好稳定。
广州红会医院血液透析中心日接诊量约为120~150人,中心现有透析机33台,平日的透析机使用率约为80%左右。以60名患者透析治疗数据来测试系统效能,其中30例患者无传染性疾病,10例HIV患者,10例肝病患者,10例梅毒患者。其中22人为一周透析三次,19人为一周透析两次,19人一周透析一次,如表1所示。
设置测试透析机12台,6台无传染性疾病透析机,2台HIV透析,2台肝病透析机,2台梅毒透析。参照上述参数设置,对系统进行了多次测试,测试结果如表2所示。测试结果表明,广州市红十字会医院血液透析中心信息系统的排台模块能顺利进行智能排台,并尽可能将患者集中排入,使透析机保持数台富余,实现科学排班的功能。

表1 病人透析需求分布

表2 透析机排班效果

图10 患者透析时间排班结果图示
4 结 语
本系统采用基于二进制的排班算法实现了透析机智能排台的功能,并结合病人录入、查询、图表生成等功能构建了一个基于B/S架构的信息化血液透析中心管理平台,使医务工作者能在医院任何地方使用手持设备进行操作,大大提高了工作效率。红会医院透析中心每月会对病人进行评估统计,但由于数据量巨大,数据难以实现直观精确的统计,因此该系统的数据统计功能实现了临床数据的二次利用,对过往的数据进行整合统计,同时对医生科研工作以及临床透析方案起到一定的辅助指导作用。该透析中心每周都需要耗费1-2个工作日进行病人的排班配置,不仅耗费了大量人力资源且不能达到资源的最佳配置,因此该系统排班功能模块的设计能有效解决了手动排班造成的人力资源的浪费,利用该功能模块的自动排台算法使透析中心最大限度地减少工作透析机的台数,关闭不必要开启的设备,有效控制节约成本。经过多次测试,系统能良好地运行并且达到预期效果。未来在系统中增加与HIS系统的接口模块,可直接与HIS进行数据交互。
参考文献:
[1]刘宝亮.全国青少年慢性肾病患者已超过300万[N].中国经济导报,2013-7-30(07).
[2]王帅.基于J2EE的医院信息系统的分析与设计[D].同济大学,2008.
[3]邱金水.基于SSH的Web医院信息系统的设计与实现[D].昆明:昆明理工大学,2013.
[4]ZAROUR K,ZAROUR N.A coherent architectural framework for the development of hospital information systems [J].Applied Medical Informatics,2012,31(4):33-41.
[5]李青,张军,张学军.解决排班问题的多目标优化模型及算法研究[J].北京航空航天大学学报,2003,29(9):821-824.
[6]蒋龙聪,刘江平.模拟退火算法及其改进[J].工程地球物理学报,2007,4(2):135-140.
[7]SRIDHAR G R,RAO ALLAM APPA,MURALEEDHARAN M V,et al.Electronic medical records and hospital management systems for management of diabetes [J].Diabetes and Metabolic Syndrome:Clinical Research and Reviews.2009,3(1):55-59.
[8]WU J J ,LIN Y,ZHAN Z H,et al.An ant colony optimization approach for nurse rostering problem [C]//Systems,Man,and Cybernetics (SMC),2013 IEEE International Conference on 2013:1672 - 1676.
[9]HADWAN M,AYOB M.A constructive shift patterns approach with simulated annealing for nurse rostering problem [C]//Information Technology (ITSim),2010:1-6.
[10]姚仲敏,自立静,孟洪颜.一种透析机自动排台优化算法的实现与应用[J].测控技术,2012,31(9):51-55.
[11]姚仲敏,商秀美.基于ADO技术的血液透析全自动排台系统设计[J].测控技术,2010,29(7):68-71.
[12]白立静.基于Android的血液透析信息系统设计[D].齐齐哈尔:齐齐哈尔大学,2012.
[13]张稳.网络环境下的血液透析中心信息管理系统设计与实现[J].中国医疗设备,2008,23(2):23-26.
