OLAP在大学生首次职业类型选择中的应用研究
2014-03-01王善勤孟龙梅王小林
王善勤,孟龙梅,王小林
(1.滁州职业技术学院信息工程系,安徽滁州239000;2.安徽工业大学计算机学院,安徽马鞍山243032)
随着信息技术的发展和大学生职业类型选择相关数据量的增长,联机事物处理技术已无法同时满足高效作业和决策支持的需求,造成了海量数据与信息“孤岛”的并存[1].近年来,对职业生涯领域的研究工作,国外已经比较深入全面[2],对职业、职业类型选择及职业价值观等方面做了深入地研究,国内在此方面的研究相对较浅、单一.国内外专家学者对OLAP技术在各行各业进行应用研究,但对国内大学生首次职业类型选择的应用研究还是空白.目前,安徽工业大学的王善勤、王小林、陈业斌已对高职学生职业类型选择数据仓库进行了研究与构建.鉴于此,以安徽工业大学、滁州学院、滁州职业技术学院近三年毕业生首次选择的职业类型与个人先天因素作为数据源来构建的数据仓库为基础,以OLAP技术为手段,建立了大学生首次职业类型选择预测模型,对大学毕业生首次职业类型选择进行预测与指导,能够更好地为职业规划指导师做好学生职业类型选择指导工作提供依据参考.
1 OLAP介绍
联机分析处理(OLAP)的概念最早是由关系数据库之父 E.F.codd于1993年提出的:OLAP是使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术[3].OLAP主要是用来对用户当前的及历史的数据进行分析,完成大量的查询操作,对时间的要求相对不高.OLAP的步骤如图1所示.

图1 OLAP的步骤
2 数据预处理
如果数据仓库中存在脏数据,决策分析系统也就失去根基.由于现实世界数据常存在含有噪声、不完全的和不一致的现象,提高数据的质量是非常重要的[4].因此数据预处理是整个OLAP过程中一个非常重要的步骤.此文研究分析的数据来源于已构建好的数据仓库,对数据仓库中的数据集市数据进行进一步清洗,根据业务需要进行数据转换.由于人的气质、兴趣、性格、职业类型做个绝对区分是一件比较复杂的事,所以在对数据进行OLAP之前必须针对先天因素影响下大学生职业类型选择的主题进行数据的预处理.
2.1 数据清洗
(1)数据通常存在的问题.噪声数据是指数据中存在着错误或异常的数据[5].比如,被测试人在心情最低谷或最高涨的时候,进行测试,数据可能存在一定波动,当情绪正常时,没有参加测试,导致数据特别低(高).不完整数据是指感兴趣的属性没有值[6].例如,有的工作人员在就业质量跟踪调查时,没有详细统计就业岗位、在其岗位发展情况及综合满意度等.
(2)数据清理处理方法有平滑噪声数据、填补遗漏的数据、识别或去除异常值及解决不一致问题几种.例如存在问题的数据会给整个OLAP的过程注入无色无味的“毒药”,会导致数据模型出现“畸形”,虽然OLAP过程大都能处理噪声数据,但挖掘分析工作的重点常放在怎么避免结果过分逼近实验数据上.
2.2 数据转换
数据转换是把一种格式的数据转换为另一种格式的数据,并进行规范化,构成一个适合联机分析处理的描述形式.此研究中数据转换主要包括以下几点:
(1)合计处理:对数据进行总结或合计操作,如学生气质分值进行合计测试操作得到最后平均分值.
(2)规格化:有关属性按比例进行缩放,将其定格在特定的小区域中.
2.3 数据属性的选择及预处理后数据
选择数据的属性,是在已有属性集的基础上构建新的属性.属性选取标准在决策树领域可分属性间相互独立的选择方法、属性之间相互关联的选择方法两类.文中使用属性间相互独立的选择方法来确定关于大学生先天因素及首次选择职业类型情况的数据表属性,共有1个ID属性,5个普通属性,其中序号表示ID属性,性别属性表示学生的性别、气质表示学生的气质类别、性格表示学生的性格类别、兴趣表示学生兴趣类别、职业类型表示大学生首次选择的职业类型.
对先天因素影响下大学生首次职业类型选择为主题的数据信息进行预处理后,选取89条典型的样本记录.为了便于描述,序号字段属性改为自动编号,种子值为1,增量值为1.如图2所示.

图2 “先天”条件下首次职业类型选择信息
3 分析工具提供的算法在职业类型选择中的应用
从目前企业的应用上来看,OLAP分析大多是通过使用OLAP工具来实现的,目前国内流行的OLAP工具主要有下列产品:Cognos(Powerplay)、Hyperion(Essbase)、微软(Analysis Service)、MicroStrategy.综合考虑大学生职业类型选择需求和研究团队的现状,选用了微软(Analysis Service)作为联机处理分析工具.
3.1 分析工具提供的决策树算法在首次职业类型选择中的应用
微软数据分析工具提供的决策树算法是一种混合算法,它综合了多种不同的创建树的方法,并支持多种分析任务.本文使用Microsoft工具提供的决策树算法在学生先天因素中找出性别、性格、气质、兴趣四个方面对首次职业类型选择影响度情况,并能挖掘分析出相应规则.
3.1.1创建“先天”职业类型选择模式的 OLAP模型
在Analysis Manager树视图的“挖掘结构”中建立挖掘结构;通过挖掘结构向导,选择决策树挖掘技术;指定定型数据;为挖掘结构命名,根据算法名命名为“决策树算法”,即建立完成“决策树算法”挖掘结构.
3.1.2 设置挖掘参数
在挖掘模型编辑器中,包含显示模型和模型列的表,还包含一个属性窗口中.用挖掘模型编辑器,可为每个模型设置算法特有的参数.右键单击“Microsoft_Deccision_Trees”,在弹出的菜单中选择“设置算法参数”.决策树算法通过控制所生成的挖掘模型的性能和准确性.这些参数可控制树的增长、树的形状和输入/输出属性的设置.下面给出本算法的参数作一些分析与设置.
(1)COMPLEXITY_PENALTY,此参数控制决策树的增长.值越小,则分叉数越多;值越大,则分叉数越少.在本次挖掘中,事务表中有六个字段属性,符合要求的数据量不是很大,我们将此参数设置的比较小,即COMPLEXITY_PENALTY=0.01,进而控制树的生长.
(2)MINIMUM_SUPPORT,此参数确定在决策树中生成拆分所需的叶事例的最少数量.默认值为10.如果数据集非常大,则可能需要增大此值,以避免过度定型.比如将这个参数值设为6,表示任拆分而产生的子节点的个数至少有5个.由于职业类型有6种,经处理后数据量不是很大,我们将此参数值设置为1,即 MINIMUM_SUPPORT=1.
(3)SCORE_METHOD,此参数确定用于计算拆分分数的方法.该参数有三种可能的取值:SCORE_METHOD=1,说明该算法使用信息熵控制树的增长.SCORE_METHOD=3,说明该算法使用Bayesian with K2 Prior方法,表示树的节点中可预测属性的每一个状态增加一个常量,而无用考虑该属性在树中所处的层次.SCORE_METHOD=4,这是告诉算法使用Bayesian Dirichlet Equivalent(BDE)with uniform prior方法,这种取值也是默认值,根据树节点的层次为每一个可预测的状态增加权支持度.由于我们在建模过程中,使用的是信息熵的算法,因此选择该参数值为1,即SCORE_METHOD=1.
(4)SPLIT_METHOD,此参数确定用于拆分节点的方法,该参数控制树的形状.该参数有三种可能的取值:SPLIT_METHOD=1,(Binary)指示无论属性值的实际数量是多少,树都拆分为两个分支.SPLIT_METHOD=2,(Complete)指示树可以创建与属性值数目相同的分叉.SPLIT_METHOD=3,(Both)指定 Analysis Services可确定应使用binary还是 complete,以获得最佳结果.这种取值也是默认值.
(5)FORCE_REGRESSOR,此参数强制算法将指定的列用作回归量,此参数只用于预测连续属性的决策树.因为我们前期对数据进行大量操作,连续属性已转换成离散的属性,所以此参数此处不做设置.
3.1.3 生成和部署
在开发窗口选择“生成”菜单中的“部署”命令,出现“处理进度”提示框,提供有关处理操作的一些状态信息.当处理完成后,可看到处理步骤的细节信息.现在数据挖掘模型部署好后,可以使用这些模型对大学生首次职业类型选择进行深入分析研究,挖掘出相应规则供来预测新毕业生职业类型选择情况.
3.1.4 分析研究挖掘出的职业类型选择模型
微软Analysis Services为每一个数据挖掘的算法都提供一个自己的查看器.“数据挖掘查看器”提供的实际模型视图有两种基本的类型,即图和表.
(1)职业类型选择测评依赖关系
依赖关系网络显示决策树模型中所有属性之间的关系,这些属性派生自决策树模型的内容.如图3所示.图中线上编号代表各维度与职业类型之间存在关联强度排序,由此可看出职业类型选择受兴趣影响最强,依次是性格、气质、性别.
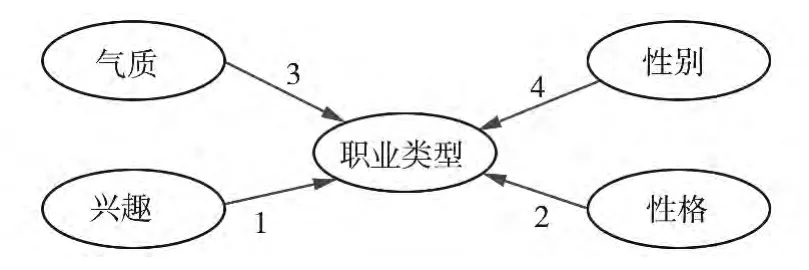
图3 决策树模型依赖关系
(2)挖掘模型
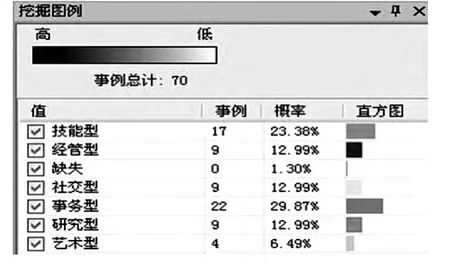
图4 挖掘图例
技能型、经管型、社交型、事务型、研究型、艺术型,下面给出大学生首次职业类型选择社交型决策树模型,如图5所示.
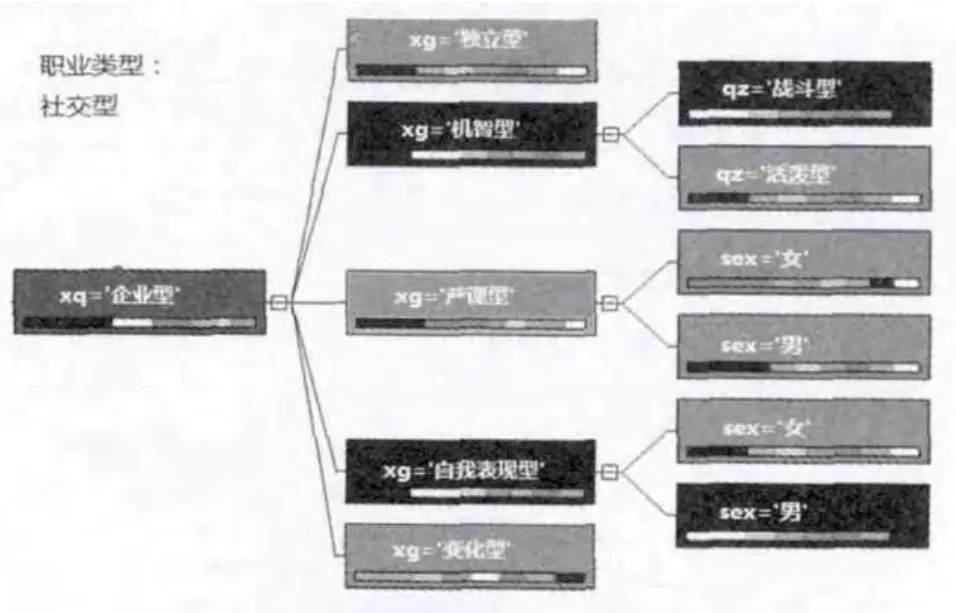
图5 职业类型为社交型的典型决策树模型
图5中的树是水平摆放的,最左边是分类节点较突出分类因素;节点着色各有不同,着色深的节点是支持事例较多的.决策树的模型所反映出来的规则非常容易理解,每一条从最左边节点到最右边的叶子节点就是一条规则.
3.1.5 挖掘准确性分析
微软的商业智能开发平台提供“挖掘准确性图表”窗格,以用来衡量所创建模型的质量和精确性.图6是决策树算法挖掘模型的提升图,此图显示了挖掘模型的整体预测准确性与理想模型的对比.此图的横坐标表示比较预测的测试数据集的百分比,纵轴表示准确预测的百分比.从图中可以观测到一条对角线,使用50%的数据来获得50%的目标,此挖掘模型总体准确度是相当高的.
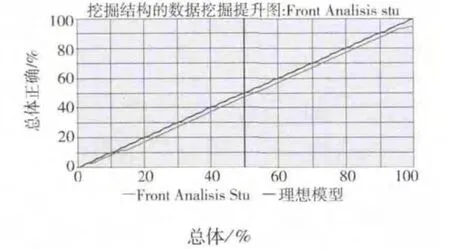
图6 决策树算法挖掘模型的提升图
此决策树模型在50%的数据中的预测准确率为47.14%,当数据量是100%时,此模型的预测准确率达到94.29%.
3.1.6 结果分析
从以上挖掘结果可以分析出,大学生首次职业类型选择与兴趣存在很大内在的关联度.由此得出结果,兴趣对大学首次职业类型选择影响最大.通过对学生兴趣、性格、气质、性别情况预测大学生的首次职业类型选择情况进行数据挖掘分析.大学生为了更好做好首次职业类型选择,要加强自己兴趣培养,进而做好职业规划,最终能实现“人职匹配”.从分析可看出,个人性格、气质对高职学生职业类型选择也有一定影响,性别对职业类型选择影响并不是很大.
3.2 分析工具提供的关联规则算法在职业类型选择中的应用
在Analysis Manager中创建模型及相关设置如上,这里不在赘述,直接分析结果.3.2.1 职业类型选择测评依赖关系
依赖关系如图7所示.连接线上数字表示关联强度,1表示是最强,8表示最弱.
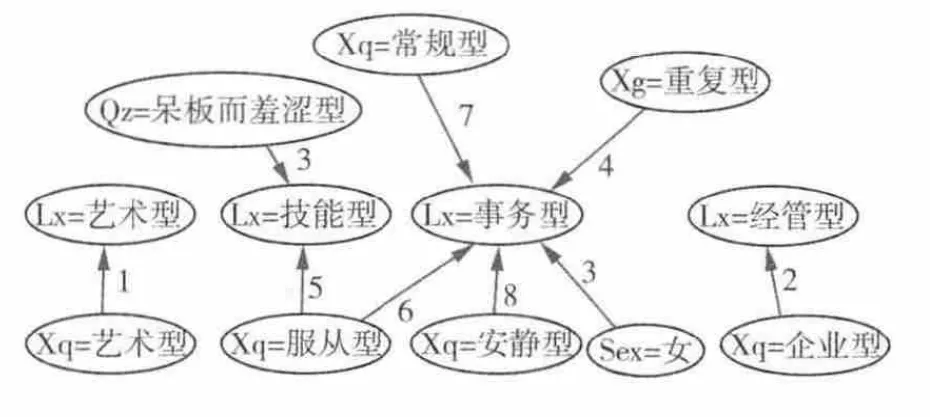
图7 关联规则模型依赖关系
3.2.2 挖掘模型
图8显示了大学毕业生职业类型选择关联规则模型.
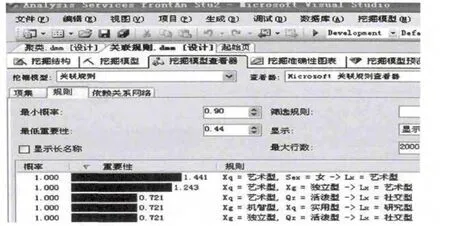
图8 关联规则模型
3.2.3 挖掘准确性分析
图9给出关联规则模型的提升图.图9展示了这个挖掘模型的提升图,从图中可以看出,准确度良好.此实际决策树模型在50%的数据中的预测准确率分别为47.14%,而当数据量达到100%时,该模型的预测准确率为68.57%.
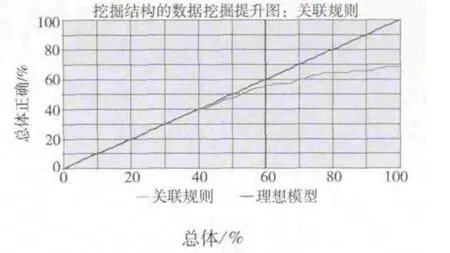
图9 关联规则模型的提升图
3.2.4 结果分析
从以上挖掘结果可以分析出,大学毕业生职业类型选择与个人先天因素存在一些内在的规则.由此同样得出结果,兴趣对大学生毕业生首次职业类型选择影响最大,个人性格、气质对高职学生职业类型选择也有一定影响.
4 职业类型选择数据挖掘规则提取及分析
通过对以上两个模型进行分析,得出大学毕业生首次职业类型选择与人的兴趣、性格、气质、性别有一定的关联,提取支持率比较高的规则,可供职业规划指导师参考、大学生首次职业类型选择的决策支持;将上述结论应用到高等院校职业类型选择专家指导系统中,也进一步推进高等院校职业规划工作信息建设.兴趣用Xq表示,性格用Xg表示,性别用Sex表示,气质用Qz表示,职业类型用Lx表示;表示部分规则如下:
If Xq=企业型and Xg=严谨型and Sex=男then Lx=经管型
If Xq=企业型 and Xg=自我表现型 and Sex=女then Lx=经管型
If Xq=实用型and Xg=重复型and Qz=活泼型then Lx=事务型
If Xq=常规型and Qz=安静型and Xg=服从型then Lx=事务型
If Xq=研究型and Xg=变化型and Qz=活泼型then Lx=研究型
If Xq=研究型and Xg=协作型and Qz=战斗型then Lx=研究型
If Xq=艺术型and Sex=女then Lx=艺术型
If Xq=实用型and Qz=战斗类型then Lx=社交型
If Xg=严谨型and Xq=实用型then Lx=社交型
If Xq=研究型and Xg=自我表现型then Lx=技能型
If Xq=实用型and Xg=独立型and Xg=Qz=安静型and Sex=男then Lx=技能型
If Xq=常规型and Qz=呆板而羞涩型then Lx=技能型
……
5 结 论
将OLAP技术应用到大学生首次职业类型选择指导的实际工作中,为做好高校学生职业生涯规划工作提供新思路.利用微软数据分析工具提供的决策树算法、关联规则算法创建两个模型并进行对比分析出学生的兴趣、性格、气质、性别与首次选择的职业类型存在的潜在规律,挖掘出兴趣对大学生首次职业类型选择影响较大等许多有参考价值的成果.但仍存在研究数据不够丰富、数据处理过程繁琐等,所以还有待进一步研究.
[1] 张美虎,等.OLAP工具在企业决策支持系统中的应用[J].淮阴工学院学报,2009,(1):55-56.
[2] 康雁冰.职业发展与大学生职业规划[J].创新与创业教育.2012,3(6):29-30.
[3] 容晓晖.基于数据挖掘的邮政业务量收系统改进方案研究[D].沈阳:东北大学,2009:6-7..
[4] 徐娟.基于数据挖掘技术的信用评估模型研究[D].合肥:合肥工业大学,2009:4-5.
[5] 马勇.恶意网页的分析及识别方法研究[D].天津:南开大学,2008:11-12.
[6] 周成义.数据挖掘技术在电子商务企业中的研究与应用[D].鞍山:辽宁科技大学,2007:3-4.
