语义词特征提取及其在维吾尔文文本分类中的应用
2014-02-28吐尔地托合提艾克白尔帕塔尔艾斯卡尔艾木都拉
吐尔地·托合提, 艾克白尔·帕塔尔, 艾斯卡尔·艾木都拉
(新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046)
1 引言
文本分类中,先需要以某种粒度对文本进行切分,因为切分层次越高其分析代价也越高,因此常用以词的级别切分文本,并用词特征来形成文本模型。对于中文,因为词之间没有明显的切分标记,因此需要特殊的分词处理,这也是中文自然语言处理中的一个难点。与中文不同,英文词间是以空格隔开,不需要特殊的分词方法就可以将文本切分成单词集合。维吾尔文与英文类似,也是一种拼音文字,词与词之间也是以空格隔开,因此,同样以词间自然分隔符进行词切分,是到目前为止唯一的分词方法。

针对以上情况,在中文统计分词方法的先导作用下[4-6],我们提出了一种新的维吾尔文无监督及无词典语义分词方法dme-TS,并把它用到维吾尔文文本分类中。dme-TS无需为它提供分词词典和人工分词的指导信息,所需要的全部统计信息完全来自大规模生语料库,无需人工介入。dme-TS的分词依据是,将相邻单词之间的t-测试差(difference of t-test),互信息(mutual information)及邻接对熵(entropy of adjacency)的线性融合作为一个组合统计量(dme)来度量相邻单词之间的关联紧密程度,并将dme小于给定阈值的词间位置确定为切分位置,从而提取语义具体独立的单词和多词(二词,三词或四词)结构的语义词。
研究者们已有共识,以短语特征表征文本可以得到更好的分类效果,因为与单个的词特征相比,短语特征包含更丰富的信息。文献[7]的实验结果表明,以n元法提取短语特征,n的取值不超过4时,分类效果最好。我们提取的特征也是长不超过4个单词的语义词,信息表达能力不如短语,但其语义表达能力比传统分词方法提取的抽象单词特征更具体和独立,而且其分析代价比短语提取方法更小。
dme-TS是我们最近的一项研究工作(一种无监督及无词典支持的维吾尔文语义分词方法),本文的研究重点是这种分词方法在维吾尔文分类中的应用及验证其有效性。因此,我们分别用传统方法和dme-TS来切分训练文本和测试文本,再用被认为最好的有监督特征选择方法IG来选取最优特征,观察了最流行的三种分类算法NB,SVM和KNN在两种特征集下的分类效果,并得到了我们期望的结果。
2 dme-TS分词的语义词特征提取
我们知道,对于一个独立使用的语言单元,其内部词与词(字与字)之间的结合程度应该是非常紧密的,而它与外部上下文的关联应该是非常松散的,这种“紧密”或“松散”性可以用某种统计量来度量,而这个统计量也能够非常容易地从大规模真实语料中获取。
dme-TS中,从大规模生语料库中自动获取维吾尔文单词Bigram及上下文语境信息,充分考虑维吾尔文单词间结合规律的前提下,将相邻单词间的t-测试差、互信息及双词上下文邻接对熵的线性融合作为组合统计量dme来度量相邻单词之间的结合程度,并在dme小于给定阈值的词间位置插入一个切分标记“|”。这样,完全不考虑词间空格,切分出文本中语义具体的单词特征和语义独立完整的语义词特征。
2.1 互信息(mutual information)
根据互信息原理,在以空格隔开的维吾尔文有序词串A B中,单词A,B之间的互信息定义如式(1)所示。
其中,P(A,B)为词串A B在语料库中出现的概率,P(A)为单词A出现的概率,P(B)为单词B出现的概率。 如果mi(A,B)≥0,则A B间是强关联的;如果mi(A,B)≈0,则A B间是弱关联的;如果mi(A,B)<0,则A B间是互斥的。随着mi(A,B)的增加,紧密程度也增加,当mi(A,B)大于给定的一个阈值Tmi时,可以认为A B是不可分割的。
从式(1)看出,互信息反应了相邻单词A B之间的静态结合能力,而不考虑它们的上下文,因此仅依靠互信息这个绝对度量,有时也会出现判断错误。
2.2 t-测试差(difference of t-test)
Church等首次引入t-测试,以度量一个英文单词A与其它任意两个单词x和y的结合紧密程度[8]。根据定义,维吾尔文单词串xAy的t-测试值计算如式(2)所示。
其中p(y|A)和p(A|x)分别是单词串A y和x A的Bi-gram概率,σ2(P(y|A))和σ2(P(A|x))分别是二者的方差。由式(2)可以看出,如tx,y(A)>0,则A与后继y结合的强度大于与前趋x结合的强度,此时A应与x分开,而与y要连。如tx,y(A)<0, 则A与前趋x结合的强度大于与后继y结合的强度, 此时A应与y分开,而要与x连。如tx,y(A)=0,则A与其前趋和后继的结合强度相等,无法判断A跟哪个要连或分开。
t-测试是基于字的统计量,而不是基于字间位置,因此为了能够在中文分词中直接用来计算相邻字间连断概率,清华大学孙茂松教授等人提出了t-测试差的概念[4]。
根据定义,对于维吾尔文单词串x A B y,相邻单词A,B之间的t-测试差值计算如式(3)所示。
当dts(A,B)>Tdts(Tdts为阈值)时,A B的单词间位置更倾向于连,反之倾向于断。与互信息不同,t-测试差反映的是相邻单词之间的动态结合能力,因为它综合考虑一个单词的上下文结合趋向,因此总的切分正确率比互信息好。
2.3 邻接对熵(entropy of adjacency)
信息熵是判断一个语言单元对于上下文语言环境的独立性及完整性的有效度量。如文献[9]提出的新词识别方法中,计算一个词串的左邻接熵和右邻接熵,当左右邻接熵大于一个阈值是,认为该词串是一个独立语言单元,并将该词串提取为一个新词,否则将它舍去。我们将以上思路引入到本文研究中,但我们发现以左右邻接熵判断词间位置,就无法整体获取三词语义词。例如,判断三词关联模式A B C中的A和 B间的位置时,词对A B的左邻接可能是变化多样的,但右邻接是确定不变的,也就是C。根据信息熵的定义,A B的右邻接熵是0(最小值),因此将A B间的位置被错误地判断为断(B和C间位置也是被错判为断)。针对以上情况,如果我们将问题改成计算邻接对熵及基于邻接对熵的词间位置连、断判断问题,那就适合文本的研究需求。
定义对维吾尔文有序单词串x A B y(x和y是任何一个维吾尔文单词),A B在文本中每次出现的左邻接元素x和右邻接元素y构成一个邻接对
由计算公式得知,邻接对熵的最小理论值为0(当c=1时),而最大理论值为log(m)(当c=m时)。如果ea(A,B)取值越大,表明词串A B的语言环境变化多样,是不依赖于上下文的语言单元。如果ea(A,B)取值越小,则表明A B的独立性不强,很可能是一种偶然性组合。因此,当ea(A,B)>Tea(Tea为阈值)时,A B的单词间位置更倾向于判断为连,反之判断为断。
2.4 组合统计量dme
不管是互信息、t-测试差还是邻接对熵,都是将词在语言环境中某一方面的信息特征作为计算依据,因此必然存在着一定的局限性。中文分词中已有成功的案例表明,可将基本统计量加以组合从而各取所长[4-5]。除此之外,我们分别用互信息、t -测试差和邻接对熵进行切分实验,也发现将它们结合互补的较大的可行性。因此,我们将以上三个基本统计量进行线性叠加,融合成一个新的统计量dme,并完全根据dme来判断词间位置,从而得到了更准确的切分结果。
因为以上基本统计量取值范围相差较大,因此我们用与文献[4]相同的方法,先对各统计量进行归一化处理,然后进行线性叠加。三者叠加的dme计算如式(5)所示。
其中λ和γ的值经实验测定, 发现λ=0.35,γ=0.30时的切分准确率最高。
分词时,计算待处理文本中各相邻单词(词干)之间的dme值,如dme(A,B)>Tdme(Tdme=0),则保留他们之间的关联性,否则以分隔符(本文用“|”)将它们隔开(图1)。

图1 以dme-TS切分的一个例子
可以看出,如用传统的切分方法来切分,就把图1中的维吾尔文句子切分成语义不完整的8个词特征,但dme-TS的输出是5个特征,而且都是语义具体而独立的语言单元。本算法开放测试中的切分准确率达到了88.21%。
3 实验及结果分析
3.1 数据集
本文用新疆大学智能信息处理重点实验室提供的维吾尔文分类文本集进行分类实验和分析,共含6类(01经济,02体育,03政治,04教育,05法制,06健康)3 000篇文本(每类500篇)。
3.2 实验方案
为了对本文提出方法进行有效的评估,我们设计了两个实验。
实验1 用传统方法对整个文本集进行分词并用停用词表去除停用词,再用性能最好的有监督特征选择方法IG来评估特征词的重要度。然后从经过排序的特征序列中递增地选取N个(N的增量为100)特征组成一个特征子集,并将其作为最流行的三种分类器NB,SVM和K-NN的输入,观察分类准确率。
实验2 用dme-TS对整个文本集进行分词,然后用实验1同样的方法进行分类实验,观察用语义词特征表征文本时的分类准确率。
3.3 结果及分析
分别用传统分词方法和我们的dme-TS对文本集进行切分,得到了两种原始特征集,如表1所示。
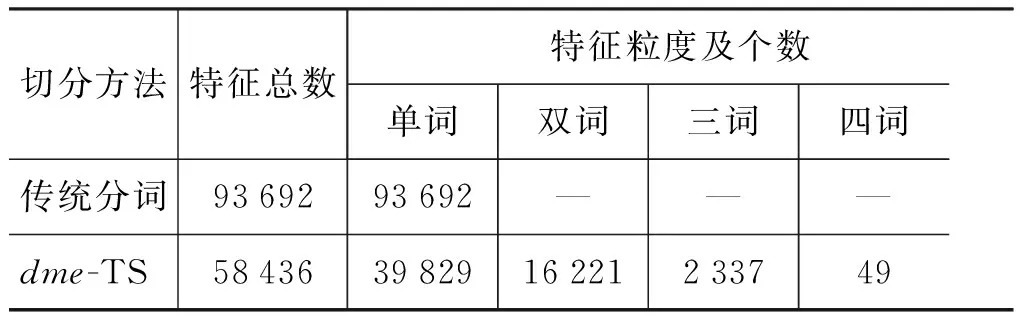
表1 两种切分方法对应的原始特征集
可以看出,用dme-TS分词的特征维数是传统分词获取的特征维数的62.3%(特征空间降维率为37.6%),其中32%左右的特征是二词、三词和四词语义词,它们比单词更能表达具体而独立的语义。因此,从这样的原始特征集中选取少量的最优特征来表征文本,这对分类算法性能的提高会有很大的帮助。
为了验证语义词特征提取在维吾尔文文本分类中的有效性,我们用开发工具Visual C# 2010,分别实现了三种最流行的分类器NB,KNN和SVM,并在以上两种特征集上进行分类实验。在评价分类器的性能时,我们将5次5-fold交叉验证运行结果的分类准确性的平均值作为最终的分类准确性。经过试验确定KNN的K值为11。在两种特征集下不同N值的三种分类器分类效果如图2~4所示。
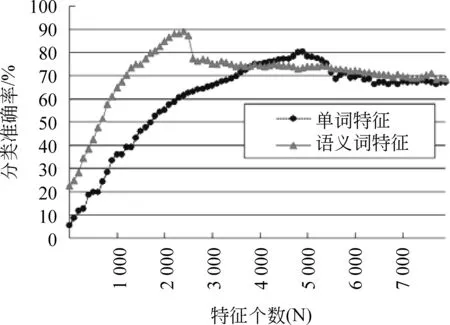
图2 两种特征集的NB分类效果
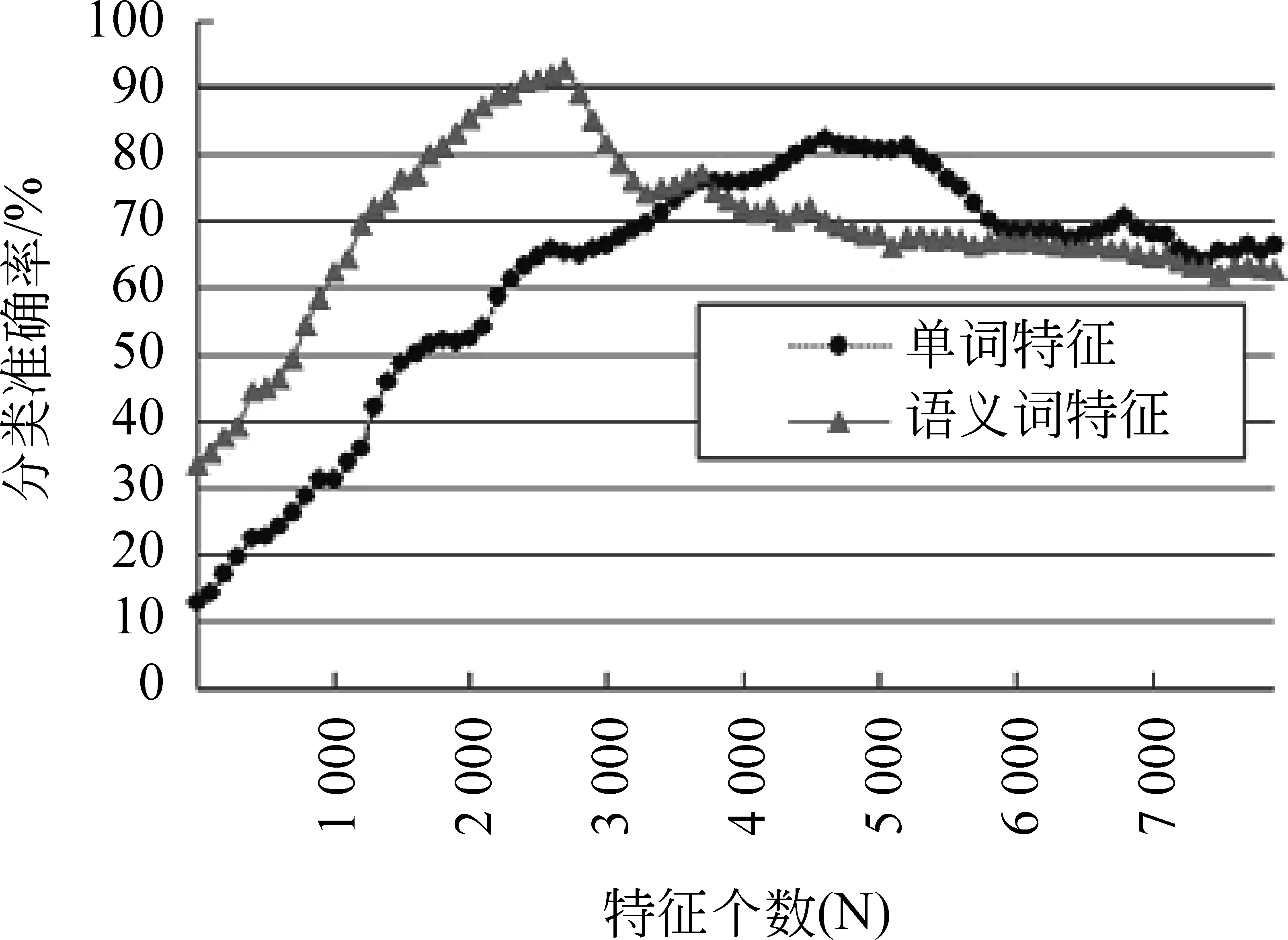
图3 两种特征集的KNN分类效果

图4 两种特征集的SVM分类效果
很容易看出,每一个学习算法对于两种特征集的分类效果有明显区别。表2给出了三种算法对于两种特征集的最佳特征子集的特征个数和对应的最高分类准确率。
从表2中可以看出,相对于单词特征,用更少的语义词特征表征文本时,得到了更准确的分类结果。
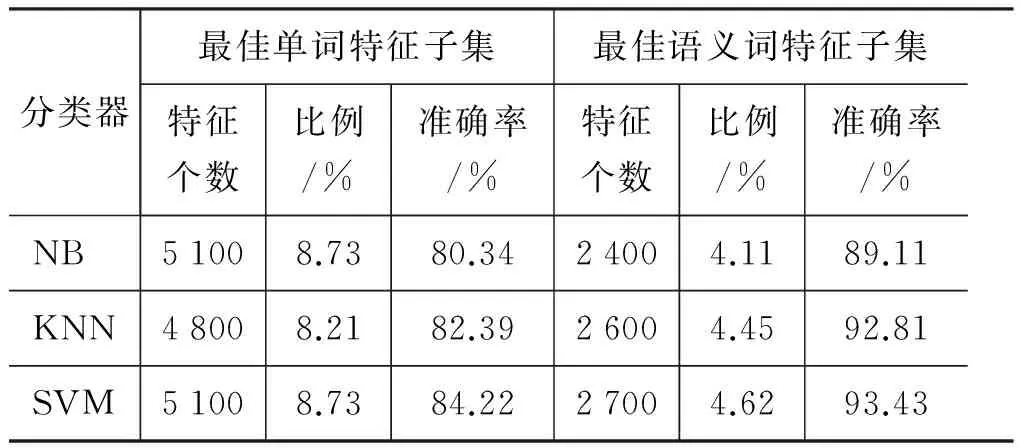
表2 最佳特征子集及分类性能
这是因为,用IG打分并放在特征序列前面的特征都是具有代表性和富含信息的重要特征,我们又发现其中大部分是多词语义词。这就充分说明了语义词特征提取在维吾尔文文本分类中是有效的。
4 结束语
文本分类中,特征提取的粒度和特征词条的语义独立性会决定被形成文本模型的质量,这也是影响分类器性能的主要因素。针对维吾尔文传统分词及基于词特征的文本模型对维吾尔文文本分类的影响,本文提出一种语义词特征提取方法,并用三种流行的分类算法进行分类实验。实验结果表明,用语义词作为特征表征文本时,不仅缩小原始特征空间的维度,还可以用少量特征来形成易于理解的,紧凑而泛化能力更强的文本模型,因此明显提高了分类准确率。
[1] 阿力木江·艾沙,吐尔根·依布拉音,艾山·吾买尔, 马尔哈巴·艾力.基于机器学习的维吾尔文文本分类研究[J].计算机工程与应用,2011,36 (7):110-112.
[2] 徐峻岭,周毓明,陈林,徐宝文. 基于互信息的无监督特征选择[J].计算机研究与发展,2012,49(2):372-382.
[3] 孟春艳.用于文本分类和文本聚类的特征抽取方法的研究[J].微计算机信息,2009,25(3):149-150.
[4] 孙茂松, 肖明, 邹嘉彦. 基于无指导学习策略的无词表条件下的汉语自动分词[J].计算机学报, 2004, 27(6) : 736-742.
[5] 王思力,王斌.基于双字耦合度的中文分词交叉歧义处理方法[J].中文信息学报, 2007,21(5):14-17.
[6] 费洪晓,康松林,朱小娟,谢文彪.基于词频统计的中文分词的研究[J].计算机工程与应用,2005,30(7):67-69.
[7] Furnkranz J.A Study Using N-gram Features for Text Categorization[R].Technical Report:TR-98-30,http://www.ai.univie.ac.at/cgi-bin/tr-online?number+98-30,1998.
[8] Church K W, Gale W, Hanks P, Hindle D. Using statistics in lexical analysis[C]//Proceedings of the Zernik U. ed.. Lexical Acquisition: Exploiting On-line Resources to Build a Lexicon. Hillsdale NJ :Law rence Erlbaum Associates,1991: 115-164.
[9] 贺敏,龚才春,张华平,程学旗.一种基于大规模语料的新词识别方法[J]. 计算机工程与应用,2007,43(21): 157-159.
