基于Counting Bloom Filter的DNS异常检测
2014-01-31胡蓓蓓彭艳兵程光
胡蓓蓓,彭艳兵,程光
HU Beibei1,PENG Yanbing2,CHENG Guang3
1.武汉邮电科学研究院,武汉430074
2.烽火通信科技股份有限公司,南京210019
3.东南大学计算机科学与工程系,南京211189
1.Wuhan Research Institute of Posts and Telecommunications,Wuhan 430074,China
2.Fiberhome Communication Technologies Co.Ltd,Nanjing 210019,China
3.Department of Computer Science and Engineering,Southeast University,Nanjing 211189,China
1 引言
域名系统(DNS)是标识计算机电子方位的“GPS”,它将域名和IP地址相互映射成一个分布式数据库。一次DNS查询的失败(DNS query failure,以下简称DNS failure)通常意味着无法在数据库中找到所查域名对应的资源记录。出现DNS failure可能是由DNS配置不当或域名输入错误引起,但前者发生的机率非常小,后者产生的数据量非常小。相关事件与研究表明一些网络异常活动会导致大量DNS failure的出现:
2009年5月18日域名托管商DNSPod的一台承担着暴风影音等十万个域名解析工作的服务器因遭到攻击而失效离线,19日数量巨大的重复的baofeng.com查询在得不到响应的情况下转向各省递归服务器,19日晚这些服务器陆续因超负荷而崩溃,引发大规模网络瘫痪[1]。
Yadav S[2]、Jiang N[3]等学者研究发现僵尸网络等异常活动是DNS failure的主要来源。考虑到采用domainflux技术的僵尸主机会对特殊算法生成的域名进行逐一访问而有大量DNS failure出现,前者借助域名的熵值计算和访问的时间相关性来分离网络流量中的恶意域名与合法域名,实验表明该方法对Conficker僵尸网络具有较好的检测效果;后者为区别不同类别的failure模式,使用三维非负矩阵聚类,成功检测到未知僵尸网络的存在。
大部分DNS异常检测的过程里需要保存和处理一定的域名、IP、访问时间、报文长度等DNS流特征,以研究具体的异常细节。考虑到目前大部分主干网络已经升级到OC-48(2.5 Gb/s)和OC-192(10 Gb/s)[4],上述研究方法并不适用于计算资源(CPU、内存、硬盘等)有限的高速大规模的网络环境中。
因此,本文以DNS failure中的域名和客户端IP为检测对象、以发现恶意活动为检测目标,提出了一种仅需很小资源开销的基于Counting Bloom Filter的检测方法。如何改进Counting Bloom Filter,以较低的资源开销实现高效的DNS异常检测是本文的主要研究内容。
2 准备工作
鉴于恶意程序DNS查询的动机、时间、频率由事先编程的代码内容设定,它的DNS failure流量与合法用户的随机DNS failure存在着明显的区别。为了让恶意DNS failure从DNS数据流中“脱颖而出”,首先需要做好两项准备工作:
(1)提取纯净的DNS failure报文
借助网络数据包分析工具wireshark对DNS样本数据进行观察,发现DNS failure报文的三条特征:
①DNS服务器的回复为Server Failure。在该类DNS响应报文中,标志字段中的rcode子字段值为2。
②DNS服务器的回复为No Such Name。在该类DNS响应报文中,标志字段中的rcode子字段值为3。
③域名被劫持至电信114广告服务器。在该类DNS响应报文中,返回的资源数据内容为114服务器IP地址(a.b.c.d)。
(2)描述恶意DNS failure的流量特征
Zhu Z.S.等人为了解不同应用产生的不同的failure流量,进行了一组对比实验:恶意应用组中被执行的程序有基于HTTP、IRC及P2P三种协议的僵尸程序以及蠕虫等;网络爬虫及视频网站等良性应用被置于正常组。观察发现24种恶意程序中有3/4表现出活跃的DNS failure现象,相对于正常应用有更高的DNS failure频度[5]。如表1所示。
由此,定义单位时间内DNS failure大规模的发生为大规模失败DNS查询异常(Numerous DNS Failures,NDF)。为将良性的DNS failure流量与恶性的DNS合理区分开,如何界定NDF异常是亟需解决的问题,通过设定NDF异常判断标准,使最终被检测的数据尽可能多地覆盖异常内容、尽可能少地包含正常内容。
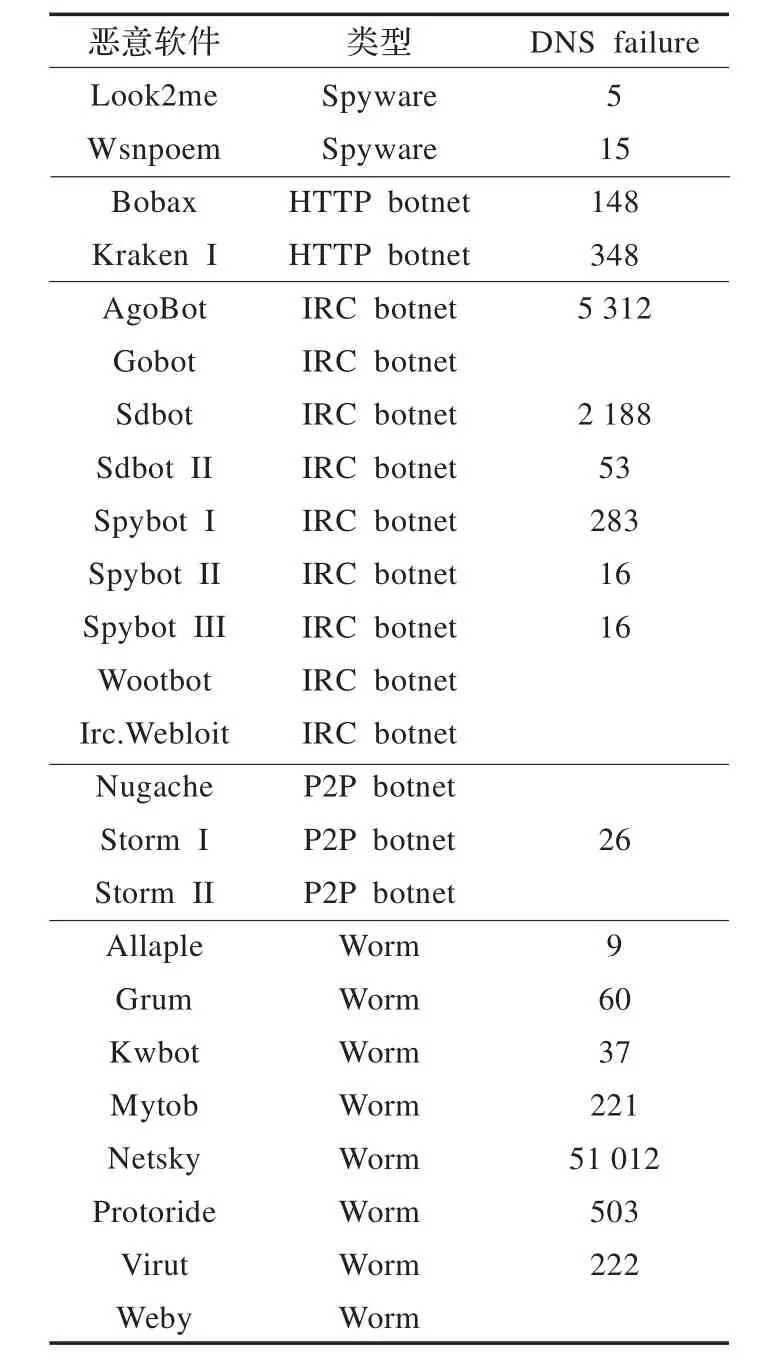
表12 4种恶意应用的每小时DNS failure数
对于网络中数据流的到达,学术界已经基本形成了共识,认为其是服从Poisson分布的,DNS流亦如此。而对于DNS failure的到达,目前还没有相关结论。由于每一次DNS查询都是独立的用户行为,并且最终结果只有DNS success和DNS failure两种可能性,设DNS failure发生的概率为p,以X表示n个时间粒度内的DNS查询中DNS failure发生的次数,则X服从二项分布X~b(n,p)。当测量时间足够长,即n值足够大时,X可以很好地近似为正态分布。
为有效分析大规模网络环境中DNS failure流到达的分布特征,采用某主干网边界采集器上的数据为研究对象,考察其2012年5月19日10:00至20:00时间范围内DNS failure报文数量随着时间变化的分布状况,以5 min为单位时间粒度,对报文进行计数,计数结果如图1所示。图1中横轴是以时间刻度为单位的时间轴;纵轴是DNS failure数据的瞬时强度,即单位时间粒度内到达的DNS failure报文的数目。如图所示,正常访问的DNS failure数量很少,而且DNS failure的爆发在短时间内发生。
根据6σ原理,当随机事件的发生服从正态分布时,其正态总体几乎总取值于区间(μ-3σ,μ+3σ)内,在此区间之外的取值概率为0.002 6,通常认为这种情况在一次实验中几乎不可能发生。上文中已说明DNS failure的发生可近似为正态分布,在保证正常DNS failure尽可能地落入正常区间的前提下定义:


图1 某主干网信道上的DNS failure变化曲线
为NDF异常的判断标准,其中i为DNS failure数据的瞬时强度,高出这一标准的概率仅为0.022 8。
依据异常标准对DNS数据进行检测和还原,可知道发生异常的DNS failure的有效信息,从而能够跟踪和识别僵尸网络等引起NDF的网络行为。
图1中期望Ε为211.542,标准差σ为468.855。A点高于Ε+2σ线,发生了NDF异常,下面将重点描述如何进行异常检测获得发生异常的场景信息(A点主要异常的域名,客户端IP)。
3 基于Counting Bloom Filter的DNS异常检测
本章将围绕带语义特征的可逆哈希函数展开,利用该函数将检测中聚类与还原两个重要环节紧密联系在一起。其中,key到value的映射过程用于聚类;其逆运算将用于还原。
3.1 hash聚类
hash函数作为一种简单的聚类方法,使不同类别的数据按照hash函数给定的规则聚集到不同的hash值上,该hash值即成为具有某个特性的流的聚类标签。这个以短标签替代长标签的过程,将原始数据的长流映射到很短的哈希串所在空间里,极大地减缩了存储代价和遍历查找等计算时间。Bloom Filter作为普通hash函数的变形,选用多个hash函数提高hash检验的精度。Counting Bloom Filter则将Bloom Filter位数组的每一位扩展为计数器,以支持聚类过程中对某类元素的个数统计。
标准Counting Bloom Filter(Bloom Filter)的hash聚类有两个局限:一是所有的聚类对象被多个hash函数映射到同一哈希空间中,不可避免的内部冲突影响聚类结果的准确性;二是对映射结果均匀分布(为减小不同对象间的冲突)的期望,不仅加大了hash函数的选取难度,也不利于hash串的逆向还原。为了能在显著降低普通Counting Bloom Filter错误肯定率(False Positive Rate,FPR)的前提下还原hash串,本文扩展了Counting Bloom Filter的应用。
首先为每个hash函数准备独立的存储空间,这样虽然不能消除多个不同源串被哈希至同一位置的外部冲突,但杜绝了不同hash函数映射结果相同的内部冲突;其次选用一些直接取源串中的部分重叠比特的hash函数,不仅非常简单,对源串的还原也有很大的益处。这里就此两点进行细述:
DNS域名长度应在255个字符范围之内,如何在有限的空间内标识一个唯一的域名,这在域名聚类前必须要考虑。实践表明,取域名前13个不包括“.”的字符(若域名本身长度不足,可小于13),能很好地兼顾聚类结果的精度及存储开销。如将“ftp.cn.playsafe.com.tw”中的ftpcnplaysafe作为源串,用12个独立的hash函数分别依次按字符重叠取出不同的两个字符(ft,tp,pc,…,af,fe)的比特串;对于拆解后的多对短串,以第一个字符对应的二进制数为高8位,第二个字符对应的比特值为低8位,经过按位与运算得到索引,并在索引对应的哈希空间中计算该短串在数据流中的出现次数(hits)。图2给出了域名的聚类过程。

图2 域名的聚类过程
而对于IP地址,三个hash函数直接映射IP地址的高16 bit、中间16 bit以及低16 bit,具体聚类步骤如图3所示。
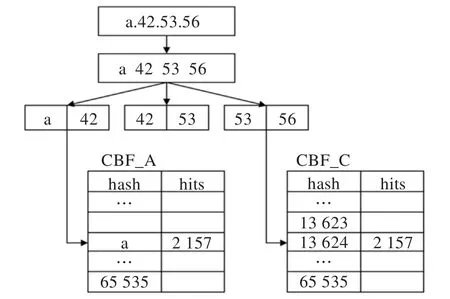
图3 IP地址的聚类过程
不同的hash索引对应着不同短串的出现次数,通过对域名和IP的hash聚类,不同源串中相同的短串自然地聚集在了一起;多个哈希空间的并行映射使得FPR减小了许多;但因域名字符的种类限制,以及IPv4地址的特定范围,使得哈希后的值集中于哈希空间的某一区间。对于此类使用独立哈希空间、非均匀Counting Bloom Filter的FPR及误差分析,文献[6]有详细报道,此处不再赘述。
3.2 源串还原
上节中精心挑选的hash函数,让还原过程变得非常简单。如果能够确定两个hash串出自同一个源串,那么就可以通过字符拼接来最大可能地恢复源串的全貌。根据上节的分析,这里提出三条同源性判断的依据:
(1)字符语义;
(2)若短串ab的hits值为N,短串bc若与ab同源,那么它的hits值至少为N;
(3)hash短串的hits值大于或等于其源串的出现次数。
3.3 还原算法
考虑到检测时间内的某点发生NDF异常由该点对应时间内的少数高频度异常DNS访问贡献,因此只需对各哈希空间TopN的短串进行同源性判断,再通过拼接复原即可得到异常域名和IP的具体信息。
基于以上分析,本文给出域名源串还原算法(IP地址的还原算法与此类似,不同之处在于IP地址的前缀聚类可用于蠕虫扩散、路由循环等异常的检测,相关分析可见文献[7]):

3.4 算法复杂度对比
以异常客户端IP地址的检测为例,将改进的Counting Bloom Filter算法与单哈希(32 bit)、单哈希+链表以及map三种常规实现“算法”进行比较,如表2。

表2 复杂度对比
对表2的几点说明:
(1)Counting Bloom Filter算法的主要计算是排序获得Top N,而借助于比较进行的排序在最坏情况下能达到的最好时间复杂度为O(N lbN)。对hash空间的访问开销为O(1),在对IP进行检测的过程中,直接映射IP其中的16 bit,设映射空间的大小为M,则M=216。该算法的空间复杂度为O(M+N),时间复杂度为O(M+N lbN),由于N远小于M,所以两者均近似为O(M)。
(2)单哈希算法预先分配固定大小的哈希数组,映射空间内可以是对IP地址的计数或存放完整的IP地址(32 bit),前者不便于可逆还原,后者占用4 GB的存储空间。对hash空间的访问为O(1);若直接存储IP地址,则映射空间的大小M′是上一条中M的两倍。
(3)单哈希与链表的组合,是由链表存储原始的IP地址,而哈希表中存放指向链表的指针。M″是对链表访问所花费的开销,空间复杂度由指针本身的存储空间Mp以及平均每个链表所占用的空间Mlist决定,n是数据流中的IP数。
(4)C++的STL默认使用树结构来实现map,在一次树查找中,最坏情况下的复杂度为O(lbn),另外还需考虑查找过程中一些函数的调用。空间上,主要是存储n个IP地址值和map容器自身的开销Mmap。
当这些方法应用于高速大规模网络环境中(即n非常大时),改进的Counting Bloom Filter算法的优势会非常明显,尤其在异常域名的检测上。
4 实验与结果分析
本节对基于Counting Bloom Filter的检测方法进行了实现,实验所用的数据取自某主干网5月19日10:00至20:00共10个小时的DNS数据,具体DNS failure的变化曲线如图1所示。下面通过表格说明图1中的A点(12:20—12:25)异常的检测过程(为节省篇幅,表3和表4仅列出Counting Bloom Filter空间的Top 5,实际实验时取Top 10)。

表3 域名的Counting Bloom Filter空间Top 5

表4 客户端IP的Counting Bloom Filter空间Top 5
参考同源性判断的三条依据,拼接表3和表4中的短串,得到异常域名和客户端IP的列表,如表5、6。
根据第2章E为211.542,σ为468.855可知此次检测中NDF的判断标准E+2σ=1 149.251。在表5与表6中,域名“ftp.cn.playsafe.com.tw”和“ftp.playsafe.com.tw”以及客户端IP“a.42.53.56”的瞬时强度(hits值)均符合这一标准。关联三者可进一步看出A点的爆发异常的主要原因是IP地址a.42.53.56对域名ftp.cn.playsafe.com.tw和ftp.playsafe.com.tw的爆发访问。

表5 异常域名

表6 异常客户端IP
5 结论
本文以DNS failure为切入点,提出了一种基于Counting Bloom Filter的DNS异常检测方法——在选取多个有独立空间和语义特征的哈希函数保障不同的hash代表的语义间不会产生冲突之后,根据同源判断和Top N的结果拼接出频度上异常的域名和IP源串。借助该方法,能够快速从真实的高速大规模主干网数据中发现异常DNS行为,确诊这些异常的具体类型将是下一步的研究方向。
[1] 丁森林,吴军,毛伟.利用熵检测DNS异常[J].计算机系统应用,2010,19(12):195-198.
[2] Yadav S,Reddy N.Winning with DNS failures:strategies forfasterbotnetdetection[C]//SecurityandPrivacyin Communication Networks,2011.
[3] Jiang N,Gao J,Lin Y,et al.Identifying suspicious activities through DNS failure graph analysis[C]//IEEE International Conference on Computer Communications,2011.
[4] 程光,龚俭.互联网流测量[M].南京:东南大学出版社,2008.
[5] Zhu Z S,Yegneswaran V,Chen Y.Using failure informationanalysistodetectenterprisezombies[C]//Security and Privacy in Communication Networks,2009.
[6] 彭艳兵,龚俭,刘卫江,等.Bloom Filter哈希空间的元素还原[J].电子学报,2006,34(5):822-827.
[7] 龚俭,彭艳兵,杨望,等.基于Bloom Filter的大规模异常TCP连接参数再现方法[J].软件学报,2006,17(3):434-444.
