基于标签与协同过滤算法的淘书吧应用
2014-01-15张建明
徐 彬,张建明
(江苏大学 江苏 镇江 212013)
协同过滤(Collaborative Filtering,CF)由 Goldberg 等人[1]在1992年提出并首次应用在研究邮件推荐模型Tapestry中。协同过滤推荐算法的核心思想是利用用户的历史信息,计算用户之间的相似性;利用与目标用户相似性较高的用户对其他产品的评价来预测目标用户对特定产品的喜好程度;根据喜好程度来对目标用户进行推荐。协同过滤又可分为两种:基于用户的协同过滤和基于商品的协同过滤。协同过滤算法的基本思想是找到与该用户行为最相似的其他用户,通过其他用户的行为来预测该用户的行为,并提出了k最近邻的思想[2]。本文还将标签属性加入到推荐算法中,将具有相同标签的书籍进行分类,使得内容之间的相关性和用户之间的交互性大大增强[3]。协同过滤方法已成为电子商务中非常重要的一种推荐方法。国外用到协同过滤方法比较著名的网站有亚马逊的网络书店,通过记录购买的商品以及对商品的评分还有浏览过的商品来判断您的兴趣,然后与其他用户的购买行为进行比较,从而进行相似度的分析,最后推荐商品。而国内比较著名的有淘宝,当当,京东商城。他们利用改良后的协同过滤算法,将一系列可能满足要求的商品推荐给用户,以便用户的筛选,将用户体验做到极致,为网站带来了大量的流量。原有的协同过滤只依赖于用户对项目的评分矩阵,对于各种特定的应用都有较好的适用性,但它也存在一些难以完全解决的问题,如新用户问题、数据稀疏性问题及可信问题等[4]。
文中提出了一种将标签集成到推荐系统的方法,首先对标签进行预处理,然后构建用户-商品评分矩阵,最后将标签混合至用户-商品评分矩阵的协同过滤推荐算法中。本文的贡献如下:1)提出了通用的标签预处理方法;2)通过标签预处理减少推荐过程中同义标签的计算,从而提高了推荐算法的性能;3)提出了一种改良后的协同过滤方法,该方法可以利用用户、产品和标签之间的三维关系,提高推荐系统的准确性。
1 基于标签的协同过滤推荐算法
1.1 算法描述
1)根据用户对商品的评分,建立用户-商品评分矩阵。
2)对标签进行预处理,整理商品与标签之间的关系。
3)根据商品-标签的评分矩阵来计算商品之间的相似度,确定商品的最近邻,建立物品的协同过滤评分矩阵。
4)综合商品-标签评分矩阵和协同过滤方法来计算预测评分值。
5)按照排名先后将评分值最高的N个商品推荐给用户。
1.2 用户-商品评分矩阵C(m,n)
在矩阵C(m,n)中,其中m行代表m个用户,n列代表n个评分商品,元素Cij表示用户i对商品j的评分。该方法中用1,2,3,4,5离散值表示对该商品的偏爱度。值越大表示用户喜爱程度越高。
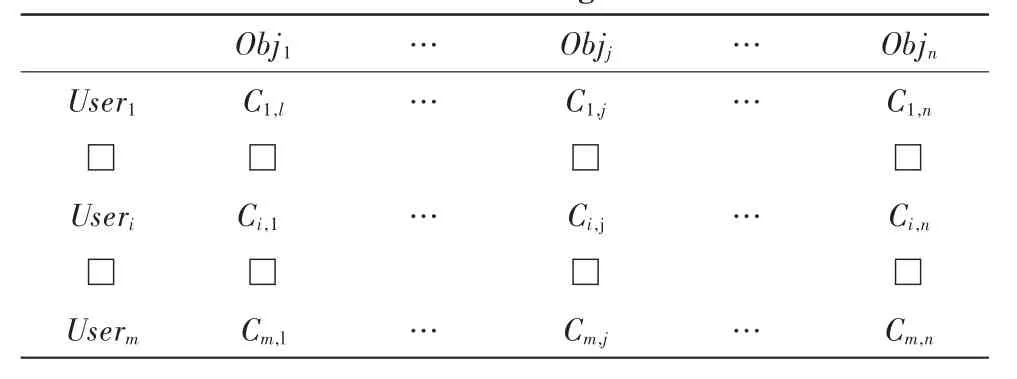
表1 用户评分矩阵Tab.1 User rating matrix
1.3 商品-标签评分矩阵
1.3.1 标签处理
不同类型的商品通过分类将其区别。相同分类下的商品,我们通过设定不同的标签,将有联系的主从关系的商品联系在一起。同一种商品可以使用多个标签,同一个标签也可以使用多个商品。商品和标签之间是多对多的关系。我们通过这种复杂的关系,再结合用户浏览和购买过的商品所属的标签。这很少一部分的标签是频繁用到的,而这些少量频繁标签集合也是稳定的[5]。根据用户与标签的关系,将用户—标签构成一个二部图,如图1所示。本系统使用SimRank算法计算商品之间的相似度。
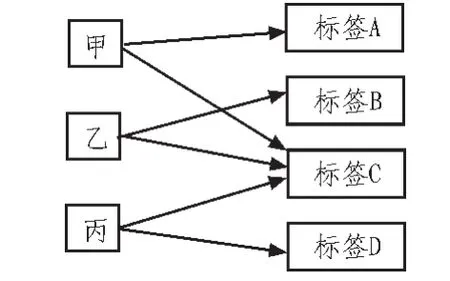
图1 用户标签二部图Fig.1 User tags bipartite graph
SimRank算法是在2002年提出的,为了衡量结构性上下文(structural-context)的相似性[6]。SimRank算法的根本就是:相似与同一个物品的两个或两个以上物品之间也存在相似性。
基于SimRank算法,我们假定:如果相同或相似的标签都适用于两个用户,则这两个用户就存在相似性。构造如图1,标签集合NT和用户集合NU,如果用户甲和标签A之间存在联系,则用有向线段连接用户甲与标签A。它们之间的相似性按如下公式计算:
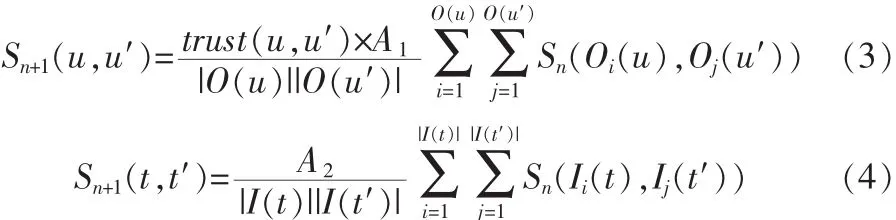
公式中:u′∈Ut,trust(u,u′)表示用户 u 与 u′的信任度;O(u)表示用户u的出邻居集合,即由u出发所指向的标签集合;n 是迭代的次数;|O(u)|表示用户 u 的出邻居数;A1,A2为常数,在0~1之间。
1.3.2 综合相似度计算
基于传统的协同过滤方法,要求每个商品的详细评分数据。但客观条件决定了用户不可能对每个商品都进行评分。这就造成了商品的评分信息不够全面,导致了评分矩阵稀疏,在该矩阵上产生的推荐,会有较大的误差,对推荐的准确度也会产生比较大的影响。而基于商品标签的协同过滤方法,弥补了单一评分矩阵稀疏的问题。常用的用户相似度计算方法有余弦相似性、修正余弦相似性、皮尔森相似性。本文采用皮尔森相似性作为相似度度量标准,将商品的评分相似度和标签相似度加权得到综合相似度:
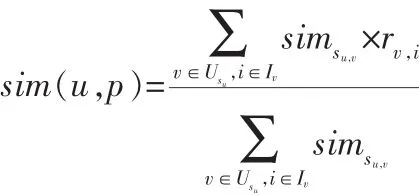
根据公式计算预测评分,将评分最高的Ns个项目生成推荐集Cs。对目标用户u进行预测评分,simsu,v是社交网络下经过SimRank算法迭代得到的用户u和v的相似性Sn(u,v)。将得到预测评分记为sim(u,p),并将评分最高的Cs作为推荐结果。
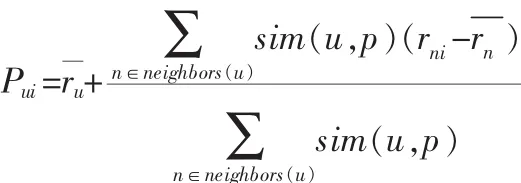
其中,neighbors(u)是评价过的商品i,且与用户u最相似的n个用户的集合。
此方法预测用户u对于所有未评分商品的评分值,取预测评分值最高的N个商品推荐给用户u。
2 实验结果与分析
为验证基于标签协同过滤算法的有效性,取豆瓣站点(www.douban.com)的数据集进行实验,该站点用户可以自由发表有关书籍、电影、音乐的评论,可以自动进行推荐。展现在用户面前的大部分内容,都是基于每个用户的特点自动生成的。我们从该站点得到实验数据集(包括65171个用户和其标签过的图书)。实验数据集分为训练集和测试集,其中训练集占90%,测试集占10%。
2.1 结果评价
本文使用平均绝对误差 (Mean Absolute Error,MAE)来评价推荐系统的精确性。MAE通过计算项目的实际评分与预测评分之间的偏差来计算预测的准确性。MAE越小,推荐系统的准确度越高[7]。MAE公式如下:
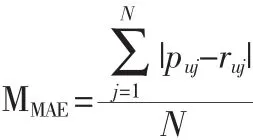
其中,ruj为用户的实际评分;puj为用户的预测评分;N为预测的项目个数。
2.2 实验结果
为检验本文提出的基于标签-协同过滤方法的有效性,本文参照传统的协同过滤方法,在最近邻居个数取值不同的时候,对比2种方法MAE的变化情况。实验数据以下表所示,分别计算平均绝对误差,结果如图2所示。
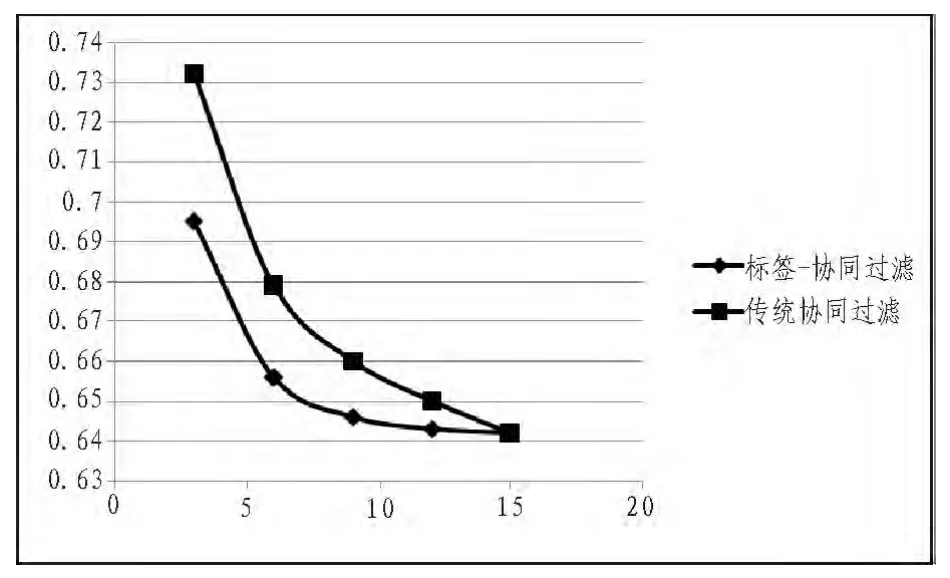
图2 绝对评价误差Fig.2 Absolute evaluation errors
由图2可知,对比传统的协同过滤方法,本文提出的标签-协同过滤方法在同等条件下的MAE值更小,精确度更高。因此,将标签信息和协同过滤方法相结合,可提高推荐系统的准确度。
3 结束语
本文使用的协同过滤推荐算法加入了标签属性。在原有的协同过滤算法的基础上,通过标签更加精确了算法的推荐程度。并通过实验数据,客观的证明了该方法能够在一定程度上提高了推荐质量。
在以后的研究中,我们还要加强对近义词,反义词标签的处理。并且结合用户的检索,用户的购买时间,进一步提高相似度的计算,为用户推荐更加精准的产品。
[1]Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[2]Herlocker J L,Konstan J A,Borchers A,et al.An algorithmic framework for performing collaborative filtering.Proc of the 22nd Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval[M].New York:ACM,1999:230-237.
[3]踏莎而行.小Tag有大智慧[J].电子商务世界,2006(5):84-85.Lufthansa riding the line.Small Tag with great wisdom[J].Ecommerce World,2006(5):84-85.
[4]Chetto H,Chetto M.Some result of the earliest deadline scheduling algorithm [J].IEEE Trans on Parallel and Distributed Systems,1989,15(10):1261-1269.
[5]徐雁斐,张亮,刘炜.基于协同标记的个性化推荐[J].计算机应用与软件,2008,25(1):9-13.XU Yan-fei,ZHANG Liang,LIU Wei.Recommended based on collaborative personalized tag[J].Computer Applications and Software,2008,25(1):9-13.
[6]Jeh G,Widom J.SimRank:a measure of structural context similarity [C]//Proc of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM Press,2002:538-543.
[7]陈志敏,沈洁,赵耀.基于相关均值的协同过滤推荐算法[J].计算机工程,2009,35(22):53-55.CHEN Zhi-min,SHEN Jie,ZHAO Yao.Related to the meanbased collaborative filtering recommendation algorithm[J].Computer Engineering,2009,35(22):53-55.
