基于FCA的领域问句相似度计算方法
2014-01-14万庆生黄少滨刘刚陆路
万庆生,黄少滨,刘刚,陆路
(哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001)
基于FCA的领域问句相似度计算方法
万庆生,黄少滨,刘刚*,陆路
(哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001)
文章提出一种基于形式概念分析的领域问句相似度计算方法,该方法不仅考虑了问句的语义与语法结构,更主要的是利用形式概念分析方法提取和建立领域概念集,是一种新的计算领域问句相似度计算模型。通过形式概念分析构建领域知识概念集,概念集以概念格形式进行组织。将问句相似度计算转换成概念集的相似度计算。试验结果表明,使用该方法的相似度计算准确率约为84%,并在有噪声的情况下依然保持高准确率。
式概念分析;概念格;问句;相似度
在基于问答对的问答系统中,问句相似度计算直接影响问答系统检索结果的准确率。目前,国内外对问句相似度计算方法已有大量研究,其中大部分问句相似度计算方法采用的是自然语言处理中的句子相似度计算方法。已有许多句子相似度计算的方法,如基于编辑距离的方法[1]、基于语义计算的方法[2]、基于语义依存的方法[3]、基于骨架依存树的方法[4]、TF-IDF(Term Frequency-In⁃verse Document Frequency)方法[5]等。这些方法多数基于向量空间模型,也有采用句法分析和语义分析。由于问句相似是指问句答案的相似这一特点,句子相似度计算方法并不完全适用于问句相似度计算。
在实际应用中,仅通过问句语义和语法相似度衡量问句相似度,并不能取得很好效果。
本文提出一种基于形式概念分析的问句相似度计算方法,该方法不仅考虑问句的语法与语义结构,更主要的是利用形式概念分析方法提取和建立领域概念集,通过构建领域概念格和提出概念集相似度计算方法,提高领域问句相似度计算的准确率。
本文提出基于领域问题相似度计算方法,能很好得解决上述情况下的相似度计算问题。最后利用社保中的五险(养老保险、医疗保险、工伤保险、失业保险和生育保险)领域问题集进行试验,并取得很好效果。
1 相关知识
1.1 基于形式概念分析的概念格相关理论
20世纪80年代德国达姆施塔特科技大学的Wille教授以形式概念分析(Formal Concept Analy⁃sis,FCA)重构格理论(Lattice T heory)[6],形式概念分析和基于形式概念分析的概念格相关理论与技术,作为数据分析研究领域的重要方法和手段,逐渐受到国际学术界的广泛关注[7]。概念格也随之由Wille首先提出。概念格的每个节点是一个形式概念,由外延和内涵两部分组成。外延指概念所覆盖的实例。内涵指概念的描述,该概念覆盖实例的共同特征。概念格的构建过程从本质上说是概念的聚类过程。概念和概念之间的泛化和例化关系,可以用一个Hasse图来表示。通过Hasse图,可直观看出整个概念格的层次结构。
关于形式概念分析和概念格详细介绍可参考文献[8-10]。形式概念(Formal Concept)与形式背景(Formal Context)是支撑形式概念分析的两大理论基础。在Wille和Ganter的阐述中,有相关内容定义如下:
定义1一个形式背景K=(U,A,R)由对象集合U和属性集合A以及U和A的二元关系R组成。其中U称为形式对象,A称为形式属性。记作(u,a)∈R或uRa,指对象u具有属性a。
形式背景K可看成如表1所示的一张二维关系表。一个元组代表一个对象,列代表属性集合,如果uRa,则在元组u的a列上进行标记。表1说明对象1具有属性b、c和d,对象3具有属性a、c、d和e。

表1 形式背景的二维关系表Table 1 Relation table of formal context
在形式背景K中,在U的幂集M(U)和A的幂集M(A)间可定义两个映射f和g如下:

其被称为U的幂集和A的幂集之间的Galois联接。如果二元组,满足条件U1=g(A1)和A1=f(U1),则被称为形式背景K的一个形式概念。所以,一个概念C为一个二元组(U1,A1),其中U1称为概念C的外延,A1称为概念C的内涵。如图1所示,描述形式概念在具体应用中的形式。
定义2形式背景K下的所有形式概念记为C(K),给定形式概念(U1,A1)和(U2,A2),如果U1⊂U2(等价于A2⊂A1)则称形式概念(U1,A1)是(U2,A2)的后继,相反(U2,A2)是(U1,A1)的前驱。
概念的前驱后继关系相对应于概念的泛化与细化关系。而这种前驱后继关系满足自反性、反对称性和传递性,因此前驱后继关系是形式背景K上的偏序关系。通过这种关系等到1个偏序集(C(K),≤),并且偏序集(C(K),≤)是1个完全格,称为形式背景K的概念格,记为L(K)。且L(K)可通过Hasse图来直观地描绘L(K)的层次结构。图2为形式背景如表1所示下的概念格的Hasse图。

图1 形式概念结构Fig.1The structure of formal concept
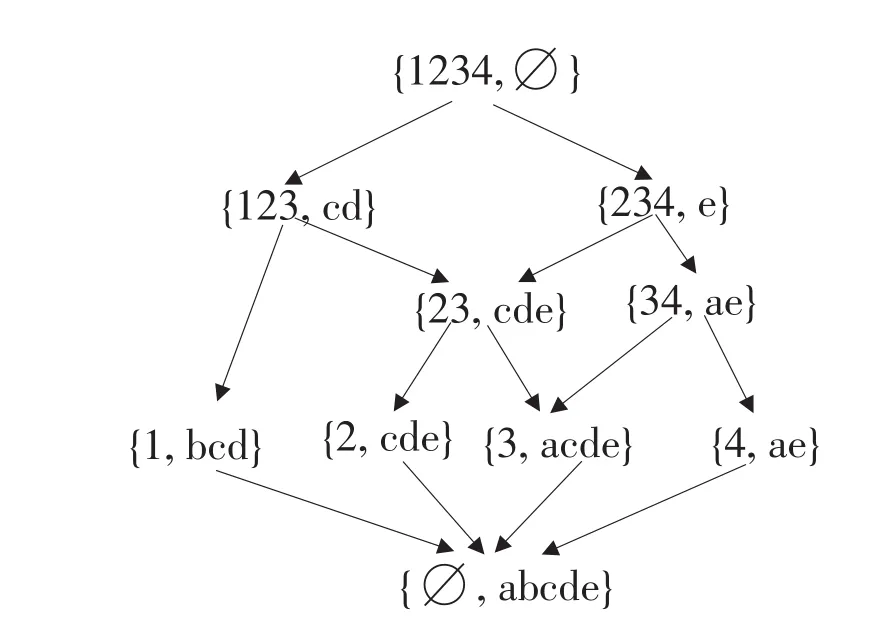
图2 形式背景K下的概念格Fig.2 The concept lattice of formal context K
1.2 概念格构造算法
概念格是以数学的序理论和完全格理论为数学基础,描述概念和概念间的层次关系。构造概念格的本质就是对概念进行聚类。对于同样的形式背景,最终形成的概念格结构是唯一的。概念格包括概念和概念间的层次关系,因此所有构造算法必然需要生成所有概念和所有概念之间的层次关系。
渐进式构造算法和批处理算法使用完全不同的基本思想。批处理算法主要包括构造形式概念集和构造概念层次关系两个任务,大多数都属于任务分割生成模型,只有少部分是属于任务交叉生成模型。渐进式构造算法则是同时进行生成概念和构造概念层次关系两个任务,在生成概念的同时,更新概念格直接的层次关系。由于渐进式构造算法支持动态添加新概念,适合实际的使用需求并且有优越的时间性能。因此,本文中使用Godin算法构造概念格。关于Godin算法的具体理论证明与细节可参考文献[11-12]。
2 相似度计算
经过形式概念分析后,可以得到一个领域概念格L(K),概念格中的每个节点为一个形式概念。L(K)实际是一个以完全格为组织形式的领域概念集。领域概念集是进行问句相似度计算的基础。问句文本首先经过语义分析、词性标注和分词,得到由关键词组成的问句向量V=
2.1 概念向量提取算法
在概念形式分析中,虽然不涉及向量,但是可以把一个向量看成一个对象。一个向量V=
定义3对于对象O所具有的属性集A0,形式概念C1=(U1,A1),如果A1⊆A0,则称对象O覆盖形式概念C1=(U1,A1),记作O∠C1。对于形式概念C1=(U1,A1)和形式概念C2=(U2,A2),如果A1⊆A≡,则称形式概念C2=(U2,A2)覆盖形式概念C1=(U1,A1),记作C2∠C1。
定义4:Cc(O)={Ci|O∠Ci,Ci∈L(K)},即Cc(O)为对象O在L(K)上覆盖的概念的集合。Cc(O)={Ci|∃Cj(Cj∠Ci,Ci∈CC(O),CiCC(O)},即CC(O)为对象O在L(K)上覆盖的最大概念集合。
概念向量提取是指给定一个对象O和一个概念格L(K),求集合CC(O)的过程。本文提出一种求集合CC(O)的概念向量提取算法(Concept Cover)。算法的主要思想是从L(K)的最小下界L∨开始进行深度优先搜索,检查当前格节点是否被对象覆盖,如果被覆盖则将节点添加到概念集合中,并返回。由定义2有(U1,A1)≥(U2,A2)A1⊂A2,所以O∠⇒C2O∠C1,即如果对象O覆盖概念C,那么概念C的前驱节点也被对象O所覆盖。因此,当搜索到O∠C1后如果继续搜索,那么得到的概念集合即为Cc(O),如果停止当前路径的搜索,那么得到的概念集合即为CC(O)。概念向量提取算法(Concept Cover算法)的伪代码如下所示。

Call Find Concept:L,O,L∨,Clist{以概念格L,问句对象O,格L的最小下界L∨,存储提取的概念向量容器Clist为参数,调用Find Concept算法}


Concept Cover算法是1个在概念格L(K)中自底向上深搜过程,并且每个节只访问1次。因此该算法的时间复杂度为O(n),n为概念格中节点个数。
2.2 概念向量相似度计算方法
经过概念向量提取,一个问题对象O被转换成一个概念集CC(O)。一个概念向量V=
概念集之间的相似度计算依赖于集合元素间的相似度计算,即形式概念间相似度的计算。目前,国内外学者提出不少在概念格中形式概念的相似度计算方法。其中文献[11]中提出一种基于领域本体相似图(similarity graph)的计算形式概念相似度方法。其中基于领域本体的相似图本质上是一个本体之间相似度的二维矩阵。文献上形式概念中的属性是本体,本文提出的方法中是词语,因此基于领域本体相似度图在本文中就是一个词语之间相似度的二维矩阵。这个矩阵可用前面提到的基于《知网》的语义相似度方法得到。下面给出关于形式概念相似度计算的相关定义,关于详细内容可参考文献[12]。
定义5考虑两个在L(K)形式概念(U1,A1)和(U2,A2),n=|A1|,m=|A2|,假定n≤m,集合η(A1,A2)为任意A1和A2元素间的n对匹配。定义如下:η(A1,A2)={{
进而提出形式概念的相似度计算方法,如下:

其中as(a,b)为计算a和b的语义相似度结果,n如定义5中所示。
w是一个0到1之间的参数,用以调节形式概念中对象集和属性集对相似度计算影响的权重。形式概念中的对象集和属性集满足2.1小节描述的f和g的映射关系,所以对象集和属性集是对偶关系,因此,w一般设置为0.5。Sim((U1,A1),(U2,A2))的值域为[0,1],值越大,表明形式背景(U1,A1)和(U2,A2)的相似度越高。
考虑概念集O1={a1,a2…an}和概念集O2={b1,b2…bn},ai,bjL(K),i=1…n,j=1…m那么概念集之间的相似度计算公式为:

其中n是集合O1的元素个数,m是集合O2的元素个数。公式(2)求的是集合间元素相似度的加权平均值。Sim(O1,O2)的值域为[0,1],值越大,表明两个集合越相似。
3 试验评估
3.1 试验数据和试验方法
本文选择社保中关于五险的问题集进行试验。社保中五险包括养老保险、医疗保险、工伤保险、失业保险和生育保险。问题集是从公民在网上提出的关于五险的并且频率较高的问题中筛选出的45个问题。试验的问题集来至于公民日常生活所遇到的关于五险的真实问题,用此进行试验具有实际意义。其中,关于每类保险的问题数量是8到10个不等。对于每个问题,都通过人为挑选出与其相似度较高的8到10个问题,也称为相关问题。并通过不断添加领域外的问题数量(噪声),分别使用编辑距离、TF-IDF、基于语义依存方法和本文提出的方法进行相似度计算,并进行准确率和召回率的统计。通过试验分析四种方法在不同的噪声比例中的实际效果。噪声比是指社保领域外的问题数(噪声数量)除以45(社保领域内的45个问题)。在试验中取相似度最高的前k个问题作为检索结果,且取k等于相关问题数,因此准确率与召回率相等,以下只对准确率进行统计。准确率(Precision)的计算方法如下定义:
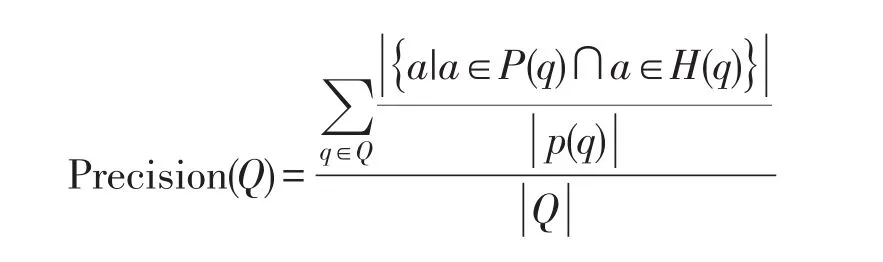
其中Q为问题集,P(q)为人为选出与问题q相似的问题集,H(q)是利用算法求出与问题q相似的问题集。
3.2 试验结果及分析
图3是在噪声比分别为0、20%、40%、60%、80%和100%情况下4种方法的准确率比较图。

图3 不同噪声比准确率对比Fig.3 Comparision of accuracy at different noise ratios
由图3可知,本文提出的方法在无噪声数据情况下,准确率可达83.84%,而编辑距离、IF-IDF和基于语义依存方法的准确率分别为71.76%、73%和76.2%。本文方法的相似度计算准确率明显优于前3种方法。随着噪声比的增大,四种方法的准确率都有所下降,并且在噪声较大时(80%),准确率都有明显下降。但是本文提出的方法始终保持较高准确率,在噪声比高达100%时,准确率仍有71.36%。其他3种方法并不基于领域知识,没有区分领域问题的能力,因此准确率会随噪声比的增大而不断下降。
本文提出的方法依赖领域知识,在噪声比较小情况下能保持高准确率。当噪声比较大时,由于本文试验所用的领域知识只是五险领域的部分法律法规,知识覆盖面较小,覆盖的领域知识不全,抽取的领域概念的粒度较大,对噪声的区分能力有所下降,导致准确率降低。但是可通过健全领域知识来改善高噪声下的准确率。
3.2.1 与编辑距离方法对比试验结果
图4是噪声比例分别为0%、20%、40%、60%、80%和100%的情况下,编辑距离和本文方法对于每个问题的准确率对比图。对于某个问题,长条高于曲线说明编辑距离方法对于这个问题的准确率高于本文方法,反之亦然。
由图4可知,本文方法的准确率明显高于编辑距离方法,并表现更为稳定。随着噪声比的增大,编辑距离方法对于各问题的准确率浮动较大,准确率也比较低。编辑距离方法通过计算两个句子的编辑距离衡量两个句子的相似度。通过引入HowNet和《同义词词林》对其进行改进[1]。这种方法对句子的结构和词语出现的次序依赖性很强,此方法不能有效处理两句意思相近但结构和用词不同的句子。这是导致编辑距离方法准确率低,且对噪声很敏感的原因。
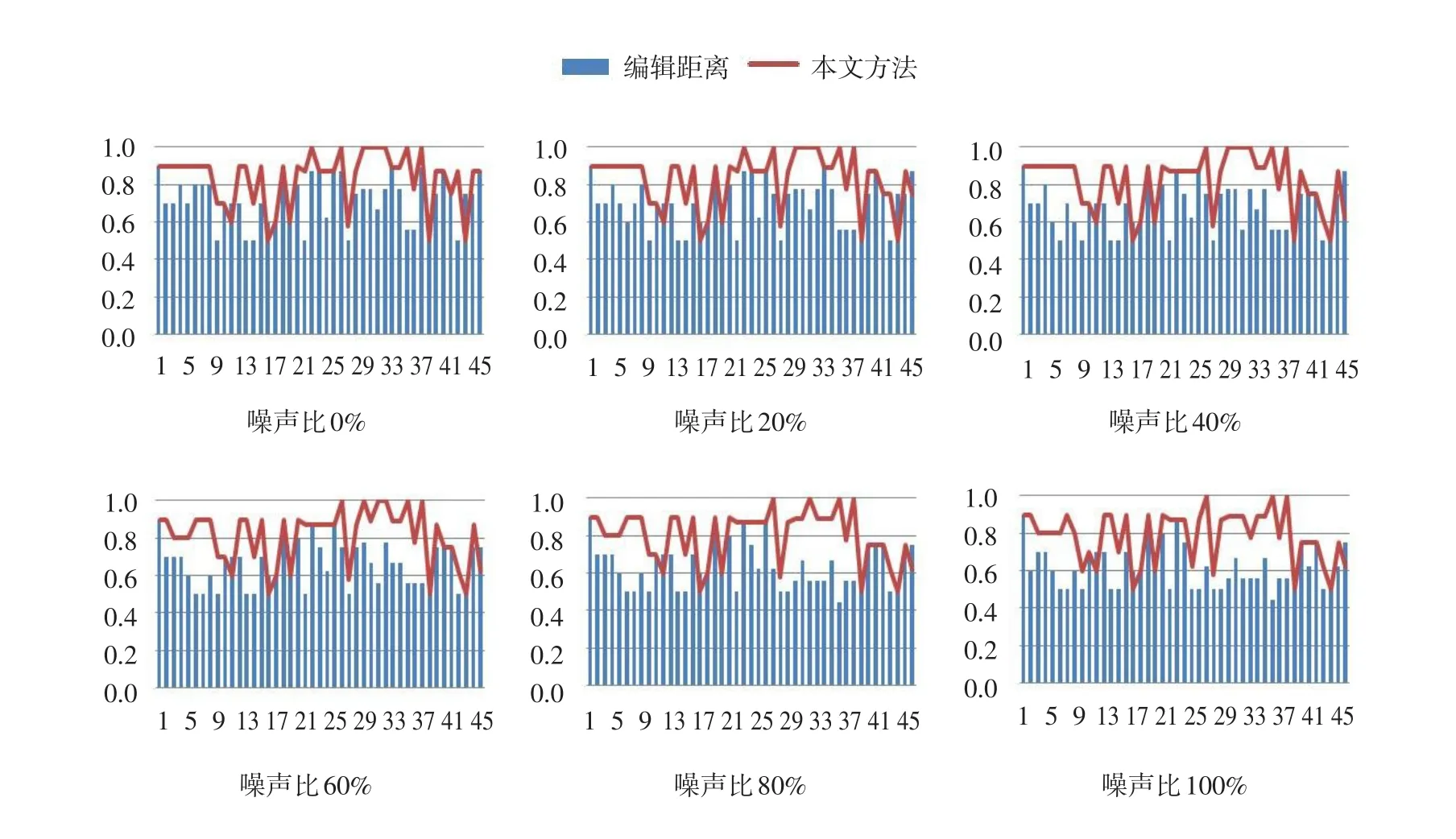
图4 不同噪声比下编辑距离与本文方法准确率对比Fig.4 Comparision of accuracy between edit distance and this method at differenct noise ratios
3.2.2 与TF-IDF方法对比试验结果
图5是噪声比分别为0%、20%、40%、60%、80%和100%的情况下,TF-IDF和本文方法对于每个问题的准确率对比图。图中曲线是本文方法的准确率曲线,柱状图是TF-IDF的准确率。对于某个问题,长条高于曲线说明TF-IDF方法对于这个问题的准确率高于本文方法,反之亦然。
由图5可知,本文方法的准确率明显高于TFIDF方法,并表现更为稳定。在噪声比为0%时,TF-IDF方法大多数问题的准确率明显低于本文方法的准确率。随噪声比增大,TF-IDF方法的对于各问题的准确率趋于平稳,但普遍较低。这是由于TF-IDF方法缺乏对噪声的识别能力,导致准确率普遍较低。TF-IDF方法对于特征词的加权是静态的,即每个特征词的权重固定不变,但是很多情况下每个特征词的权重不是固定不变的,且可能有很大差异,如引言中所述。在本文提出的方法中,特征词随组合不同,所表现的重要性也不同。本文方法具备噪声的识别能力,但依赖于领域知识,由于领域知识不够全面,使得某些问题的准确率波动较大,但能保持较高的准确率。随着噪声比增大,TF-IDF方法准确率高于本文方法准确率的问题越来越少,表现出在高噪声比情况下本文方法的明显优势。
3.2.3 与语义依存方法对比试验结果
图6是噪声比例分别为0%、20%、40%、60%、80%和100%的情况下,基于语义依存方法和本文方法对于每个问题的准确率对比图。图中曲线是本文方法的准确率曲线,柱状图是基于语义依存方法的准确率。对于某个问题,长条高于曲线说明基于语义依存方法对于这个问题的准确率高于本文方法的准确率,反之亦然。

图5 不同噪声比下TF-IDF与本文方法准确率对比Fig.5 Comparision of accuracy between TF-IDF and this method at different noise ratios
由图6可知,本文方法的准确率明显高于语义依存方法的准确率,并表现更为稳定。语义依存方法的准确率较高,但随着噪声比的增大。波动较大。语义依存方法的对于每个问题的准确率很不稳定,高低起伏较大,最高达90%,同时最低只有37.5%。语义依存方法是基于句子的依存结构进行相似度计算的。对于每个句子,提取核心词和直接依存于其的有效词组成搭配,通过计算搭配的相似度来计算句子相似度,具体细节可参见文献[3]。
语义依存方法很大程度依赖两个句子的核心词的语义相似程度。当两个句子的核心词语义相差较大时,相似度相应较低。导致准确率很不稳定,随着噪声比增大越明显。
本文方法在计算领域问句相似度上明显优于编辑距离方法、TF-IDF方法和基于语义依存方法,并可通过健全领域知识来进一步提高准确率和降低对噪声的敏感度。

图6 不同噪声比下语义依存方法与本文方法准确率对比Fig.6 Comparision of accuracy between semantic dependency and this method at different noise ratios
4 结论
本文提出一种基于形式概念分析的领域问答系统中的问句相似度计算方法。通过构建领域概念格和提出概念集相似度计算方法提高领域问句相似度计算的准确率。给出一种新的领域问句相似度计算的模型,不同于以往基于语义和语法分析以及统计方法的句子相似度计算方法。本文方法准确率有所提高,并可通过健全领域知识进一步提高准确率。
[1]车万翔,刘挺,秦兵,等.基于改进编辑距离的中文相似句子检索[J].高技术通讯,2004(7):152.
[2]李素建.基于语义计算的语句相关度研究[J].计算机工程与应用,2002(7):219.
[3]李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2003,20(12):15-17.
[4]穗志方,俞士汶.基于骨架依存树的语句相似度计算模型[C].北京:中文信息处理国际会议,1998.
[5]罗欣,夏德麟,晏蒲柳.基于词频差异的特征选取及改进的TF-IDF公式[J].计算机应用,2005,25(9):29.
[6]Wille R.Restructuring lattice theory:An approach based on hier⁃archies of concept[C].Droceedings of the 7th International Confer⁃ence on Formal Concept Analysis.Berlin:Springer-Verlag,2009: 314-339.
[7]毕强,滕广青.国外形式概念分析与概念格理论应用研究的前沿进展及热点分析[J].现代图书情报技术,2010(11):12.
[8]Ganter B,Wille R.Formal concept analysis:Mathematical founda⁃tions[M].Berlin:Springer,1999.
[9]韩道军.Godin算法的改进和FCA在智能搜索引擎中的应用[D].郑州:河南大学,2005.
[10]Godin R,Missaoui R,Alaoui H.Incremental concept formation al⁃gorithms based on Galois(concept)lattices[J].Computational Intel⁃ligence,1995,11(2):246-267.
[11]Formica A,Missikoff M.Concept similarity in symontos:an enter⁃prise ontology management tool[J].Comput J,2002,45:24.
[12]Formica A.Ontology-based concept similarity in formal concept analysis[J].Information Sciences,2005,176(18):2624-2641.
Calculation method of domain question similarity based on FCA
WAN Qingsheng,HUANG Shaobin,LIU Gang,LU Lu(School of Couputer Science and Technology,Harbin Engineering University,Harbin 150001,China)
A domain question similarity calculation method was proposed based on formal concept analysis.This method not only considers the question of semantic and grammatical structure,but also uses the method of formal concept analysis to extract and build domain concept sets.It's a new model for computing the similarity of calculation questions.Concept sets of domain knowledge are built through formal concept analysis,and the concept sets are organized in the form of conceptual lattice.And then the similarity of questions can be transformed into the similarity of concept sets.Finally,the experiment results indicated that the accuracy of similarity calculation by using this method was about 84%,and it could maintain a high accuracy in the case of noise.
formal concept analysis;concept lattice;questions;similarity
TP315
A
1005-9369(2014)02-0103-08
2013-12-09
国家科技支撑计划项目(2012BAH08B02);中国博士后科学基金(2013M541345);哈尔滨工程大学中央高校基本科研业务专项资金项目(HEUCF100603,HEUCFZ 1212)
万庆生(1975-),男,博士研究生,研究方向为中文问答系统。E-mail:79863200@qq.com
*通讯作者:刘刚,副教授,研究方向为计算机应用。E-mail:liugang@hrbeu.edu.cn
时间2014-1-17 16:36:39[URL]http://www.cnki.net/kcms/detail/23.1391.S.20140117.1636.004.html
万庆生,黄少滨,刘刚,等.基于FCA的领域问句相似度计算方法[J].东北农业大学学报,2014,45(2):103-110.
Wan Qingsheng,Huang Shaobin,Liu Gang,et al.Calculation method of domain question similarity based on FCA[J].Journal of Northeast Agricultural University,2014,45(2):103-110.(in Chinese with English abstract)
