试析中国数字期刊利用统计指标的类型与功能*
2014-01-11刘丹
刘 丹
(南京大学信息管理学院 江苏南京 210093)
1 引言
20世纪90年代以来,数字资源在我国呈现出蓬勃的发展态势,数字期刊更是凭借其单篇文章的零散化使用优势受到用户的广泛青睐,据最新发布的《2012-2013中国数字出版产业年度报告》显示,2012年我国数字期刊收入已达10.83亿元,同比2008年翻了一倍,并保持着较高的增长势头。面对用户持续增长的利用需求与同样高涨的数字期刊采购费用,图书馆等文献机构迫切需要对期刊的影响力和利用绩效做出评估,利用数据的统计则为其提供了重要的数据支撑。利用数据不仅可以作为图书馆选购期刊、数据商(即各类数字服务提供商)调整运营策略的决策依据,还可以为图书馆与数据商之间针对订购模式及价格问题的谈判提供参考。
现阶段,我国数字期刊的利用数据主要来源于各数据商,但由于标准不统一,统计结果不具有可比性,部分图书馆尝试自行统计,而统计指标又缺乏规范性,也有不少机构对利用数据认识不足,仅以引文数据取代之,而且国内尚未形成受期刊界广泛认可的统计标准,相关规范中的指标也都比较宽泛,总体来看,国内的统计指标发展现状不容乐观。相比之下,国外的统计实践则远超国内,一些学术团体和标准化组织已相继制定了较为成熟的统计标准,考虑到国内外数字期刊发展情况的差异,相关指标可供借鉴但并不完全适用于我国。
近年来,统计指标的有关问题,也逐渐引起了学者们的关注,相关研究成果中,国内以论文为主,国外则多为应用性项目,其中影响最广的是英国的COUNTER(Counting Online Usage of Networked Electronic Resources),该项目自2002年就发布了有关数字期刊在线利用统计的实施规范,详细规定了利用数据的统计细则,而PIRUS(Publisher and Institutional Repository Usage Statistics)项目的提出,又为COUNTER增添了期刊单篇文章级的统计规范。国内学者的相关研究则大多是对国外已有成果的单纯介绍,或着眼于数字资源整体,概括分析其利用统计指标,当前针对中国数字期刊细致探讨相关指标的文章比较少:季山针对“下载影响因子”等上网期刊Web文献计量指标的涵义进行了讨论;刘雪立根据期刊被引半衰期的概念,提出“期刊下载量半衰期”并揭示其计量学意义;陈丹、杨萌从有效浏览量的角度提出了“数字期刊阅读量”的计算方法,但其适用范围仅限于龙源期刊网。有鉴于此,本文以中国数字期刊为研究主体,综合国内外相关指标,拟从期刊利用的揭示层级和深度入手,提出不同类型的利用统计定量指标,力求更多维地揭示期刊的利用情况,并对指标的统计方法和功能进行统一分析,旨在解决现有利用数据缺乏可比性和可靠性的问题,这对于今后我国数字期刊利用统计指标的规范具有重要的现实意义。
2 数字期刊利用统计的指标类型
传统的期刊利用统计往往基于文献计量学中的被引指标,但过度依赖被引指标测度数字环境下的期刊利用率与影响力也存在诸多问题:其忽略了非作者用户、时滞较长、存在用而不引、无法区分被引期刊是数字期刊还是印刷型期刊、高质量低引用的小众期刊常被低估等,可见其反映用户利用情况的功能很有限。若要全面揭示数字期刊的利用情况,应从用户视角出发多维度、多粒度地统计利用数据,基于此,本文将适用于我国数字期刊的利用统计指标划分为以下类型(见图1):按照期刊利用情况被揭示的层级,分为“期刊层级”指标与“期刊单篇文章层级”指标;按照用户对期刊的利用深度,又分为“浅层使用”指标和“深度利用”指标,浅层使用,即对期刊文章内容的直接获取,如阅读、下载等,此类指标可直观即时地揭示期刊被用户使用的情况,深度利用是经用户吸收、转化到最终反馈的利用行为,考虑到期刊被引指标是当前较为公认的深度利用情况的外在表征,且数字期刊在被引期刊中占有较大比重,将其暂列为深度利用指标。本文选取各类指标中易测度、有代表性的指标进行分析,供数据商与各机构根据需要进行选择、扩展,这些指标互为补充,共同构成中国数字期刊的利用统计指标。
3 期刊层级统计指标的含义与功能分析
3.1 浅层使用统计指标
统计期刊层级的浅层使用数据时,需要提供每种数字期刊的描述性元数据(见表1),以此作为相应的匹配和定位依据,其中核心项的匹配程度较高,扩展项可作为辅助。
3.1.1 期刊基本使用数据
基本使用数据,是基于用户浅层使用行为的总量指标,也是其他相对指标的统计基础,因此,对下列原始数据的准确收集与分析,在利用统计整体工作中具有至关重要的作用。

图1 数字期刊利用统计指标类型图

表1 数字期刊的元数据集
(1)单位时段内、每种期刊所有全文文章的成功请求量
指标含义:全文文章成功请求量,是数字期刊最主要的利用数据,而该指标是其基本组成单元。全文文章,即一篇文章完整的文本,除正文外,还有参考文献、图表及辅助材料链接,通常包含HTML、PDF等格式。用户对全文文章的请求行为,包括阅读、下载、电邮、打印等方式,当前的请求量统计通常以“下载量”、“阅读量”为主。
统计方法:服务器会自动记录请求信息,被计数的“成功”请求,在服务器日志中有特定返回码,为提高数据有效性,用户对HTML格式10秒内的多次请求及对PDF等格式30秒内的多次请求,应按最后一次记录。在具体统计操作中,应确保数据的即时更新,从而灵活选择统计时长,通常情况下,单位时段为“1个月”,为充分揭示使用情况的变化,需将统计时长延至1年,而若要提供当前任意12个月的数据,则至少连续统计24个月,累积计算请求总量,并分别提供文章每种格式的请求量。以CNKI中国知网收录的《图书与情报》期刊为例,假设在2013年1月1日至2013年12月31日内,分别统计用户每月对该刊文章的成功请求量为 421、613、901、1402、1203、912、456、512、1213、1452、1024、891,则该刊 2013 年的请求总量为11000(单位为次)。
指标功能:该指标数值越大,表明用户对期刊的使用量越多。横向对比不同期刊在同一时期内的数据,可以了解各刊的使用量,针对使用量少的期刊,图书馆应综合分析原因来决定停止订购抑或提高使用率;比较不同数据商提供的数据,可以了解用户对期刊获取途径的选择倾向;纵向对比同一期刊不同时段的数据,可以预测用户的使用趋势。
此外,当统计的单位时段为“1年”时(“某年”即期刊出版年),被记录的请求就是用户对该年出版期刊的使用请求,将统计时长设为近20年,便可得到回溯库中过刊的使用量,图书馆可以依此划定回溯采购的起始点。
(2)单位时段内、每种期刊、每种内容单元的成功请求量
除上文所提的全文文章外,用户对期刊的使用粒度,还可以细分到期刊的各内容单元。数字期刊的内容单元,包括不同格式的全文文章、文摘、目次等纯文本类型,也包括图像、音频等非文本类型。该指标增加了统计的细粒度,也提高了统计难度,统计方法与全文文章的成功请求量类似,按月统计,并计算年度总量,例如,假设统计得2013年内对《图书与情报》中HTML格式文章、PDF格式文章、文摘、图片的成功请求总量分别为4630、5322、6345、2360,可以看出用户偏向于使用该刊文摘,而针对文章更倾向于使用PDF格式。对比不同内容单元的使用数据,有利于数据商和图书馆判断用户的使用偏好,从而有针对性地开展个性化服务和培训活动。
(3)单位时段内、每种期刊的被拒请求量
被拒绝的请求量,反映的是用户需要但未被满足的请求数量,数值越大,说明用户的需求满足率越低。请求被拒绝的类型,除了因访问人数超过用户最大并发数导致的被拒,还包括因未获得使用授权造成的被拒,但不包括因口令错误等引起的请求失败。该指标通常按月统计,提供年度总量,并分别计算两种类别的被拒请求量,对比这两类数据有助于分析请求被拒的原因,例如,假设统计得《图书与情报》于2013年的两类被拒请求总量分别为9620、6901,可知因访问人数过载引起的被拒次数更多,此时数据商可考虑放宽用户许可数,若主要因未获得使用授权造成被拒,图书馆则应综合考虑购买成本、印刷型期刊利用率等因素后决定最终的获取途径,进而调整印刷型期刊和数字期刊的采购比例。
上述数据常用的分析方法,是借助分析工具或采用数据挖掘方式来分析服务器的日志记录,其中包含代理服务器及中间网页网关的记录,这种“日志分析法”主要依靠IP追踪用户,而在实际统计中,人为或代理软件的重复请求、恶意攻击、网络爬虫应用等不规范的使用行为,都会加大统计噪声,导致统计数值虚高,因此,可以结合更适于第三方统计的“在线统计法”,通过Cookie识别已访问用户,在此基础上,不断优化统计系统结构和分析工具,综合考虑用户各种访问路径产生的数据,从而滤去无效数据,提高数据精确度。
此外,统计上述数据时,数据商也可以获得用户的数目、类型等信息,若能估算不同机构的最终用户总数,就可以提供上述数据的人均使用量,便于在不同机构间对比。但是,因受制于当前的技术条件和用户隐私保护,用户信息的精准度不高且不便公开,相比之下,由机构内部收集更具可行性,西安交通大学图书馆自行设计了一套“电子资源访问网关系统”,通过用户认证可以了解用户的学科和数目,只记录与其学科相符的使用请求,精确提供反映其需求的使数据。
3.1.2 期刊使用因子(Journal Usage Factor,以下简称JUF)
JUF是COUNTER Online Metrics公司与英国期刊协会(the UK Serials Group)于2007年联合提出的与期刊影响因子(Journal Impact Factor,JIF)原理类似的新指标,旨在从实际使用量的角度衡量期刊影响力,计算公式为:

该指标的计算,基于上文中请求量(以下指成功请求量)的统计结果,依据国际通行的观点,时间窗x长度通常为1年或2年,出版时间窗y一般为两年。考虑到算术平均值对极值有较强的敏感性,采用“中位数”估算均值,如将《图书与情报》2012~2013年在线出版的全文文章于2012-2013年每月的请求量按大小排成数列,取其中值,就可得到该刊2012~2013年的JUF,所得终值为整数。JUF作为一个相对指标,反映了数字期刊中内容单元(全文文章为主)的平均使用率,在不同期刊间更具可比性。我国的“下载影响因子”指标也有相似的统计原理,但其统计时间窗扩大为3年,与浅层使用量的峰值不符,同样,JUF的时间窗设定问题也有待进一步商榷。虽然JUF的算法还有待完善,但已引起了期刊界的广泛关注,调查显示它在影响图书馆期刊采购决策方面,排名第2,并在JIF之前,相比 JIF,JUF能有效地反映应用性期刊的影响力,而且其反应及时、没有时间间隔,可包含统计当年的数据,同样适用于新刊,当前不少文章作者、出版者、科研资助机构都非常认同将其应用到期刊评价中作为JIF的补充指标,遏制过分强调JIF的倾向。
3.1.3 期刊使用即年指数(Journal Usage Immediacy Index)
使用即年指数,是反映用户对数字期刊使用速率及期刊即时影响力的相对指标,实际上,它是统计某期刊当年在线出版文章的请求量与该刊当年在线出版文章总量的一个比值,例如,假设《图书与情报》2013年在线出版的文章总量为170篇,同年对文章请求总量为11000次,则该刊2013年的使用即年指数为65,此数值越大,表明期刊文章在线出版后被使用的速率越快,即时影响力越大,该刊所属主题的学者对热点问题也有较高关注度。使用即年指数,相比传统的引用即年指数,更具统计意义,因为发文存在较长时滞,某年发表的文章很难在当年被引用,尤其体现在人文社科类期刊中,但浅层使用行为的反应速率要迅速得多;使用即年指数,相比我国现已作为期刊评价指标之一的“Web即年下载率”,统计范围也更全面,包含了下载行为以外的使用形式,但该指标相对缺乏稳定性,仅可用于数字期刊的短期评价。
3.1.4 期刊使用半衰期(Journal Usage Half-life)
使用半衰期,是从出版年角度测度数字期刊老化速度和长期影响力的指标,它的计量原理与被引半衰期类似,即统计当年某期刊所有文章的总请求量中,较新的一半文章在线出版的时间跨度,按年计量,例如,假设将2013年《图书与情报》的请求量按照请求文章的在线出版年自2013年倒序排列,其中接近50%的累积请求百分比分别为47.43%、56.43%,其所属出版年分别为2011年、2010年,则该刊2013年的使用半衰期为2013-2011+(50-47.43)/(56.43-47.43)=3.3(年)。该数值越大,代表期刊文章在线出版后的老化速度越慢,也表明其及时反映速率越慢,期刊具有较长的使用寿命和长期的学术影响力,因此,该指标对于数据商制定数字期刊定价策略及选择存档期刊具有参考价值,分析比较同刊各年度的半衰期,也可为每年的期刊组稿、编辑质量提供评价依据,但需注意,使用半衰期通常受期刊所属主题或学科的研究领域影响较大。
3.2 深度利用统计指标
3.2.1 期刊被引指标
有关被引指标计算方法的相关探讨已有很多,文中不作赘述。常用的被引指标,主要包括总被引频次、JIF、即年指数、被引半衰期及其他修正扩展指标,其中最具代表性的是JIF,国际通用的ISI算法中,其时间窗长度为2年,而考虑到自然科学与人文社会科学文章引用时间的差异及发文的较长时滞,可灵活调整时间窗长度,综合比较期刊的短期影响与长期影响。被引指标属于静态指标,统计结果相对稳定,但当前国内的统计结果因统计源不同而差别较大,举例说明,受收录期刊范围的影响,2013年CNKI发布的《图书与情报》综合JIF为1.111,而万方数据《中国科技期刊引证报告》(扩刊版)中其JIF为1.654,对此,可以考虑由第三方统计或整合多方数值统一发布复合数据。同时需要注意,JIF具有学科领域覆盖面窄、只重视理论性学术期刊等局限,反映期刊的被利用程度有限,但此类数据对后继的浅层使用存在一定影响,可作为参考。
3.2.2 网络影响因子(Web Impact Factor,WIF)
随着期刊载体的转变,期刊研究者的视线也逐渐转向了作为网络计量学研究重点之一的链接分析指标,并将其应用到期刊网站网页的利用分析中,WIF就是其中最具代表性的指标。它是JIF在网络环境中的引申,基于“外部链接相当于用户对期刊网站的引用”这一理论假设,计算方法是某一时段用某期刊网站的外部链接总数除以该刊网站下的网页总数,得到每个网页的链接均值,例如,假设在2013年12月20日8:00~9:00间借助All The Web等工具搜索得《大学图书馆学报》期刊网站的外部链接数为40,网站网页数为30,其WIF则为1.333,该数值越大,代表被引程度越高。然而,WIF也存在较大的局限性:链接结构与引用结构的不同降低了理论假设的合理性,算法自身缺陷使得指标难于精确统计,加之我国期刊网站的发展程度不高,该指标的参考价值较小。
4 文章层级统计指标的含义与功能分析
用户对数字期刊的利用,通常是按照主题查找并利用其中的单篇文章,很少以期刊整体作为使用对象,因此,对单篇文章层级的计量(Article-level Metrics)更能深入期刊内容揭示其利用效能,而这也提高了统计要求。
4.1 浅层使用统计指标
统计此类指标时,除了需要提供表1中文章所属期刊的描述性元数据,还需提供单篇文章的描述性元数据(见表2),以此作为相应的匹配依据。
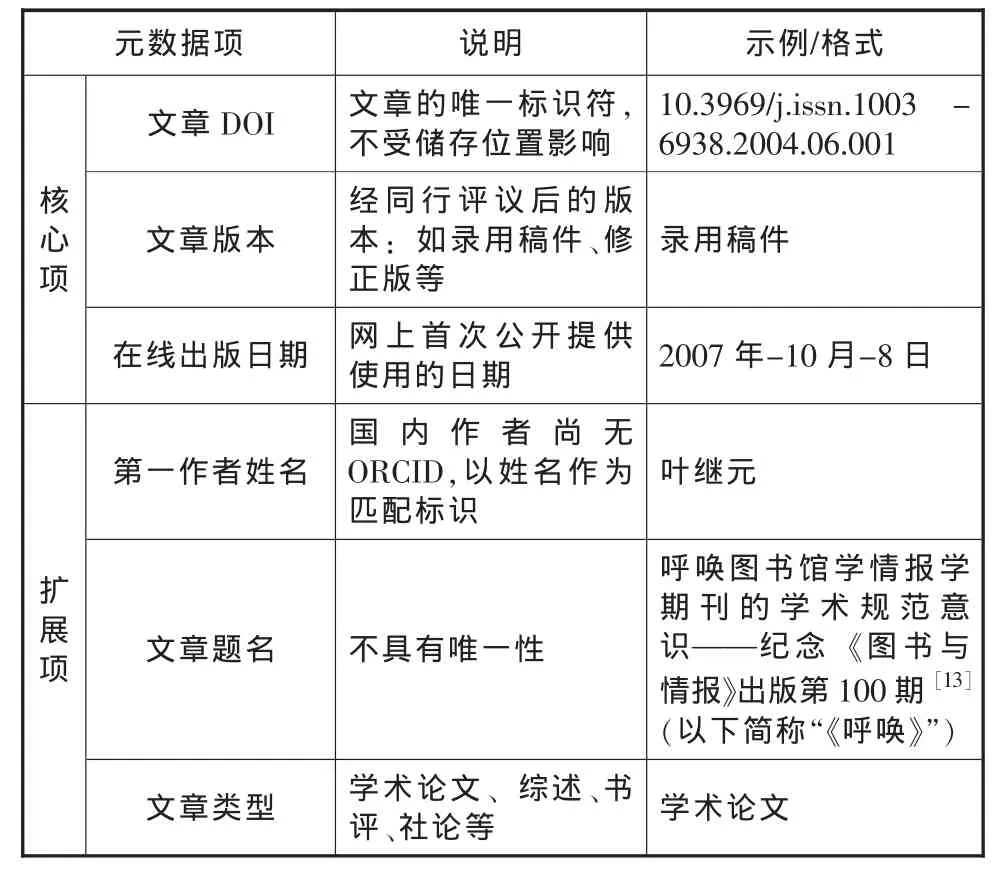
表2 数字期刊单篇文章的元数据集
4.1.1 单位时段内,每篇全文文章(或每种内容单元)的成功请求量
单篇文章请求量的统计数据将为用户选择期刊文章提供指导。PIRUS项目对该数据的收集机制正处于探索阶段,除了各数据商,各机构知识库也需要提供统计数据。我国的机构知识库发展缓慢,收录文章的数量也与国际水平有较大差距,因此,可选取部分代表性的机构知识库作为试点。该指标的统计方法与上文中期刊层级的请求量类似,但统计起始时间应按照文章在线出版日期来划分,并分别统计文章各种版本的请求量,如针对表2中《图书与情报》的文章《呼唤》,应从2007年10月8日起,连续统计每个月的请求量,而不能任意划定统计起始点。
4.2 深度利用统计指标
4.2.1 文章被引频次
文章被引频次,是指期刊中单篇文章自发表以来在统计当年的被引次数,在一定程度上揭示了文章的学术影响力和被深度利用的程度,最终体现为学术产出的数量,可以作为用户的使用参考。我国CSSCI中文社会科学引文索引现已在文章记录中提供了该指标,可以查询到表2中文章《呼唤》自2004年发表后,在2006年的被引次数为4次,至2013年累积被引次数为16次,但是受收录文章数量的影响,不同的统计源针对该指标的统计结果也有所差别,如CNKI提供的累积被引次数为25次,且多数统计源只提供了累积被引次数,缺少各年度的被引数据。
4.2.2 社媒影响指标
在Web2.0环境中,用户对期刊文章的深度利用方式,已由传统引用拓展到在社交媒体中对文章“纳米级”内容信息的分享、标引与对话等,Altmetrics(“选择性计量学”、或译作“社媒影响计量学”、“网络补充计量学”)这种新兴计量方法的出现,为这些在科研过程中即时产生的大众利用数据的收集提供了新思路。国外的相关计量研究尚处于实验阶段,学者们开发了ImpactStory等数据收集工具,追踪用户在Twitter、PLOS等社交媒体及开放获取平台中的学术交流行为,初步得出了部分社媒影响指标,主要包括标签数、标签密度、评论数、社会书签数等,随着相关研究的日臻完善,可将部分指标用作我国数字期刊利用统计的补充指标,例如,通过Twitter Search API可收集到某篇英文文章在Twitter中的每日推荐数(Tweets),推广到我国,则可以统计某篇文章在新浪微博中的每日发贴数。此外,还可对指标进行拓展,如针对“评论数”这一指标,可以分别统计在科学网等学术博客中与某篇文章相关的“正面评论数”与“负面评论数”,从正反两方面深度揭示其影响力。
单篇文章层级的利用统计数据,能够即时、真实地反映作者研究成果的实际影响力与学术质量,有利于扭转学界片面化“以刊论文”的局面,对于文献的知识亮点评价及知识管理亦有重要价值。
5 结语
本文借鉴国内外数字期刊利用统计指标,进一步细化统计维度、粒度,提出综合的适用于我国数字期刊的统计指标,并将其按照利用的揭示层级和深度分为不同类型,从理论上分析了各种指标的含义、功能和统计方法。虽然部分新型指标的可行性尚需实践验证,但也利用统计提供了新的视角,弥补了单纯依赖被引指标的缺陷。针对统计指标在我国数字期刊利用统计中的应用和后续研究提出以下建议:其一,我国用户对数字期刊的利用,虽然可以借助期刊网站、开放获取等方式,但多数基于期刊全文数据库,因此,当前基本使用数据的统计主要依赖数据商,有统计条件的机构可自行统计比对,数据商应定期为用户提供相应数据,并将统计数据按期刊所属主题进行归类,对收录文章情况不同的期刊进行区分;其二,应充分认识到数字期刊多访问途径对统计结果的影响,将统计噪声降至最低,可参考国外做法,建立“第三方”统计平台,收集数据商提供的基本使用数据,用于更多指标的计算分析和用户的开放获取;其三,用户的利用行为具有复杂性,若要全面评价期刊的利用绩效和影响力,需加入定性分析,考虑到数字环境下期刊利用形式的多变性,应动态调整相应的统计指标,如JUF今后可以拓展出单篇文章层级或作者层级的新指标,社媒影响指标也可以发展为期刊层级的新指标。
[1]中国新闻出版研究院.“破局”之年的数字产业——《2012-2013中国数字出版产业年度报告》速览[N/OL].[2013-10-12].http://media.people.com.cn/n/2013/1 010/c369775-23152808.html.
[2]全国信息与文献标准化技术委员会.GB/T 13191-2009信息与文献 图书馆统计[S].北京:中国标准出版社,2009.
[3]吕淑萍,罗云川.图书馆数字资源统计标准和应用指南[M].北京:北京图书馆出版社,2010:3-181.
[4]COUNTER [EB/OL].[2013-12-16].http://www.projectcounter.org/.
[5]COUNTER PIRUS [EB/OL].[2013-12-16].http://www.projectcounter.org/pirus.html.
[6]季山,胡致强.关于上网期刊Web文献计量指标的讨论[J].中国科枝期刊研究,2006,17(5):756-759.
[7]刘雪立.科技期刊下载量半衰期的建立及其文献计量学意义[J].中国科技期刊究,2012,23(4):561-564.
[8]陈丹,杨萌.数字期刊阅读量统计路径及方法初探[J].图书与情报,2012,(2):18-22.
[9]张静,阎晓弟,周奇.目前电子资源使用统计存在的问题及解决设想——以西安交通大学图书馆为例[J].图书与情报,2008,(5):82-85.
[10]Usage Factors Study-Final Report Now Available[R/OL].[2013-12-27].http://www.uksg.org/usagefactors/final.
[11]Ian Rowlands,David Nicholas.The missing link:journal usage metric[J].Aslib Proceedings,2007,(59):222-228.
[12]Phil Davis.Journal usage half-life[EB/OL].[2013-12-27].http://124.240.187.83:81/1Q2W3E4R5T6Y7U8I9O0P1 Z2X3C4V5B/www.publishers.org/_attachments/docs/jour nalusagehalflife.pdf.
[13]叶继元.呼唤图书馆学情报学期刊的学术规范意识——纪念《图书与情报》出版第100期[J].图书与情报,2004,(6):3-9.
[14]刘春丽.Web2.0环境下的科学计量学:选择性计量学[J].图书情报工作,2012,7(14):52-56.
[15]Stefanie Haustein,Tobias Siebenlist.Applying social bookmarking data to evaluate journal usage[J].Journal of Informetrics,2013,(5):446-457.
