基于MapReduce的网格化优化CURE算法的实现
2014-01-05郎福通
郎福通,王 鹏
(成都信息工程学院软件工程学院,四川成都610255)
0 引言
随着大数据时代的来临,如何更加高效、准确地划分数据,已成为聚类研究的一大热点。面对日益增长的海量信息数据,现有的聚类算法在伸缩性和扩展性方面存在着一定的局限性。而分布式聚类算法由于能够充分利用集群伸缩性和扩展性,因此能很好地解决这一问题,已成为当前聚类算法研究的重点之一[1]。目前,在已存在的分布式聚类算法的研究中,基于层次聚类[2]的CURE(Clustering Using Representative)算法[3]相较于基于划分聚类的K-means算法[4],具有处理任意形状的数据分布的优势;相较于基于密度聚类的DBSCAN算法[5]以及利用动态模型的CHAMELEO算法[6]和基于小波变换的WaveCluster算法[7]具有算法实现简单,可聚类任意形状的族分布等优点。因此CURE算法的并行化研究也成为分布式聚类算法研究的一大热点[8]。
CURE算法通常采用随机抽样和划分的方法来处理大数据集。而大数据时代的数据集具有数据体量大,价值密度低和要求响应时间快等特点,通过少量的数据抽样可能无法满足大数据要求获得较准确聚类结果的需求,采样更多数据或全部数据来提高聚类效果的准确度,却需要处理大量的数据。针对该问题,借用网格聚类思想[9]和MapReduce计算框架[10],提出Grid-CURE分布式聚类算法。该算法首先对数据集进行快速网格聚类处理。然后采用MapReduce并行框架对CURE算法进行并行扩展,使算法能够充分利用集群的计算和存储能力,以加速算法的聚类过程。
1 背景
1.1 CURE 算法
CURE算法是层次聚类算法的一种,通常使用随机抽样与划分的方法处理大数据集,在质心和周围的异常点之间的区域进行聚类。通常情况下,选择c个较分散点代表一个类,并通过收缩因子向类的质心收缩,收缩之后的分散点就代表了这个类的形状。然后,CURE算法将合并最相近的类对,并将降低异常点对聚类的影响[11-12]。CURE算法的步骤:
(1)从源数据集中抽取一个随机样本S。
(2)将样本S分割为一组划分。
(3)对每个划分局部的聚类。
(4)通过随机取样剔除孤立点。如果一个类增长太慢,就去掉它。
(5)对局部的簇进行聚类。
(6)用相应的簇标签标记数据。
1.2 Grid Cluster 和 MapReduce
Grid Cluster(网格聚类)网格聚类是多种聚类方法[13]中的一种,是将数据空间划分为网格单元,聚类过程在网格上进行;当网格足够小时,落入到同一个网格中的数据点是相似的,应属于同一个聚类。若一个网格单元中数据对象的个数大于给定的密度阈值,则认为其是高密度单元;否则视其为低密度单元,通常视低密度单元中的数据对象为孤立点或噪声数据将其丢弃。该算法的处理时间仅依赖于量化空间中每一维上的单元数目而独立于对象数目,具有聚类速度快且能发现任意形状、大小的类的优点[14]。
MapReduce是一种并行编程模型,用以大规模数据集的计算。其主要采用了分而治之的思想,把大的问题分割为一个个小的问题并行处理[15]。模型中两项任务Map和Reduce,Map用来把一组键/值对映射成一个新的键值对,Reduce对Map输出结果进行规约处理,用来保证所有映射的键值对中的每一个共享相同的键组。
2 Grid-CURE算法介绍
Grid-CURE算法是一种优化的CURE算法。核心思想为:针对某一数据集,将数据对象空间量化为有限数目的网格单元,根据单元格内数据对象的个数对原始数据集进行初始化聚类;通过MapReduce框架把初始化的类数据分割到一个个数据块中,再将数据块分发到集群中各个数据节点上,并行地计算出每个类与其最近的类之间的距离,Reduce阶段凝聚两者之间距离最短的类对。改进的算法总的来说可分为两个阶段:第一阶段借用网格聚类算法的思想,利用MapReduce框架对原始数据集进行Grid Cluster预处理;第二阶段采用MapReduce框架来实现CURE算法的并行性扩展,扩展后的算法聚类过程将在Map与Reduce阶段通过合并距离最相近的类对完成。
2.1 Grid Cluster预处理阶段
根据数据集中包含数据对象的个数n和数据对象拥有属性的个数r,定义数据集O={o1,o2,…,on},数据对象的维度空间A={A1,A2,…,Ar}。将A的每一维进行M等分,则可将A分割为Mr个网格单元。通过MapReduce计算框架,将原始数据集中的对象在Map阶段映射到对应的网格单元内,在Reduce阶段依据每个单元格内的数据对象的数目进行相应的初始化聚类处理。分析上面的处理过程:将数据集中对象映射到对应的网格单元内的操作与其他数据对象是无关联的;依据网格单元内的数据对象数目进行初始化聚类的处理亦与其他单元格无关,因此使用MapReduce框架的Map和Reduce操作完成数据集的初始化聚类是可行的。首先,通过MapReduce框架把存储在文件中的数据集分割为一个个等同大小的数据块,并把数据块分发到各个datanode数据节点上。其次,启动各个datanode上的Map任务,把该节点上数据块中的数据对象映射到对应的网格单元中,并把单元格ID和数据对象分别作为Map任务的key和value输出,以作为Reduce阶段的输入。然后,在Map任务完成后,启动Reduce任务,把key值相同的value视为同一单元格中value,统计同一单元格中value对象的数目确定该单元格的类型(稀疏单元格,均匀单元格和密集单元格),根据单元格的类型进行不同处理:对稀疏单元格中数据进行删除处理;对均匀单元格中每个数据分别初始化为一个类处理;对密集单元格中全部数据初始化为一个类处理。接着,只把各个类的中心点和代表点作为该类的标识存入HDFS上特征类文件中。最后,将类的标识(中心点和代表点)和类中的对象分别作为Reduce任务的key和value输出。
2.2 MapReduce并行化扩展CURE算法处理阶段
CURE算法聚类过程概括来说核心操作有3部分:计算距离最短的类对;合并距离最短的类对;判断聚类是否结束。分析这些操作过程发现:类之间最短距离的计算与计算顺序无关且与类中的数据对象无关;合并最短距离的类对是在计算簇间最短距离之后且其他类无需合并;判断聚类是否结束,可作为主程序的迭代执行1和2的终止条件。因此,CURE算法是可以采用MapReduce框架进行并行性扩展的。详细处理步骤如下:首先,通过MapReduce框架把上阶段产生的初始聚类结果数据集分割为等同大小的数据块,并分发到各个datanode上。其次,启动Map任务读取HDFS上特征类文件,得到所有类的标识存入list列表中,计算节点上的类与list中除该类外的类之间的距离,距离的计算可,而距离的计算方法可以采用欧几里德距离、曼哈顿距离或拉格朗日距离等,两个类M、N之间的距离定义如(1)式所示的形式,其中p和q分别为属于M和N的代表点,把计算结果最短距离和该类的标识(代表点和均值)分别作为Map任务的key和value输出。然后,在Map任务结束后,启动Reduce任务,选取最小key值对应的一对value(两者之间距离值为key的类对)合并,其余value不处理,因此只需一个Reduce任务。接着,只把各个类的标识存入HDFS上特征类文件,并把类标识和类分别作为Reduce的key和value输出。最后,主程序读取HDFS上特征类文件获取类个数R,比较R与实际类个数K的大小,以判断聚类是否结束。未结束则删除增长过慢的类,否则迭代上面操作。

Grid-CURE算法的框架流程图如图1所示。描述如下:
(1)启动第一阶段Map-Reduce迭代任务,通过MapReduce框架读取数据集,并把数据分割为一个个等同大小的数据块,分发到各个数据节点上。
(2)利用MapReduce框架的Map操作,将数据节点上的数据映射到对应网格单元内。
(3)利用MapReduce框架的Reduce操作,删除稀疏网格单元的数据,将均匀网格中每个数据对象初始化为一个类,将稠密网格单元中所有数据初始化为一个类。
(4)启动第二阶段Map-Reduce迭代任务,主程序判断聚类是否结束,若是则输出聚类结果数据并结束程序;否则,删除出生长过慢的类,然后执行步骤5。
(5)利用MapReduce框架的Map操作,计算出数据节点上的类与其他所有类之间的最短距离dist,并将dist和该类的标识(中心点和代表点)作为Map任务的输出。
(6)利用MapReduce框架的Reduce操作,只合并最小key键对应的value对,将合并得到的新类和其他的类的标识存储到HDFS上特征类文件中,最后把这些类的标识和这些类输出,然后执行步骤4。

图1 Grid-CURE算法框架流程图
3 实验及结果分析
3.1 实验环境
实验实施在由Apache开源项目Hadoop[16]搭建的集群上。实验硬件环境:6个服务器节点,每个节点的配置均为:Cpu IntelR○CoreTMi3-2100 3.10GHz,内存4G,硬盘为500G;软件环境:每个节点均为CeontOS Linux6.3操作系统,Hadoop 版本为0.20.2,Java 开发工具包为 JDK1.6-0-27 版本,程序开发工具为 MyEclipse10.0,算法全部由Java语言实现。
3.2 实验数据集
实验数据选取两组数据集,第一组来源于联合程序开发网站的测试数据集[18],包含10000个二维数据的点,聚类个数为3;第二组来源于Matlab生成的人工数据集,包含20000个二维数据点,聚类个数为3。使用两组数据集测试CURE算法和Grid-CURE算法处理数据的效率。
3.3 实验
为验证MapReduce框架和网格化聚类预处理能够解决CURE算法的效率问题,将使用以上两组数据集(不使用随机抽样与划分)测试CURE算法和Grid-CURE算法的执行效率,并在不同规模的Hadoop集群上运行Grid-CURE算法,测试集群的规模大小对Grid-CURE算法的影响。因为实验数据集为平面二维数据,因此聚类距离选择欧几里德距离进行计算。实验结果如下:
图2显示了随着集群规模动态变化Grid-CURE算法运行的时间的状况。可以看到:随着集群规模的增加,Grid-CURE算法的运行时间逐渐缩短,但运行时间的缩短速率逐渐降低;Grid-CURE算法处理第二组数据集的时间要短与处理第一组数据集的时间。
分析原因:(1)随着集群规模的增长,更多计算资源和存储等资源被放入hadoop平台资源池中,集群计算能力和存储能力也变得更强,Grid-CURE算法通过MapReduce框架充分利用集群的计算和存储能力,使其处理数据的能力也得以加强。但随着集群规模的增加,集群中任务的调度会把任务分配到更多的集群节点上,节点间的通信时间消耗也会以指数形式增加,所以随集群规模的增长计算力对算法处理速度的优化会变得越来越弱,因此节点数目有个最优配置。(2)虽然第二组数据集的规模要大于第一组数据集,但其数据分布图4(a)类似3个环型,数据分布呈现密集集中的特征。使用Grid-CURE算法处理符合该特征分布的数据集,可充分发挥该算法的网格化预处理优势:筛选掉稀疏网格中的数据,凝聚稠密网格中的数据,以加速算法的处理效率。
在单台服务器节点上使用CURE算法分别处理两组数据集,运行结果显示:处理第一组数据需大约4.3×106毫秒,处理第二组数据需大约5.8×107毫秒。结合图2进行分析可以发现:CURE算法处理第二组数据集消耗时间远比第一组数据集长。处理第一组数据集,4节点上运行的Grid-Crue算法比CURE算法高效的多,而单节点上运行的Grid-CURE算法与CURE算法效率相似。
分析原因:(1)CURE算法的时间复杂度为O(n2logn)[17],伴随数据量的增长,运行时间成指数增长。(2)启动MapReduce框架需要消耗掉一些时间,但Grid-Crue算法有一步数据集网格预聚类处理步骤,提升算法的执行效率,所以单节点上Grid-CURE算法和CURE算法效率相似。随着节点数目的增多,Grid-CURE充分利用MapReduce框架的并行处理计算能力,大大降低了算法的运行时间,所以比CURE效率高。
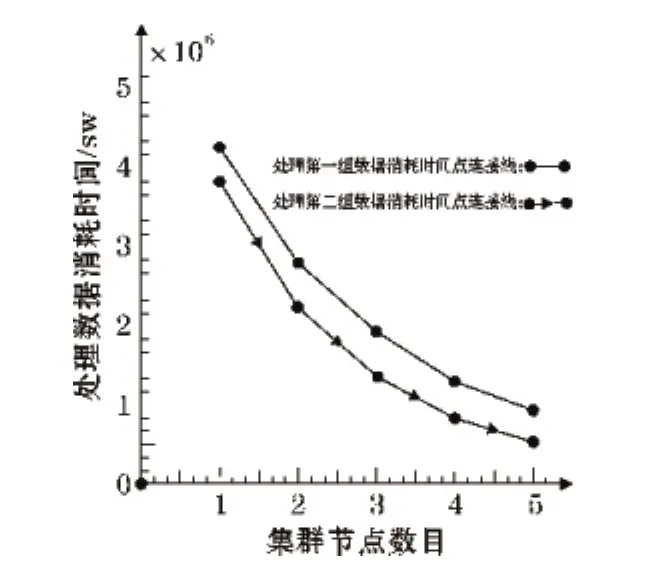
图2 Grid-CURE算法运行时间图

图3 第一组数据实验结果图
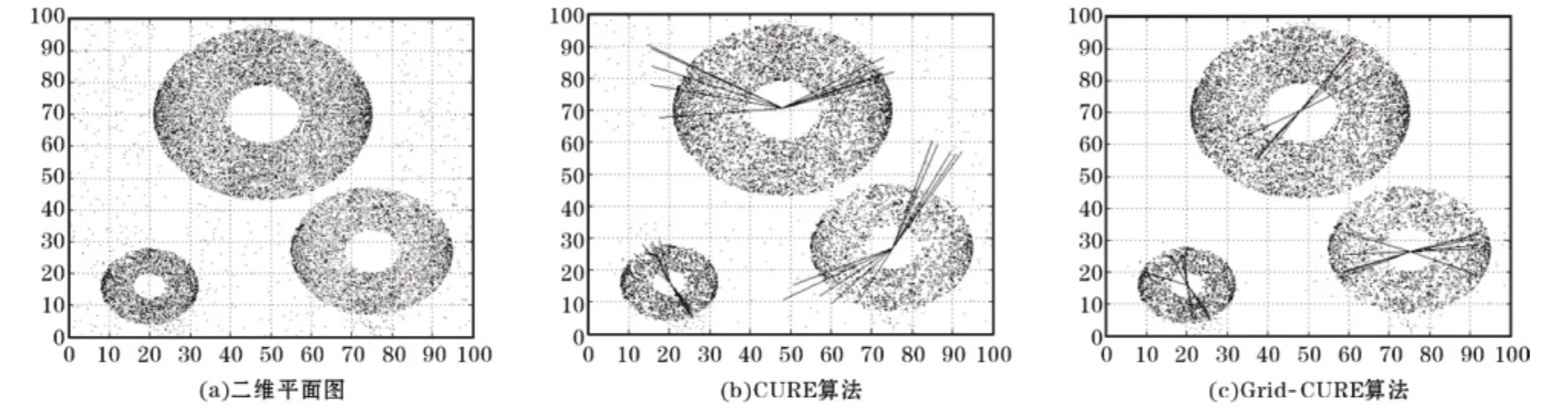
图4 第二组数据实验结果图
图3(a)为第一组数据的二维平面图。图3(b)和图3(c)分别为使用第一组测试数据运行CURE算法和Grid-CURE算法产生的结果图。由图3(b)和3(c)中星射线的外缘点为类的代表点,星射线的中心点为类的均值,而中心点和代表点周围的点为该类中的数据点,从图3(b)和3(c)可以看出聚类结果为3个类。亦可看到使用Grid-CURE算法处理后的类中数据点比较密集,噪声点比较少。原因为Grid-CURE算法对数据集进行了网格化预聚类处理,把网格密度较低的数据点剔除掉了,降低了噪声点对聚类结果的影响。图4(a)为第二组数据的二维平面图。图4(b)和图4(c)分别为使用第一组测试数据运行CURE算法和Grid-CURE算法产生的聚类结果图。观察图4(b)和图4(c)与图3(b)和3(c)显示出同样的结果:Grid-CURE算法产生的簇中数据点较密集并且噪声点较少。
通过以上分析,可以得出Grid-CURE具有较好聚类效率和较强的抗噪声能力结论。
4 结束语
为解决海量数据的聚类效率问题,基于原CURE聚类算法做了一些改进:对原始数据进行了网格化聚类的处理,剔除一些孤立点同时合并一些密集区的点;使用MapReduce框架对CURE算法进行了并行化扩展,同时在多个节点上计算类之间距离最短的类对。通过对原始数据集进行网格化聚类处理,加速了算法的聚类速度并提高了算法的抗噪声能力,采用MapReuce框架对CURE算法并行化扩展,同时在多个节点计算类之间距离最短的类对,提升了算法的处理效率。在构造的实验环境下,通过不断的试验与对算法的改进,使算法的聚类效率得到了大幅度提升,初步证明Grid-CURE算法在集群环境下具有较高的聚类效率和抗噪声能力。方法适用于大规模数据集的处理,如根据网络日志数据划分不同的兴趣用户群。
[1] 李应安.基于MapReduce的聚类算法的并行化研究[D].广州:中山大学,2010.
[2] Han Jiawei,Kamber M.Data mining:concepts and techniques[M].San Francisco:Morgan Kaufmann Publishers,2000.
[3] Guha S,Rastogi R,Shim K.CURE:An Efficient Clustering Algorithm for Large Database[C].In:Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data,Seattle,Washington,1998.73-84.
[4] 吴夙慧,成颖,郑彦宁,等.k-means算法研究综述[J].现代图书情报技术,2011,(5):28-35.
[5] 冯少荣,肖文俊.DBSCNA的研究与改进[J].中国矿业大学学报,2008,37(1):105-111.
[6] Karypis G,Han E H,Kumar V.CHAMELEON:A hierarchical clustering algorithm using dynamic modeling[J].Computer,1999,(32):68-75.
[7] Sheikholeslami G,Chatterjee S,Zhang A.WaveCluster:A Multi-Resolution Clustering Approach for Very Large Spatial Databases[C].In:Proceedings of the 24th VLDB Conference.New York,USA:[s.n.],1998:428-439.
[8] 毛典辉.基于MapReduce的Canopy-Kmeans改进算法[J].计算机工程与应用,2012,48(27):22-27.
[9] 赵慧,刘希玉,崔海青.网格聚类算法.计算机技术与发展[J].2010,20(9):83-89.
[10] 李玉林,董晶.基于Hadoop的MapReduce模型的研究与改进[J].计算机工程与设计,2012,33(8):110-3117.
[11] 王民,尹超,王稚慧,等.Binary-Positive下的并行化CURE算法[J].计算机工程与应用,2012,50(11):58-61.
[12] 魏桂英,郑玄轩.层次聚类方法的CURE算法研究[J].科技和产业,2005,5(11):22-24.
[13] 贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007(1):10-13.
[14] 张真,周志强.数据挖掘中网格聚类算法研究[J].科技信息,2010,25:20-21.
[15] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,(11):2635-2642.
[16] White T.Hadoop权威指南[M].曾大聃,周傲英,译.北京:清华大学出版社,2010:68.
[17] adrian.聚类的测试数据集[DB/OL].http://www.pudn.com/downloads78/sourcecode/math/detail297600.html,2014-05-10.
[18] 董健康.数据挖掘中CURE聚类算法研究[J].电脑与电信,2007,(4):14-15.
