基于最优路径策略方法快速计算字符串编辑距离
2014-01-05王远超安俊秀程芃森
王远超,安俊秀,程芃森,王 鹏
(成都信息工程学院软件工程学院,四川成都610225)
0 引言
在信息理论和计算机科学领域里,字符串之间的相似度研究获得了广泛地应用,而字符串与字符串之间的相似问题可转化成一个字符串变成另一个字符串所需的编辑操作次数的问题。Levenshtein[1]提出基于独立符号的插入、删除和替换操作的最小编辑距离算法,即编辑距离算法的源模型,因此编辑距离也被称为Levenshtein距离。Wagner R A和Lowrance R[2]在Levenshtein的基础上提出增加相邻位置字符之间地交换操作,对于相邻位置顺序颠倒的两个字符采用正序纠正操作,使两个字符串的相似度比较结果达到最小化。Sten Hjelmqvist[3]在Levenshtein的基础上提出采用两个一维数组分别保存求解过程中的前一步求解结果和当前的求解结果,逐步迭代并交换前一步结果和当前结果,最终求解出两个字符串之间的编辑距离值。赵作鹏等[4]提出增加非相邻位置字符的交换操作,是对文献[2]地扩展,针对顺序颠倒的不相邻的多个连续或非连续字符在合理的范围内实现最小化的编辑操作。吴玲等[5]提出分段处理的1/p概率字符串匹配方法实现求解两字符串的编辑距离。
基于编辑距离模型的近似字符串匹配被广泛应用于数据库重复记录消除、数据库元数据语义标注、语音辨识、拼写检查、DNA分析等领域。Monge A E和Elkan C P[6]基于启发式方法结合编辑距离模型快速识别数据库中损坏或重复的记录,该方法采用类似聚类算法的思想能够快速识别领域无关的重复记录。Hernández M A和Stolfo S J[7]基于信息相关性理论结合编辑距离模型,实现对不同的大型数据库所产生的重复记录信息进行合并处理。邱越峰和田增平等[8]提出编辑距离的一种改进方法,消除数据库中的重复记录信息,提高了数据库中数据信息的质量。董国卿和童维勤[9]结合编辑距离算法计算元数据与本体实体间的语义相似度对元数据进行自动语义标注,实现异构数据库的信息集成。Cohen[10]使用编辑距离模型以及基于标记的TF-IDF字符串相似值来计算导出的网页在数据库表中的相似性连接排名。Bakker等[11]和Holman等[12]提出归一化划分编辑距离方法(LDND)评价各种不同语言之间的距离。Petroni和Serva[13]提出不同源语言具有相同语义的Levenshtein距离思想,提出归一化编辑距离(LDN)评价各种不同语言之间的距离。Wichmann等[14]通过实践证明LDND方法相对于LDN方法在评价不同语言的相关度问题上更好。Gooskens C和Heeringa W[15]及Beijering K等[16]使用编辑距离算法针对相同文本在不同方言里的发音相似度进行了研究,用于预测不同方言的语言可知度和语言感知距离。Brill和Moore[17]基于编辑距离思想通过期望最大化(EM)算法训练得到的拼写纠正模型提高了拼写纠正系统的检查纠正能力和结果识别准确率。在生物信息学领域,R Durbin[18]利用编辑距离算法对基因序列排列方式进行研究,在进化论以及生物化学评估方面获得广泛的应用。Patil N等[19]提出基于编辑距离模型的模糊匹配算法对基因数据进行分类,简化了基因序列分类过程并提高了分类速度。
上述对编辑距离模型的应用都是使用一个二维矩阵对两个字符串的距离值进行动态迭代求解,时间复杂度和空间复杂度均为O(M×N)(M为源字符串的长度,N为目标字符串的长度,下同),限制了编辑距离算法在长字符串处理领域的应用。另外,Sten Hjelmqvist[3]算法在空间复杂度上性能有所提高,即O(2×min(M,N)),但时间复杂度依然为O(M×N),算法总体性能并没有获得很大提高。
通过研究编辑距离算法的求解过程,发现存在一条最优路径可以直接求解出两字符串之间的编辑距离值。通过确定该路径所在的关键区域,求解出关键区域内的值,即可沿着最优路径方向求解出最小编辑距离值,除去存在于传统方法中无需进行计算的区域,缩小问题的求解规模。从理论上分析以及对实验结果进行观察发现,该方法优于传统的处理方式。
1 编辑距离算法基本思想
编辑距离算法最初由Levenshtein提出,是指把一个字符串转换成另一个字符串所需的最小编辑操作次数,假设字符串Sour的长度为m,字符串Dest的长度为n,编辑距离edit(Sour,Dest)是指把Sour字符串变为Dest字符串所需的最小转化操作次数,转化操作包括3类:
(1)替换一个字符,如:kitten → sitten,字符“k”替换成“s”;
(2)插入一个字符,如:sittin→ sitting,在字符串的末尾插入“g”;
(3)删除一个字符,如:sittin→ sitin,在字符串中删除一个“t”。
编辑距离算法的一般求解策略为采用动态规划方法逐步迭代计算,每一步迭代计算的结果保存在一个二维数组。如字符串Sour前i个连续字符所形成的子字符串同字符串Dest前j个连续字符所形成的子字符串之间的最小编辑距计算公式如式(1)所示,其中LD[m][n]值即为所求的两字符串之间的最小编辑距离值。

其中单字符a、b之间的最小编辑距离值为:

由式(1)和(2)可得计算字符串Sour前i个连续字符同字符串Dest前j个连续字符之间的最小编辑距离值的递推关系式为:

其中j=0表示字符串Sour通过删除所有字符变为空的目标字符串Dest,i=0表示字符串Dest可以通过在Sour中插入每一个字符形成;LD[i][j]与LD[i-1][j]相比字符串Sour多了一个字符,因此计算LD[i][j]时字符串Sour需要执行一次删除操作;LD[i][j]与LD[i][j-1]相比字符串Dest多了一个字符,因此计算LD[i][j]时字符串Sour需要执行一次添加操作;LD[i][j]与LD[i-1][j-1]相比根据字符串Sour的第i个字符和字符串Dest的第j个字符是否相同确定是否执行一次替换操作。
2 确定最优路径的方法
编辑距离计算方式为迭代遍历并标记二维数组LD中的每一个位置,基于式(3)若把二维数组LD展开形成一个二维矩阵,根据矩阵的描述功能并结合图论知识的相关应用,矩阵中每一个位置上的元素表示图中的一个节点,则矩阵LD中存在若干条路径可以从节点LD[0][0]到达节点LD[m][n],经研究发现存在一条以LD[0][0]为起点、LD[m][n]为终点的最优路径,最优路径由一系列关键节点组成,关键节点满足以下计算规则:若节点值r,p,q∈LD时,min(r,p,q)=min(min(r,p),q);若r=p,则 min(r,p)=r;相邻两关键节点中后一关键节点的值由前一个关键节点值求得;最优路径中所有关键节点之间的邻接关系满足式(3)且关键节点上的值小于等于与其相邻的非关键节点上的值;最优路径中一系列关键节点所构成的序列即可确定最优路径的前进方向。如图1所示计算字符串“sikitting”和“kitten”之间的编辑距离值,包含数字的每一个单元格表示图论中的每一个节点,包含箭头的单元格为关键节点。
结合式(3)和编辑图[20]的思想,假设若相邻两关键节点中后一个关键节点与前一个关键节点满足表达式LD[i][j]=LD[i-1][j]+1时,称关键节点KN(i-1,j)向x方向前进一步到达关键节点KN(i,j)(下标(i-1,j)和(i,j)表示图1中关键节点的下标索引值,下同);若相邻两关键节点中后一个关键节点与前一个关键节点满足表达式LD[i][j]=LD[i][j-1]+1 时,称关键节点KN(i,j-1)向y方向前进一步到达关键节点KN(i,j);若相邻两关键节点中后一个关键节点与前一个关键节点满足表达式LD[i][j]=LD[i-1][j-1]+edit(i,j)时,称关键节点KN(i-1,j-1)向z方向前进一步到达关键节点KN(i,j)。
对所有关键节点递推应用上述方法,发现形成的最优路径都需要经过上述3种方向变换之一,起始节点为LD[0][0],结束节点为LD[m][n]。因此,可得计算编辑距离的另一种表示形式

图1 字符串“sikitting”与“kitten”之间的编辑距离图及其对应的最优路径
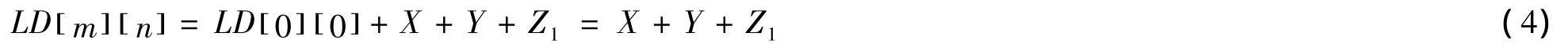
其中X表示向x方向行进的关键点个数,Y表示向y方向行进的关键点个数,向z方向行进的关键点总个数用Z表示(其中Z=Z0+Z1,Z1表示向z方向行进且edit(i,j)=1的关键点个数,Z0表示向z方向行进且edit(i,j)=0的关键点个数)。如图1所示为计算字符串“sikitting”和“kitten”之间的编辑距离值的过程,其中X=3,Y=0,Z0=5,Z1=1,最终求得的编辑距离值为4。
式(4)基于插入、删除、替换操作的权值都是1并结合矩阵所具有的数据结构特征,把LD[][]矩阵抽象成图论中的一个图,抽象化后图中的每一个节点代表原矩阵中每一个索引位置的元素,图中每一个节点具有x方向(竖直方向)、y方向(水平方向)、z方向(斜对角方向),3个方向分别对应于计算编辑距离时的删除、插入、替换3种基本操作,说明编辑距离值可由最优路径中不同方向的关键节点总数确定。如图1中竖直箭头(“↓”)表示前进方向为x方向,斜对角箭头(“↘”)表示前进方向为z方向,水平箭头(“→”)表示前进方向为y方向。图中单元格内的数字表示相应编辑距离值,符号标记d,e,s,i分别表示删除、不变、替换、插入操作。
假设最优路径中有两个关键点分别记为LD[i][j]、LD[k][s](0≤i<k,0 ≤j<s),LD[i][j]在整个路径中沿x方向连续行进a(0≤a<k-i)步(非连续的情况可以转化为连续,任意位置都可以转换为LD[i][j]开始)后到达点LD[i+a][j],从LD[i+a][j]到LD[k][s]需要向z方向行进k-i-a步,向y方向行进 (sk)+(i-j)+a步,且满足下述关系:

因此可得变量X、Y、Z、m、n之间存在下述关系:

将式(6)代入式(4)可得计算LD[m][n]值的表达式:
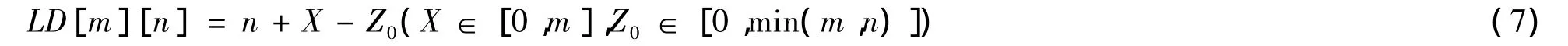
或表达式:

其中LD[m][n]值满足条件LD[m][n]≤max(m,n),而每向x方向行进1步,则向z方向行进机会便减少1,由式(7)可知会使LD的值增加2,为了使LD[m][n]的值尽可能小,需要使z方向中满足edit(i,j)=0的点数尽可能多。因此,选择构成最优路径的节点向x方向行进的条件为:向x方向行进a步后,新的z方向上的节点满足条件edit(i,j)=0的个数大于2a。因此,为了使LD[m][n]值最小,可求只有当X<m/3时,有可能使关系式Z0>2X成立,从而求得关键节点的坐标取值范围

同理,由式(8)可求关键节点的坐标取值范围也位于以下区域

根据式(9)、(10)构造如下区域

由式(11)形成的区域由3个子区域组成,由位置(0,0)沿着近似对角线方向(z方向)到达位置(m,n)。
为了确定最优路径,使LD[m][n]值尽可能小,定义符号<a,b>表示路径中先后沿着方向a和方向b通过相邻两节点,最优路径的前进方向可以为<x,x>、<y,y>、<z,z>、<x,z>、<y,z>、<z,x>、<z,y>几种情况,但不能为<x,y>和<y,x>2种情况,即不能出现相邻两节点之间前一节点为x方向,后一节点为y方向,或者相反的情况。x与y相邻的原理为:先执行一次删除操作(x方向),然后执行一次添加操作(y方向),或者相反的操作,整个过程执行了两次操作,可以用一次替换操作代替(z方向)。因此,可得性质:最优路径中不能出现路径的前进方向为x方向与y方向相邻的情况。
3 确定最优路径所在的关键区域
综合第2节讨论可知,在矩阵区域LD中存在一条由一系列关键节点序列所构成的最优路径,通过最优路径可以快速地直接求解出编辑距离值LD[m][n]。然而,基于Levenshtein编辑距离算法的基本思想关键节点上的值受其相邻的非关键节点影响,因此通过确定最优路径所在的关键区域,保证关键节点上的值只受关键区域内非关键节点值的影响,降低问题的求解规模,由式(9)、(10)可知,由一系列关键节点所形成的最优路径同时通过由公式(9)、(10)所构成的区域。由此,可得性质:最优路径沿着由公式(11)所形成的近似对角线方向且必通过由式(11)所构成的区域范围。
基于最优路径通过由式(11)所确定区域的边界问题的解决办法为添加辅助区域,确保由式(11)所确定区域的各边界完全落在该辅助区域范围内,使最优路径完全位于辅助区域范围,辅助区域所围成的范围即为最优路径所在的关键区域。
添加辅助区域的方式分为3种情况,即X=Y、X>Y、X<Y。图2~4描述3种不同情形添加辅助区域的不同方式,采用深色颜色标记由式(11)所形成的区域范围,浅色颜色标记添加的辅助区域范围,深色区域刚好落在辅助区域范围内。
图2所示为X=Y情形,这种是规则形式,辅助区域的左边界和右边界由起始位置沿着斜对角线方向(z方向)前进到达终点位置。图3所示为X>Y情形,这种是不规则形式,为确保深色阴影部分的所有边界都落在辅助区域所围成的范围内,辅助区域的左边界和右边界需以对齐各子区域起始位置沿着x方向移动|X-Y|步,剩余辅助区域的左边界和右边界沿着z方向前进。图4所示为X<Y情形,这种是不规则形式,为确保深色阴影部分的所有边界都落在辅助区域所围成的范围内,各子区域起始位置处的辅助区域的左边界和右边界需沿着y方向移动|Y-X|步,剩余辅助区域的左边界和右边界沿着z方向前进。

图2 X=Y形式的关键区域

图3 X>Y形式的关键区域

图4 X<Y形式的关键
最后,由图2~4所示的浅色区域即为添加的辅助区域,浅色区域和深色区域共同组成的部分即为最终所求的关键区域。
4 算法描述
对最优路径所在关键区域进行研究可知,在关键区域内存在一条最优路径可以快速地直接求得两字符串之间的编辑距离值。最优路径中相邻两关键节点之间后一个关键节点的值由其前一个关键节点的值求得,区域内其他非关键节点的值作为关键节点的参照与关键节点上的值做比较,并不直接参与最优路径上值地计算。关键区域确保最优路径上所有关键节点都位于该区域内,因此只要求得关键区域内所有节点的值,即可求两字符串之间的最小编辑距离值。算法用二维数组LD[1…X][1…2Y]保存关键区域内所有节点的计算结果,整个关键区域按x方向长度为X、y方向长度为2Y划分为各个子区域,子区域个数N(sub-area)≥3。对所有子区域采用动态规划方法进行迭代计算,经过最后一步计算操作LD[][]中所保存的结果即为所求的最小编辑距离值。关于关键区域边界节点的求值问题,根据添加辅助区域,右边界沿着y方向向右延伸,左边界沿着x方向向下延伸。由性质1知,关键区域右边界节点值可由沿着y方向或者z方向前进的节点求得,关键区域左边界节点值可由沿着x方向或者z方向前进的节点求得。核心算法如下,表示关键区域的每一个子区域的求解过程。
通过迭代计算关键区域内所有子区域的值,最后求得的值即为两字符串之间的编辑距离值。
5 算法效率分析
设源字符串与目标字符串的长度分别为m和n,根据关键区域的结构特点,基于最优路径策略的关键区域算法在计算编辑距离值过程中所用空间为(m/3)×(2n/3),即该算法与原算法相比在空间改进方面由(m×n)变为((2/9)×(m×n)),较原算法提升了(7/9);所用时间按基本循环操作次数进行估量使原算法的问题求解规模由(m×n)变为(m/3)×(2n/3)×3,即时间效率提升方面变为((2/3)×(m×n)),较原算法提升(1/3),可以看出改进后的算法在时间上和空间上都优于Levenshtein算法。
6 实验结果与分析
为验证基于最优路径策略的关键区域算法较Levenshtein算法在时间和空间性能上的提高,选择环境为Dell OptiPlex 790,CPU 3.10GHZ,内存8GB条件下进行实验。实验数据采用从字符个数范围为200~20000抽出100组不同长度的源字符串和目标字符串。
图5为基于最优路径策略的关键区域算法和Levenshtein算法分别计算不同长度字符串之间的编辑距离值所用的时间对比情况(时间单位:秒),算法用一个二维数组保存中间结果。图中不同算法名称简写所代表的具体算法类型说明如下。
CA-I算法:基于最优路径策略的关键区域算法(critical area),采用一个二维数组保存求解结果;
LV算法:Levenshtein[1]算法,采用一个二维数组保存求解结果。
由图5可知,当字符串长度达到一定值时LV算法所用时间大于CA-I算法所用时间。
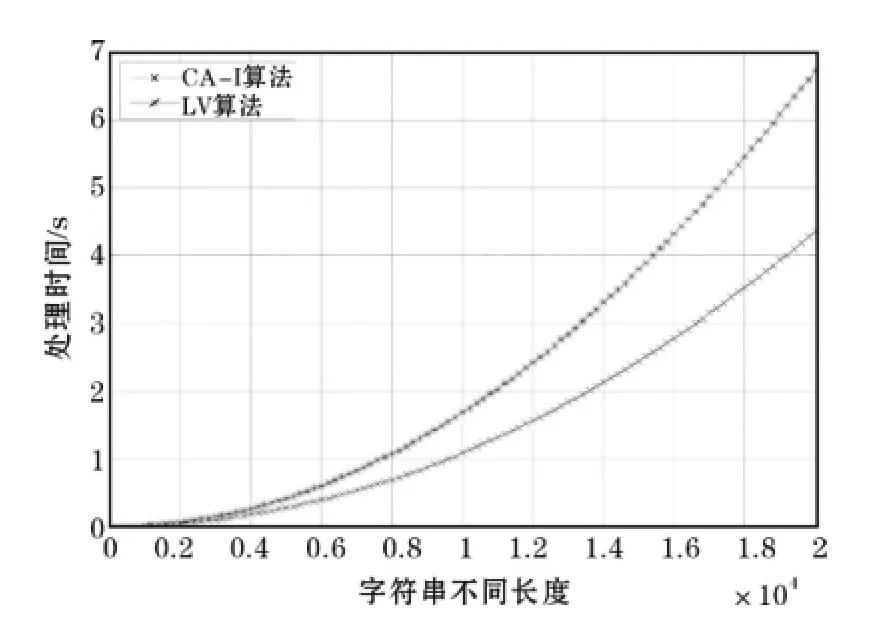
图5 CA-I算法和LV算法随着字符串长度变化所用时间对比图

图6 CA-II算法和SH算法随着字符串长度变化所用时间对比图
Sten Hjelmqvist提出采用两个一维数组分别保存每一次迭代求解的结果,使Levenshtein算法所用空间减少为2×min(m,n),即空间复杂度为O(2×min(m,n))。基于Sten Hjelmqvist算法思想采用两个一维数组分别对基于最优路径策略的关键区域算法和Levenshtein算法进行改进,对比分析计算不同长度字符串之间的编辑距离值所用的时间(时间单位:秒),实验环境和实验数据与图5一致,实验结果如图6所示。图中不同算法名称简写所代表的具体算法类型说明如下:
CA-II算法:基于最优路径策略的关键区域算法(critical area),采用2个一维数组分别保存前一行和当前行的求解结果;
SH算法:Sten Hjelmqvist算法,基于Levenshtein算法采用2个一维数组分别保存前一行和当前行的求解结果。
由图6可知,当字符串长度达到一定值时SH算法所用时间大于CA-II算法所用时间。
针对图5和图6的实验结果进行分析:设LV算法、SH算法、CA-I算法、CA-II算法所用时间分别为t(LV)、t(SH)、t(CA-I)、t(CA-II)。LV算法和SH算法需要遍历矩阵LD[m][n]整个区域,问题求解规模为(m×n);CA-I算法和CA-II算法只需遍历矩阵LD[m][n]中的关键区域,问题求解规模降低为((2/3)×(m×n)),因此t(LV)>t(CA-I),t(SH)>t(CA-II)。上述4种算法的问题求解规模和空间需求差异如表1所示。

表1 不同算法时间复杂度和空间复杂度对比
针对图5和图6的实验结果对比分析可得基于最优路径策略的关键区域算法CA-I、CA-II较传统针对矩阵所有区域进行遍历的算法LV、SH在时间性能上都有所提高,对比不同算法所提高的时间性能用时间加速比(Time Speedup Rate)描述。定义时间加速比的计算公式为(t()为时间函数,A和B表示2种不同的算法)
算法A较算法B时间加速比

图5、6中实验采用100组不同的实验数据,因此计算时间加速比的平均值作为衡量不同算法的时间性能对比情况,计算公式为(TSRi为第i组数据的时间加速比,n为总的数据组数)
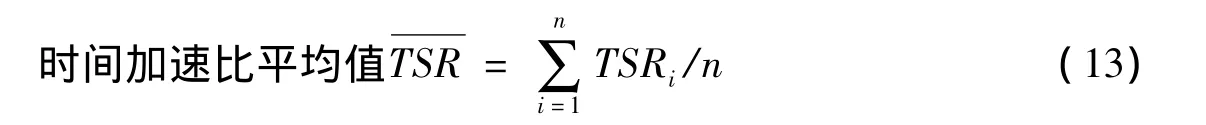
对应算法的时间平均加速比如图7所示。
由图7可看出,基于最优路径策略的关键区域算法较传统算法在时间性能上的提高超过20%,理想情况下超过30%。因为基于最优路径策略的关键区域算法的问题求解规模为((2/3)×(m×n)),是传统算法的2/3(传统算法的问题求解规模为(m×n))。

图7 相应算法时间提高对比图

图8 LV算法和SH算法随着字符串长度变化所用时间对比图
图9 CA-I算法和CA-II算法随着字符串长度变化所用时间对比图
另外通过分析图8和图9中的实验结果可以看出算法的执行时间t(LV)≥t(SH),t(CA-I)≤t(CA-II)。从理论上分析LV算法和SH算法需遍历矩阵LD[m][n]的整个区域并计算相应位置上的值,基于LV算法是构造一个范围大小为m×n的矩阵区域并遍历计算该区域内所有位置上的值,需要分配的物理内存大小为m×n;而基于SH算法是构造两个长度为n的线性区域,需要分配的物理内存大小为2×n,但每计算完一次线性区域内所有位置上的值后都需要针对线性区域内每一个位置上的值执行一次复制操作[3]。CA-I算法和CA-II算法只需遍历并计算矩阵区域LD[m][n]中关键区域内各个位置上的值,CA-I算法需要分配的物理内存大小为X×2×Y(X≪m,Y≪n,符合“≪”表示远小于,下同),遍历计算方式同LV算法;CA-II算法需要分配的物理内存大小为2×Y(Y≪n),遍历计算方式同SH算法。因此基于内存分配和CPU时钟频率因素而出现了算法执行时间t(LV)≥t(SH)和t(CA-I)≤t(CA-II)2种不一致的情形。
7 结束语
在研究传统编辑距离算法的基础上提出一种改进方法,即在原算法进行计算过程中所形成的矩阵区域内存在一条最优路径,通过最优路径可以直接求出两字符串之间的编辑距离。然而,基于Levenshtein编辑距离算法的基本思想最优路径中关键节点上的值受其相邻的非关键节点的影响,因此,提出基于最优路径策略方法的关键区域算法思想计算两字符串之间的编辑距离,该方法虽然没有仅仅基于最优路径的方法高效,但与传统编辑距离算法相比缩小了整个问题的求解规模,适用于求解长字符串之间的编辑距离问题,提高了问题的求解速度。针对算法特点该算法对源字符串长度大于等于目标字符串长度且都大于或等于3的情形所获得的处理结果更理想,未来的研究工作可从如何确定仅仅通过最优路径即可计算两字符串之间的编辑距离入手并实现构造最优路径的并行化工作,进一步优化编辑距离算法。此外,所描述的改进思想同样适用于图论中使用动态规划方法求解一般问题地应用,比如最优分配问题和背包问题等。
[1] Levenshtein V I.Binary codes capable of correcting deletions,insertions and reversals[C].Soviet physics doklady,1966,10:707.
[2] Wagner R A,Lowrance R.An extension of the string-to-string correction problem[J].Journal of the ACM(JACM),1975,22(2):177-183.
[3] Hjelmqvist Sten.Fast,memory efficient Levenshtein algorithm[EB/OL].http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm,2012.
[4] 赵作鹏,尹志民,王潜平,等.一种改进的编辑距离算法及其在数据处理中的应用[J].计算机应用,2009,29(2):424-426.
[5] 吴玲,秦志光,石竑松,等.分段处理的1/p概率字符串匹配[J].计算机科学,2008,35(7):91-95.
[6] Monge A E,Elkan C P.Efficient domain-independent detection of approximately duplicate database records[C].Proc.of the ACM-SIGMOD Workshop on Research Issues in on Knowledge Discovery and Data Mining,1997.
[7] Hernández M A,Stolfo S J.The merge/purge problem for large databases[C].ACM SIGMOD Record.ACM,1995,24(2):127-138.
[9] 董国卿,童维勤.数据库元数据的自动语义标注[J].计算机科学,2012,(3).
[10] Cohen W W.Data integration using similarity joins and a word-based information representation language[J].ACM Transactions on Information Systems(TOIS),2000,18(3):288-321.
[11] Bakker D,Müller A,Velupillai V,et al.Adding typology to lexicostatistics:a combined approach to language classification[J].Linguistic Typology,2009,13(1):169-181.
[12] Holman E W,Wichmann S,Brown C H,et al.Advances in automated language classification[J].Quantitative Investigations In Theoretical Linguistics(QITL3),2008:40.
[13] Petroni F,Serva M.Measures of lexical distance between languages[J].Physica A:Statistical Mechanics and its Applications,2010,389(11):2280-2283.
[14] Wichmann S,Holman E W,Bakker D,et al.Evaluating linguistic distance measures[J].Physica A:Statistical Mechanics and its Applications,2010,389(17):3632-3639.
[15] Gooskens C,Heeringa W.Perceptive evaluation of Levenshtein dialect distance measurements using Norwegian dialect data[J].Language variation and Change,2004,16(3):189-207.
[16] Beijering K,Gooskens C,Heeringa W.Predi-cting intelligibility and perceived linguistic distance by means of the Levenshtein algorithm[J].Linguistics in the Netherlands,2008,25(1):13-24.
[17] Brill E,Moore R C.An improved error model for noisy channel spelling correction[C].Proceedings of the 38th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2000:286-293.
[18] R Durbin.Biological sequence analysis:probabi-listic models of proteins and nucleic acids[M].Cambridge university press,1998.
[19] Patil N,Toshniwal D,Garg K.Genome data classification based on fuzzy matching[J].CSI Transactions on ICT,2013,1(1):9-28.
[20] Myers E W.An O(ND)difference algorithm and its variations[J].Algorithmica,1986,1(1-4):251-26.
