制造业上市公司财务危机预警模型
2013-12-23贾炜莹,申贵成
贾 炜 莹 , 申 贵 成
(1.北京物资学院商学院, 北京市101149;2.北京物资学院信息学院, 北京市101149)
一、引言
随着经济一体化和全球化的发展,企业所面临的风险越来越复杂、广泛,因财务危机导致企业陷入经营困境甚至破产的案例屡见不鲜,于是财务风险管理变得举足轻重,财务危机预警也愈来愈被引以为重。对企业财务危机进行准确预测分析,既是市场竞争机制的客观要求,也是企业继续生存的重要条件。财务危机的发生并非突然,它是一个逐步、渐进的动态过程,因此财务危机是可以预测的。正确地预测财务危机,对政府部门监管上市公司质量和证券市场风险,对投资者和债权人保护自身利益,对企业经营者防范财务危机,都具有十分重要的现实意义。
20 世纪30 年代,国外学者就开始对财务危机预警模型进行研究。菲茨帕特里克(FitzPatrick)进行了单变量模型的开拓性研究,他选取19 家公司作为样本,比较分析了危机公司与健康公司的财务指标,认为对于财务危机判别能力最高的是净利润/股东权益和股东权益/负债两个比率。比弗(Beaver)提出了较为成熟的单变量模型,他随机挑选79 家经营正常公司和79 家经营失败公司进行一元判定预测,发现现金流量/总负债的预测能力最强,其次是资产负债率。[1]单变量模型具有简便易行的优点,但是单变量模型只是利用个别比率指标预测财务危机,而企业的生产经营活动受到许多因素的影响,采用不同的财务指标对同一个企业进行预测时,往往会得出不同甚至相悖的结果,因此单变量模型逐渐被多变量模型替代。奥特曼(Altman)率先采用多元判别模型对企业财务危机预警进行研究,他选取33 家破产公司和33 家非破产公司构建了Z-Score 模型。[2]多元判别模型运用较为容易,但建模前提是自变量呈正态分布且两组样本协方差相等,然而现实的样本数据往往不能满足这一要求,这就大大限制了多元判别模型的使用范围。奥尔森(Ohlson)采用逻辑(Logistic)回归方法构建了财务预警模型,并发现公司规模、资本结构、业绩和当前的变现能力4 个指标有显著的预测能力。[3]逻辑回归模型建立在累计概率函数基础上,不需要自变量服从多元正态分布和两组间协方差相等的假设,克服了线性方程受统计假设约束的局限性。但是逻辑回归模型对多重共线性敏感,当解释变量之间的相关程度较高时,样本的较小变化将会带来系数估计较大的变化,从而降低模型的预测效果。
国内的财务危机研究起步较晚,主要是利用国外的方法来建立中国的预警模型。吴世农和黄世忠首次在我国介绍了企业破产的分析指标和预警模型,运用统计方法进行定量分析。[4]周首华、杨济华和王平利用1977~1990 年的62 家公司建立了F 分数模型。[5]陈静以1998 年的27 家ST 公司和27 家非ST 公司为样本,使用了1995~1997 年的财务报表数据,进行了单变量分析和多元线性判定分析。[6]吴世农和卢贤义应用费雪(Fisher)线性判定、多元线性回归和逻辑回归分析三种方法,分别建立了三种预测财务危机的模型,并检验了其在财务危机出现前5 年的预测准确率。[7]
总结前人的研究,笔者有以下几点思考。(1)由于研究年份较早、样本量较少,因此会影响到公众对预测精度和判别结果的正确解读。(2)在构建模型过程中,研究人员一般没有检验财务比率的数据分布特征而是假定服从正态分布。事实上,数据的分布特征将决定统计方法的选择。(3)由于我国上市公司在出现财务状况异常被ST 之前,都已连续两年亏损或每股净资产低于股票面值,所以采用上市公司被ST 前两年的年报预测其是否会陷入财务危机显然会夸大模型的预测能力。
本文的研究与以前有所不同。一是样本新、时间长、容量大、行业统一。本文选取2001~2011 年间存在财务危机的企业181 家以及配对健康企业181 家作为研究对象,样本量达到362 家。二是初始预测指标选取范围广、数量多。为了避免因随机选取初始指标而带来的重要指标遗漏的局限,本文选取了5 大类23 项财务指标作为初始预警指标。三是利用主成分分析法筛选回归变量。本文利用主成分分析法计算主成分的特征向量并以此为权重计算回归变量。
二、研究设计
1. 样本选取
我国ST 制度的采纳和应用,使得国内研究大部分采用了因为“财务状况异常”而被特别处理(ST)作为界定财务危机的标准。与国内研究保持一致,本文从沪、深两市选取2001 年至2011 年首次被特别处理的制造业上市公司作为发生财务危机的样本(包括ST 和*ST),剔除纯B 股的公司、由于其他状况异常而被ST 的公司、数据缺省及数据不合理的公司。这样,我们得到181 家财务危机公司,其中2001 年13 家,2002 年21 家,2003 年27家,2004 年14 家,2005 年14 家,2006 年20 家,2007 年25 家,2008 年9 家,2009 年12 家,2010年17 家,2011 年9 家。
与ST 公司的选取相对应,本文按照行业相同、会计年度相同、资产规模相近的原则选取181家未被特别处理的上市公司作为财务健康公司。这样,我们最终得到362 家样本公司,将2001 年至2007 年268 家公司作为建模样本,2008 年至2011 年94 家公司作为检验样本。
由于我国证监会是根据上市公司前两年的年报所公布的业绩判断其是否出现财务状况异常并决定是否要对其进行特别处理的,所以采用上市公司前两年的年报预测其是否会被ST 显然会夸大模型的预测能力。因此,本文以ST 公司被“特别处理”的前三年作为样本的时间范围,即选择在上市公司被ST 的前三年进行预测,判断其最终是否会陷入财务危机。
2. 预警指标选取
财务预警指标的选取对于财务危机预警研究具有非常重要的影响,科学的指标不仅应具有较好的分类能力,而且应有效简化模型。国内外很多学者已经利用财务指标对公司财务危机预警进行了实证研究,尽管不同学者得出的预测公司发生财务危机的有效财务指标不同,但基本上是从公司的偿债能力、盈利能力和营运能力等方面进行研究的。通过国内重要的文献索引并结合前人研究企业财务危机预警指标体系的研究,考虑到资料的可获得性与适用性,本文从偿债能力、盈利能力、营运能力、成长能力和获取现金能力5 个方面选取了23 项财务指标,具体如表1 所示。
3.研究方法
主成分分析是以最少的信息损失,将众多的原始变量浓缩成为少数几个主成分变量,使变量具有更高可解释性的一种多元统计方法。主成分变量并非原始变量的简单取舍,而是将众多彼此可能存在相关关系的财务指标变量转换成较少的、彼此不相关的综合指标,可以有效地克服原始变量之间的多重共线性。其表达式为:
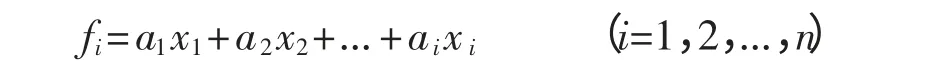
主成分分析方法一方面能考虑更多一些对财务危机有指示作用的财务指标,另一方面又不会因为财务指标太多而增加分析问题的复杂性。
三、实证结果与分析
1. 差异性检验
为了能有效地区分财务危机公司和健康公司,需要知道两组公司之间哪些财务指标具有显著差异。为了筛选出具有显著差异及表征能力的变量指标,首先必须对指标的样本数据进行正态性检验,以确定是采用参数检验或者非参数检验来确定指标变量的差异性。
本文首先对变量的样本序列进行K-S 检验,检验样本序列是否服从正态分布。从表2 可以看出,在a=0.05 的显著性水平下,仅X4(资产负债率)的K 统计量的P 值大于0.05,因此该指标的样本总体服从正态分布,其余22 个指标的样本总体不符合正态分布。这一结果与国外的实证检验结果一致。根据正态分布检验结果,本文分别采用参数T 检验和非参数Z 检验,来检验23 个变量是否有显著差异。从表2 可以看出,在a=0.05 的显著性水平下,ST 公司与健康公司的全部23 个指标均具有显著差异。
尽管已经筛选出具有显著差异的变量,但这些变量可能彼此之间高度相关,即存在多重共线性的可能。为此,本文采用主成分分析法从众多指标中提取主成分,再选用几个主成分建立模型。
2. 适用性检验
模型数据是否适合主成分分析要通过KMO和巴特利特(Bartlett’s)球形检验来考察。检验结果显示KMO 统计量(0.704)大于0.5,且巴特利特球形检验值为4941.569,显著性(0.000)小于0.05,表明相关系数矩阵单位矩阵有显著差别,说明样本适合进行主成分分析。
3. 标准化处理
为避免由于量纲不同而造成的结果差异,本文首先对所选原始数据进行标准化,使各指标的均值为0,方差为1。采用z-score 标准化方法进行数据标准化处理,标准化公式为:
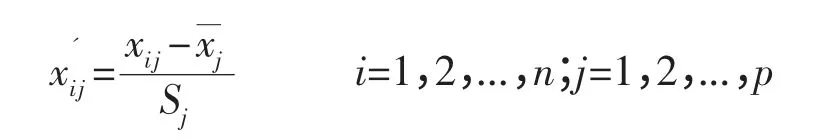
其中xij为原始数据,为第j 个指标的平均数,Sj为其标准差,n 为样本数,p 为指标数。
4. 主成分提取
根据表3 所示的主成分特征值与贡献率可以看到,前11 个主成分的累积贡献率达到了86.785%,根据主成分累计贡献率大于85%的标准,提取这11 个主成分来代替原始的财务指标。
5. 主成分经济解释
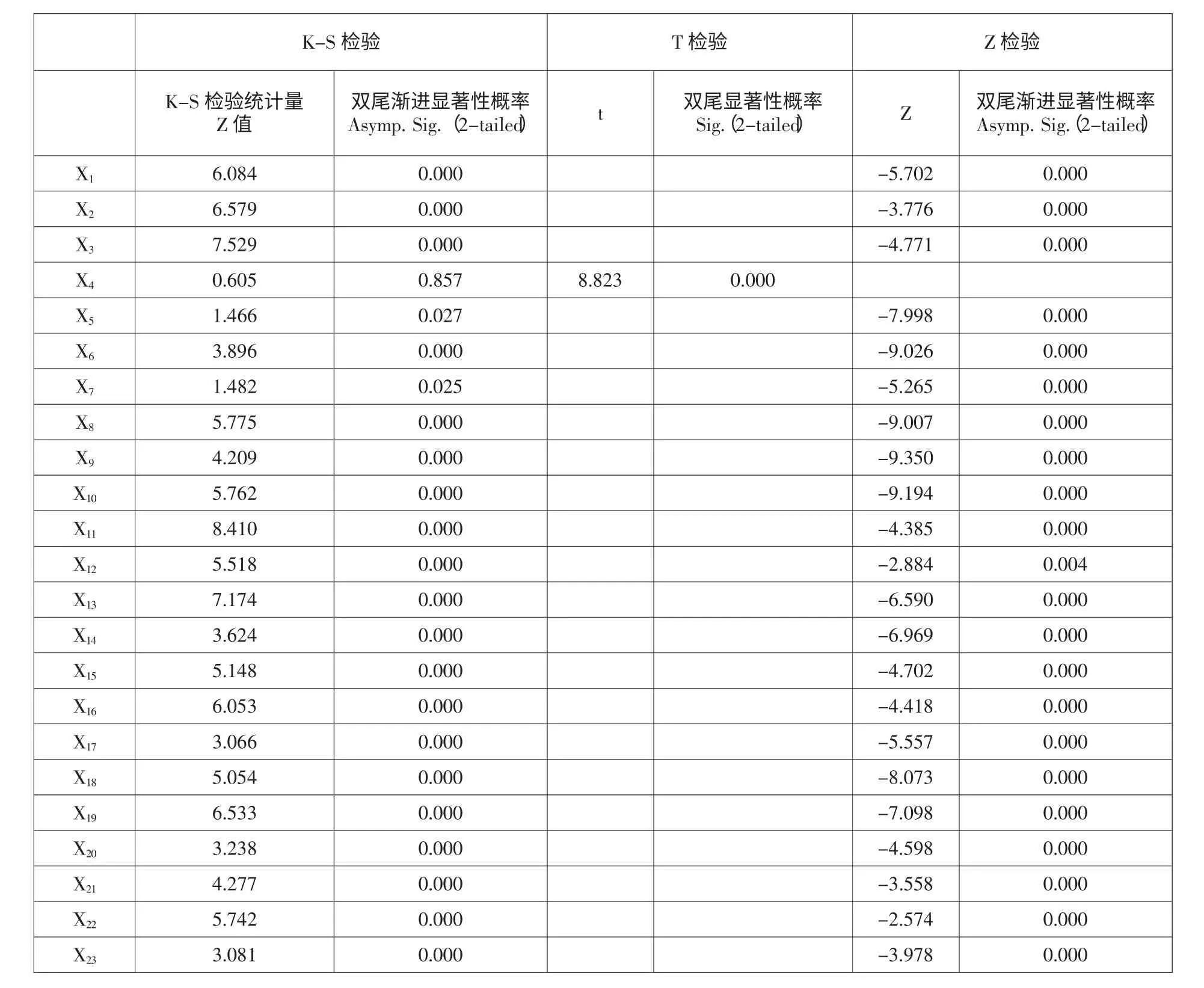
表2 K-S 检验、T 检验和Z 检验结果
通过表4 方差最大化旋转后的主成分因子载荷矩阵还可以看出,主成分f1主要由变量x1(流动比率)、x2(速动比率)和x3(现金比率)解释,反映公司的偿债能力;主成分f2主要由变量x20(现金流动负债比率)、x21(每股经营现金净流量)和x23(总资产现金回收率)解释,反映公司的现金获取能力;主成分f3主要由变量x4(资产负债率)、x5(每股净资产)、x6(每股收益)、x9(资产净利率)和x10(净资产收益率)解释,反映公司的盈利能力;主成分f4主要由变量x13(流动资产周转率)和x14(总资产周转率)解释,反映公司的营运能力;主成分f5主要由变量x17(总资产增长率)和x18(净资产增长率)解释,反映公司的成长能力。其余几个主成分,f6主要由变量x8(销售净利率)和x22(销售现金比率)解释,f7主要由变量x7(主营业务利润率)解释,f8主要由变量x12(存货周转率)解释,f9主要由变量x16(主营业务利润增长率)解释,f10主要由x19(净利润增长率)解释,f11主要由变量x15(主营业务收入增长率)解释。
6. 主成分得分矩阵
在确定了各个主成分的经济意义之后,还要确定各主成分关于原始财务指标的线性表达式,这由主成分得分系数矩阵提供,如表5 所示。通过主成分得分系数矩阵可以计算出11 个主成分得分函数:
f1=0.333x1+0.336x2+0.344x3-0.03x4-0.02x5-0.017x6+0.004x7+0.01x8-0.006x9-0.063x10+0.002x11-0.046x12+0.018x13+0.032x14+0.004x15+0.008x16-0.016x17-0.018x18+0.005x19-0.027x20+0.022x21-0.004x22+0.009x23
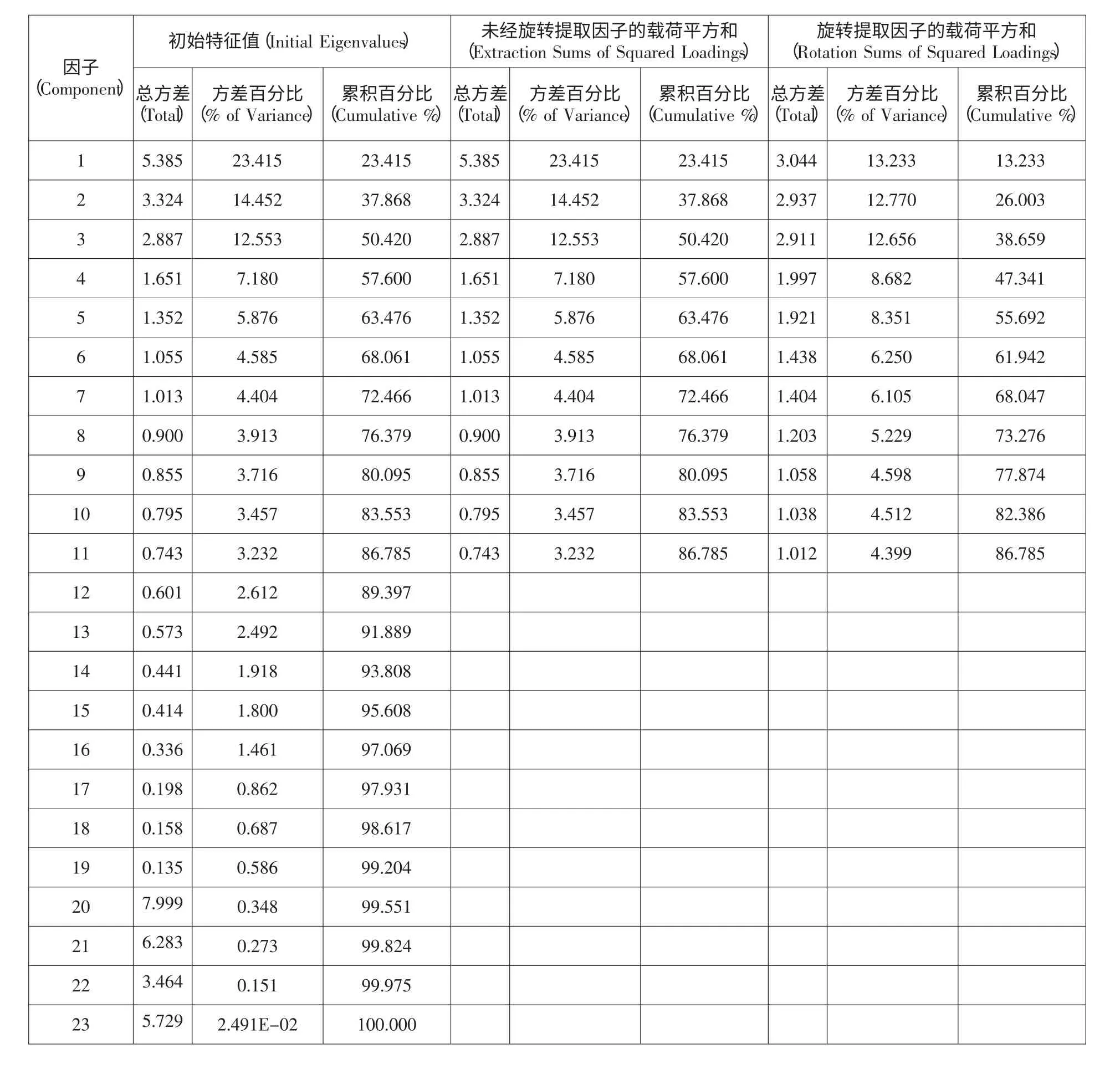
表3 主成分特征值与贡献率
f2=-0.011x1+0.002x2-0.009x3-0.123x4+0.028x5-0.072x6+0.013x7-0.137x8-0.051x9-0.079x10+0.002x11-0.056x12+0.01x13-0.069x14-0.009x15+0.064x16+0.014x17+0.094x18+0.04x19+0.348x20+0.345x21+0.122x22+0.342x23
f3=-0.015x1-0.047x2-0.074x3-0.333x4+0.247x5+0.257x6-0.122x7+0.000x8+0.189x9+0.54x10-0.033x11-0.063x12-0.036x13-0.055x14-0.011x15-0.053x16-0.213x17-0.084x18-0.093x19-0.031x20-0.032x21-0.086x22-0.053x23
f4=0.013x1+0.02x2+0.074x3+0.17x4+0.076x5+0.055x6-0.016x7+0.024x8+0.056x9-0.095x10-0.047x11-0.05x12+0.518x13+0.551x14+0.004x15+0.006x16-0.018x17-0.134x18-0.056x19-0.054x20-0.003x21-0.156x22-0.016x23
f5=-0.022x1-0.006x2-0.036x3-0.015x4+0.078x5-0.083x6-0.062x7-0.142x8-0.056x9-0.254x10+0.008x11+0.008x12-0.068x13-0.06x14+0.015x15-0.047x16+0.598x17+0.63x18+0.008x19+0.105x20-0.001x21+0.106x22+0.04x23
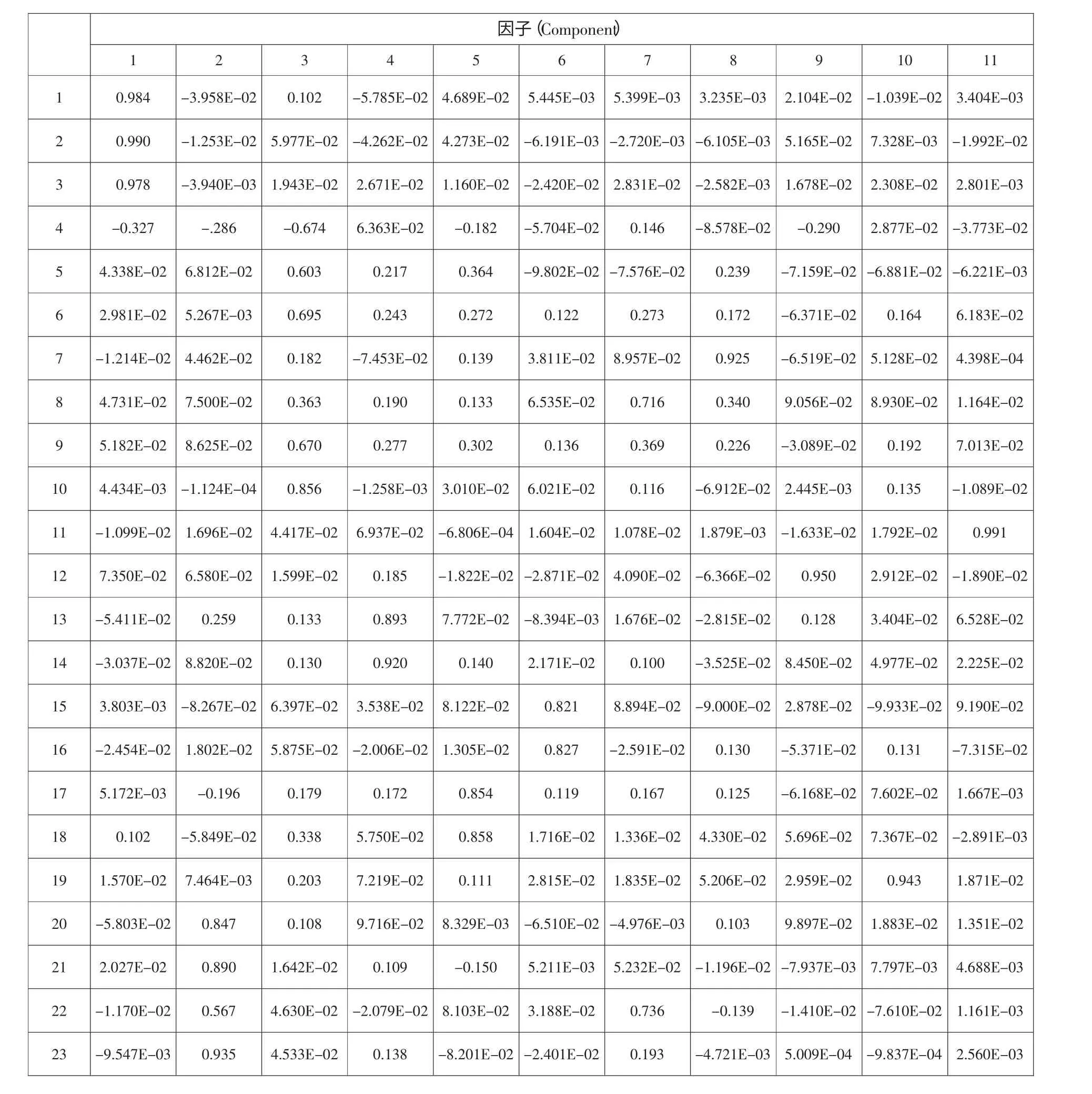
表4 旋转后的因子载荷矩阵
f6=0.009x1+0.007x2-0.007x3-0.038x4-0.105x5+0.007x6+0.005x7-0.045x8+0.013x9-0.026x10-0.013x11+0.005x12+0.006x13+0.009x14+0.591x15+0.608x16+0.022x17-0.037x18-0.026x19-0.007x20+0.051x21-0.027x22+0.013x23
f7=0.013x1+0.008x2+0.038x3+0.285x4-0.227x5+0.099x6-0.051x7+0.571x8+0.168x9+0.008x10-0.014x11+0.071x12-0.118x13-0.017x14+0.009x15-0.139x16+0.045x17-0.114x18-0.048x19-0.19x20-0.117x21+0.6x22+0.000x23
f8=0.000x1+0.003x2+0.017x3+0.019x4+0.102x5-0.02x6+0.897x7+0.22x8+0.033x9-0.27x10+0.013x11+0.058x12+0.014x13-0.012x14-0.109x15+0.109x16-0.039x17-0.138x18-0.064x19+0.09x20-0.006x21-0.248x22-0.025x23
f9=-0.055x1-0.028x2-0.073x3-0.247x4-0.117x5-0.104x6+0.056x7+0.117x8-0.067x9-0.053x10+0.015x11+0.953x12-0.036x13-0.074x14+0.05x15-0.024x16-0.028x17+0.071x18+0.004x19+0.05x20-0.086x21-0.019x22-0.074x23
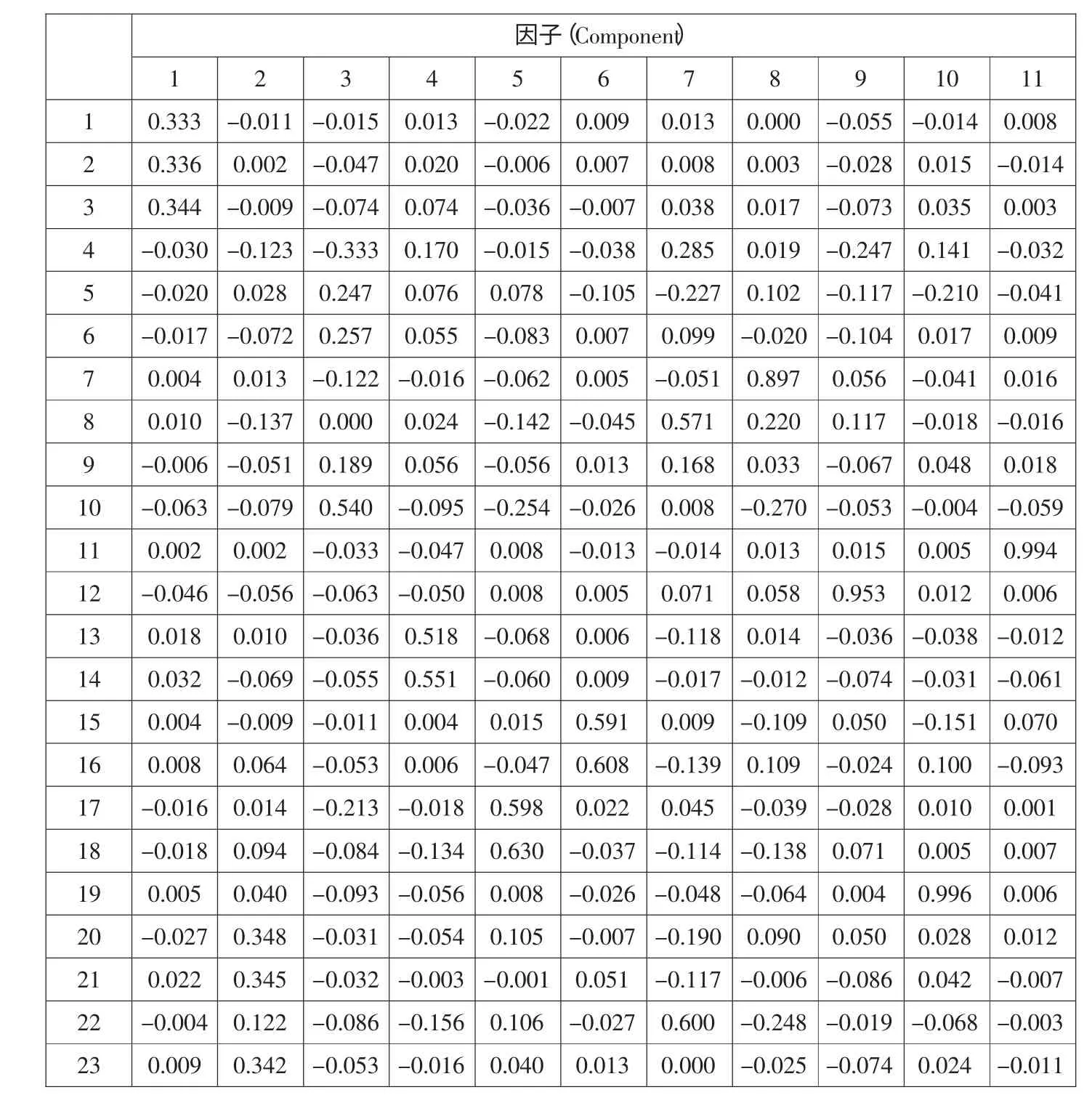
表5 主成分得分系数矩阵
f10=-0.014x1+0.015x2+0.035x3+0.141x4-0.21x5+0.017x6-0.041x7-0.018x8+0.048x9-0.004x10+0.005x11+0.012x12-0.038x13-0.031x14-0.151x15+0.1x16+0.01x17+0.005x18+0.996x19+0.028x20+0.042x21-0.068x22+0.024x23
f11=0.008x1-0.014x2+0.003x3-0.032x4-0.041x5+0.009x6+0.016x7-0.016x8+0.018x9-0.059x10+0.994x11+0.006x12-0.012x13-0.061x14+0.07x15-0.093x16+0.001x17+0.007x18+0.006x19+0.012x20-0.007x21-0.003x22-0.011x23
7. 预警模型的构建
根据表3 中各主成分因子的贡献率,可以得到制造业上市公司的财务预警模型:
f=(13.233 f1+12.77 f2+12.656 f3+8.682 f4+8.351f5+6.25f6+6.105f7+5.229 f8+4.598f9+4.512 f10+4.399f11)/100
将建模样本组标准化后的财务指标代入主成分得分函数得到各主成分的数据,再根据财务危机预警函数模型计算得到各上市公司的预警分值,并按预警分值由大到小排序。预警分值越高代表公司的财务状况越好,相反,预警分值越低则公司的财务状况越差。然后,根据判别分类错误总数最小原则,确定判别分割点在0.4144 和0.4788 之间,取其平均数0.4466 为ST 公司和健康公司的PS 值分割点,从表6 的建模样本判定结果可以看到模型总体正确率为73.88%,由此可见模型的适用程度较高。
8. 预警模型的检验
为了进一步检验以上模型的效果,本文将选取的2008 年至2011 年首次被ST 的47 家上市公司和与其配对的47 家公司组成的检验样本的财务指标变量的主成分得分代入上述构建的财务危机预警模型中,运用建模样本获得的分割点,得到检验结果如表7 所示。可以看出,检验样本中,在47 家ST 公司中被误判为非ST 公司的有12 家,检验的准确率为74.47%;在47 家非ST 公司中被误判为ST 公司的有10 家,检验的准确率为78.72%。综合检验结果的准确率达到74.47%。这也进一步证明了模型的效果。
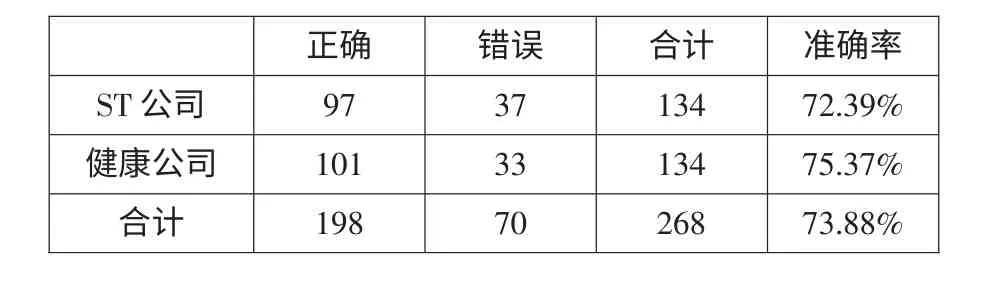
表6 建模样本结果
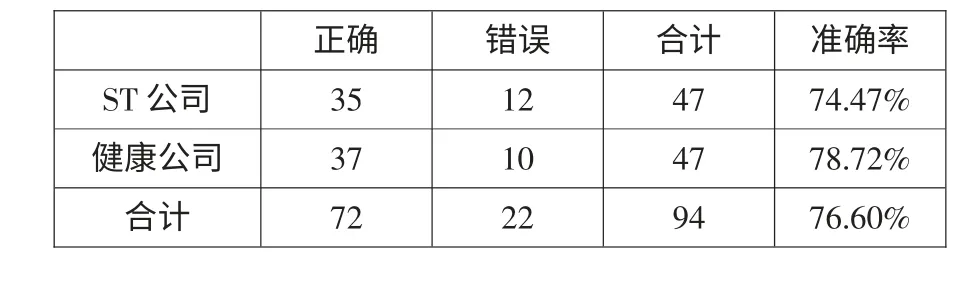
表7 检验样本结果
四、研究结论
考虑到已有企业财务危机预警模型存在的缺陷,本文选取我国制造业2001 年至2011 年首次被ST(包括*ST)公司和正常公司各181 家为样本,以被ST 前3 年传统财务指标为基础,构建了上市公司财务危机预警的主成分分析模型。该模型对建模样本的预测正确率为73.88%,对检验样本的预测正确率为76.60%,结果表明该模型具有超前3 年的预测效果。业内人士均知道,ST 公司是在连续2 年出现亏损后被给予ST 处理的,超前3年恰好是ST 公司开始出现亏损的前一年,换言之,本模型在ST 公司“戴帽”前3 年或ST 公司开始出现亏损的前一年就可预知公司的前景。
本文在研究上也存在着一定的局限性,一是与国内众多学者一样,公司样本的选择还局限于上市公司,这就限制了模型的适用范围。二是本文对模型的构建基础仅限于财务指标,有关的宏观环境、行业竞争情况和公司治理等影响企业财务状况的非财务指标因素没有纳入研究。三是本文在建立模型时,只选择了制造业,没有考虑其他行业。这些在以后的研究中需要进一步改进和完善。
*本文系北京市属高等学校人才强教深化计划资助项目中青年骨干人才培养计划(项目编号:PHR201008224)的部分研究成果。
[1]Beaver W.Financial Ratios as Predictors of Failure [J].Supplement to Journal of Accounting Research,1966(4):71-111.
[2]Altman E.Financial Ratios,Discriminant Analysis and the Prediction of Corporate Bankruptcy [J].Journal of Finance,1968(9):589-609.
[3]Ohlson J.Financial Ratios and the Probabilistic Prediction of Bankruptcy [J].Journal of Accounting Research,1980(18):109-131.
[4]吴世农,黄世忠.企业破产的分析指标和预测模型[J].中国经济问题,1986(6):15-22.
[5]周首华,杨济华,王平.论财务危机的预警分析-F 分数模式[J].会计研究,1996(8):8-11.
[6]陈静.上市公司财务恶化预测的实证分析[J].会计研究,1999(4):31-38.
[7]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001(6):46-56.
