基于多特征组合优化的汉语数字语音识别研究
2013-12-21蔡敏
蔡 敏
(苏州工业园区工业技术学院机电中心,江苏 苏州215123)
汉语数字语音识别是语音识别领域中一个重要的分支,在日常生活中的电话拨号、人机交互、密码身份识别等领域都有着重要的应用价值,但由于汉语数字语音的发音特点,容易产生互相之间混淆,导致识别率不高。
汉语数字语音识别系统主要包括了语音特征提取和分类器两部分[1]。特征参数的选择是其中的关键问题。线性预测倒谱系数[2](LPCC)参数是根据声管模型建立的特征参数,可以准确反映声道响应信息。梅尔频率倒谱系数[3](MFCC)参数则充分考虑了人耳的听觉特性,具有较好的鲁棒性和识别性能。
本文首先提取了汉语数字语音的LPCC 参数、MFCC 参数及其一阶差分,并进行特征组合。针对每个语音每帧均需要提取系数,导致维数过高的问题,按照参数矩阵按列求取均值和方差的方法进行首次降维,随后采用基于关联规则的特征选择算法[4]进行二次降维,最后采用C4.5 决策树算法[5]进行识别实验。
1 特征提取算法及优化
1.1 线性预测倒谱系数(LPCC)
线性预测分析技术就是由语音信号直接求出一组线性预测系数,通过在最小均方误差准则条件下求预测系数的最佳估计值,而该组预测系数恰好能反映声道的响应信息。
语音信号的声道传输函数为:

其中ai(i = 1,2,…,p)即预测系数,可采用Levinson-Durbin 递推算法求解。线性预测系数能够用于模拟声道模型,但获取系数时语音信号产生过程中的激励信息也混入其中。倒谱分析利用同态处理方法,能够将无关的激励信息从中分离出来。首先对语音信号求离散傅里叶变换,然后取绝对值的对数进行反变换,同时设计一个滤波器,把需要的声道响应信息留下来而把声门激励信号去除,就能够得到所需特征。
1.2 梅尔频率倒谱系数(MFCC)
梅尔频率倒谱参数是将人耳的听觉特性和语音的产生机制相结合而产生的一组特征参数。人耳具有一些特殊的功能,在1 kHz 以下为线性尺度,而在1 kHz 以上则为对数尺度,这就意味着人耳对低频信号更加敏感。突出低频信息有利于屏蔽噪声的干扰,提取稳定性很高的语音特征参数。
Mel 频率和实际频率的转换关系和图示如下:
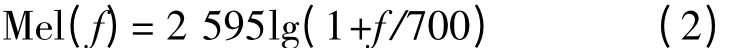
首先将信号S(n)预加重后采用汉明窗进行加窗分帧,得到每帧信号xn(m),然后通过短时傅里叶变换得到其频谱Xn(k),随后求取频谱的平方,即能量谱Pn(k)。用梅尔带通滤波器对Pn(k)进行滤波,将每个滤波器频带内的能量进行叠加,取对数功率谱并进行反离散余弦变换,即得到MFCC 系数。
1.3 特征降维
提取LPCC 和MFCC 参数后,通过求取其系数矩阵的均值和方差的方式进行一次降维,如图1 所示,得到24 阶LPCC,24 阶MFCC 及其一阶差分(24阶ΔMFCC)。
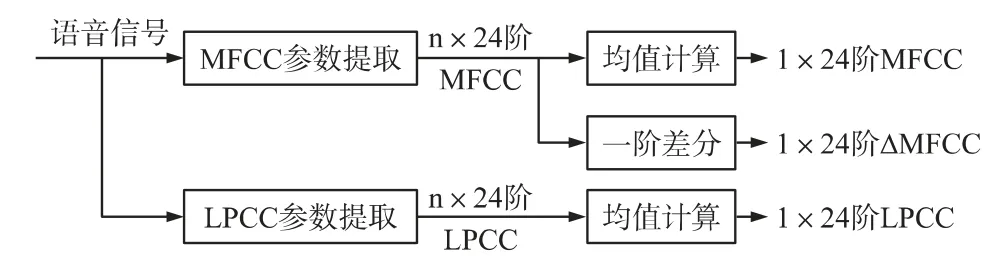
图1 MFCC、LPCC 第1 次降维过程
将完成第1 次降维后的参数,采用特征参数优化选择方法,实现二次降维。关联规则能够发现数据库中属性间隐藏的关联网,通过优先选择短规则选择相关属性,有可能得到最小的属性子集[8]。基本思想是首先挖掘后件为类属性的强关联规则,再根据关联规则参数找出与类属性密切相关的属性子集。
设I={i1,i2,…,im}是项的集合,A 是一个项集,关联规则是形如A⇒B 的蕴涵式,其中A⊂I,B⊂I,且A∩B=φ。参数描述如下:
支持度
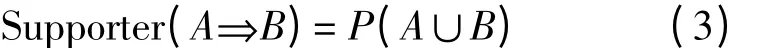
置信度
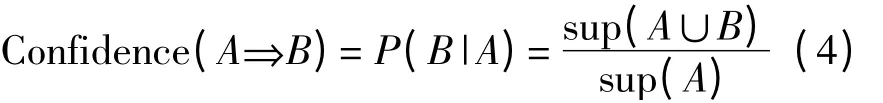
提升度
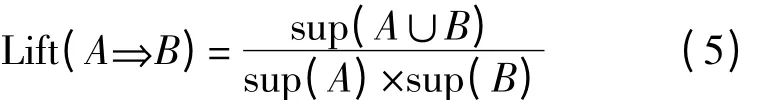
2 C4.5 决策树算法
决策树方法是数据挖掘中分类方法的一种,其核心思想是根据某种规则将测试样本生成决策树模型,然后利用生成的决策树模型对未知数据进行分类预测。决策树是一个类似流程图的树型结构,如图2 所示,采用自顶向下的递归方式,通过把样本从根节点排列到某个叶子节点来进行分类,根据不同的属性值判断从该节点向下的分支,叶节点即为实例所属的分类。

图2 决策树示意图
C4.5 决策树算法作为在经典决策树ID3 算法基础上进行了改进,以样本的最高信息增益率作为属性选择的判决依据。用离散属性A 对样本集T进行划分的信息增益率:
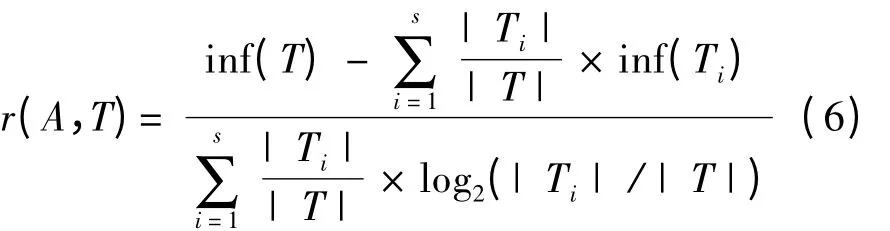
式中,inf(T)表示信息熵。
3 实验结果及数据分析
本文采用了苏州大学语音实验室录制的汉语数字语音库进行实验(SZDX-2006),语音信号的特性是11 025 Hz,16 bit,单声道。选用数字语音0 ~9各100 个,共1 000 个语音文档进行实验。
采用10 折交叉验证方式进行实验,表1 为二次降维前不同特征组合的识别通过比较发现MFCC+ΔMFCC 组合得到较高的识别结果,为94.9%,识别时间从0.1 s 到0.3 s 不等。

表1 二次降维前识别结果
对组合特征进行特征优化选取实现二次降维后实验结果如表2 所示,在保持高识别率的同时,大大缩短了识别时间。且LPCC+MFCC+ΔMFCC 的识别率识别率高达95.3%,识别时间相对较短,可信度高,误差小,由此可见采用特征组合的方法并进行二次降维以后,与二次降维前相比,去除了特征中的冗余信息,既有效的缩短了识别时间,又进一步提高了语音识别率。

表2 二次降维前识别结果
对比二次降维前后语音识别率如图3 所示,除MFCC+ΔMFCC 特征组合降维后识别率有所降低以外,MFCC,MFCC+LPCC,MFCC+LPCC+ΔMFCC 组合识别率均得到了一定的提高,且MFCC+LPCC+ΔMFCC 识别率提高到95.3%。
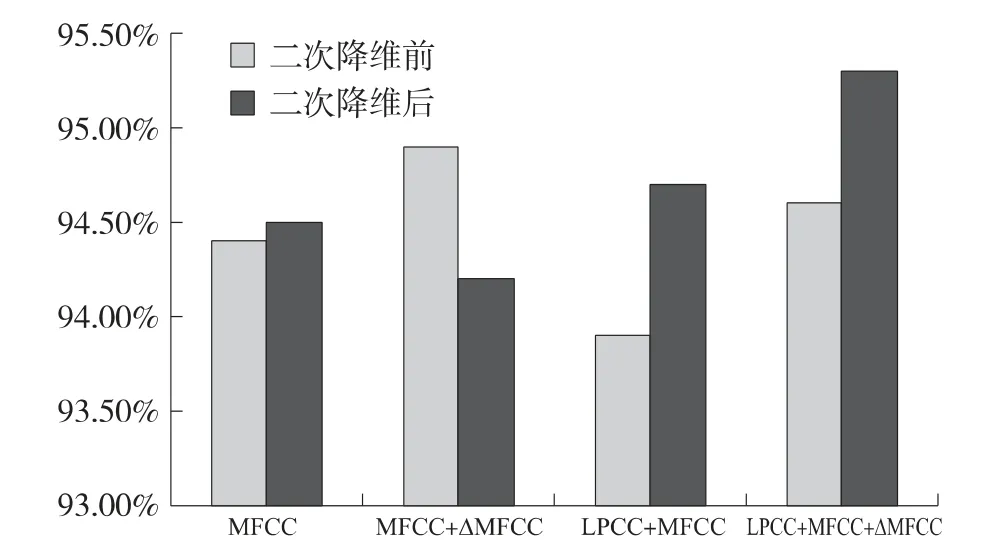
图3 二次降维前后识别率比较
4 结论
本文提取了汉语数字语音特征参数并进行组合,通过求取其系数矩阵的均值和方差的方式进行一次降维后,采用基于关联规则的特征选择算法进行二次降维处理,并采用C4.5 决策树算法进行识别,通过实验发现本文提出的方法能有效缩短识别时间,且LPCC+MFCC+ΔMFCC 的组合识别率最高,达95.3%。在今后的研究中,如何找到更优的特征降维算法和分类算法,以提高汉语数字语音的识别率,还有待于进一步研究。
[1] 刘雅琴,智爱娟.几种语音识别特征参数的研究[J].计算机技术与发展,2009:67-70.
[2] 韩纪庆,张磊,郑铁然. 语音信号处理[M]. 北京:清华大学出版社,2004.
[3] Sri Rama Murty K,Yegnanarayana B. Combining Evidence from Residual Phase and MFCC Features for Speaker Recognition[J].IEEE Signal Processing Letters,2006,13(1):52-55.
[4] 程险峰.多种关联规则挖掘算法的研究与分析[J].长春理工大学学报(自然科学版),2011:107-109.
[5] Kirchner K,Tolle K H,Krieter J.Decision Tree Technique Applied to Pig Farming Datasets[J]. Livestock Production Science,2004,90:191-200.
[6] Mahadeva Prasanna S R,Cheedella S Gupta,Yegnanarayana B.Extraction of Speaker-Specific Excitation Information from Linear Prediction Residual of Speech[J]. Speech Communication,2006,48:1243-1261.
[7] Li Fuhai,Ma Jinwen,Huang Dezhi. MFCC and SVM Based on Recognition of Chinese Vowels[J].CIS,2005:812-819.
[8] 武建华,宋擒豹,沈均毅,等. 基于关联规则的特征选择算法[J].模式识别与人工智能,2009,4:256-262.
