基于Apriori算法的高职院校课程相关性分析
2013-12-06傅亚莉
傅亚莉
(无锡科技职业学院,江苏 无锡214028)
0 引言
高职院校的人才培养方案中,课程设置是最关键的元素。课程设置规定了课程的类型、课程的性质、学时分配以及课程之间的顺序,课程结构的合理与否会直接影响到人才培养的质量。但是在人才培养方案的制定过程中,课程的设置是否合理,课程的先行后续的关系、课程之间内容衔接是否正确,还有待验证。通过数据挖掘的方式对学生成绩的样本数据进行深层次的挖掘,分析课程之间隐藏的内在联系,将课程相关性研究成果作为课程设置的基本依据,有利于在课程设置过程中优化课程结构,帮助学生构建良好的知识和能力的体系,提高教学质量,同时对学院教学和管理水平的提高也有一定的帮助。
1 关联规则挖掘
数据挖掘(Data Mining),就是对整理好的庞大的数据集或事务数据库进行分析,挖掘出其中隐含的、未知的、用户可能感兴趣的和对决策有潜在价值的知识和规则,供用户在决策时有一定的依据可循[1]。
关联分析是数据挖掘的重要分析方法之一,关联分析的目的就是发现隐藏在事务数据库中项目集之间有意义的联系,从而确定不同数据之间的关联规则。
1.1 关联规则的定义
关联规则是形如X→Y的蕴涵表达式,其中X和Y是事务数据库D中不相交的项集,X称作规则的前提或前项,Y为结果或后项。关联规则的强度可以用它的支持度(Support)和置信度(Confidence)度量。[2]
支持度(Support)是一种重要的度量,是指在事务数据库D中项目集X在总事务中出现的频率,记为Support(X)。项目集X和Y同时出现的频率即支持度为:Support(X→Y)=Support(X∪Y)=XY出现的次数/事务总数。支持度应用于发现频率出现较大的项目集,低支持度的规则是没有意义的,一般会被删除。
置信度(Confidence)是指在事务数据库D中项为:Confidence(X→Y)=Support(X∪Y)/Support(X)=XY出现的次数/X出现的次数。置信度应用于在频繁项目集中发现频率较大的关联规则[3]。置信度越高,表示Y在包含X的事务中出现的可能性就越大。
1.2 Apriori算法
Apriori算法是关联规则挖掘算法中最为经典的算法,它使用了基于支持度的剪枝技术,找出数据库中的最大频繁项集,分析得到符合要求的关联规则。
1.2.1 Apriori算法的主要思想
首先产生频繁项集,利用先验原理“在给定的事务数据库中,如果一个项集是频繁的,则它的所有子集一定也是频繁的”[4],对事务数据库进行循环扫描,按层次顺序搜索,完成频繁项集的挖掘工作,利用k_项集产生(k+1)_项集,通过连接和剪枝找到全部的频繁项集,然后根据频繁项集来产生关联规则。
1.2.2 Apriori算法的操作
Apriori算法的主要操作步骤是连接和剪枝。
(1)连接:将符合条件的k_频繁项集中的项目集,按照连接的规则作连接运算,寻找出符合条件的k+1_频繁项集。
(2)剪枝:通过对事务数据库进行扫描计算判断出候选项集是否为频繁项集,为减少扫描计算量,需将非频繁的子集或包含非频繁子集的候选项目集从候选集中清除,以提高算法的效率。
1.2.3 Apriori算法过程
(1)确定最小支持度minsup及最小置信度mincon。
(2)数据库中初始的每个项集均是候选1_项集,再根据支持度计算公式计算出候选1_项集的支持度,如果候选项目集的支持度大于给定的最小支持度,则为频繁项集。将候选1_项集的每一候选项与最小支持度比较判断,得到频繁1_项集。
(3)再根据连接的规则将频繁1_项集的集合两两连接,迭代产生候选2_项集。计算出其每一项集的支持度,与最小支持度进行比较,同时使用先验原理,可以更快捷地获得频繁2_项集。以此类推,不断产生新的候选项集和频繁项集,直到获得最大频繁项集为止。[5]
2 Apriori算法在课程相关性分析中的应用
使用Apriori算法发掘学生成绩事务数据库中各门课程成绩之间的关联规则,需首先确立进行数据挖掘的事务数据库,并对数据进行有效性清理和转换,再进行数据挖掘。
2.1 事务数据库
在关联规则Apriori算法中,事务数据库多采用横向结构。Apriori算法在生成候选项集和频繁项集过程中,因要不断计算支持度和置信度,需要反复对数据库进行扫描,学生数越多,课程门数越多,所耗费的时间越多。在本例中,共选取了软件技术专业150位学生,选取了每个学生事务的高等数学、C语言程序设计、数据库原理与应用、数据结构4门课程成绩共600条成绩记录做为研究对象,通过学生成绩优秀的获得情况来挖掘某门课程学习与其他课程的关联关系,以及对其他课程的影响程度。如表1所示横向结构的数据库中,每个学生是一个事务,4门课程分别用I1,I2,I3,I4表示。并设定最小支持度为10%,最小置信度为50%。
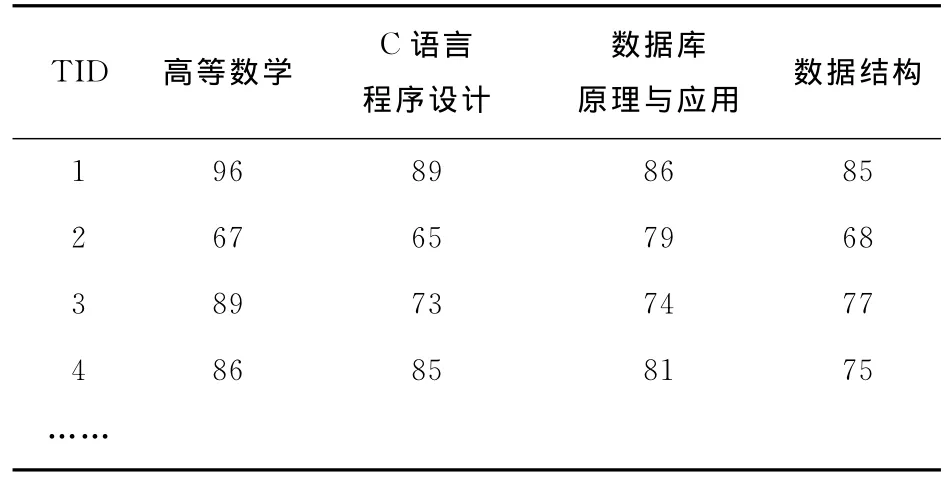
表1 学生成绩事务数据库
2.2 数据的清理与转换
确定好的数据库,需要通过数据清理来消除干扰性数据,同时还要针对事务数据进行数据的选择与转换,使数据库适合数据挖掘。
在学生成绩事务数据库中,会因为学生的缺考、休学等情况产生成绩记录的缺失。数据清理主要是检查事务数据库中不完整的、含噪声的、不一致的数据,对数据进行清理,同时删除无效数据,最终得到149个学生成绩事务。并将事务数据库进行整理,按照80分进行等级划分,80分以上为优,记为“1”,其他记为“0”,最终使事务数据库成为适合数据挖掘处理的格式,提高数据挖掘数据的精度和有效性。
2.3 数据挖掘
应用Apriori算法进行数据挖掘的过程,就是不断地连接和剪枝的过程,最后形成满足要求的最大频繁项集,具体操作步骤如下:
(1)初次扫描学生成绩事务数据库,初始的每个项集均是候选1_项集C1中的项集,本例中选择了4门课程做为数据挖掘的对象,挖掘其中成绩优秀的获取情况,因此,共有4个候选项集,C1包括{I1},{I2},{I3},{I4}。并根据支持度的计算公式计算出每个候选1_项集的支持度,如表2所示。根据Apriori算法的规则,满足给定的最小支持度的候选项集均为频繁项集,C1中所有项目集均满足最小支持度10%,因此,所有项集均是频繁1_项集,即F1包含{{I1},{I2},{I3},{I4}},如表3所示。

表2 候选1_项集支持度

表3 频繁1_项集支持度
(2)将F1中的项集两两连接,形成候选2_项集C2,C2包括{I1,I2},{I1,I3},{I1,I4},{I2,I3},{I2,I4},{I3,I4}。再次扫描事务数据库,计算出候选2_项集的支持度,如表4所示。与给定的最小支持度比较,得到频繁2_项集F2。由于C2中{I3,I4}项集的支持度小于给定的最小支持度10%,不是频繁项集,除此之外的其他项集均满足条件,如表5所示。

表4 候选2_项集支持度

表5 频繁2_项集支持度
(3)再采用Fk-1×Fk-1的方法,将F2中的每一个项集连接生成候选3_项集C3,连接时,算法要求k-2项相同的频繁项集才可连接。因此,候选3_项集C3包括{I1,I2,I3}、{I1,I2,I4}、{I1,I3,I4}、{I2,I3,I4}4个候选集。因为算法需确定该项集的真子集是否是频繁的,如果其中有一个是非频繁的,则该项集是非频繁的,会被剪枝。这样可以减少候选项集的数量,减少支持度的计算的复杂度。由于{I3,I4}项集是非频繁项集,因此{I1,I3,I4}和{I2,I3,I4}均是非频繁项集,经过剪枝后的候选项集如表6所示。第三次扫描数据库,计算出支持度,再根据给定的最小支持度得出结论,{I1,I2,I3}小于给定的支持度10%,不是频繁项集。因此,得到一个频繁3_项集也就是最大频繁项集F3{I1,I2,I4},如表7所示。
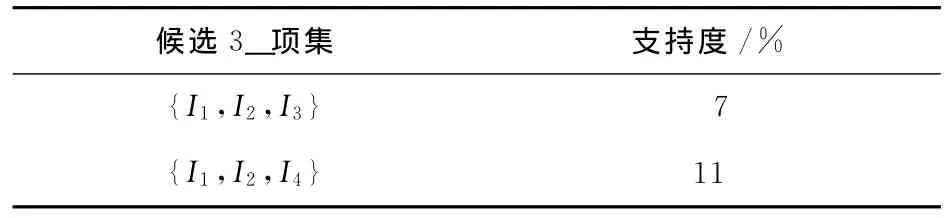
表6 候选3_项集支持度

表7 频繁3_项集支持度
(4)根据得到的频繁项集,形成关联规则。根据得到的频繁项集,可生成关联规则,如频繁2_项集中的{I1,I2},可生成I1→I2和I2→I1两种关联规则。最大频繁项集中的{I1,I2,I4}可生成6种关联规则,如表9所示。Apriori算法在生成频繁项集时,记录了每个频繁项集的支持度,置信度由频繁项集产生,因此可根据置信度的计算公式,利用频繁项集的支持度计算出每种关联规则的置信度,即项目集X出现使项目集Y也出现的条件概率。根据计算公式得到频繁2_项集关联规则置信度如表8所示,最大频繁集关联规则的置信度如表9所示。其中满足最小置信度50%的关联规则为符合条件的关联规则。
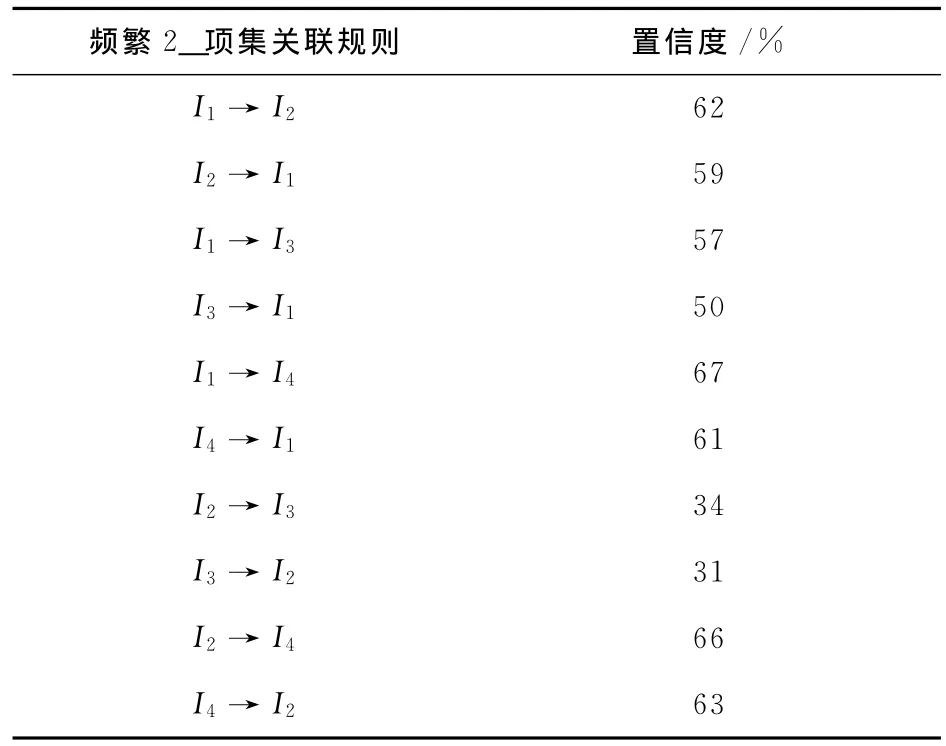
表8 频繁2_项集关联规则

表9 最大频繁集关联规则
2.4 结果分析
Apriori算法通过数据挖掘,得出如下分析情况:
(1)满足最小置信度50%关联规则符合条件,置信度高的可能性更大一些。根据频繁2_项集关联规则分析,I1→I2关联规则的置信度为62%,即高等数学成绩为优→C语言程序设计成绩为优的置信度为62%;I2→I1关联规则的置信度为59%,C语言程序设计为优→高等数学为优的置信度为59%。算法规定置信度高的关联规则的可信度更大,因此,可以断定,高等数学对C语言程序设计课程的学习影响大,课程设置要在前。同理分析,高等数学的学习对在数据库原理与应用、数据结构有一定的影响,课程设置在前。C语言程序设计的学习对数据结构有一定的影响,课程设置要在数据结构之前。C语言程序设计与数据库原理与应用的关联规则置信度低,因此两门课程的学习相互影响较低,两门课程的顺序可自行安排。
(2)根据最大频繁集关联规则分析,I1,I2→I4关联规则的置信度最高,为62%,因此可信度最大,高等数学成绩为优同时C语言成绩为优的同学,数据结构为优的置信度为62%。因此这两门课程对数据结构的学习有很大的帮助。
3 结语
利用关联规则挖掘的Apriori算法对专业的部分课程成绩规律进行挖掘,通过最小支持度和最小置信度,可以分析课程的相关性,挖掘出各门课程之间的隐藏关联关系,如课程的先行后续关系、衔接关系等。扩大课程研究范围并有效地利用课程相关性的分析结果,可有利于在制定人才培养方案中时优化专业课程设置,规范课程先行后续的开设流程,同时有利于引导学生正确地选修课程,帮助学生根据合理的课程设置构建出良好的知识和能力的体系,提高学校的教学质量。
[1]邵峰晶,于忠清,王金龙,等.数据挖掘原理与算法[M].北京:科学出版社,2009.
[2]廖芹,郝志峰,陈志宏.数据挖掘与数学建模[M].北京:国防工业出版社,2010.
[3]宋中山.挖掘大型数据库中的Apriori算法及其改进[J].中南民族大学学报:自然科学版,2003,22(1):54-57.
[4]Tan Pang-Ning,Steinbach Michael,Kumar Vipin,等.数据挖掘导论[M].北京:人民邮电出版社,2011.
[5]陈启买,彭利宁,刘海,等.基于关联挖掘的课程相关性模式研究[J].华南师范大学学报:自然科学版,2008(1):52-59.
