潮汕方言数字化框架设计与研发
2013-11-21吴永娜黄春梅
吴永娜,黄春梅
(揭阳职业技术学院信息工程系,广东揭阳 522000)
潮汕文化历史悠久,潮汕方言使用者众多.潮汕方言保留了不少两汉六朝时期的语音特点,是中国最古老、最特殊的方言之一.随着计算机技术的高速发展,在潮汕方言的研究中引入中文信息处理技术,是一种新的尝试,它涉及到计算机和方言两个领域的知识融合.计算机技术在文献检索、录入、保存、各种资料的统计对比方面有很大的优势,给我们带来诸多的便利.本文建立了潮汕方言字词数据库检索系统、潮汕方言口音数据库、潮汕方言自动处理软件,让专家学者从繁重的整理工作中解放出来,将更多的精力放在分析和解决问题上.
1 潮汕方言音系
潮汕方言口音可以分为揭阳、汕头、潮州、汕尾、普宁、海陆丰等,每种口音大体相同,相互间能听懂,但各地的发音还是有所区别.系统以广东省教育厅1960年9月公布的潮汕话拼音方案为标准(简称60方案,下同).
1.1 潮汕方言的声母
根据潮汕话拼音方案,潮汕话声母共有18个,见表1.

表1 潮汕方言声母表
1.2 潮汕方言的韵母
潮汕话常见有61个韵母,但为了全面保留潮汕语音系统的完整性,把不常见和管字甚少的韵母都一并收录,共计95个,见表2.

表2 潮汕方言韵母表
表2没有按照传统音韵学的方式编排,主要是针对计算机的特点而设计的.
1.3 潮汕方言的声调
潮汕话有8个声调如表3所示.
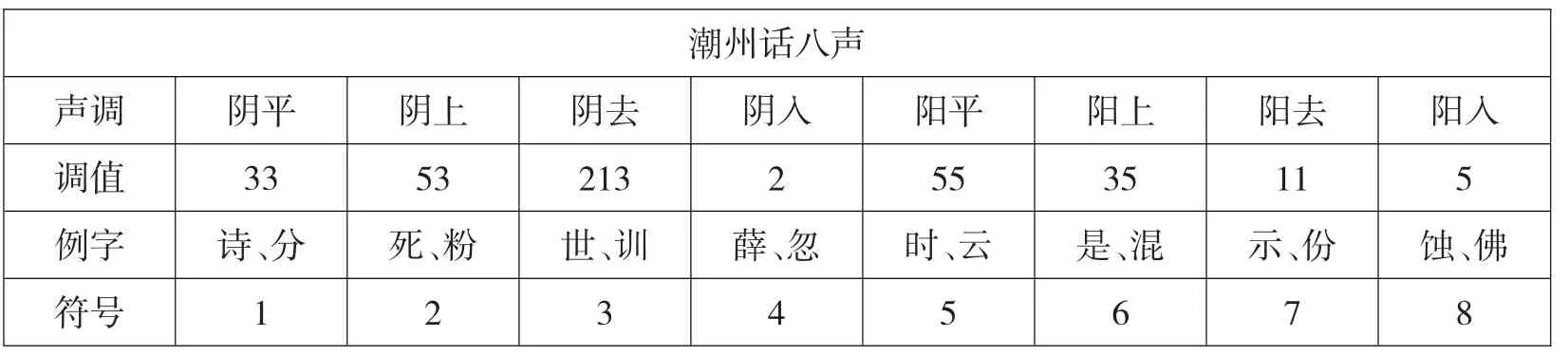
表3 潮汕方言声调
2 方言字库的建造和安装
目前大约有80个潮汕方言字超出常规计算机的输入范围.由于缺少字库支持无法输入和显示.这部份字在Windows平台主要是利用eudcedit.exe自带的造字程序来实现的.步骤如下:
2.1 确定方言字字符代码
Windows系统为用户自定义字符预留了一定的编码空间,并提供了一个制作自定义字符的程序eudcedit.exe,并确定编码类型和代码页[11].EUDC中有各种不同的代码页,932代表日本语,936代表简体中文,949代表韩语,950代表繁体中文,代码页不同,其规定的内码不同,在设计和规划时必须严格按照其范围编排.如下所示:
932=F040-F9FC
936=A140-A7A0,AAA1-AFFE,F8A1-FEFE
949=C9A1-C9FE,FEA1-FEFE
950=8140-8DFE,8E40-A0FE,C6A1-C8FE,FA40-FEFE
Unicode=E000-F8FF
本设计没有采用936(简体中文)代码页空间,而是采用了Unicode的规范,方便在各种系统上使用.潮汕方言字符的编码空间从E001H开始,到E050H(十六进制)结束,共80个.运行Windows自带的造字程序,选择Unicode代码,然后选择从E001H代码开始造字,全部造完后保存为文件.
2.2 修改注册表的值
系统要识别使用自造字,必须修改注册表,这部分位于KEY_LOCAL_MACHINESystemCurrent-ControlSetControlNLSCodePageEUDCCodeRange EUDCCodeRange CodePage=FromTo[,FromTo],操作系统不同,其位置也不同,Windows 2000、Windows Server 2003、Windows XP SP1、SP2位置相同,Windows XP SP3位置与之不同,Windows7、Windows8又有差别,这些过程比较复杂,输入法专门附带了一个eudc-install程序,把设计完成后的自定义字符安装到目标计算机上,并自动完成对注册表的操作和文件的操作.
3 输入法的设计
输入法软件的设计是数字化过程中一个关键环节.不论写作或是整理文献都要和大量的方言字打交道.我们花费了大量的时间和精力完成了潮汕话输入法的开发,软件可以直接按照潮汕话拼音输入常见的单字和词组,对文献录入、创作或是聊天达到实用的水平.输入法的设计过程中,碰到的主要问题有:
3.1 潮拼声母韵母的规范化
潮汕地区有很多本土的字典和专业文献,它们大都附带有一个声、韵母表,从表4可以看出,四个附带表没有一个完全相同,表的内容虽然没有错,但容易使人无所适从,非潮语区的用户看后更是一头雾水.随着时间的推移,广东省教育厅1960年发布的潮汕话拼音方案已经跟不上时代的变化,制定一个标准声、韵母表对推广潮汕方言十分关键.普通话能够推广,一个重要因素就是有一个相对固定的标准声韵母表.本系统采用60方案,其优点是接近汉语拼音方案,容易上手.系统所有收集到的资料,全部以60方案进行编码.

表4 各字典附带的声母表对照
3.2 字符集编码问题
汉字信息化处理一直是个非常复杂的问题,国内外先后出现了多种方案,导致了汉字字符编码的混乱和兼容性问题[10].潮汕方言输入与常规的输入有很大的不同,很多方言字在常规输入法中根本无法输入和显示.从发展方向和兼容性考虑,本系统采用了Unicode的编码方案.系统采用海峰五笔的字库,该字库严格按照Unicode的编码规范进行设计,具体内容见表5.其中CJK EUDC自造区的编码空间正好用在潮汕方言俗字的编码上.
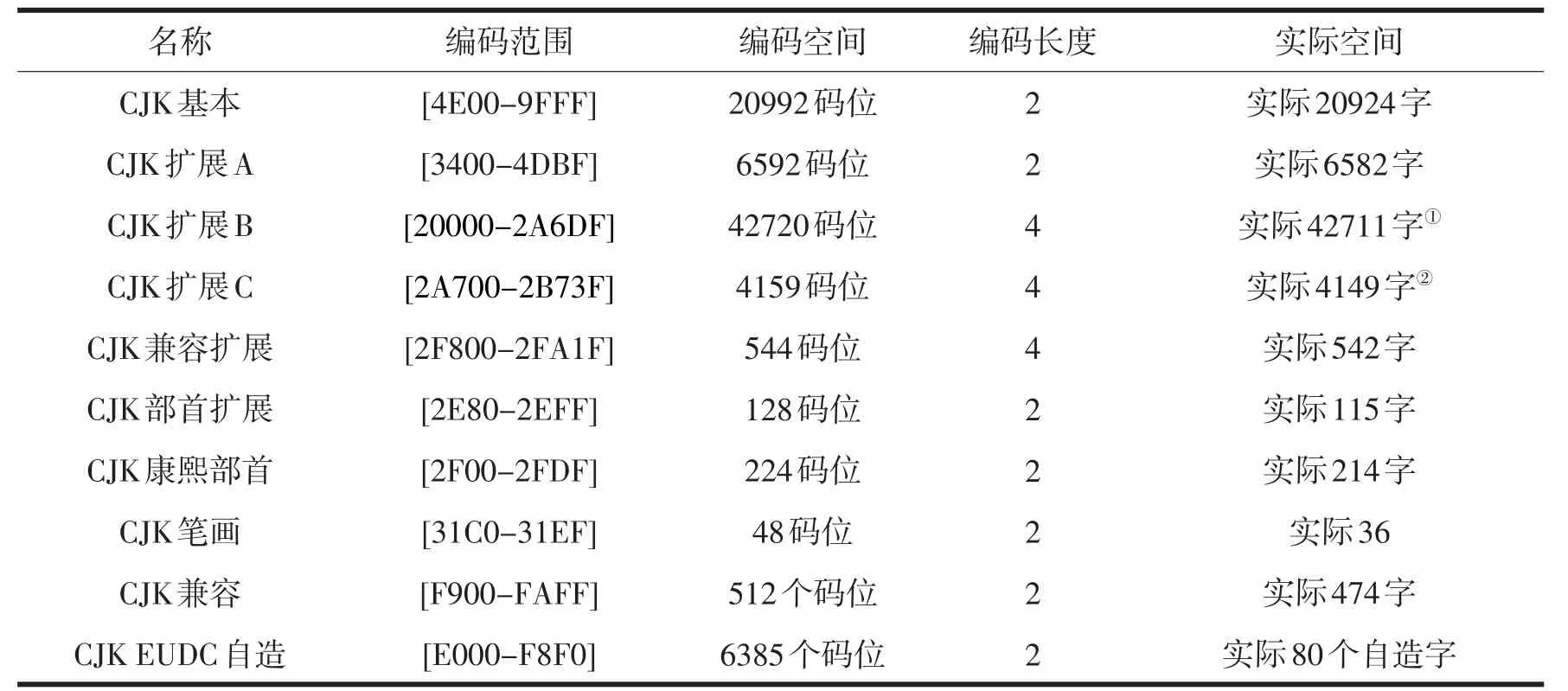
表5 Unicode字库编码范围
3.3 主要的数据结构
输入法由5个数据表组成:五笔单字库、五笔词组、潮音字库、潮音词组和自定义库.潮音字库按照<单字><方音1,方音1,…,方音n>的结构组织,用户输入时由软件自动在各个方音中查找,就不用考虑到地区的差别,词组文件按照<词组><方音组1,方音组2,…,方音组n>的结构组织,输入时也同样不用考虑地区的差别,只是要求软件必须尽可能地收录各地的发音.对于没有收录到的方音和词组,则由自定义库来解决,该库由二部份组成,第一部份是单字,第二部份是词组,结构也同上,由软件完成插入排序.
3.4 人性化的设计
由于潮语很多是古汉字,笔划很多,常规字体有时较难看清,所以潮汕话输入法开创性地设计了输入窗口可自由调整字体大小的技术,以方便用户.在输入状态下,只要按下键盘上的“↑”、“↓”键,输入法窗口就可以实现放大缩小.
3.5 五笔单字反查潮拼功能
输入法中专门设计了五笔单字反查潮拼拼音的功能,在输入过程中,碰到无法用潮拼输入时,可用五笔打出该字,同时该字右边显示潮语拼音,对用户学习潮汕拼音法起到辅助作用.
4 词汇的收集与潮汕方言字词检索系统
词汇的收集和录入非常繁重和耗时.潮汕方言目前还没有官方正式的词汇收集文献.潮汕地区的各种词汇专著比较少,出版时间参差不齐,词汇量不多,最常见的是林伦伦编著的《潮汕方言熟语辞典》,该书收集的词汇量有2 400条左右,是目前比较权威严谨的著作.部份词汇中的方言字要么留空,要么用同音字代替,除了部分至今无法考证出本字的方言字外,现在考证出来的方言字没有及时收录,而用同音字代替的现象比比皆是,在网络上用词混乱不堪.较少收录俚语,事实上有些俚语词汇更具潮汕特色.资料重叠严重,而且只有纸质内容,造成录入困难.所以专门开发了辅助的方言字词收集检索系统,见图1.

图1 潮汕方言字词收集检索系统
5 注音程序的设计
方言注音程序的设计比拼音注音要复杂得多,现在还不能达到百分之百的注音.拼音的注音已经有大量的研究和可用的资料.而潮汕方言在这方面还是个空白,潮汕方言既有文读,又有白读,各个方言区的发音又不尽相同,所以注音复杂且速度大大受到制约,例如,“广”字,表示地名时用“geng”,表示“广大”时用“guang”,而“广交会”本要用“geng”,但实际要用“guang或guêng”;又如“人”字,在“男人,工人,商人,人参,人中”发“ring”的音,但在揭阳却发“rêng”的音,在“助人为乐,人面,负责人”中发音为“nang”;又如“齐”字文读为“ci”,白读为“zoi”.这些现象比较复杂,只有经过长时间收集统计分析才能提高注音的准确性.图2是潮汕方言自动处理软件界面,该软件初步实现了潮汕方言的分词与自动注音.

图2 潮汕方言自动处理软件
6 书籍OCR数字化与语音合成
文献录入是非常繁重的工作.把文献扫描后识别其中的文字称为OCR.目前OCR软件大部份仅支持国家规定的常见汉字,对潮汕特有的汉字无能为力.针对收集到的潮汕单字进行了宋体字型数据分析,提取了关键点数据.主要进行印刷体的OCR试验,重点是试验方言俗字的识别.
语音合成具有广泛的使用范围.目前以揭阳方言区的读音为试点,编制出所有揭阳话的发音表,按发音表录制相应的单字发音,再根据揭阳音的变调规则实现了一套简单的语音合成软件.
方言数字化的内容还有很多,像智能输入、自动分词、机器发音、各地语音库的建立等等,相信这些工作会方便以后的研究.
[1]林伦伦.(普通话对照)新编潮州音字典[M].汕头:汕头大学出版社,1997.
[2]张晓山.(普通话潮州话对照)新潮汕字典[M].广州:广东人民出版社,2009.
[3]殷人昆,陶永雷.数据结构[M].北京:清华大学出版社,1999.
[4]黄维通.Visual C++面向对象与可视化程序设计[M].北京:清华大学出版社,2000.
[5]杨扬发.(普通话对照)潮州十八音字典[M].汕头:汕头大学出版社,2001.
[6]刘尧咨.说潮州话[M].广州:华南理工大学出版社,1995.
[7]林伦伦.潮汕方言熟语辞典[M].深圳:海天出版社,1993.
[8]陈凌千.潮汕字典[M].汕头:汕头育新书社,1935.
[9]吴华重.(普通话对照)潮州音字典[M].广州:广东人民出版社,1983.
[10]徐英慧.基于Qtopia的嵌入式智能拼音输入法设计[J].微计算机信息,2008,24(30):276-278.
[11]叶娜娜,邓飞其,余红明.基于Qt/Embedded技术的中文输入法设计[J].自动化技术与应用,2009,28(8):26-32.
