中文分词算法概述
2013-11-01甘秋云
甘秋云
(1.福州海峡职业技术学院,福建 福州 350014;2.福建工程学院 国脉信息院,福建 福州 350014)
对于以汉语为母语的我国来说,中文信息处理技术已经在我国信息化建设中占据了一个非常重要的地位。据统计,在信息领域中80%以上的信息是以语言文字为载体的,这些信息的自动输入和输出、文本的校勘和分类、信息的提取和检索以及语言翻译等语言工程,都是我国信息化建设的重要基础。在众多中文信息处理技术中,中文分词技术是关键技术,同时也是中文信息处理的基础。
1 中文分词概述
1.1 中文分词简介
中文分词既是中文信息处理的关键,也是中文信息处理的基础。对于中文分词可以通俗地指由机器在中文文本的词与词之间自动加上空格,以实现分词的目的。
中文信息处理主要包括了字、词、短语、句子、篇章等多层面的信息加工处理任务。当前汉语信息处理的主要任务已从“字处理”转移到“词处理”。由于中文文本是按词连写的,词间无间隙,因而在中文文本处理中,首先遇到的问题是词的切分问题,也就是中文自动分词,例如将“学习信息科学”切分成“学习/信息/科学”。
在20世纪80年代初期,自动分词技术的研究就受到重视并不断发展,因此许多分词模型和软件也不断问世。近年来,随着国民经济信息化的不断发展以及 Internet的普及应用,在中文信息处理的广泛应用中,实现汉语词典和语料库等中文资源的共享和复用显得尤为重要,因此对自动分词的要求也越来越高,自动分词已经成为中文信息处理的一个前沿课题[1]。
1.2 中文分词中存在的困难
1.2.1 分词规范问题[2]
汉语词的概念。对于分词结果是否正确需要有一个通用、权威的分词标准来衡量。分词标准的问题实际上是汉语词与语素、词与词组的界定问题,这是汉语语法的一个基本、长期的问题。主要包括核心词表问题、词的变形结构问题、词缀的问题等。
不同应用对词的切分规范要求不同。汉语自动分词规范必须支持各种不同目标的应用,但不同目标的应用对词的要求是不同的,甚至会有矛盾。如,以词为单位的键盘输入系统,为了提高输入速度,一些互现频率高的相互邻接的几个字也常作为输入单位,如“这是”、“就是”等。
1.2.2 分词算法的困难
1.2.2.1 分词与理解的先后
由于计算机理解文本的前提是识别出词、获得词的各项信息,即它只能在对输入文本尚无理解的条件下进行分词。因此它无法像人那样在阅读汉语文章时边理解边分词,而只能是先分词后理解,这就会造成逻辑上的两难:分词要以理解为前提,而理解又是以分词为前提。所以任何分词系统都不可能企求百分之百的切分正确率。
1.2.2.2 切分歧义的消除[3]
当语言存在歧义时,我们一般是通过上下文理解来选择正确的词语。但是机器很难正确判断该如何切分。例如“中国人民”,到底是切分成“中国人/民”还是切分成“中国/人民”,就需要想办法正确选择。
对于歧义而言,我们按照它的结构可以分为两种类型:交叉歧义(交集型歧义)和覆盖歧义(组合型歧义)。
交叉歧义指的是,字串“ABC”,如果“AB”、“BC”分别属于两个不同的词,既可以切分成“A/BC”,也可以切分成“AB/C”,则称“ABC”存在交叉歧义。例如字串“组合成”,“组合”和“合成”都是一个词,他们就存在交叉歧义。
覆盖歧义,也称为组合歧义,对于字串“AB”,如果“AB”是一个词,“AB”其中的子串“A”和“B”也是一个词,则称“AB”存在覆盖歧义。例如字串“才能”,“才能”是一个词,“才”和“能”也可以单独成词。例如“他/来/了/,/问题/才/能/解决”,“他/的/才能/是/有目共睹/的”,这时候就存在覆盖歧义。
歧义的消除一般需要提供更多的语法和语义信息,而且有时候要结合上下文语境理解。切分过程中,当出现人工也无法判断时,就必须要结合更多的上下文才能理解。此时要求计算机自动识别,就更加困难了。
1.2.2.3 未登录词识别[4]
未登录词指的是词典中没有收录的词语。主要指各种命名实体和新词。另外,一些缩略语和术语也属于未登录词的范围。
对于有些命名实体,比如数词、时间等具有较强的规律性,相对容易识别。有些比如人名、地名,也有自己的常用词,采用一些规则和统计信息,也能识别大部分。但是对于新词来说,则很难找出什么规律。随着社会的发展,各种新词层出不穷,很多新词的形成在语法语义上是完全没有规律的,例如“非典”、“酱紫”等。而且很多未登录词和常用词混在一起,容易形成歧义。
1.2.2.4 先识别已知词还是先识别未登录词
在目前的分词算法中,通常是将已知词识别和未登录词识别分作两个部分。这样就产生了一个问题:先识别哪个部分更有利。
如果先识别未登录词,同样也可能导致已知词识别错误,例如“胜利/取决/于勇/气”。反之,如果先识别已知词,会导致未登录词识别错误,例如“内塔尼亚/胡说”。
目前来说,对于哪一步识别在先更好一些,研究者们并没有一个确定的结论。
2 中文分词切分算法
从1983年第一个实用分词系统CDWS的诞生到现在,关于汉语分词的算法大致可以分为四大类。
2.1 基于词典和规则的方法[5]
这类算法在切分时用待切分的字符串去匹配词典中的词条,如果匹配成功,则切分成一个词。目前最常用的是基于词典的字符串匹配方法,主要包括最大匹配、全切分、最短路径等。
2.1.1 最大匹配法
该方法又可分为正向最大匹配、反向最大匹配和双向最大匹配三种,主要是根据取词的方向来决定的。正向最大匹配从左到右每次取最长词,反向最大匹配则每次是从右到左取最长词,得到切分结果。双向匹配则是进行正向、反向匹配,然后对于两种匹配结果不同的地方再利用一定的规则进行消歧。这种方法实现简单,而且切分速度较快。但是,当出现覆盖歧义的时候,最大匹配法是无法发现的,对于某些复杂的交叉歧义也会遗漏。
2.1.2 全切分法
全切分算法是利用词典匹配,获得一个句子所有可能的切分结果。当句子长度增加时,全切分的结果数也随之增加,且呈指数增长,对于比较长且包含较多歧义的句子,往往要经过很长的时间才能遍历完所有的切分路径。因此该方法的时间开销非常大,无论是在统计语言模型训练还是在全文检索、机器翻译等实际应用中都是难以接受的。
2.1.3 最短路径法
最短路径方法是一种动态规划算法,它的基本思想是在词图上选择一条词数最少的路径,节省了时间开销,且它相对优于单向最大匹配方法,但是这种方法忽略了所有覆盖歧义,也无法解决大部分交叉歧义问题。
2.2 基于大规模语料库的统计方法
这一类方法是目前分词算法中比较常用的方法,主要是从大规模语料库中统计得到各种概率信息来指导字符串的切分。基于统计的方法可以借用许多比较成熟的概率模型来实现切分,不需要人工维护规则和复杂的语言学知识,扩展性较好。除了最常见的词频统计信息以外,目前常用的几种其它概率模型主要包括有:
2.2.1 N元语法模型和隐马尔可夫模型
在N元语法模型中,一个句子可以看成一个连续的字符串序列,即可以是单字序列,也可以是词序列。N元语法假设一个单词出现的概率分布只与单词前面的 1-N 个单词有关,与更早出现的单词无关。若一个句子的出现概率用 P (W)表示[6]。则
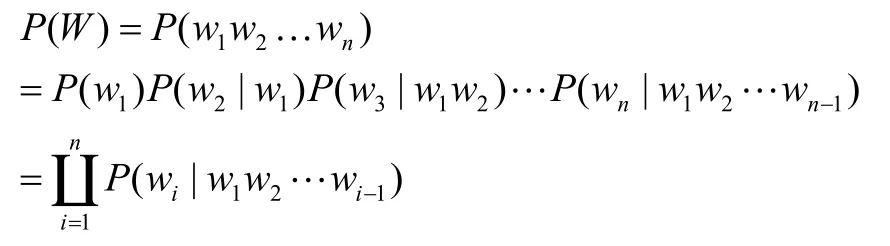
可以看出,N元语法模型认为产生语句W的概率是产生其第一个字的概率,乘以在给定第一个字的条件下产生第二个字的概率,乘以在给定前两个字的条件下产生第三个字的概率,……乘以在给定前 1-n 个字的条件下产生第n个字的概率。产生第i个字的概率是由已产生的 1-i 个字决定的。
利用大规模的语料库和成熟的N元语法模型,使用三元语法,在不考虑未定义词的情况下,就可以将切分的正确率提高到98%以上[7]。
隐马尔可夫模型是N元语法模型的一种,已广泛地应用于自然语言处理领域中,比如语音识别、词性标注等等。在隐马尔可夫模型中,任一随机事件都有一个状态序列和一个观察值序列隐马尔可夫模型可以形式化为一个五元组),,,,(πBAOS,其中:

隐马尔可夫模型很少单独使用,通常是和词性标注结合在一起用,它的作用类似于译码。在序列分析中,从序列中的每个观察值去推测它可能属于哪个状态。
2.2.2 互信息
互信息用来表示两个字之间结合的强度,其公式为:
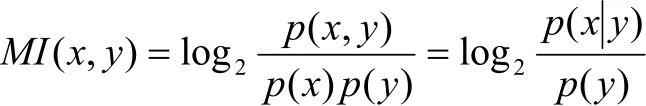
MI越大,表示两个字之间的结合越紧密。反之,断开的可能性越大。当x与y关系强时,0),(≥yxMI;当x与y关系弱时,0),(≈yxMI;而当0),(<yxMI时,x与y称为“互补分布”[8]。
2.3 规则和统计相结合的方法
目前大多数的分词算法都是采用规则和统计相结合的方法,主要是利用词典进行初切分,然后用其它的概率统计方法和简单规则进行消歧和未登录词识别。这样不仅可以降低统计对语料库的依赖性,充分利用已有的词法信息,还能弥补规则方法的不足之处。
2.4 人工智能分词方法
人工智能法,又称理解分词法,主要是对信息进行智能化处理的一种模式。主要有两种处理方式:一种是基于生理学的模拟方法,例如神经网络,即在模拟人脑的神经系统机构的运作机制来实现一定的功能;另一种是基于心理学的符号处理方法,例如专家系统,即通过模拟人脑的功能,构造推理网络,经过符号转换,从而可以进行解释性处理。以上两种思路是近年来人工智能领域研究的热点问题,应用到分词方法上,产生了专家系统分词法和神经网络分词法。
3 结束语
每一种分词算法都有各自的优缺点。由于汉语语言知识的笼统和复杂性,对于将各种语言信息组织成机器可直接读取的形式具有一定的难度,目前基于人工智能的分词系统还在试验阶段中。
[1] 文孝庭.汉语自动分词研究进展[J].图书情报,2005(5):54-62.
[2] 张春霞,郝天永.汉语自动分词的研究现状与困难[J].系统仿真学报,2005(17):138-147.
[3] 孙斌.切分歧义字段的综合性分级处理方法.北京大学计算语言学研究所讨论班[EB/OL].http://ccl.pku.edu.cn/doubtfire/nlp/Lexical_Analysis/Word_Segmentation_Tag ging/Chinese_Word_Seg_Tag/seg_tag_BSWEN.htm,199 9-4-13.
[4] 冯玉春,宋涛瀚.Web中文文本分词技术研究[J].计算机应用,2004,24(4):134-136.
[5] 刘件,魏程.中文分词算法研究[J].微计算机应用,2008,29(8):12-16.
[6] 龙树全,赵正文,唐华.中文分词算法概述[A].电脑知识与技术,2009,5(10):2605-2607.
[7] 高山,张艳,徐波等.基于三元统计模型的汉语分词标注一体化研究[A].全国第六届计算机语言学联合学术会议(JSCL-2001)[C].太原:山西大学,2001.
[8] 张磊,张代远.中文分词算法解析[A].电脑知识与技术,2009,5(1):192-193.
