基于龙芯多核处理器的云计算节点机
2013-10-29阮利秦广军肖利民祝明发
阮利,秦广军,肖利民,祝明发
(1. 北京航空航天大学 软件开发环境国家重点实验室,北京 100191;2. 北京航空航天大学 计算机学院,北京 100191)
1 引言
高性能计算机是当前云计算数据中心[1]、大数据计算的核心装备。高性能计算机的研制水平、生产能力及应用程度是国家综合国力、信息化建设、数据和计算安全保障能力的重要体现,是世界各国特别是发达国家争夺的战略制高点[2]。美国国防部的“高效能计算系统”(HPCS, high productivity computing system)[3]研究计划首次提出了以“高效能”作为新一代高性能计算机研制的目标。自此,美国的 HPCS以及我国的“863”计划“高效能计算机系统研制与关键技术研究”重大专项等项目均已相继开展了针对HPCS的研究。
目前,科学计算、云计算和大数据计算等新应用对计算性能无止境的需求推动了高性能计算机系统峰值性能的迅速提高。然而,在高效能计算机峰值性能和系统规模不断扩大的同时,如何有效解决国外处理器带来的可靠性和安全性,由于应用多样性、系统规模显著增大、复杂的体系结构等带来的性能功耗比、性能体积比和可扩展性等高效能瓶颈问题,是高效能计算机研究领域近期和未来亟待解决的热点和难点问题之一。首先,高性能计算机对高密度紧耦合计算资源的需求变得极为迫切。例如,在2013年11月公布的Top 500排名中,排名第一的Tianhe-2的Linpack能达到33 862.7 Tflop/s,拥有3 120 000个处理核,1 024 000 GB内存[4]。此外,因为高性能计算机在系统功耗方面也面临严峻的挑战。例如,据英特尔统计,数据中心25%的成本是耗电。Top 500排名第二的Titan功耗为8 209 kW,而Tianhe-2更高达17 808 kW。另一个是高性能计算机体积问题。从数据中心的占地面积来看,Google在美国俄勒冈州哥伦比亚河畔建设的数据中心占地面积达到10×104平方公尺,总共拥有8 180个机柜[5,6]。
处理器作为高效能云计算节点的核心处理单元,是达成安全性、高性能、低功耗等高效能指标的关键。龙芯3A处理器[7,8]是中国科学院计算技术研究所自主研制的一款面向高性能计算的片上多处理器,采用65 nm生产工艺,在1 GHz主频下可实现16 Gflop的运算能力,功耗约10 W,性能功耗比为1.6。研究表明,相对于主流的 Intel和AMD处理器,新兴的以龙芯 3A和 3B为代表的龙芯 3系列处理器在性能功耗比等高效能指标和自主创新等上有较明显的综合优势。此外,从自主创新和安全可控的角度来看,使用国产处理器作为高效能云计算节点的核心部件可扭转高效能计算机长期以来依赖从国外进口处理器的被动局面,对提高我国高性能计算机的自主研发水平、维护国家安全等都具有重要意义。另一方面,计算节点是高性能计算机体系结构中除加速节点、主机单元、通信网络等外的核心部件之一,计算机节点的高效能已成为整机“高效能”目标能否达成的关键。目前在研和投入使用的一批大规模高性能计算机均十分注重计算节点高效能问题的突破,代表性的系统主要包括:Gary Titan[4],日本富士通 K 计算机[9]、Tianhe-1A、Jaguar[10]、Cray 的 Cascade 和 Baker,IBM 的 Roadrunner等[11~18]。可见,研究一种具有高性能功耗比、高密度和较强可扩展性的、基于国产龙芯多核处理器的高效能云计算节点具有非常重要而深远的研究意义和工业实践价值。
本文关注于云计算节点的高效能软硬件设计和实现问题,提出了一种基于龙芯3A多核处理器的云计算节点机的软硬件设计和实现方法。
2 逻辑结构
基于龙芯3A多核处理器的高效能云计算节点的基本设计思路为:作为高性能计算机体系结构中除加速节点、主机单元、通信网络等外的核心部件之一,高效能云计算节点主要承载大规模或超大规模的计算密集型应用任务,是超级计算能力的主要实现者,主要应对高效能目标中的高性能、低功耗、高密度、低成本和高安全等挑战。在拓扑结构上,计算节点总体由4个SMP构成。从处理器角度来看,节点在1U高度的Rack机箱中集成16颗龙芯3四核处理器,构成一个cc-NUMA结构的系统,系统实现高性能功耗比、高性能体积比和高集成度等目标。
处理器是高效能云计算节点的核心运算单元,处理器的选择和互连方法是本文计算节点设计中的关键。在处理器的选择上,本文选取的龙芯 3A处理器总体具有如下特征:每个龙芯3A片内集成4个64 bit的四发射超标量主频1 GHz的GS464高性能处理器核。处理器预留的互连端口决定了高效能云计算节点互连技术的设计。对于龙芯3A多核处理器来说,每个处理器有2个16 bit HT端口,而每个端口可以拆分成 2个 8 bit端口使用(HT0和HT1),因此共有4个可用的8 bit HT端口(HT00和H01分别表示HT0的低8 bit和高8 bit,HT10和HT11分别表示HT1的低8 bit和高8 bit)。基于龙芯3A的HT互连端口的配置,计算节点通过每4颗处理器互连即可自动构成一个 cc-NUMA结构的SMP。
为便于对本文计算节点设计和实现技术做进一步详细介绍,首先给出如下定义。
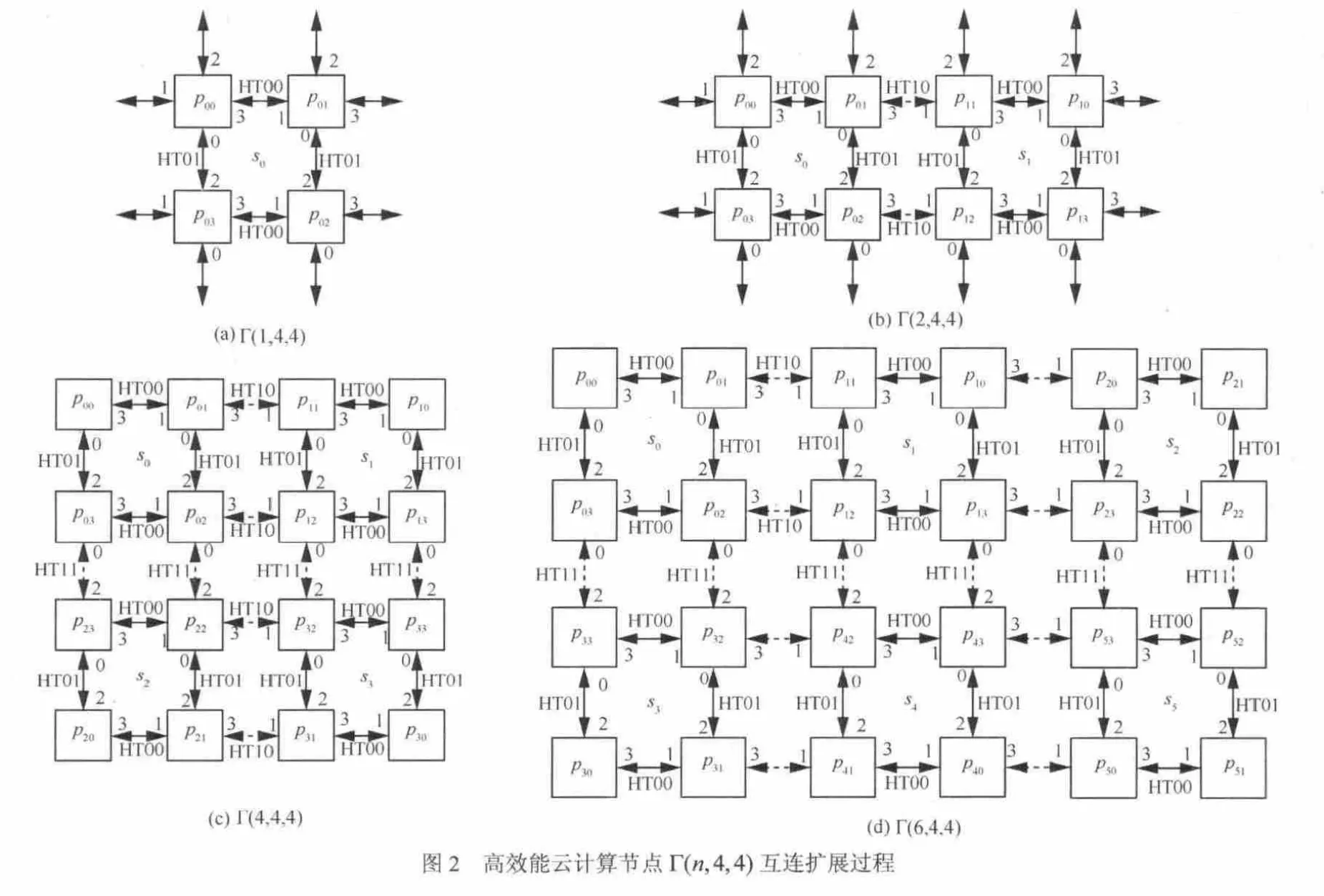
定义 1 基于龙芯3A多核处理器的高效能云计算节点Γ(n, r, m)可定义为一个二元组Γ(n, r, m)=< Sn,r, Cm>。其中, Sn,r是SMP集合,n表示计算节点中所含的SMP的个数,即 Sn,r集合中的元素个数;r表示每个基本SMP单元包含的处理器个数,即 Sn,r集合中每个元素包含的处理器个数。Cm是处理器间直连端口集合;m表示每个处理器可用的直连端口数目。
具体地,Γ(n, r, m)表示该计算节点是由n个包含r个处理器,且每个处理器的可用直连端口数为m的SMP组成的计算节点。例如, Γ(4,4,4)=<S4,4,C4>,就表示计算节点 Γ ( 4,4,4)在体系结构上由4个SMP组成,每个SMP包含4个处理器,每个处理器有4个互连端口。也即表示了一个16路4SMP的计算节点。对 Sn,r和 Cm更详细的定义如定义 2~定义 4所示。
定义2 计算节点的SMP集合定义为 Sn,r={si},n - 1 ≥ i≥ 0 。其中, si表示第i个SMP单元。
定义3 给定 Sn,r,第i个SMP单元定义为 si={ pi,j},r - 1 ≥ j ≥ 0 。其中, pi,j表示 si中的第j个处理器。r表示每个基本SMP单元 si包含r个处理器。
定义 4 给定 Sn,r的处理器间直连端口集定义为Cm= { ci,j,k},m - 1 ≥ k ≥ 0 ,其中,ci,j,k表示 Sn,r中的SMP单元 si的第j个处理器 pi,j的第k个直连端口。n和r如定义2和定义3所示,m表示每个处理器可用的直连端口数目,端口从正南方向开始顺时针编号。在定义4中,处理器互连的具体拓扑结构与 Cm的值密切相关,m值不同,互连规则不同,得到的拓扑结构也将不同。
基于定义 1~定义 4,本文研制的基于龙芯 3A多核处理器的云计算节点表示为 Γ ( 4,4,4),其逻辑结构布局如图1所示。具体地,该计算节点由4个SMP组成,每个SMP包含4个处理器,每个处理器有4个互连端口,也可看作一个由16个处理器组成的二维四元的mesh结构。图1中, pi,j表示龙芯 3A 处理器。“chipset”表示芯片组,用于连接USB、IDE、Ethernet等外部接口;“InfiniBand”表示InfiniBand互连设备,用于连接InfiniBand网络。其中,SMP内部通过HT0互连,SMP间通过HT1互连。 Γ ( 4,4,4)总体相当于一个基于 HT总线的4SMP板上机群。
3 互连规则
本文所研制的高效能云计算节点单节点上具有16个处理器,如何将这16个处理器进行互连并形成一个统一的计算平台,这是系统设计首要解决的关键技术问题。2.1节重点介绍了计算节点的核心组成部件和逻辑结构。本节将重点介绍本文所研制的Γ ( 4,4,4) (16路4 SMP)的互连方法,并讨论其性质。
HyperTransport(HT)是一种为主板上的集成电路互连而设计的端到端总线,可用于处理器的互连和处理器的I/O。龙芯3A处理器集成了HT接口,在总线宽度为32 bit时HT总线带宽为6.4 Gbit/s。因此,HT 可作为主板级CPU 之间及CPU与芯片组的互连总线。
由龙芯 3A组成的 2D mesh结构的计算节点Γ ( n,4,4),其处理器间互连总体包括 SMP组内与SMP组间2种。下面将详细介绍互连规则。
定义5 对计算节点Γ(n,4,4),其中,n=xy,x≥1,y ≥1,如x表示横向(或x轴方向)的SMP个数,y表示纵向(或 y轴方向)的 SMP个数。其2D mesh构图规则如下所示。
规则1 SMP内部处理器互连。在 si内, pi,j与pi,k若满足( j + 1 )mod4= k ,则 pi,j与 pi,k直接互连,且互连端口分别为 ci,j,h和1
规则2 SMP间处理器互连。在 sk与 sj间,pk,i与 pj,i,满足 j + 1 = k (在x轴方向),或 j+ x = k (在y轴方向),则 pj,i与 pk,i直接互连,且互连端口分别为cj,i,h1和

规则1定义了SMP内部的处理器间互连方式。规则2定义了SMP间的互连方式, sk的编码是从左到右,从上到下,按规则2递增, sk和 sj的互连端口号差2个。
按照规则1和规则2,图2(c)表示了本文高效能节点的互连方式。图2(a)和图2(b)示例了由龙芯3A组成的 2D mesh结构的高效能云计算节点Γ ( n,4,4)的互连扩展过程。
性质1 按定义5,Γ(n,4,4)是以Γ (1 ,4,4)为基元的mesh结构。
证明 定义5的规则2横向节点编号按1递增,纵向节点编号按x递增,构成典型的2D mesh结构。Γ(n,4,4)的每个节点都是4路SMP,因此,Γ(n,4,4)是以 Γ (1 ,4,4)为基元的mesh结构。
证毕。
性质2 定义5中,Γ(n,4,4)的处理器个数为4n。
证明 按照定义1,Γ(n, r, m)中的n为SMP个数,按照定义5,Γ(n,4,4)中每个SMP都是4路,所以Γ(n,4,4)的总处理器个数为4n。证毕。
性质3 定义5中,Γ(n,4,4)的处理器规模按4的倍数递增。
证明 按定义5和性质1,Γ(n,4,4)无论在横向还是纵向,或者双向扩展,都将至少增加一个Γ (1 ,4,4),而 Γ (1 ,4,4)是一个4路的SMP,因此,Γ( n,4,4)的规模按4的倍数递增。
证毕。
定理1 Γ(n,4,4)中任意处理器间最长通信距离为 x + y- 2 。
证明 按性质1,Γ(n,4,4)是mesh结构,mesh结构的任意两点间最长距离等于 x + y- 2 。又因为Γ ( n,4,4)的每个节点都是 4路 SMP,SMP内的 4路处理器通过内存共享进行通信,通信距离通常定义为0。因此,Γ(n,4,4)中任意处理器间最长距离为 x + y- 2 。
证毕。
综上可见,本文所研制的高效能云计算节点总体具有如下性质:龙芯3A处理器间通过HT总线互连,在定义5的规则2下,(,4,4)nΓ的SMP间互连形成2D mesh结构,因此理论上具有mesh结构的所有特性,适用 mesh结构的路由策略。在实际工程中,需根据具体需求和工艺制造特性确定节点的处理器规模。
4 通信机制
基于第2节的逻辑结构和第3节的互连结构,本文研制的高效能云计算节点总体包含3套网络,分别是板上HT总线网络、节点间的InfiniBand网络和吉比特以太网。本节将根据龙芯处理器HT总线特性重点介绍基于HT总线的通信机制。
如图1和定义5所示,高效能云计算节点的四组is都是cc-NUMA结构的SMP,因此,路由分SMP内和SMP间两层。如图2(a)所示,在SMP内,各处理器通过HT总线互连,4个处理器具有共同的内存空间,因此,SMP内的处理器间通过共享内存通信,故通常可认为 SMP内的处理器间通信距离为0。SMP间可通过HT总线传递数据,通信规则基于2D mesh结构进行。
龙芯处理器的4个SMP间通过地址映射实现隐式通信,具体的通信过程为:处理器识别访存地址,如果地址在本地SMP的内存空间,则通过共享内存通信;如果地址在地址映射的范围内,则由处理器负责路由到相应的其他SMP内存空间去。具体地,通过地址映射将图1配成了内外2个闭环通路,外环按:

顺序形成顺时针环路,内环按:
顺序形成逆时针环路,如图3所示。
在上述通信系统下,假定处理器 pj,i要访问pk,h,并用 o1表示外环, o2表示内环,则路由算法伪码如图4所示。

图4 路由算法伪代码
图4算法的基本原理为:如果源处理器与目标处理器在同一个 SMP内,则通过共享内存通信;否则优先通过内环通信,因为内环相比外环和 IB具有更短的通信路径。当内环路忙时,则选择通过外环通信;否则,绕道InfiniBand网络进行通信。
5 基于龙芯3A多核处理器的云计算节点系统实现
5.1 主板
在主板设计上,高效能云计算节点系统具有16个处理器,组成4个SMP,考虑到电路板制造和可调性等工艺问题,不能将系统设计成单块 16路的大主板。因此,计算节点被设计成对称的两块主板,每板包含8路2SMP,两板通过对插组成一个1 U的计算节点。 8路主板逻辑图如图5所示。
在部件组成上,高效能云计算节点系统总体基于16个龙芯3A处理器,每个处理器支持4条内存条。16个处理器放在1 U的标准高度和宽度的计算节点内。系统还支持4个QDR Infiniband高速网,4个吉比特以太网,另外支持VGA、串口和USB等。
在布局上,单板上有8个龙芯3A处理器,32条内存条,2个IO芯片,2个吉比特以太网接口以及VGA、USB和串口。每颗龙芯处理器支持4个内存条。IO芯片对外扩展Infiniband、以太网、VGA、USB和串口。
单主板的电子元器件多,但是主要的部件是处理器和内存,在布局上需重点考虑把这两类部件的布局和电子线路规划好。考虑到处理器之间的互连结构和各自连接内存条,因此,在布局上采用了规则的方阵式布局,即处理器放在中间,内存条放置在两侧。这样的布局能够使得处理器之间的高速信号连接线路最短,同时处理器与内存的连接线路也最短,电路信号上保证主板运行的可靠性。
在层数设计上,电路板采用12~20层的设计,以解决高速、低速数字信号和电源等模拟信号之间的干扰,从PCB印制板上首先保证信号的完整性。
在散热上,考虑到内存条和处理器的散热需求,因此采取如下布局方式:将处理器放在中间,较高的内存条放在两侧,所有的内存排列采取前后走向。其余的芯片如IO放置在不影响通道的位置。
5.2 硬件子系统
本节介绍其他关键子系统的设计方法。

高带宽 I/O子系统:在系统架构和主板设计中充分考虑了较高的带宽性能和较高的扩展能力。高带宽I/O子系统包括集成在主板上的高速Infiniband、吉比特以太网和I/O板卡槽。每个计算节点集成了4个QDR的高速Infiniband口,4个吉比特以太网,还有4个PCIE×8的I/O卡槽,可用于安装I/O板卡。这些对外的系统接口保证了对外高I/O带宽,主板集成4个QDR Infiniband接口,综合传输带宽达到160 Gbit/s。总体具有对外高带宽的网络,并可以通过外部的交换机连接成一个更大的系统,可见,高效能云计算节点具有很好的扩展性。
互连子系统:为满足系统的互连功能和良好的扩展性,每个计算节点设计了 4个 QDR的高速Infiniband口,4个吉比特以太网,还有4个PCIE×8的I/O卡槽,可用于安装I/O板卡对外网络连接。Infiniband网络接口可以连接到 Infiniband交换机上,组成高速的计算网络。吉比特以太网接口可以连接到以太网交换机上组成管理网络,同时也可以作为计算网络的后备使用。主板上的I/O板卡可以连接存储网络。
存储子系统:存储子系统设计包含本地存储和远程存储,其中,远程存储是通过 I/O卡对外连接实现的,本地存储是与主板直接连接的硬盘,用于安装操作系统和保存本地的数据。同时,主板上的每个处理器支持4个内存条,作为板级的存储,用于计算数据的保存。这3部分组成了每个计算节点的存储系统。在由多个计算节点组成的系统中,I/O系统和存储可合为一体,直接连接到高速Inifiniband网络上,提高I/O的带宽和访问存储的速度。
电源子系统:电源系统包括主电源模块、电源分配板和主板上的 DC-DC模块。系统采用宽电压设计,支持110~240 V、50~60 Hz宽电压输入。
高效能系统软件:高效能系统软件是高性能计算节点发挥其效能的关键。总体采用自下而上分 3层来考虑系统软件:节点层系统软件、整机系统软件层、应用支撑软件层。
具体地,如图6所示,各层功能划分和详细设计如下所示。

图6 高效能系统软件层次结构
节点系统软件层:单节点上承载的系统软件,主要包括基于龙芯3A的节点操作系统及其核心扩展以及节点提供的用户编程工具、环境和库。
整机系统软件层:整机(多节点)层次所需的系统软件。
应用支撑软件层:支撑应用编程的环境和工具软件。
6 原型实现与性能测试
笔者实现了基于龙芯3A多核处理器的高效能云计算节点,其整机与机箱实物图如图7所示。主板为对称的上下2个PCB板,由四对板间连接器互连,电源位于主板右侧,风扇位于主板后端,后面板提供2个IB接口,前面板提供网卡接口、USB接口以及一块含电源开关。系统为每个龙芯3A处理器的每个DDR2通道各提供一个DDR2 DIMM内存,位于芯片同侧,因此板上每2个内存条为一个处理器提供服务。基于上述分析,所实现的高效能云计算节点的关键技术特征概括如下。

板上机群:单计算节点包含两块完全相同的PCB,每个PCB可分为左右近似对称的两部分,其中每部分运行一个操作系统。由于PCB间采用了高速接插件,因此从整个节点上看,对插的两块PCB可作为拥有4个操作系统的板上机群系统。
高密度高安全可控计算节点:每个节点包含国产龙芯16路处理器,处理器之间可通过Hyper Transport互连。单节点共包含16路处理器,虽然单节点上的 4个操作系统每个都只包含其中的4路处理器,但龙芯 3A处理器的可扩展性允许节点内部16路处理器互连,构成4×4的二维mesh结构,并可利用 BIOS指定处理器间访问的路由配置。
多种互连方式:主板选用 InfiniBand公司MT25408芯片实现系统间高速互连,选用RTL8211B芯片结合nVidia南桥芯片的Mac层实现吉比特以太网互连,并且处理器的HT1总线可用于单节点内跨系统多处理器间互连,实现了多种互连方式。
7 性能测试
7.1 测试方法
为了测试基于龙芯3A多核处理器的高效能云计算节点的性能,如表1测试方法所示,其中“★”表示该行所对应的测试用例对该指标进行了测试,“—”表示该行所对应的测试用例对该指标未进行测试。本文对所实现的系统采用了3个测试用例,从功耗体积、通信性能和Linpack性能3个目标进行了实验。在测试用例和度量指标选取上,对测试用例1,选取常用的功耗和体积2个常用指标。对测试用例2,分别从点对点通信和MPI全局通信2个角度选取带宽和延迟进行了测试。对测试用例 3分别从Linpack性能和可扩展性进行测试分析。本实验章节的部分数据是对论文成果[8]的数据扩展。
为表述方便,对后续的章节将用到的数学符号的含义说明如表2所示。
7.2 实验结果分析
实验1 计算节点效能
单节点机的测试结果如表3所示。表3主要从单节点的 CPU数目、功耗、性能、体积角度反映了基于龙芯3A的高效能云计算节点的效能。
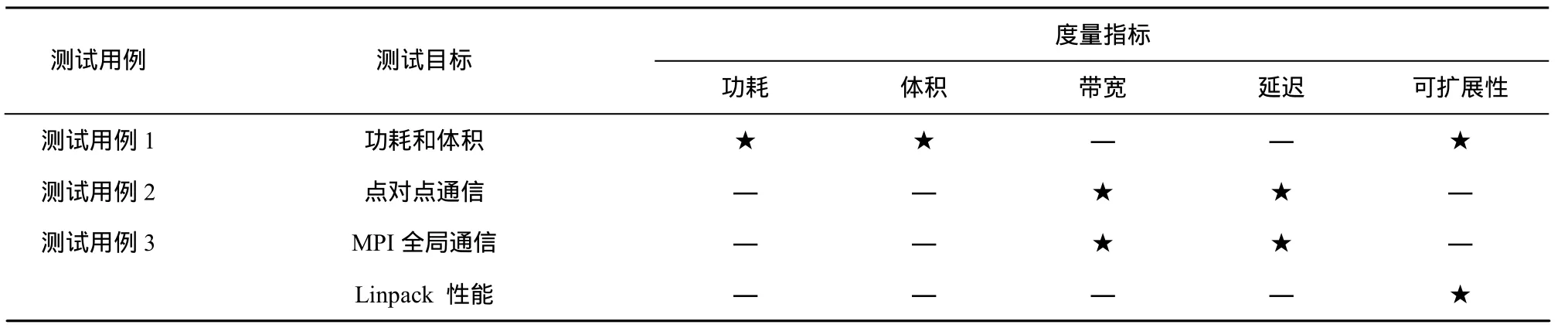
表1 测试方法概览
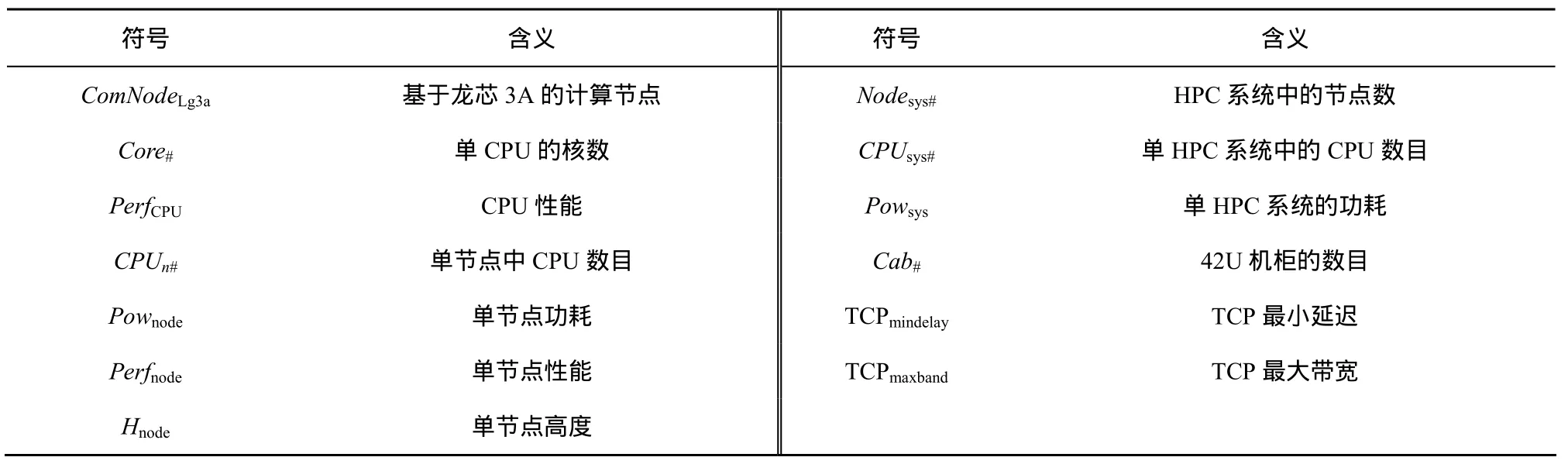
表2 简写数学符号含义

表3 单节点的效能

表4 基于不同处理器构建1PF高效能计算机系统的比较
基于龙芯3A的节点机的情况如表4所示,表4估算了分别用Intel 8核、AMD 6核、龙芯3A和龙芯3B构建1 Pflops计算单元的功耗和体积。从表4中可以看出,如采用龙芯3B处理器构建1 Pflops计算单元,计算单元总功耗约为 477 KW,体积约占13个42U工业机柜。可见,相对于同期主流的x86处理器,用龙芯3A(尤其是龙芯3B)处理器构建计算单元在功耗和体积方面有明显优势,能较好地应对高效能目标中的低功耗和高密度挑战。
实验2 通信性能
为了便于对基于HT互连的通信模块的时延性能进行对比分析,本文还在相同条件下使用NetPIPE软件测试了IB的通信时延和带宽。针对IB高速网卡的通信时延测试主要分为两部分:一部分是测试系统的CPU直接与IB网卡相连,一部分是测试系统的CPU与IB网卡间接相连;针对IB高速网卡的通信带宽测试主要分为两部分:分别是通信系统的CPU均直接与IB网卡相连以及通信系统的CPU均与IB网卡间接相连。
7.3 点到点通信性能
使用NetPIPE 测试软件,在度量指标上测试不同计算单元间的点到点通信延迟与带宽。在测试互连场景上,对3种互连通信场景进行测试,具体包括同一虚拟子网内2个计算节点,同一IB子网内2个计算节点和相邻虚拟子网内2个计算节点间。测试结果如表5所示。
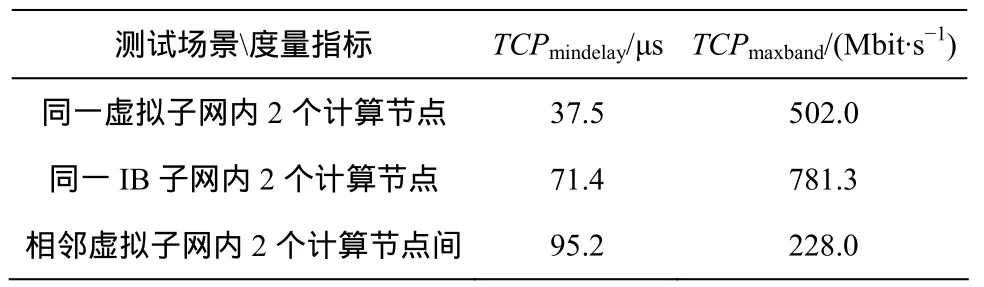
表5 点到点通信延迟和带宽
7.4 MPI全局通信性能
使用IMB 2.2测试软件,对节点机不同规模的计算节点通过16 384 byte的SendRecv、Allreduce、Reduce、Allgather、Allgatherv、Alltoall、Bcast测试,得到相应规模的带宽或延迟,通过Barrier测试,得到同步延迟、MPI全局性能测试结果如表6所示。

表6 MPI全局通信带宽和延迟
实验3 系统Linpack性能
16个CPU(64 核)规模的系统和矩阵阶数从10 000增加到48 000时,Linpack浮点运算性能如图8所示,在64核时,性能达到44.5 Gflop。

7.5 实验结果小结
对原型系统的实验和测试表明,基于龙芯3多核处理器的高效能节点机单节点具有每秒0.256万亿次浮点运算能力(Tflops),单一机柜可容纳42个1 U节点机箱,672颗CPU,2 688个CPU核(672×4),总体具有高密度、高性能功耗比,基于自主知识产权处理器和安全可控性等优点。
7.6 相关研究
云计算节点是高性能计算机体系结构中除加速节点、主机单元、通信网络等外的核心部件之一,计算机节点的高效能已成为了整机“高效能”目标能否达成的关键。首先,目前在研和投入使用的一批大规模高性能计算机均十分注重计算节点高效能问题的突破,代表性的系统主要包括:Cray Titan[4]、日本富士通K计算机[9]、Tianhe-1A、Jaguar[10]、Cray的Cascade和 Baker、IBM 的Roadrunner等[11~18]。其次,从处理器角度来看节点机,近年来随着多核处理器的兴起,目前主流的高效能计算机节点普遍呈现采用多路多核技术的趋势。但现有技术在路数上,尤以4路和8路居多,8路以上高密度的比较缺乏。再次,在处理器选型上,现有高效能云计算节点机仍然主要采用国外处理器居多,在基于国产(如龙芯3A多核)处理器的高密度的计算节点的实践上相对较为稀少甚至缺乏。文献[8]中概要介绍了计算节点在设计和研制中的一些关键问题及其硬件方面的设计(包括系统总体结构以及处理器互连、时钟、上电与复位、内存、主板和结构等子系统)方法,但文献[8]更多是从高性能计算角度,并没有从云计算角度考察,尤其是并没有对云计算节点机的逻辑结构、互连规则、通信方法和软件系统等给出更为细致的理论建模和详细设计与实现等的介绍,本文工作是对文献[8]的进一步扩展和系统化。基于现有研究存在的问题,本文介绍了一种基于龙芯 3A的高效能云计算节点机软硬件设计和实现方法。所实现的基于龙芯 3A处理器的节点机是一款16路1 U机架式计算节点,占地0.46 m2,峰值性能256 GFlops,峰值功耗不超过300 W/U,计算/功耗比约0.853 GFlops/W,如表7所示,与IBM等一些主流高性能计算节点相比,其具有高密度、低占地的显著特点,在处理器3A升级为 3B和软件进一步优化后,龙芯节点机的高性能、低功耗特点在实际运行中将体现得更为明显。
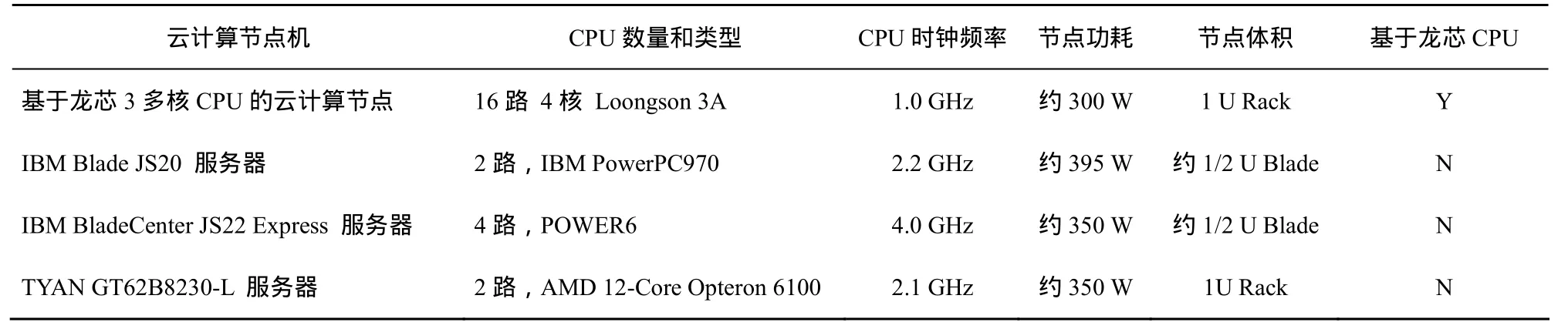
表7 相关云计算节点机的比较
8 经验和教训
本节将重点对基于龙芯多核处理器的高效能云计算节点机在软硬件设计与实现方面的经验和教训,以及与现有系统的优势与差距方面的具体原因进行一些讨论与分析。
系统架构方面:相对于现有系统,由于本系统采用mesh结构互连的16路处理器,由每4路处理器构成一个CC-NUMA单元,该架构的优势是能够充分利用并行性,但受系统总线带宽以及龙芯处理器开放接口数的限制,所能支持的处理器数目会受到限制,再加上软硬件设计工艺复杂,对于商用化目标来说,相对造价成本会较高,目前笔者正在进一步优化该架构,正在研究一种“多胞胎”架构的节点机。
处理器的性能和稳定性方面:由于龙芯处理器是核心,处理器的性能和稳定性直接关系到系统的性能、设计和实现的难度和效果。
器件布局、高速型号处理和散热方面:由于单主板的电子元器件数量和种类都比较多,需要处理的核心部件是处理器和内存,在布局上尤其需重点考虑把这两类部件的布局、高速型号处理、电子线路和散热规划好。基于对处理器之间的互连结构,及其各自连接内存条以及工艺难度等方面的综合考虑,因此,在布局上需要综合考虑好处理器和内存条互连,尤其要处理好高速信号的连接问题,笔者最终采用了规则的方阵式布局,即处理器放在中间,内存条放置在两侧。这种规则布局的方式能够使得处理器之间的高速信号连接线路最短,同时处理器与内存的连接线路也最短,电路信号上保证主板运行的可靠性。在满足内存条和处理器的散热需求时,需要综合考虑分冷效果,笔者采取将处理器放在中间,较高的内存条放在两侧,所有的内存排列采取前后走向,这样有利于冷风从主板的前端向后端流动制冷,其余的芯片如I/O放置在不影响通道的位置。
互连方式方面:多种方式的支持目标要求重点考虑如何支持系统间的高速互连、吉比特以太网互连以及单节点内跨系统处理器互连。笔者的主板选用InfiniBand公司MT25408芯片实现系统间高速互连,选用 RTL8211B芯片结合 nVidia南桥芯片的Mac层实现吉比特以太网互连,并且处理器的HT1总线可用于单节点内跨系统多处理器间互连,这样就实现了多种互连方式。
软硬件配合方面:软硬件总体采用分层的设计思路,但底层软件(如操作系统等)对龙芯处理器的指令集等的依赖性还是比较大,在软件实现方面也需要针对性地定制和优化,以取得较好的性能效果。
在商用化及云计算节点经济性能方面:当前系统总体处于原型系统研制阶段,尚没有价格方面的数据。笔者基于材料成本进行了初步估算,除龙芯CPU外,系统的其他材料都是市场通用的材料。一颗龙芯3A CPU约1 500元,而目前性能和龙芯3A最接近的x86服务器CPU的成本约为500元。总体看来,云计算节点的经济性能和国外同类产品相比而言仍然存在比较大的差距,而这方面差距的核心是由国产 CPU的性能和成本等核心元器件决定的。随着国产处理器生态环境的逐步改善,基于国产处理器的高效能云计算节点机预期或能取得更大的商业应用上的突破。
9 结束语
适于云计算的高效能计算系统是新一代高性能计算机重要研制目标。高效能云计算节点是
HPCS的核心部件,是实现高效能目标的关键。性能功耗比、高集成度等高效能目标的实现是当前高效能计算节点面临的关键挑战。基于国产处理器的高效能云计算节点突破更是我国自主知识产权和安全可控高效能计算机战略的关键。本文关注于现有研究中基于龙芯处理器的高效能节点机实际系统相对缺乏等问题,提出了一种基于龙芯3A多核处理器的高效能云计算节点的软硬件设计和实现方法,并研制成功了相关的原型系统。测试数据、已实现的原型系统以及同现有系统的对比,验证了本文所研制的系统在基于国产龙芯处理器、性能功耗比可集成度和自主知识产权等方面具有优势,是基于国产处理器的一个重要尝试。本文的工作更是下一代基于龙芯3B高效能云计算节点,以及基于龙芯处理器的高效能计算机设计与研制的重要基础。
基于本文工作成果,目前正在开展基于龙芯3B国产处理器的高效能云计算节点,以及适于云计算的基于龙芯处理器的高端服务器的软硬件设计与研制等工作。
[1] SOTOMAYOR B, MONTERO RUBEN S, LIORENTE I M, et al.Virtual infrastructure management in private and hybrid clouds[J].IEEE Internet Computing, 2000, 13(5):14-22.
[2] ZHANG W, SONG Y, RUAN L, et al. Resource management in internet-oriented data centers[J]. Journal of Software,
[3] 2H0p1c2s,-2h3ig(2h) :1p7r9o-d1u9c9t.ivity computer systems[EB/OL]. http://www.highproductivity.org/.Top500 Supercomputer 2012 Rank List.
[4] http://www.top500.org/lists/2013/11/.
[5] CUI Y F, OLSEN KIM B, JORDAN T H. Scalable earthquake simulation on petascale supercomputers[A]. Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing,Networking, Storage and Analysis[C]. Washington DC, USA, 2010.1-20.
[6] RUAN L, XIAO L M, ZHU M F. Content addressable storage optimization for desktop virtualization based disaster backup storage system[J]. China Communications, 2012,9(7):1-13.
[7] LIU Y H, ZHU M F, XIAO L M, et al. Design and implementation of loongson 3A CPU based high productivity computing nodes[J]. High Performance Computing Technology, 2010, 6:46-53.
[8] KUROKAWA M. The K computer: 10 Peta-FLOPS supercomputer[A].The 10th International Conference on Optical Internet(COIN)[C].Yokohama, Japan, 2012.29-31.
[9] XIE M, LU Y T L, LIU L, et al. Implementation and evaluation of network interface and message passing services for tianHe-1A[A]. 19th Annual Symposium on High Performance Interconnects (HOTI)[C].Santa Clara, CA, 2011.78-86.
[10] NCCS[EB/OL]. http://www.nccs.gov/jaguar, 2010.
[11] MCCURDY C W, STEVENS R. Creating Science-Driven Computer Architecture: a New Path to Scientific Leadership[R]. NERSC Technical Report, 2002.
[12] VECCHIOLA C, PANDEY S, BUYYA R. High-performance cloud computing: a view of scientific applications[A]. The 10th International Symposium on Pervasive Systems, Algorithms, and Networks[C].2009.4-16.
[13] HABATA S, YOKOKAWA M, KITAWAKI S. The earth simulator system,the earth simulator system[J]. NEC Res & Develop, 2003, 44(1):21-26.
[14] LAUDON J, LENOSKI D. The SGI origin: a ccNUMA highly scalable server[A]. International Symposium on Computer Architecture[C]. Colorado, USA, 1997.241-251
[15] ABTS D. The cray XT4 and seastar 3-D torus Interconnect[M]. David Padua,ed: Encyclopedia of Parallel Computing, 2011.470-477.
[16] SCOTT S. Thinking ahead: future architectures from cray[EB/OL].http://nccs.gov/news/workshops/cray/pdf/Cray_Tech_Workshop_sscot t_2_26_07.pdf, 2007.
[17] FELDMAN M. ORNL gears up for new leadership computing systems[EB/OL]. http://www.hpcwire.com/ hpc/1356225.html,2007.
[18] TURNER JOHN A. Roadrunner: Heterogeneous Petascale Computing for Predictive Simulation[R]. Los Almos Unclassified Report LA-UR-07-1037, 2007.
