异构网络化汽车电子系统中多DAG离线任务调度
2013-09-18谢国琪李仁发杨帆黄卫红
谢国琪,李仁发,杨帆,黄卫红
(湖南大学 嵌入式与网络计算湖南省重点实验室,湖南 长沙 410082)
1 引言
近年来,为了满足人们在安全性、驾驶性能等方面提出的更高要求,汽车电子系统规模和复杂性骤增。它由动力控制子系统、底盘控制子系统、安全控制子系统和车身控制子系统等多个子系统组成,每个子系统又包括多个功能任务(如安全控制子系统包括防抱死制动、线控刹车等)[1,2]。这些子系统由遍布车身的上百个的异构电子控制单元(ECU,electronic control unit)通过各类异构总线互联和协作以完成各种智能控制功能[2]。如宝马7 系,其6个子系统共享70多个ECU,ECU之间通过LIN、CAN、FlexRay、MOST 和Ethernet 5种类型的网络和网关实现互连[3];奥迪A8则包含95个ECU遍布7个子系统,由CAN、FlexRay、LIN和MOST 4种总线类型互联[4]。因此新一代汽车电子系统体系结构演变为异构化、网络化和复杂化的分布式网络体系结构。
然而,异构网络化汽车电子系统是一个典型的混合关键级嵌入式系统[5],对性能与安全关键功能子系统的调度要求极其苛刻,例如防抱死制动功能与线控刹车功能,即使调度结果正确,但只要有一个无法在截止期限内完成,执行结果也就毫无意义,甚至造成车毁人亡的灾难性后果;与此同时,网络化使系统产生的通信数据量剧增且结构多样化,使调度极易产生大量的通信开销,从而造成系统调度结果延迟,通信开销已成为影响调度性能的主要瓶颈[1]。因此如何同时保证多个功能子系统都能在截止期限内完成并降低调度长度和减少通信开销已成为异构网络化汽车电子系统调度问题所面临的主要挑战。
2 调度模型
汽车电子系统的异构化、网络化使其调度问题变得复杂,因此需要一种形式化的调度模型加以描述。由于汽车电子系统由多个异构 ECU(不同供应商提供的ECU在设计方法或硬件实现上不同)、传感器和执行器等处理设备组成,本文将这些处理单元统称为处理器,并用集合描述这些异构处理器的集合。以安全功能子系统为例,它的实现是由多个相互具有数据依赖的任务组成。首先通过摄像头采集车道偏离、红外传感器感知夜视、雷达自适应巡航控制,超声波辅助停车等;然后通过传感器融合,目标对象监测和识别技术交由刹车片、方向盘和节流阀等执行设备处理;再由线控转向、线控刹车、线控加速等功能做出行驶决策。上述功能任务在不同的处理器上执行,并产生大量的通信开销[6]。
因此,可以用一个有向无环图DAG描述一个功能子系统[7,8]。G={N,W,E,C}表示一个 DAG,其中,N={n1,n2,…,ni}表示任务集合;由于处理器处理能力的异构性,使不同任务在不同的处理器计算时间不尽相同,因此描述W是一个|N|×|P|的矩阵,wi,k表示任务 ni在 pk上的计算执行时间开销;E={e1,2,e2,3,…,ei,j}描述为任务间的优先级约束与数据依赖关系集合;由于处理器之间通过 CAN、FlexRay、LIN和MOST 等多种类型的网络和网关实现互连,不同总线的带宽不尽相同,因此任务之间的通信开销也不同,描述 C={c1,2,c2,3,…,ci,j}具有数据依赖的任务之间的通信开销集合,如果将这2个任务分配到同一个处理器上,则通信开销为0。 pred(ni)表示任务ni的直接前驱任务集合,ind(ni)表示ni的入度,也就是其直接前驱任务集合的个数,当前任务只有在它全部前驱任务的数据到达后才能执行。succ(ni)表示任务 ni的直接后继任务集合,outd(ni)表示 ni的出度,也就是直接后继任务集合的个数。没有前驱任务的任务为入口任务,记为nentry。没有后继任务的任务为出口任务,记为nexit。DAG任务模型不仅考虑了考虑任务的优先级,还考虑了任务和处理器之间的相关性以及任务之间的通信开销,因此适合于汽车电子系统的调度问题研究。
异构网络化汽车电子系统包括动力控制子系统、底盘控制子系统、安全子系统和车身子系统等多个网络子系统,因此需以多DAG[9~13]来表示汽车电子系统调度模型,每个子系统表示一个 DAG,DAG之间共享处理器和通信总线,由于各DAG都是同时发生,因此属于离线模型。本文用 GS={G1,G2,…,Gm}表示多DAG离线任务调度模型。因此可将异构网络化汽车电子系统的任务调度问题形式化为多DAG离线任务调度问题并进行研究。以下给出在多DAG中与本文密切相关的几个概念。
定义1 DAG调度长度(schedule length)。Makerspan(Gm)表示Gm的所有任务调度完毕后,其出口任务的完成时间。
定义2 多DAG调度长度(multiple DAG schedule length)。makerspan(GS)就是GS中具有最大调度长度DAG的调度长度。
如图1为一个多DAG任务模型,包含DAG-A和DAG-B,表1为相应的多DAG计算开销矩阵,本文采用与文献[11]相同的模型实例,如图1和表1所示,例如图1中,A1与A2之间的数字18表示任务A1与任务A2若分配不在同一处理器上执行的通信开销,若A1与A2在分配在同一处理器上,则通信为0;表1中A1与p1所结合表示的数字18表示为任务A1在处理器p1上的计算执行开销为14。

图1 2个DAG任务模型实例
3 相关研究与理论知识
谢勇[8]等研究时间触发网络总线技术 FlexRay的静态段配置消息调度,KLOBEDANZ[14,15]等研究FlexRay的静态段配置容错调度,然而上述算法仅针对单一网络总线 FlexRay,且限于同一功能子系统内调度,不适应于汽车电子系统的异构化、网络化和复杂化需求。
3.1 多DAG任务调度的公平性
异构系统多DAG也包含任务优先级排序和处理器分配 2个步骤。HEFT[7]算法提出了向上排序值的概念,其计算公式为
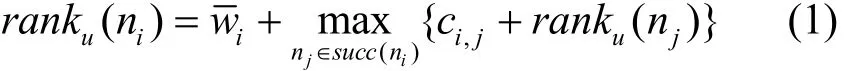
向上排序值已成为事实的任务优先级排序标准而被多种多DAG任务调度算法采用,但采用平均值wi作为计算开销,对于大规模的多DAG任务调度,计算结果则不够精确。
HÖNIG[9]等提出了将多个 DAG合成一个复合DAG后,再利用诸如HEFT等经典的单DAG启发式调度算法调度。但是此方法对于某些短DAG有明显的不公平性,例如在采用HEFT算法的情况下,尽管它们是同时调度,但是由于短DAG的向上排序值相比长DAG明显要小,因此短DAG中的任务始终得不到执行,最终造成短DAG调度长度和整个多DAG的调度长度都过长,因此需要在多DAG调度中保证一定的公平性,以降低调度长度。
ZHAO[10]首次指出了在多 DAG调度中的公平性问题,并提出了slowdown驱动的多DAG公平任务调度算法Fairness。其思想是首先基于HEFT算法对每个DAG调度一次且记下每个DAG的调度结果,并把各自的调度长度作为此 DAG的值,然后将所有 DAG按降序排列放入列表,选择具有最大 slowdown值的就绪任务进行调度,并更新slowdown值(如果有多个DAG的slowdown值相等,则选择向上排序值最大的任务调度)。slowdown计算公式为
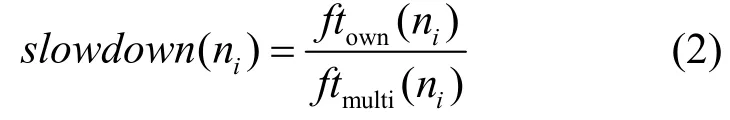
其中,ftown(ni)表示 ni单独调度的完成时间,ftmulti(ni)表示ni在多DAG中调度的完成时间。如此重复,直到列表中没有未调度完成的DAG为止。同时文献[10]也提出了评价DAG不公平性的具体方法,首先计算某个DAG的slowdown值,其计算公式为
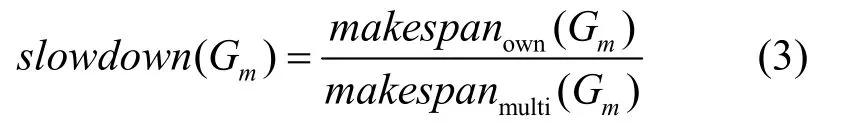
其中,makespanown(Gm)表示 Gm单独调度的调度长度,makespanmulti(Gm)表示 Gm在多 DAG中调度的调度长度。基于slowdown(Gm)计算多DAG系统调度的不公平性,其计算公式为
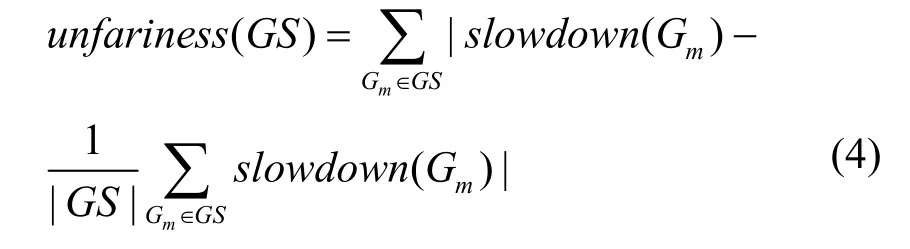
由于选择任务调度是slowdown驱动的,因此算法的关键思想是 slowdown的更新。此算法虽然在每分配一个任务后通过更新 slowdown值来保证DAG之间的公平性,但还是会产生不公平性的问题。例如,在DAG-A和DAG-B中,它们各自的slowdown值相等并且值都是1,但是DAG-A中就绪任务的向上排序值大于DAG-B,根据策略,则会选择DAG-A中的就绪任务调度,调度完后,DAG-A的slowdown还是1,则会继续选择DAG-A中的就绪任务进行调度,从而造成DAG-B中的就绪任务得不到分配处理器的机会,这样在调度开始处,就出现对后调度的DAG的不公平问题。田国忠[11]等将Fairness算法改成动态调度算法E-Fairness,除了对新提交的DAG优先调度一次外,没有其他改进方法。但由于还是 slowdown值驱动选择任务,因此同样会出现较高的不公平性。而且Fairness算法和E-Fairness算法在每次分配一个任务后需要更新slowdown值并对各DAG按升序排列,造成算法的复杂度较高,特别是在DAG个数很多的情况下,算法的效率更低。
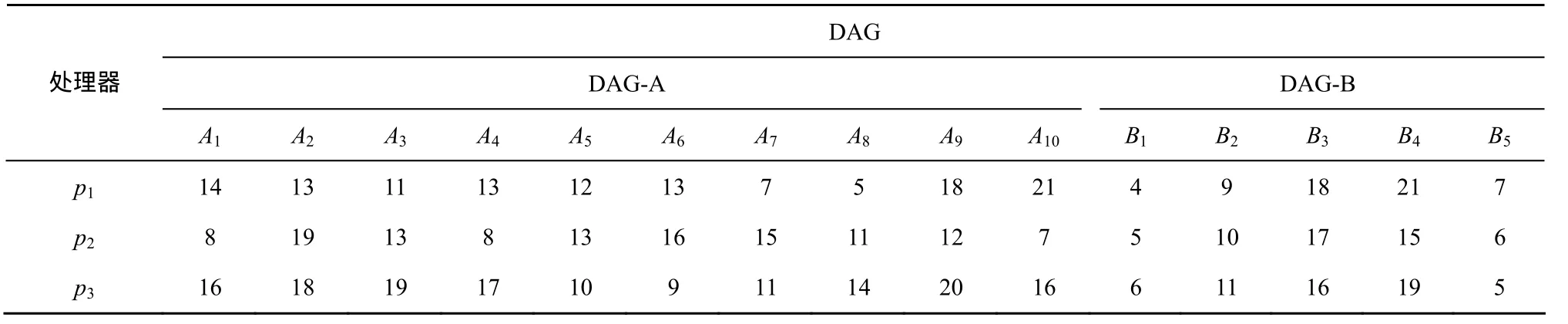
表1 DAG-A和DAG-B中各任务在处理器上的计算开销
3.2 多DAG任务调度中的轮转调度
轮转调度(round-robin)[17,18]由于具有较好的公平性,在数据通信网络和多处理器调度中得到了广泛的应用。LI[17]等提出的DWRR(distributed weighted round-robin)算法则让大规模多处理器系统的调度具有更好的调度效率和更少的延迟;MOHANTY[18]等提出的 FBDRR(priority based dynamic round robin)等算法则在减少等待时间和响应时间上具有更好的性能。轮转调度在实现公平调度上具有优势,并且具有较高的调度效率。
HSU等[12]提出了基于轮转调度的在线公平调度OWM(online workflow management)算法,在OWM中,其策略是从每一个DAG中选择一个向上排序值最大的就绪任务放入DAG就绪队列。然后从 DAG就绪队列中轮转选择最大向上排序值的任务并选择具有最小完成时间的处理器准备调度。此算法的轮转调度策略是优先调度最大的就绪任务,而短 DAG就绪任务的相比长DAG就绪任务的总是要短,因此对短DAG造成了明显的不公平性,策略标准过于单调。
ARABNEJAD等[13]提出了基于轮转调度的FDWS(fairness dynamic workflow scheduling)算法,该算法也是在线调度,其策略也是从每一个 DAG中选择一个向上排序值最大的就绪任务放入就绪队列,然后从就绪队列中不再选择具有向上排序值的任务,而是根据各个DAG剩余的未调度任务的比例及其关键路径长度定义了一个 rankr值,其计算公式为
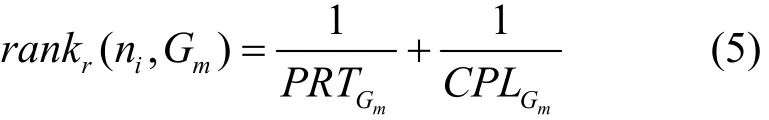
其中,PRT表示剩余任务数的百分比,CPL表示关键路径长度。此算法在考虑插入的基础上将任务分配具有最小完成时间的处理器,但由于短DAG的rankr相比长DAG总是要长,策略标准同样较单调,因而此算法对长DAG造成了明显的不公平性。虽然OWM和FDWS都是在线调度,但只要多个DAG同时发生,也就简化成了离线调度。
与单 DAG任务调度的最大不同之处在于多DAG任务调度必须要保证每个DAG中的每个任务都能够及时被调度。表2总结出了目前多DAG任务调度算法的特点,其中,M_HEFT算法即将多个DAG合成一个DAG后,再使用HEFT算法调度。
综上所述,现有多DAG任务调度算法并不能适应于当今汽车电子系统的异构化、网络化和复杂化特征,主要体现在:slowdown值驱动的多DAG公平任务调度算法复杂度高,且容易在开始调度时就出现较高的不公平性;轮转调度的多DAG公平任务调度算法的策略标准过于单调而易导致不公平性;通信开销已成为影响调度性能的主要瓶颈,但缺乏相应的解决方案。汽车电子系统是一个典型的混合关键级嵌入式系统,既需要确保实时性又要降低调度长度。为此,本文旨在通过采用减少通信开销的轮转调度的任务优先级公平排序标准以及综合考虑通信开销、完成时间和拓扑结构的处理器选择标准。提出相应的减少通信开销、降低调度长度和满足安全关键与实时性的多DAG离线任务调度算法,以适应于汽车电子系统的异构化、网络化和复杂化需求。

表2 4种多DAG任务调度算法比较
4 调度算法
下面通过图1和表1所示的多DAG任务调度模型来说明本文所提出的调度方法。这个多 DAG调度模型的复杂度、结构及各项参数与文献[11]使用的实例完全一样。
4.1 任务优先级排序
1)DAG内的任务优先级排序
由于 E-Fairness[11]、OWN[12]和 FDWS[13]等多DAG任务调度算法使用经典的任务优先级排序ranku(ni)中采用平均值wi作为计算开销, 实际上将处理器的异构特性消除,演变成同构计算。本文考虑异构计算特性,认为每个任务在每个处理器上都要有相应的向上排序值rankupd(ni,pk),计算公式为
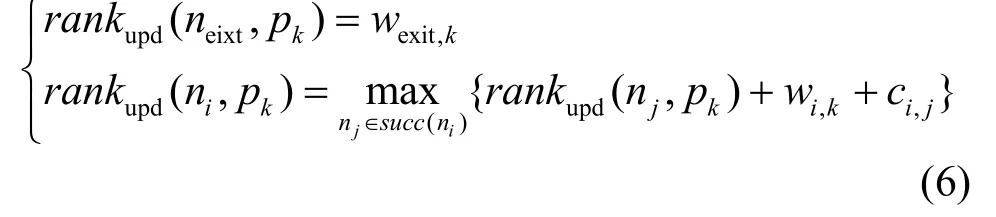
任务的出度也是影响任务优先级排序的因素。直接后继节点更多的任务如果不优先执行,则其所有后继节点都不能就绪,直接或间接地加大了DAG的调度长度。所以把任务的出度当作计算向上排序值的因子。

这样得出的 r ankupd(ni)更符合异构化特征。依据图1和表1提供的多DAG实例,可计算出每个任务的向上排序值rankupd(ni,pk)和rankupd(ni),如表3所示。
2) 多DAG任务公平性优先级排序
定义 3 通信开销权值(COW, communication overhead weight)。任务ni的通信开销权值cow(ni)表示此任务与其所有直接前驱可能产生的最大通信开销之和,其计算公式为
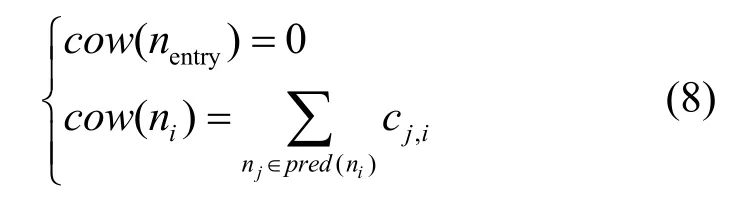
slowdown值驱动的多DAG公平任务调度算法复杂度高,不公平性也高,特别是在多DAG规模很大的情况下,算法的效率更低,因此不适应于复杂化的汽车电子系统。本文也采用公平性较好的轮转调度,针对多DAG系统GS={G1,G1,…,Gm},首先分别从各DAG就绪任务中取出一个rankupd(ni)最大的就绪任务放入 REDAY_QUEUE。对于 REDAY_QUEUE队列中的就绪任务,如果其通信开销权值较大,说明其容易与其直接前驱节点产生更大的通信开销;如果此任务优先执行,则处理器空闲槽出现的几率大增,从而造成调度长度过长。
汽车电子系统的异构化和网络化使通信数据剧增,各总线的带宽又受限,再加上调度产生的大量开销,则使网络负载不堪重负,因此减少通信开销成为调度的主要目标之一,因此,本文优先调度通信开销权值较小的任务,则会尽可能地减少空闲槽出现的几率。本文提出基于通信开销权值的轮转调度的公平排序标准,具体策略为:
(a) 计算每个 DAG中每个任务的向上排序值rankupd(ni);
(b) 分别从各DAG中取出一个rankupd(ni)最大的就绪任务,放入到 DAG的就绪队列 REDAY_QUEUE;
(c) 基于通信开销权值,对REDAY_QUEUE升序排序;
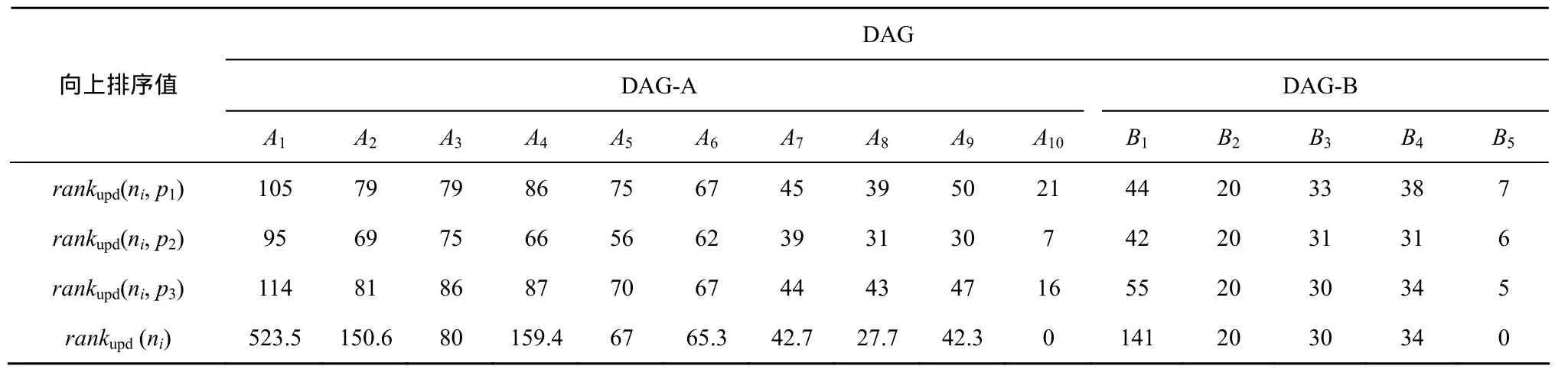
表3 DAG-A和DAG-B中的向上排序值
(d) 从REDAY_QUEUE中轮转选择具有最小通信开销权值的任务分配处理器,直到 REDAY_QUEUE为空再重复步骤(b)。
4.2 处理器选择
相比任务优先级排序,处理器选择则更加复杂。例如,DAG-B中,如果将所有任务分配到同一个处理器,那么其总通信开销为 0,但使调度长度最大串行化;反之,如果将任务负载均衡的分配到相应处理器,不但不一定使调度长度最小化,而且可能消耗较大的通信开销。
1) 处理器选择值
定义4 最早开始时间(EST, earliest start time)。est(ni, pk)表示在处理器pk上,从入口任务nentry到任务ni的最长路径长度(不包含ni本身的计算时间),也就是在处理器pk上,ni最早可能开始执行的时间,计算公式为
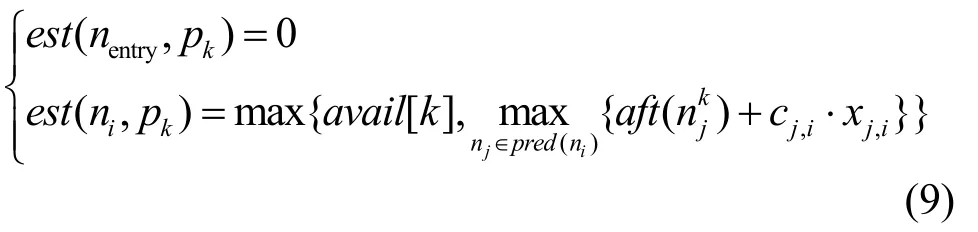
其中,cj,i为任务nj和任务ni的通信开销,xj,i取值为 0或 1, nj∈ p red(ni),若任务nj和任务ni分配在同一处理器上则xj,i=0,否则xj,i=1; a vail[k]表示处理器pk获得的最早可用时间; a ft(nk)表示任
i务ni的实际完成时间且ni被分配在处理器pk执行,由此公式可知当ni为出口任务时,a f t(nk)为DAG
exit的调度长度,因此 a ft(nk)影响DAG的调度长度。
j任务ni在处理器pk的最早完成时间eft(ni, pk)表示为
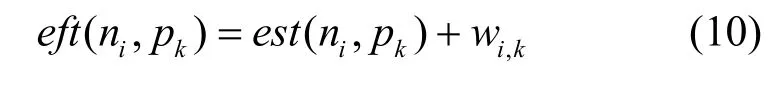
E-Fairness、OWN和FDWS等多DAG任务调度算法都以最早完成时间eft(ni,pk)作为分配处理器的策略,一方面以“向下看”的角度综合考虑了调度长度和通信开销;但另一方面,忽略了DAG的拓扑结构对调度长度的影响,即还需要以“向上看”的角度考虑调度完相应任务后,此任务距离出口的时间和通信开销。用处理器选择值select(ni, pk)代替eft(ni, pk),计算公式为
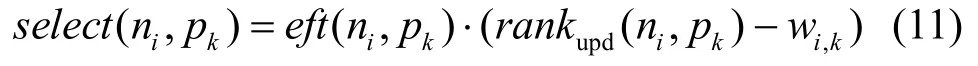
在同构计算环境下, r ankupd(ni, pk)和 wi,k对每个处理器而言都是相等的,不需要考虑,这也说明了E-Fairness、OWN和FDWS算法在处理器分配上也是在同构计算环境下进行的。而 s elect(ni, pk)的计算则从“向下看”和“向上看”的角度,综合考虑调度长度和通信开销对处理器分配的影响。
2) 插入分配法
正如图 2(c)所示,多DAG任务调度中,可将符合插入条件的任务插入到所有因优先级约束和通信开销造成的处理器空闲槽中,以提高处理器利用率,并能降低调度长度。插入分配过程为:
(a) 记录每个处理器的空闲时间段,用 SLOT_SET(pk)表示pi的空闲槽集合,每个处理器都有一个空闲槽集合;
(b) 在对任务 ni进行处理器分配时,遍历所有处理器,搜寻满足[est(ni,pk), eft(ni,pk) ] 属于SLOT_SET (pk)的处理器空闲段;
(c) 如果只存在唯一的空闲段,则直接插入的;如果存在多个处理器的空闲段,则选择选择值最小处理器插入,并更新相应的SLOT_SET。
为此,得出本文的多DAG处理器选择标准:将从DAG的就绪队列REDAY_QUEUE中选择的任务,在考虑插入法的基础上分配到具有最小选择值的处理器上调度,直到 REDAY_QUEUE中的任务全部分配到相应的处理器。
4.3 公平调度算法
定义 5 DAG 通信开销 (DOC, DAG communication overhead)。Gm中具有直接优先级约束的所有任务因没有分配在同一个处理器而消耗的通信开销之和,即
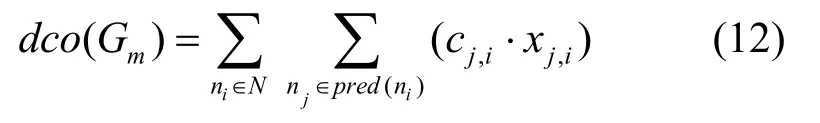
DAG本身可能产生的最大通信开销则为
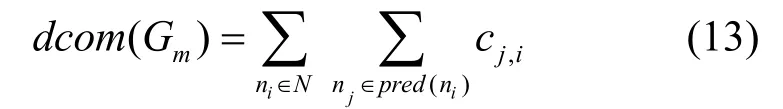
定义6 多DAG通信开销率(MDCOR, multiple DAGs communication overhead ratio)。指多DAG中,所有DAG的通信开销之和与其可能产生的最大通信开销之和的比值。那么,由M个DAG组成的多DAG 系统 GS={G1,G1,…,Gm}调度完成所付出的通信开销率表示为
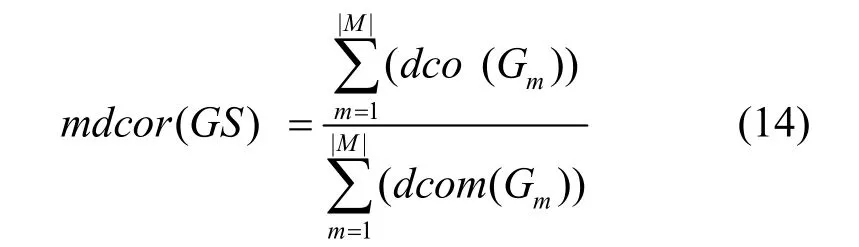
基于4.1节提出的多DAG任务优先级排序标准和4.2节提出的多DAG处理器选择标准,本节提出以降低调度长度和减少通信开销为目标的,适用于异构网络化汽车电子系统中的多DAG离线公平任务调度算法 MDOFTS(multiple DAG off-line and fairness task scheduling)。
算法1 MDOFTS算法for(DAG个数)
计算每个DAG中任务的向上排序值rankupd(ni,pk),rankupd(ni) 与通信开销权值 cow(ni);
end for
计算出拥有的最大任务数的DAG,并将个数设置为n
for(var i=1∶ n)for(DAG个数)
分别从各DAG中取出一个向上排序值最大的就绪任务,放入到任务的就绪队列 REDAY_QUEUE
end for
for(DAG个数)基于公平轮转调度,从REDAY_QUEUE中选择具有最小通信开销权值cow(ni)的任务ni
获取任务ni所在DAG为Gm
计算 ni在每个处理器上的选择值 select(ni, pk)考虑插入法的基础上将ni分配到选择值select (ni, pk)最小的处理器上更新Gm的通信开销dco(Gm)更新GS通信开销率mdcor(GS)end for end for
MDOFTS 算法的时间复杂度为 O(n2×d×p), 其中n为拥有最多任务数的DAG所包含的任务数,d为DAG个数,p为处理器个数。
证明 调度完所有DAG,遍历任务次数的时间复杂度为O(n),遍历所有DAG的时间复杂度为O(d);计算ni的select (ni,pk)需要遍历它的前驱和各个处理器的时间复杂度为O(n×p)。所以MDOFTS总的算法时间复杂度为O(n2×d×p),证毕。
图2为5种算法的调度Gannt图,表4为相应计算结果。DAG-A和DAG-B的总的通信开销为241和35。从结果可以看出,MDOFTS算法调度长度为 78,其他算法的调度长度都在 81以上,MDOFTS算法优势比较明显;在通信开销率方面,MDOFTS算法仅为0.264 5,而其他算法的通信开销都在0.529 0以上,MDOFTS算法在减少通信开销方面的优势相当明显;公平性方面,尽管MDOFTS算法的不公平性相比 OWN(off-line)和 FDWS (offline)要高一点,但是任务优先级排序结果相比这 2个算法更具有公平性。因此,实例结果显示,MDOFTS算法在没有提高算法时间复杂度的情况下,不仅保证了调度长度更短,而且能够显著减少通信开销,还具有很好的公平性。
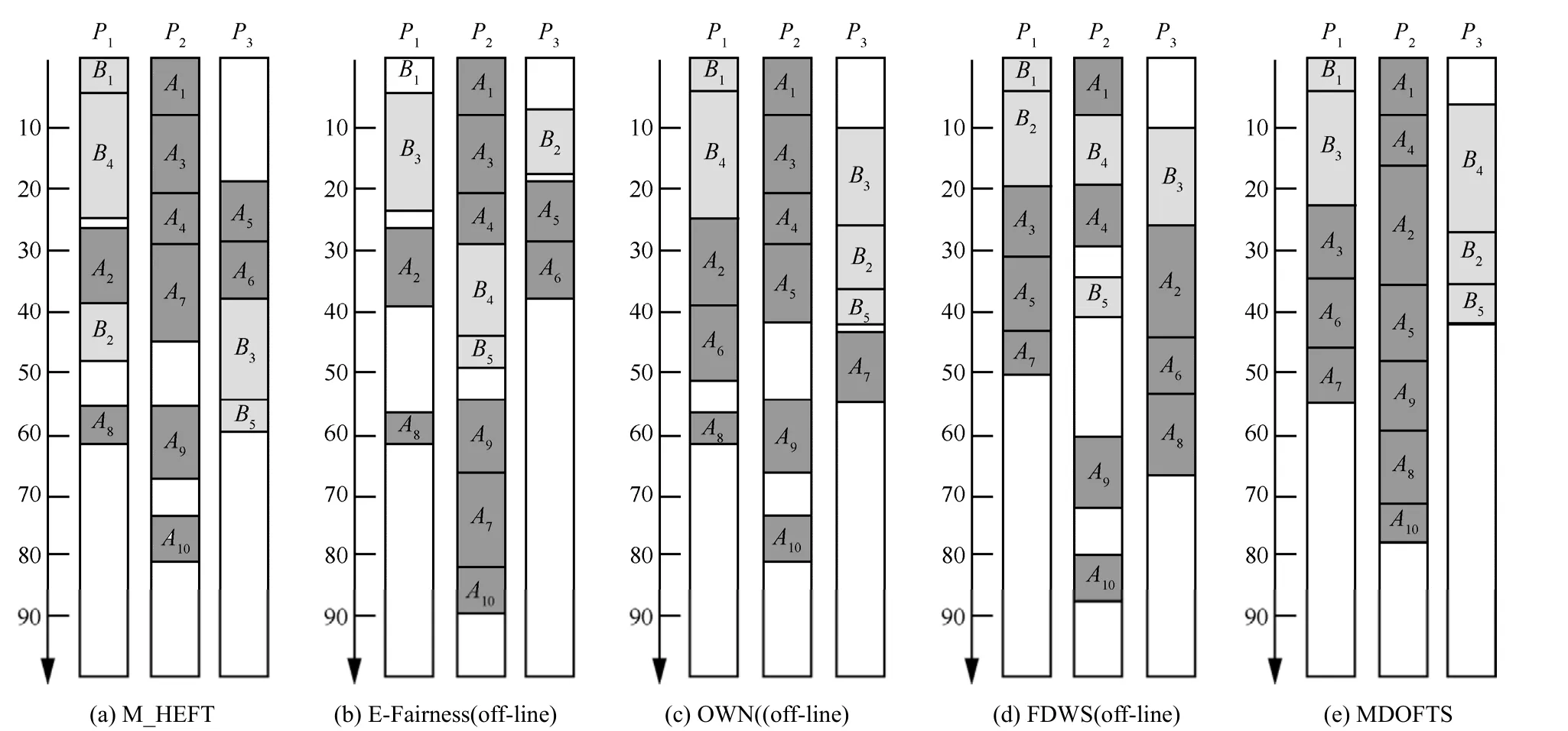
图2 5种算法公平调度DAG-A和DAG-B的Gannt图
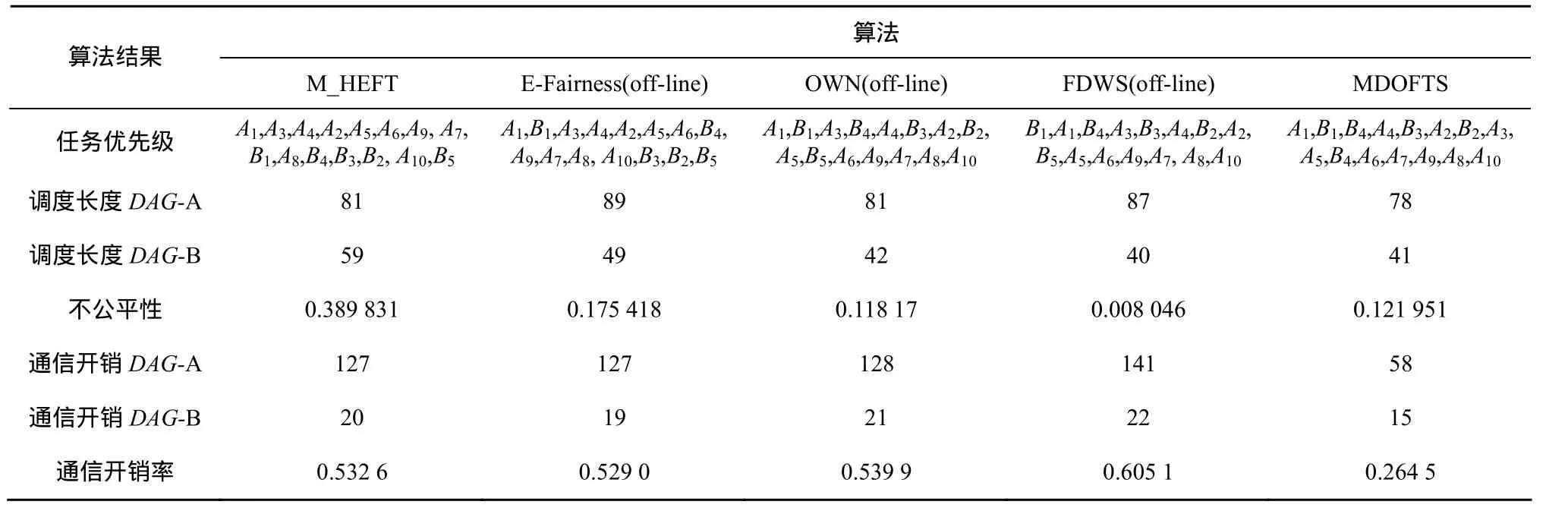
表4 5种算法公平调度DAG结果比较
4.4 优先级调度算法
尽管公平性是需要关注的重点,但是对于混合关键级嵌入式系统,每个子系统都有相应的关键级划分,例如底盘控制等安全关键子系统,有严格的截止期限要求,如果不能在规定的时间内完成, 执行结果也就毫无意义。因此需要优先执行安全关键的DAG应用,这就是DAG之间存在的混合关键优先级。针对上述情况,本节提出多DAG离线优先级任务调度 MDOPTS(multiple DAGs off-line and priority task scheduling)算法,调度策略如下。
1) 对于优先级高的DAG中的所有任务都要优先于优先级低的DAG中的所有任务。只有当优先级高的DAG中的所有任务分配处理器后,优先级低的DAG中的任务才能分配处理器。
2) 优先级低的DAG中的所有任务在考虑插入法的基础上按最小选择值分配处理器。其选择值的计算公式需调整为式(15)。因为低优先级DAG的入口节点nentry的开始时间得到了一定的推迟,其所有后继节点的时间计算都要做相应调整,即
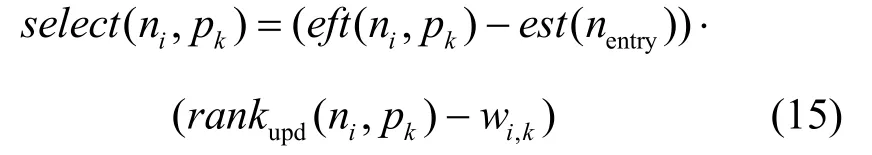
算法2 MDOPTS算法
for(DAG个数) do
计算每个 DAG中任务的向上排序值rankupd(ni,pk), rankupd(ni)与通信开销权值 cow(ni)及任务个数,并将任务放入各DAG的任务队列
end for
对所有DAG按给定的关键优先级降序放入关键级DAG队列
while 有DAG可以调度 do
从关键级DAG队列中取出未调度完成且具有最大优先级的DAG
while当前DAG的任务队列有任务可以调度do选择队列中具有最大rankupd(ni)的就绪节点ni计算 ni在每个处理器上的最早完成时间eft(ni,pk)和select(ni,pk)考虑插入法的基础上将 ni分配到选择值select (ni,pk)最小的处理器上
更新Gm的通信开销dco(Gm)
更新GS通信开销率mdcor(GS)标记ni为已调度任务
end while
标记当前DAG已调度
end while
MDOPTS算法的时间复杂度为O(n2×d×p)
证明 调度完所有DAG,遍历所有DAG的时间复杂度为O(d); 调度就绪队列中的任务,需要遍历一次的时间复杂度为O(n);遍历处理器并计算任务在每个处理器上的最早完成时间,其时间复杂度为O(n×p)。所以MDOPTS总的算法时间复杂度为O(n2×d×p),证毕。
4.5 自适应调度算法
MDOPTS算法虽然能够满足实时性,但却使低优先级的DAG没能及时分配到处理器,从而加大了整个多DAG的调度长度,造成性能明显下降。然而实时系统并不是必须要求优先级高的DAG中的所有任务都要优先于优先级低的DAG中的所有任务,而是只要在截止期限内调度完成优先级高的DAG中的所有任务即可。本节提出多DAG离线任务自适应调度MDOATS (multiple DAG off-line and priority task scheduling) 算法,在确保实时性的前提下,降低整个多DAG的调度长度和减少通信开销。调度策略如下。
1) 通过MDOPTS算法保证某些DAG在截止期限内完成,通过MDOFTS算法降低多DAG的调度长度和减少通信开销。
2) 用MDOFTS预调度多DAG系统,并判断高优先级系统是否满足截止期限,如果满足,则直接用MDOFTS调度;否则,用MDOPTS调度高优先级DAG中的第一个就绪任务。如此重复,直到所有DAG全部调度完毕。即依据截止期限和公平调度结果自适应的采用MDOPTS算法和MDOFTS算法。
算法3 MDOATS调度算法for(DAG个数) do
计算每个DAG中任务的向上排序值rankupd(ni, pk),rankupd(ni)与通信开销权值cow(ni),,并放入各DAG的任务队列
end for
对所有DAG按关键优先级降序并放入DAG队列while 有DAG可以调度 do
从 DAG队列中取出未调度完成且具有最大优先级的DAG为Gx,其截止期限为deadline(Gx)
用MDOFTS算法单调调度Gx,计算出其调度长度为makerspan(Gx)
if makerspan(Gx)≤deadline(Gx)while(Gx中有任务可以调度) do
用MDOFTS算法预调度多DAG系统,并更新Gx的调度长度makerspan(Gx)从Gx中取出向上排序值最大的就绪任务if makerspan(Gx)≤deadline(Gx)用MDOFTS调度算法调度此任务else用MDOPTS调度算法调度此任务end if end while else该多DAG系统不可调度,调度失败end if
end while
MDOATS算法的时间复杂度为O(n3×d2×p)
证明 调度完所有DAG,遍历所有DAG的时间复杂度为O(d);调度就绪队列中的任务,需要遍历一次的时间复杂度为 O(n);用 MDOFTS和MDOPTS调度的算法复杂度都为 O(n2×d×p)。所以MDOATS 总的算法时间复杂度为O(n3×d2×p),证毕。
图 3为 DAG-B截止期限为 40的情况下,MDOFTS、MDOPTS和 MDOATS算法调度的Gannt图,表4为相应计算结果。从结果可以看出,MDOFTS由于采用了公平轮转调度,其多DAG的调度长度最短,但是DAG-B的截止期限要求是40,而 MDOFTS调度的结果为 41,因此不能满足DAG-B的实时性,用此算法调度多DAG将会失败;MDOPTS针对DAG-B的截止期限要求,优先调度DAG-B,尽管满足了DAG-B的实时性,但由于调度公平性差,因而造成多DAG的调度长度过长,使 DAG的运行时间过长,造成性能下降;MDOATS综合考虑MDOFTS算法和MDOPTS算法的特点,采用自适应调度策略,既能降低调度长度,又满足截止期限,因此很适合实时系统应用。尽管MDOATS算法的时间复杂度较高,但对于同时发生的多 DAG调度属于编译时调度,因此并不会影响运行时性能。而且当优先级 DAG数量不多时,MDOATS非常接近于MDOFTS,因为如果采用MDOFTS能满足所有多DAG的实时性,那么MDOATS的调度结果就是MDOFTS的调度结果。
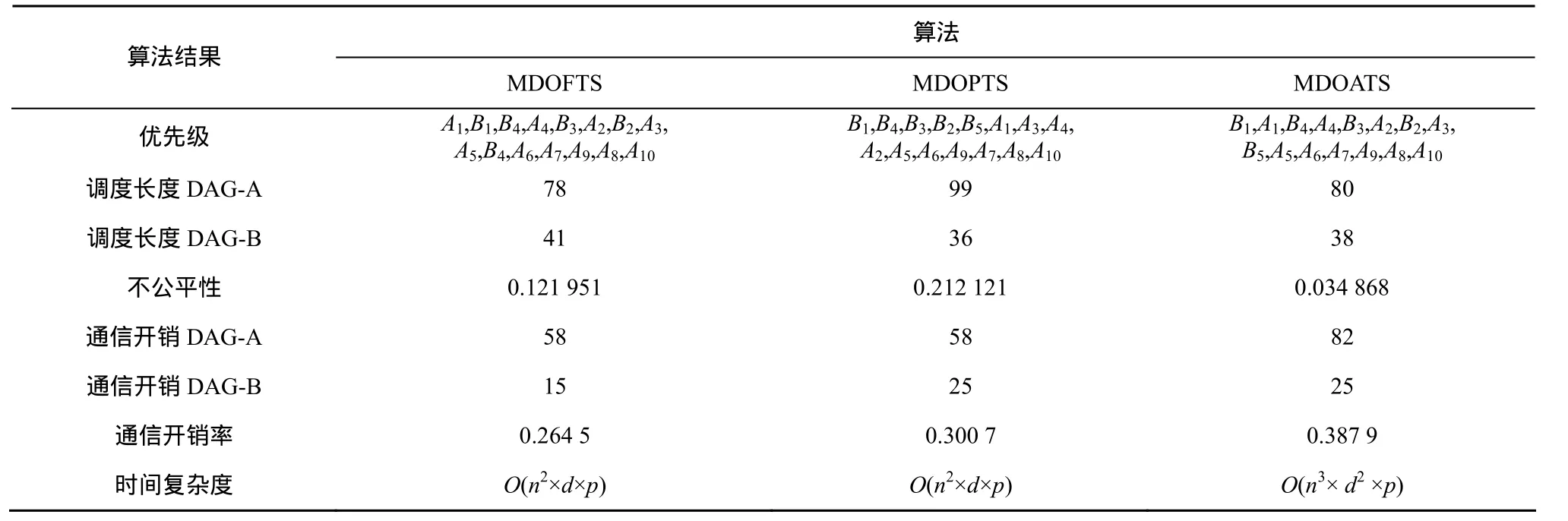
表5 3种算法调度DAG结果比较(deadlineb=40)
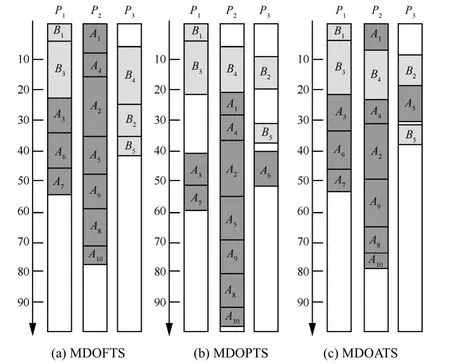
图3 3种算法调度DAG-A和DAG-B的Gannt图(deadlineb=40)
5 实验
5.1 评价指标
本文采用加速比(speedup)[7,11]、通信开销率(MDCOR)、不公平性(unfairness)以及端到端最差响应时间(WCRT, worst-case response time)[19]作为评价指标。
加速比即在一个处理器上串行执行多 DAG中的调度长度最大的DAG的所有任务使用的最少时间与其实际调度长度的比值。调度算法产生的加速比越大,说明算法越高效,加速比计算公式为
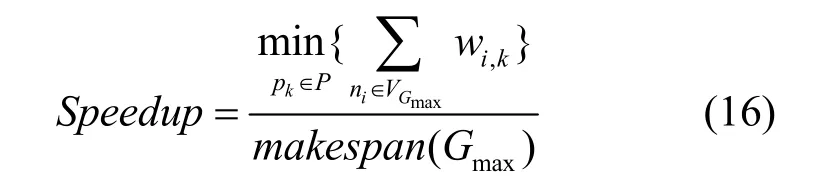
多DAG的通信开销率采用式(14)计算,通信开销率越低,说明算法越高效。不公平性采用式(4)计算,不公平性越低,算法越高效。
在汽车电子系统中,消息集的 WCRT 定义为消息集的第一个消息所分配的 ECU触发就绪到传输完毕到达最后一个消息所在 ECU节点之间的时间段,WCRT越短,算法越高效。
实验的硬件环境为一台具有奔腾双核处理器(3.2 GHz/2.0 GB RAM)的Windows XP机器上,所使用的软件工具有Java和Highcharts,DAG任务图生成工具TGFF 3.5 (task graphs for free)[20]。根据不同参数生成各种特性不同的加权DAG。多DAG系统的DAG个数为 gs={2,4,10,20,40,60,80,100},关键级 sc={1,2,3,4},Gm的截止期限长度统一为makerspan(Gm)的90%。产生随机DAG的参数设置为任务个数n={30,40,50,60,70,80,90,100},最大出度β={1,2,3,4,5},最大入度γ={1, 2, 3, 4, 5},任务在不同处理器上执行时间的差异度 η={0.1, 0.5,1.0}。假设 wi表示任务 ni的平均计算开销,那么ni在处理器 pk上的计算开销可以通过公式产生而得,即
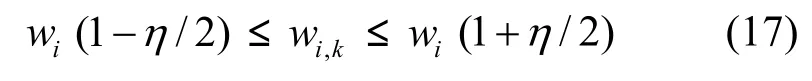
通过生成具有不同特征的大量随机DAG,并在一个由 15个异构多处理器芯片组成的网络计算系统中运行。
5.2 实验结果及分析
实验1 针对多个DAG样本,探究加速比随任务数和 DAG数变化的情况,每个数据点值是由2 000个实验次数得出的平均值。从图4和图5得知:1)随着系统规模增长,加速比都提高;2)MDOFTS的平均Speedup都优于其他算法,分别达20%以上,说明MDOFTS采用的公平轮转策略能够明显地缩短调度长度,而且选择处理器时综合“向上看”和“向下看”的原则,相比其他算法仅“向下看”的原则,优势明显。
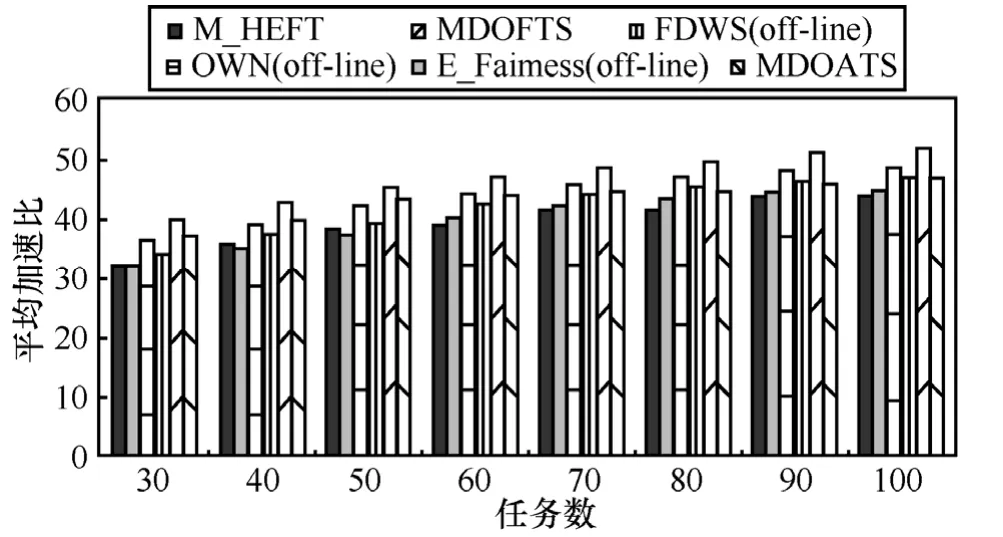
图4 平均加速比随任务数变化
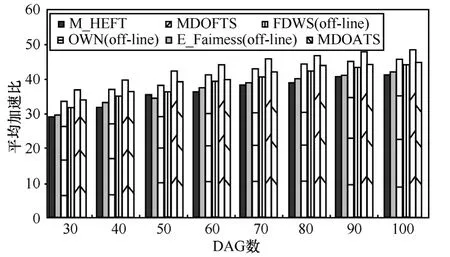
图5 平均加速比随DAG数变化
实验2 针对多个DAG样本,分析通信开销率随任务数和DAG数变化情况,如图6和图7所示:1)通信开销率随任务数和 DAG数而提高,说明随着系统规模和复杂性增长,通信任务大增,造成通信开销加大;2)MDOFTS和MDOATS算法相比其他算法优势比较明显,通信开销率始终保持在12%~44%之间,在最好情况超过了 50%,说明基于通信开销权值的轮转调度策略能够显著减少通信开销,相比其他算法调度目标更加明确,性能更加优越。
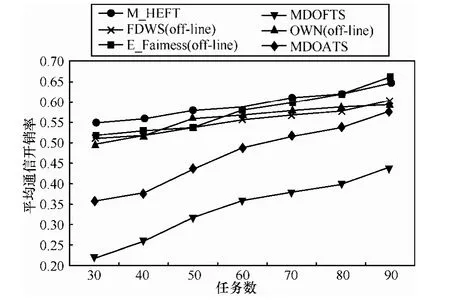
图6 平均通信开销率比随任务数变化

图7 平均通信开销率比随DAG数变化
实验3 分析不公平性随任务数和DAG数变化的情况,实验结果如图8和图9所示。可以看出在任务数或DAG数目较小时,MDOFTS和MDOATS算法优势并不明显;但随着DAG数目的增多,相比其他算法的优势分别达到20%以上,说明随着系统规模和复杂性增大,各DAG包含的任务数和属性不尽相同,使有些公平调度算法对长DAG或短DAG等造成一定的不公平性,而MDOATS的轮转调度策略不仅满足实时性,还具有较好的公平性。
实验4 在真实消息集环境下分析WRCT随消息任务数变化的情况,采用日本名古屋大学高田研究室提供的单个CAN网络的真实消息集[19],该实验集包括65个消息任务,并且被分配到14个ECU之中,由于目前关于汽车电子网络的研究都是基于单个网络的情况,故本文将上述消息集分解为2个CAN网络消息子集,其中,DAG_1为33个,DAG_2为32个。实验结果如图10~图12所示,从结果可以看出,MDOFTS的WRCT算法最短,优于其他算法20%以上。MDOFTS和MDOATS算法的通信开销和不公平性也都优于其他算法。
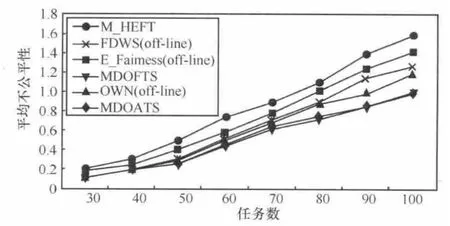
图8 平均不公平性比随任务数变化
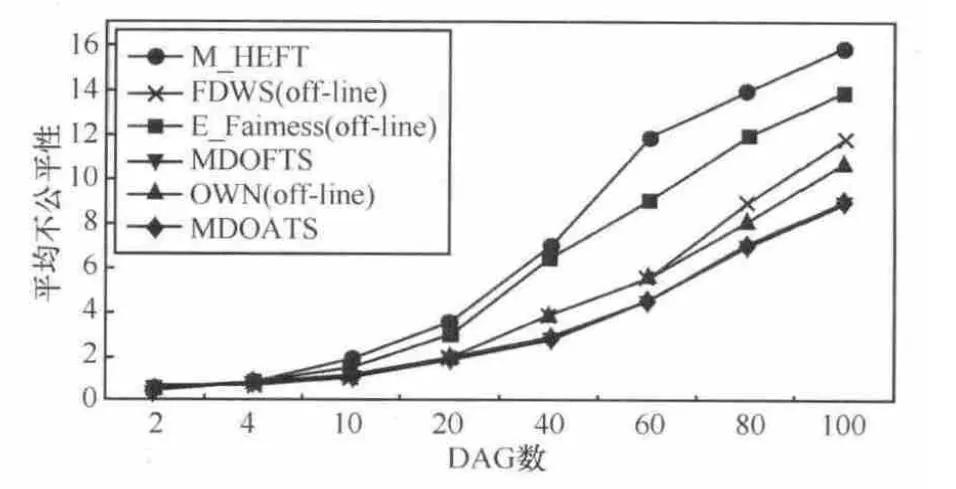
图9 平均不公平性比随DAG数变化
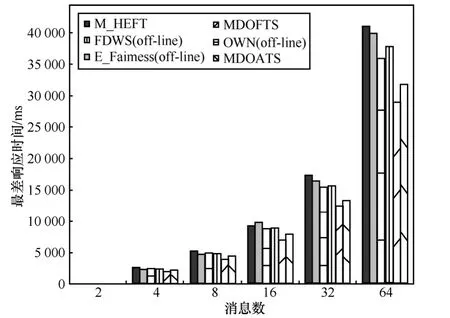
图10 WCRT随消息数变化
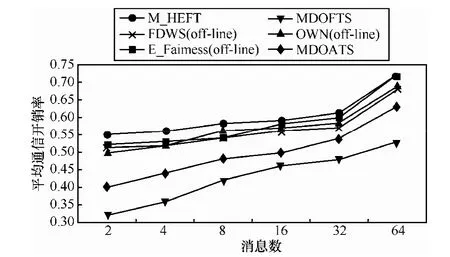
图11 平均通信开销率随消息数变化
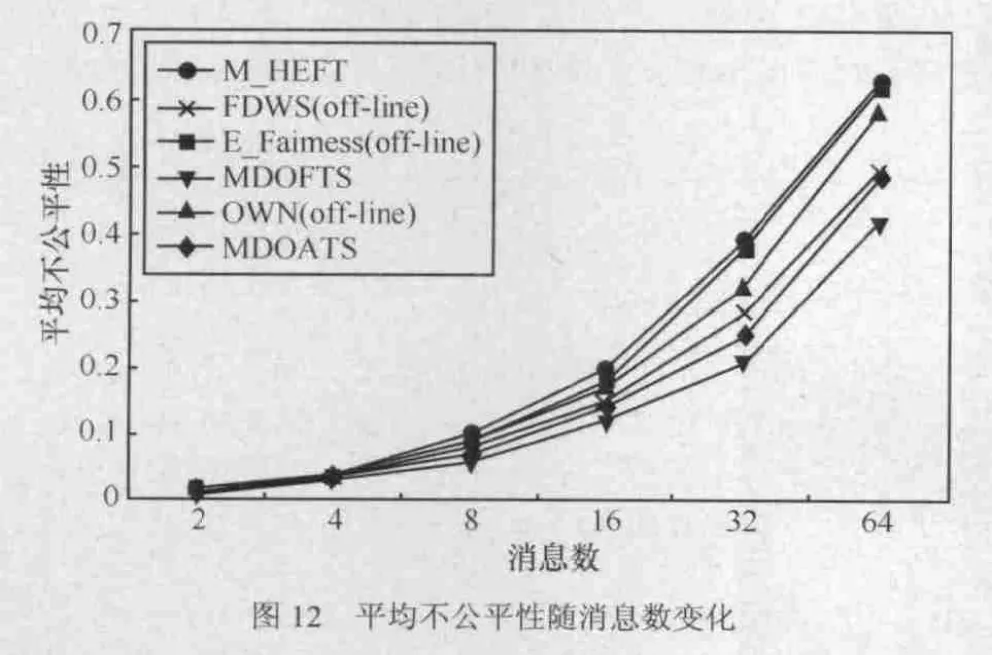
图12 平均不公平性随消息数变化
以上4次实验的结果表明,本文所提出的相关多DAG离线任务调度算法在调度长度、通信开销和不公平性相比E-Fairness(off-line)、OWN(off-line)和 FDWS(off-line)等算法都要优;在真实消息集环境下,具有更好的结果,因而能够很好地适应于异构网络化汽车电子系统的多DAG离线任务调度。了以满足安全关键DAG的多DAG离线优先级任务调度算法MDOPTS,并综合MDOFTS和MDOPTS,提出多DAG离线自适应任务调度算法MDOATS,在满足实时性的基础上提高调度性能。最后利用仿真实验将本文提出的算法与相关算法进行比较,得到本文所提出的算法在保证公平性的条件下,能够有效降低调度长度,极大地减少通信开销,产生更低的最差响应时间,具有更好的调度性能。
[1] BUCKL C, CAMEK A, KAINZ G , et al. The software car∶ building ICT architectures for future electric vehicles[A]. 2012 IEEE International Electric Vehicle Conference(IEVC)[C]. Kuching,Malaysia, 2012.1-8.
[2] FURST S. Challenges in the design of automotive software[A].Proceedings of the Conference on Design, Automation and Test in Europe[C]. Dresden, Germany, 2010. 256-258
[3] KONIK D. Development of the dynamic drive for the new 7series of the BMW group[J]. International Journal of Vehicle Design, 2002,28(1)∶131-149
[4] Audi A8’10 electrical and network systems[EB/OL]. http∶//www.audionlinetraining.com, 2010.
[5] BARUAH S K, BURNS A, DAVIS R I. Response-time analysis for mixed criticality systems[A]. The 32nd IEEE Real-Time Systems Symposium[C]. Vienna, Austria, 2011.34-33.
[6] ALDERISI G, CALTABIANO A, VASTA G, et al. Simulative assessments of IEEE 802.1 Ethernet AVB and time-triggered Ethernet for advanced driver assistance systems and in-car infotainment[A].Vehicular Networking Conference(VNC)[C]. Seoul, Republic of Korea,2012.187-194.
[7] TOPCUOGLU H, HARIRI S, WU M. Performance-effective and low-complexity task scheduling for heterogeneous computing[J]. IEEE Transactions on Parallel and Distributed Systems, 2002, 13(3)∶ 260-274.
[8] 谢勇, 李仁发, 阮华斌等. 最优的 FlexRay 静态段配置算法[J]. 通信学报, 2012, 33(11)∶33-40.XIE Y, LI R F, RUAN H B, et al. Optimal Configuration algorithm for static segment of FlexRay[J]. Journal on Communications, 2012,33(11)∶33-40.
[9] HÖNIG U, SCHIFFMANN W. A meta-algorithm for scheduling multiple DAGs in homogeneous system environments[A]. The 18th International Conference on Parallel and Distributed Computing Systems[C]. Dallas, USA, 2006.147-152.
[10] ZHAO H N, SAKELLARIOU R. Scheduling multiple DAGs onto heterogeneous systems[A]. The 20th International Parallel and Distributed Processing Symposium[C]. Rhodes Island, Greece, 2006.
[11] 田14国.忠, 肖创柏, 徐竹胜等. 异构分布式环境下多 DAG 工作流的
6 结束语
本文面向异构网络化汽车电子系统领域进行调度问题研究,以多DAG离线任务模型为基础,分析了现有多DAG任务调度算法;然后提出基于通信开销权值的轮转调度公平任务排序标准和在考虑插入法的基础上将任务分配到具有最小选择值的处理器上作为处理器选择标准。综合这2个标准提出了面向异构网络化汽车电子系统中的多DAG离线公平任务调度MDOFTS算法;接着提出混合调度策略[J]. 软件学报, 2012, 23(10)∶2720-2734.TIAN G Z, XIAO C B, XU Z S, et al. Hybrid scheduling strategy for multiple DAGs workflow in heterogeneous system[J]. Journal of Software, 2012, 23(10)∶2720 -2734.
[12] HSU C C, HUANG K C, WANG F J. On line scheduling of workflow applications in grid environments[J]. Future Generation Computer Systems, 2011, 27(6)∶860-870.
[13] ARABNEJAD H, BARBOSA J. Fairness resource sharing for dynamic workflow scheduling on Heterogeneous Systems[A]. 2012 IEEE 10th International Symposium on Parallel and Distributed Processing with Applications (ISPA)[C]. Madrid, Spain, 2012.[14] K63L3O-6B3E9D.ANZ K, KOENIG A, MUELLER W. A reconfiguration approach for fault-tolerant flexray networks[A]. Design, Automation& Test in Europe Conference & Exhibition (DATE)[C]. Grenoble,France, 2011.1-6.
[15] KLOBEDANZ K, KOENIG A, MUELLER W, et al.Self-reconfiguration for fault-tolerant flexRay networks[A]. 2011 14th IEEE International Symposium on Distributed Computing Workshops(ISORCW)[C]. Newport Beach, CA, 2011.207-216.
[16] HAGRAS T, JANEČEK J. A high performance, low complexity algorithm for compile-time task scheduling in heterogeneous systems[J]. Parallel Computing, 2005, 31(7)∶653-670.
[17] LI T, BAUMBERGER D, HAHN S. Efficient and scalable multiprocessor fair scheduling using distributed weighted roundrobin[J]. ACM Sigplan Notices, 2009, 44(4)∶65.
[18] MOHANTY R, BEHERA H S, PATWARI K, et al. Priority based dynamic round robin (PBDRR) algorithm with intelligent time slice for soft real time systems[J]. International Journal of Advanced Computer Seience and Applications, 2011, 2(2)∶46-50.
[19] CHEN Y, ZENG G, RYO K, et al. Effects of queueing jitter on worst-case response times of CAN messages with offsets[A]. In Proc of the Embedded System Symposium in Japan[C]. Tokyo, Japan,2012.119-126.
[20] DICK R P, RHODES D L, WOLF W. TGFF∶ task graphs for free[A].Proceedings of the 6th International Workshop on Hardware/Software Codesign[C]. Seattle, USA, 1998.97-101.
