长时共振峰分布特征在声纹鉴定中的应用
2013-10-26曹洪林孔江平
曹洪林,孔江平
(1.北京大学 中文系,北京 100871;2.中国政法大学 证据科学教育部重点实验室,北京 100088)
1 引言
共振峰是声纹鉴定中最重要的特征之一,它能够提供很多发音人的个性特征。目前,对于共振峰的利用,鉴定人员经常从定量和定性两个角度进行分析。定量分析共振峰频率的方法有很多,其中最为经典的还是测量元音(稳定段)共振峰中心频率值的方法。McDougall[1-2]提出了一种定量分析共振峰动态特性的新方法,即对复合元音和响音的共振峰进行多项式拟合,引入判别式对共振峰和拟合系数进行判别分析;李敬阳等[3]利用类似的方法,对汉语普通话复合元音共振峰的动态特性进行了定量分析研究,而在此之前许多有关音节内和音节间共振峰动态特性的研究一直停留在定性比较层面(有时候也会结合测量元音共振峰最低点和最高点的频率值进行分析)。最近,Nolan与Grigoras[4]提出了第三种测量共振峰频率的方法,即长时共振峰分布测量法(Long-Term Formant Distribution,缩写为LTF)。与前两种定量分析方法不同,该方法不是分析具体的目标元音,而是提取一整段语音中的全部元音信息进行分析,得出每条共振峰的整体分布情况,该分布特征不仅可以概括发音人声道的整体共鸣特点,还能反映出发音人一定的发音习惯,可以用于区分不同发音人。该方法已在德国联邦调查局(BKA)的语音分析实验室得到广泛应用[5]。Jessen与 Becker[6]以及 Jessen[7]研究发现,LTF方法有很多优点:分析高效省时、不同鉴定人员之间测量同一语料的一致性较高、LTF数值(如LTF2和LTF3的均值,另见[5])与发音人的身高呈负相关关系以及LTF数值在不同语言之间的差异性较小等。Becker等[8-9]还发现,LTF的均值和带宽参数可以应用到说话人自动识别系统中,并能有效地提高识别率。Moos[10-11]则对71位德语男性发音人的LTF分布进行了测量分析,建立了一个较有价值的参考数据库,同时发现朗读时的LTF数值要比自然说话时的稍高。
上述有关LTF方法的研究主要是针对英语和德语等语言的男性发音人展开的,迄今未见有关汉语的研究。本文将以汉语普通话为对象,介绍并分析LTF方法在声纹鉴定中的应用。
2 实验方法
2.1 发音人
20位男性发音人,年龄在19~36岁之间(均值27.9,方差4.8),20位女性发音人,年龄在21~30岁之间(均值23.2,方差2.4),所有发音人均能说比较标准的普通话,录音时身体健康,无嗓音疾病、感冒等症状。
2.2 语料
录音材料分为两个部分,一部分是普通话的4个单元音[a]、[i]、[u]和[ə],另一部分是长篇语料《北风和太阳》。
2.3 录音
在北京大学语言学专业录音室中,使用SONY ECM-44B领夹式麦克风录音,采样频率为22kHz,精度为16位。在录音过程中,首先让发音人熟悉语料,并朗读一遍,然后再使用正常的语速和音量将语料自然说出,尽量避免使用朗读的方式。发单元音时,要求发音人持续发音3s以上,两部分录音材料均录制两遍。
2.4 测量
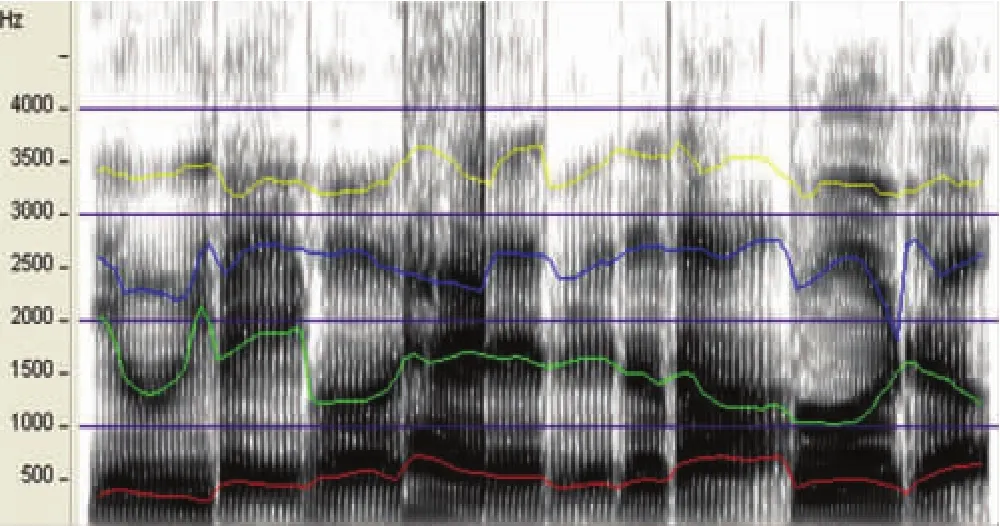
图1 使用WaveSurfer软件提取一段元音的共振峰。其中,自下往上的红线、绿线、蓝线和黄线分别表示F1、F2、F3和F4的数据
使用WaveSurfer[12]软件进行切音、提取共振峰数据,提取过程见图1。具体设置如下:哈明窗,LPC系数:12,共振峰数量:4,截止采样频率:10kHz(其中,部分男声采用8kHz,部分女声采用11kHz)①视在何种设置下能够将大部分元音的F1~F4自动准确地提取出来而定。由于一般情况下女性的声道比男性的声道短,共振峰频率整体偏高,故在此处针对女声的截止采样频率会高一些。。提取单元音的共振峰时,选择中间1~2s的稳定段进行测量,取两次发音的平均值进行分析。针对长篇语料,选择第二次录音进行分析,为了获得清晰准确的共振峰结构,笔者只对语料中共振峰结构明显的元音、边音[l]、语流中间浊化的[x]等浊音进行了分析,而将原始语料中的无声段、呼吸声、清辅音、鼻音以及共振峰结构不明显的元音部分剪切掉,保存为新的wav文件作为分析对象。语料剪切前后的时长信息见表1。当自动提取的共振峰数据不正确时,采用手动调整加以修正。

表1 篇章《北风和太阳》剪切前后时长对比
使用Matlab程序对分析得到的各条共振峰(F1~F4)数据进行统计分析,做出直方图(分箱间隔为25Hz),并用Fourier 6阶拟合函数进行曲线拟合。
3 结果
3.1 不同发音人的LTF分布
5位男性发音人和5位女性发音人的长时共振峰分布情况见图2。图中的蓝色部分是第1至4条共振峰(F1~F4)每个频率段的累积直方图,图中从左至右的黄色、红色、绿色和紫色4条曲线分别是对F1~F4直方图中的频数(达到一定频率范围的次数)进行拟合得到的曲线,该拟合曲线清晰地反映了各条共振峰的整体分布情况。由于语料中存在不同的元音,其共振峰结构不同,拟合曲线之间存在重叠现象。每条共振峰分布曲线的峰值基本上代表了该共振峰分布的众数(即出现次数最多的频率段。例外情况见图2中 M5和 Fe5的 LTF4)。
比较图2中5位男性发音人(M1~M5)的数据,可以发现他们LTF1-LTF4分布曲线的峰值均不相同。比如,M1 的 LTF3 峰值为 2437Hz(众数 2475Hz),M3的LTF3峰值却相对较高为2656Hz(众数 2650Hz);M2的 LTF4峰值为 3517Hz(众数 3525Hz),比 M4的LTF4 峰值(3817Hz,众数 3800Hz)要低 300Hz。 同时,各条曲线的形状也有很大差异,有的出现单峰,有的出现双峰或3个峰。比如,M1的LTF4表现为双峰,而M4的LTF4则为单峰,M1的LTF2有3个强度(对应的纵轴数值,即出现次数)较低的峰,而M4的LTF2则有两个比较强的尖峰。
整体而言,LTF1的分布范围最小,也最为集中,均有比较突出的“尖峰”(leptokurtic)出现;LTF2 的分布则较为分散,少有比较突出的“尖峰”出现,常常表现出比较“扁平”(platykurtic)的特点;LTF3 的分布范围也比较大,但与LTF2不同,LTF3常常出现“尖峰”,强度常略小于LTF1;LTF4与 LTF3的情况比较类似。
不同人LTF分布的峰度(kurtosis)存在较大差异,当某条共振峰的变化范围较大时,其LTF的分布形状就比较扁平,相反,有些人的高次共振峰比较稳定,变化较小,其分布形状多会出现“尖峰”。从图2中10位发音人的LTF分布可知,分布曲线接近对称分布的较少(如Fe2的LTF3),多数都是非对称性分布,其斜度(skewness)参数之间也有较大差异。当LTF的峰值(众数)较大,高频数据出现数量多于低频数据时,曲线往往向高频方向倾斜(如M4的LTF4、Fe5的LTF3),相反,曲线就会偏向低频方向 (如M4的LTF3、Fe4的LTF3)。图2中男性、女性发音人LTF1-LTF4的分布情况类似。不同的是,相比之下,女性发音人LTF1-LTF4的峰值数据和分布范围均有明显的提高。这与女性发音人的声道长度一般比男性发音人的短,女声的共振峰频率更高等特点是相吻合的。

图2 5位男性发音人(M1~M5)和5位女性发音人(Fe1~Fe5)的LTF1-LTF4分布(图中的黄线、红线、绿线和紫线分别表示F1、F2、F3和F4的长时分布情况)

图3 20位男性发音人(1~20)与20位女性发音人(21~40)LTF均值、中位数与众数比较
图3显示的是40位发音人LTF分布数值的均值、中位数和众数(如前文所述,该参数多数情况下与LTF拟合曲线的“峰值”相对应)。由于LTF1-LTF4均非对称性分布,上述3个参数值并不重合,三者越接近,其对应的LTF分布(或其中的一部分)就越接近对称性分布,比较图2中发音人Fe2、Fe3的LTF3分布情况与图3中对应女性发音人(22、23,黑色圆圈内)LTF3的3个参数的重合情况。整体观察可知,图3中LTF的均值和中位数比较接近(重合性较好),而众数与前两者的差异较大(重合性较差),这种差异性的存在正说明了不同发音人LTF分布的独特性。
3.2 同一发音人的LTF分布
图4显示的是两位男性发音人两次说长篇语料的LTF分布情况。很明显,在M13的两次发音中,F3和F4比较稳定,对应LTF3和LTF4均出现单个比较突出的“尖峰”,而M11的LTF3和LTF4的变化范围则更大一些,在曲线形状上也一致表现的比较“扁平”,出现多个不太突出的 “小峰”。两人两次发音LTF1-LTF4的均值、中位数、众数和标准差见表2。由图4和表2可以看出,同一人相同状态下发音的LTF分布变化较小,较为接近。
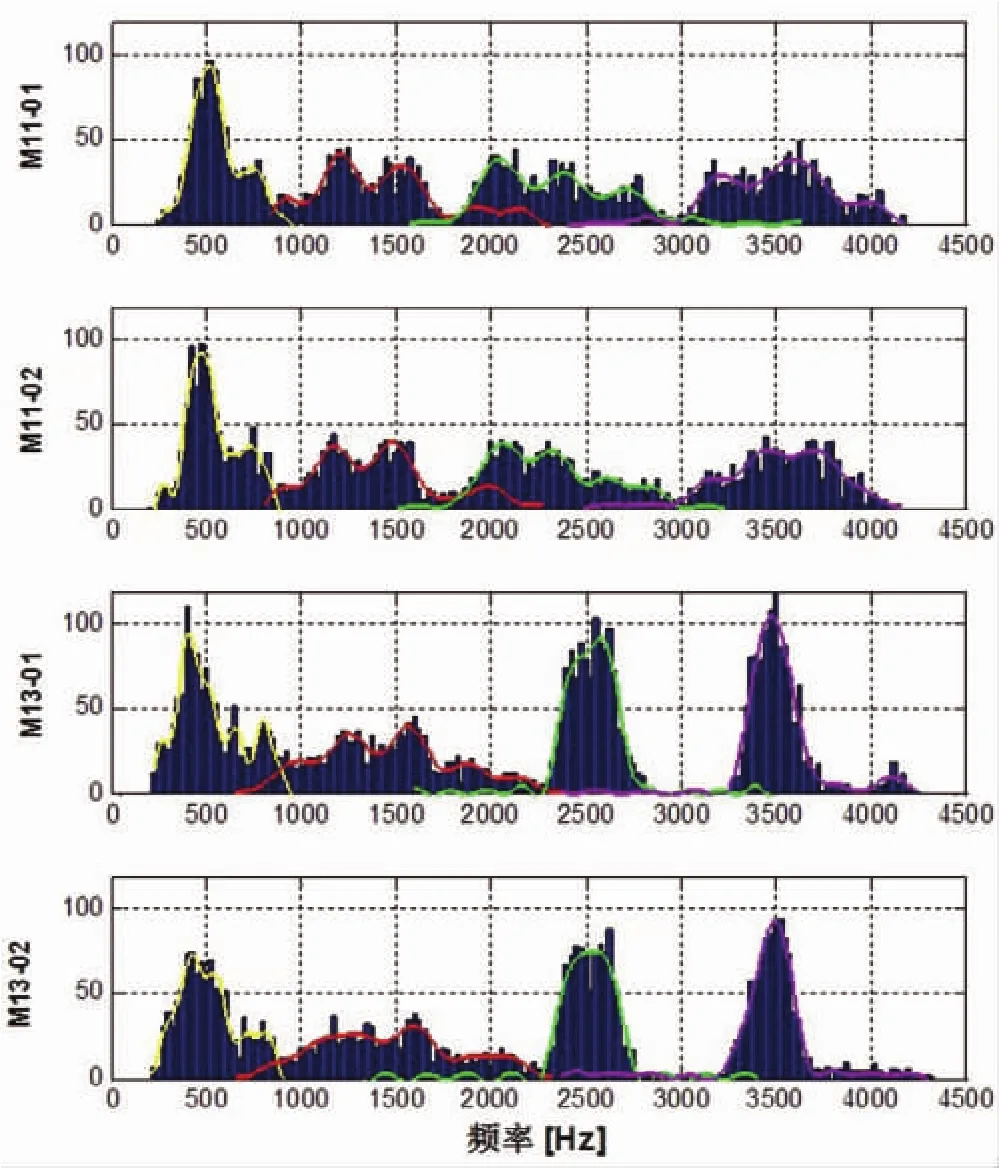
图4 两位男性发音人两次发音的LTF分布情况

表2 两位男性发音人两次发音LTF1-LTF4的均值(m1)、中位数(m2)、众数(m3)和标准差(sd)
4 讨论
4.1 LTF 与央元音[ə]的关系
顾名思义,长时共振峰分布是对一段语料中全部元音的各条共振峰(F1~F4)的所有数值分别进行平均,查看其整体的分布情况。从图3显示的结果来看,发音人LTF1-LTF4相邻共振峰之间的距离比较平均,如20位男性发音人LTF1-LTF4均值参数的平均值分别为 524Hz、1436 Hz、2523 Hz及 3600 Hz, 与成年男性理想状态下简单均匀声管模型的央元音的共振峰结构相似(第n条共振峰的频率为500*(2n-1)Hz,参考[13])。图5比较了20位男性发音人的LTF均值、中位数和众数3个参数的平均值在声学元音图中的位置,可以看出,LTF1-LTF2的均值、中位数和众数均位于元音三角形内部,分布在比较中间的位置,与央元音[ə]比较接近,与[ə]的 F1 和 F2 相比,LTF1 稍低,LTF2稍高。众所周知,不同元音的共振峰结构不同,发元音[i]时,前腔面积小、后腔面积大,[i]的F1最低、F2最高,发元音[a]时,前腔面积大、后腔面积小,[a]的F1与F2最为接近。在连续语流中,如果时长足够长,语料中出现大量的单元音、复元音时(不同元音的出现概率相近),尽管有的元音能够达到其目标值,有的不能,但总体平均后的结果都应该是一个类似央元音的“音”,其前腔、后腔的面积相当,声道形状应该与自然状态下发[ə]时的声道形状类似。

图5 LTF在声学元音图中的位置(基于20位男性发音人的平均数据)
4.2 LTF方法的应用
在声纹鉴定中,任何长时特征的利用,都有几个共同的问题需要加以明确,LTF方法也不例外。第一,要合理利用该特征,最少需要多长的语料?Catalina推荐的时长标准是不少于10s[14],需要注意的是,Catalina提到的时长是原始语料的长度,其中包含了辅音等非元音的成分。Moos研究认为,根据共振峰和说话状态的不同,对于只包含元音的语料,比较合理的时长下限是5~8s左右,作者同时还强调,在不同人之间,该标准会发生变化[10]。尽管本文语料的长度在9~18s左右(见表1),能够满足Moos的标准要求,但鉴于两项研究的语种不同,应该对基于汉语普通话的时长标准做进一步的分析。第二,是否与文本内容有关?本文与Moos研究的朗读语料(德语)均为《北风和太阳》的寓言故事,内容都是固定的(与文本有关)。尽管Nolan与Grigoras在提出LTF方法的时候,曾将案件的样本语音拆分成两部分(将样本K分为两半:K1与K2)进行分析[4],发现原始样本与拆分后的前后两部分的LTF1-LTF4有很好的一致性,但作者并未交代前后两部分的内容是否一致,即使不一致,也只有单个人的数据,若要增加可信度,则需要进行更多发音人的测试。可以设想当一段语料足够长,其中出现各个元音的概率相当时(与文本无关),LTF分布应该会趋于稳定,当然这还需要作进一步的研究。第三,是否与语言/方言有关?LTF分布主要反映了发音人声道的整体共鸣特性,如果语料足够长,同一人说不同语言/方言时,由于其LTF反映的是同一人的整体声道特性,这些被体现出来的声道特性之间的差异性应该不大。当然,不同语言/方言之间音系结构上的差别有可能会成为较大的影响因素。如果LTF在不同语言/方言之间的差异性足够小的话,那么由一种语言/方言得到的LTF数据便可以推广利用到另外一种语言/方言中去,这便为实践中不同语言之间、方言与普通话之间的语音比对提供了新的途径。Jessen与Becker[6]的研究已经发现,LTF在德语、俄语和阿尔巴尼亚语之间的差异性较小。有必要针对汉语普通话与方言及其他语言之间LTF的差异性展开进一步的研究。
在实际办案中大多数案件语料都是电话 (或手机)录音,由于电话信道的带宽限制(300~3400Hz左右),多数情况下只能显示前3条共振峰(在录音质量较差的情况下,有时只能显示两条共振峰)。从图2-图4中也能看出多数F4的数值超过此范围,不能或不能完全显示出来(可以导致F4的提取不准确),因此,实践中可以测量前3条共振峰的长时分布特征 (LTF1-LTF3)。但是对于一些由性能较好的录音设备(如安全机关使用的部分专业监听设备或部分民事案件中当事人使用的录音笔)录制的采样频率较高的语料,可以测量到LTF4。当然该方法也可以用来进行普通语音学的研究,测量的共振峰数量可视研究目的而定。
由于F3、F4高次共振峰的稳定性最强,个体差异性最大,在鉴定中更有价值,因此LTF3与LTF4的数值及分布特征应该能更好地体现发音人之间的个性差异。至于哪条共振峰分布特征的价值更高,则需要进行更深入的研究。当然,在鉴定中比较明智的做法是对LTF1-LTF3/4进行综合分析,而不是只看某条共振峰的分布特征。
如上文所述,使用LTF方法的前提是被研究语料的录音质量较好,能够反映出比较清晰的共振峰结构,在此基础上对各条共振峰的分布进行统计分析,才能够显示出共振峰整体分布的情况。由此得到的LTF分布不仅在峰数和形状(峰度、斜度)上能够较好地体现出发音人的个性特征,而且还能提供各条共振峰整体分布的多维数据,如均值、中位数、众数、标准差等,这些数据为研究发音人的声道特性提供了新的素材。正如Jessen对该方法的评价:“此方法的优点是使用相对高效省时,适用范围广,甚至连鉴定专家自己都不会讲的语言都能够适用(因为该方法无需对元音的音系范畴进行辨别和切分,仅需要具备较好的普通声学语音学的知识即可);缺点是,由于该方法集中了所有的元音信息,与分析单个元音相比,对结果进行解释变得更加困难。对不同的元音进行集中分析,很可能会忽略一些更有价值的个性特征。[7]”的确如此,由于LTF只是一个静态特征,因此在声纹鉴定中不应该单独使用它,而是要结合其他特征进行综合分析,特别是要与单元音的共振峰频率、音节内及音节间共振峰的动态特征结合起来一起使用。
5 结论
本文对20位男性发音人和20位女性发音人的普通话语料进行了研究,通过对其元音部分共振峰频率的统计分析,得出了第1至4条共振峰(F1-F4)的长时分布情况(LTF1-LTF4),发现相比男性发音人而言,女性发音人的LTF数据和分布范围均有明显的提高,这与女性发音人的声道长度较短、共振峰频率较高等特征是相吻合的。利用LTF分布的均值、中位数、众数(相当于峰值)、峰数和形状(峰度和斜度)等参数可以较好地区分不同发音人。
通过比较LTF均值分布与央元音[ə]的共振峰的关系发现,相邻LTF均值分布之间的距离比较平均,LTF1-LTF4均值的整体分布结构与央元音的共振峰结构类似。由此可以推测,在连续语流中,如果语料的时长足够长,其所有元音平均后的结果都应该是一个类似央元音的“音”。
尽管LTF方法可以用来区分个人,但不可否认的是,LTF分布只是一个静态参数,鉴定中不宜单独使用,而应该与其他动态特征结合起来做综合分析。本文仅对LTF分布特征做了概括性的介绍,今后有必要对LTF分布特征与时长、文本内容及语言的关系等问题进行进一步的探讨。
致谢
感谢Michael Jessen对LTF方法在BKA实验室中使用情况的介绍,感谢王英利、李英浩、董理对本文初稿提出的很有价值的修改意见。
[1]McDougall K.Speaker-specific formant dynamics:an experiment on Australian English/ai/[J].International Journal of Speech, Language and the Law, 2004,11(1):103-130.
[2]McDougall K.Dynamic features of speech and the characterization of speakers:towards a new approach using formant frequencies[J].International Journal of Speech,Language and the Law, 2006, 13(1): 89-126.
[3]李敬阳,王莉,崔杰,等.发音人汉语普通话复合元音共振峰动态特征分析[A].第一届全国声像资料检验鉴定技术交流会论文选[C].北京:中国人民公安大学出版社,2011:612-615.
[4]Nolan F,Grigoras C.A case for formant analysis in forensic speaker identification[J].International Journal of Speech,Language and the Law, 2005,12(2):143-173.
[5]Jessen M.The forensic phonetician forensic speaker identification by experts.In: Coulthard M, Johnson A.(eds)[M].The RoutledgeHandbook of Forensic Linguistics, 2010:378-394.
[6]Jessen M,Becker T.Long-term formant distribution as a forensic-phonetic feature[J].The Journal of the Acoustical Society of America, 2010,(128):2378.
[7]Jessen M.法庭语音学[J].曹洪林,王英利.译.证据科学,2010,(6):712-738.
[8]Becker T,Jessen M,Grigoras C.Forensic Speaker Verification Using Formant Features and Gaussian Mixture Models[M].In proceeding of Interspeech, Brisbane, 2008:1505-1508.
[9]Becker T,Jessen M,Grigoras C.Speaker Verification Based on Formants Using Gaussian Mixture Models[C].In proceeding of NAG/DAGA International Conference on Acoustics,Rotterdam,2009.
[10]Moos A.Long-Term Formant Distribution (LTF) based on German spontaneous and read speech[C].In proceeding of IAFPA, Lausanne, 2008:5-6.
[11]Moos A.Forensische Sprechererkennung mit der Messmethode LTF (long-term formant distribution)[D].MA thesis,Universität des Saarlandes.2008.
[12]The WaveSurfer software[CP].http://www.speech.kth.se/wavesurfer/,2007-11-20/2011-12-31.
[13]Ladefoged, P.Elements of Acoustic Phonetics, 2nd ed[M].Chicago: University of Chicago Press, 1996.
[14]Catalina Forensic Audio Toolbox[K].http://www.forensicav.ro/download/CatalinaManual3h.pdf,2007-11-20/2011-12-31.
