DMS动声录音与效果制作技术的研究
2013-09-20靳聪马赛
靳聪,马赛
(中国传媒大学媒介音视频教育部重点实验室,北京100024)
1 引言
为了还原声场的真实状态,使人们听起来就像身处原来的听音环境,放音通道经历了从单声道到双声道到多声道的发展历程:自从1877年,玛斯·爱迪生发明了滚桶式留声机开始,就进入了单声道的录音时代。尽管我们生活的环境中,随时随地都可从上下、左右、前后等各个不同的方向,感受到全方位的声音世界,但由于受技术条件的制约,直到1958年,人们记录和播放声音方式,仍然以单声道为主。最早期的听音方式是单声道,重建的声源被看作一个点声源。这种系统只能让人们感受到非常有限的声场信息,而不能反映声源的二维方向性和空间的位置信息。传统的立体声由时间差(ITD)和强度差(IID)决定声源在空间的定位[1]。在二维平面立体声的重建过程中,通过时间差和强度差使听音者感受到前方一定角度范围内的声像信息[2][3]。随着多媒体技术的发展,多声道系统逐渐发展成为4 声道、5.1、7.1、9.1 环绕声系统[4]。前方声道数的增加极大地改善了听音效果,最佳听音位置也不只局限于“甜点”[5][6]。为满足 UHDTV 系统的需要,日本NHK广播公司研制出了22.2多声道环绕声系统[7]。
中国传媒大学媒介音视频教育部重点实验室研发出基于声场优化原则与惠更斯原理的多声道动声系统,即DMS系统(dynamic matrix sound system)(专利名称:一种动声声场系统。专利号ZL 2009 1 0031119.4)。该系统把有限的声源信号与惠更斯原理中无限的二次波声场相结合,形成了一个M输入与N个输出的声场系统,以有限的声源真实地再现原始声场[8]。
随机选取在校大学生调查显示,大学生中100%听过立体声音乐,其中有约70%的人经常听。传统立体声是目前应用最广泛,影响最深远,普及面最广的听音方式。本文通过主观评价实验方式[9][10],对 DMS 和传统立体声进行对比研究[11],从而得出两者主观感受方面的区别,得出大众对DMS的认可程度以及DMS的最佳应用范围。
目前,对声场效果的研究主要集中于声道转换[12-15]技术和虚拟声场[16-17]技术,然而对不同系统声场的心理测试研究不够全面,更缺乏严格的科学的主观评价。本文完成了DMS多声道与传统立体声的心理感受比较的研究。
2 录音方法及原理概述
本次录音采取主话筒、辅助话筒、环境话筒的近远场结合的DMS录音方法。近场麦克风指的是辅助话筒,主要拾取直达声,加强乐队的定位和音色的修饰;远场麦克风指的是主话筒和环境话筒,主要拾取环境声和反射声,增加空间信息。
主话筒不同于传统录音,而是采用基于波束形成原理的5点麦克风线阵列的拾音方式。主话筒往往有不同方式下的应用,在通常的两声道和环绕声录音场合中主话筒的特征属性是不一样的。原理上,由于主话筒拾取到的是一部分直达声和环境声,因此主话筒应该既有音源本身的声像信息也有空间方向信息。
环境话筒拾取相应的自然反射声和混响声,包括空间印象声像和空间深度声像。在音乐厅内,深度或者距离感的主要信息来自早期和迟后反射声及混响声的延时和电平与直达声的相对关系。直达声给出的方向信息要比现场自然聆听下的方向信息少,但是在声源方向性上能够给出较重要的定位信息,环境话筒拾取的声音包含较少的距离信息,因此,空间深度声像主要与反射声相关而不是与直达声的设计相关。辅助话筒的作用主要是增加对音源的定位和对音色的修饰,拾取的主要是音源的直达声。
在不同的播放环境中,需要加入的混响与效果是不同的。然而在现有的系统与标准中无法实现这种选择与控制。DMS系统采用分部与分轨的录音方法,可以实现音源的高度隔离。DMS专业录音棚的设计要求同声录制的分轨隔离度达到80分贝。中国传媒大学媒介音视频教育部重点实验室装备了我国第一套DMS专业录音室,12个录音通道可以实现同声12声道的录制,声道之间的隔离度可以达到80分贝。这个指标是实现音源综合的关键技术,用有限个音源的合成替代波前综合方法所采用的众多扬声器系统。DMS综合声场可以克服波前综合方法所产生的相位敏感,录音阵列的复杂度与边缘效果等难以克服的问题。
3 录音乐队编制
录音采用多轨分期double的方法,利用小型乐队配置实现大型乐队的效果。弦乐部分基本配置为一提8人、二提6人、中提4人、大提4人、贝斯2人,铜管部分为长号3人、小号3人、圆号4人,木管部分为长笛2人、单簧管2人、双簧管2人、巴松2人,都是通过double的方法实现标准管弦乐团的配置。合唱部分为8男8女,分成4个声部演唱,double 3遍。定音鼓等打击乐用MIDI制做。
4 录音所用设备
话筒:DPA4009
U87
U89
SONY U800
话放:SSL super analogue channel
Studer 169
GML 8302
硬件效果器:GML Model 2030
Millenia TCL-2
Millenia NSEQ-2
Merging dua II
5 录音话筒摆位图
本次录音采用分期分轨的录音方法,按照标准的交响乐团编排,话筒摆位如图1所示。其中主话筒采用5只心形指向性的DPA4009,构成5点麦克风线阵列。距离乐队2米,高度3米。环境话筒采用4只全指向性的U87,构成有左前、右前、左后、右后四个方向的阵列。距离乐队5米,高度5米。
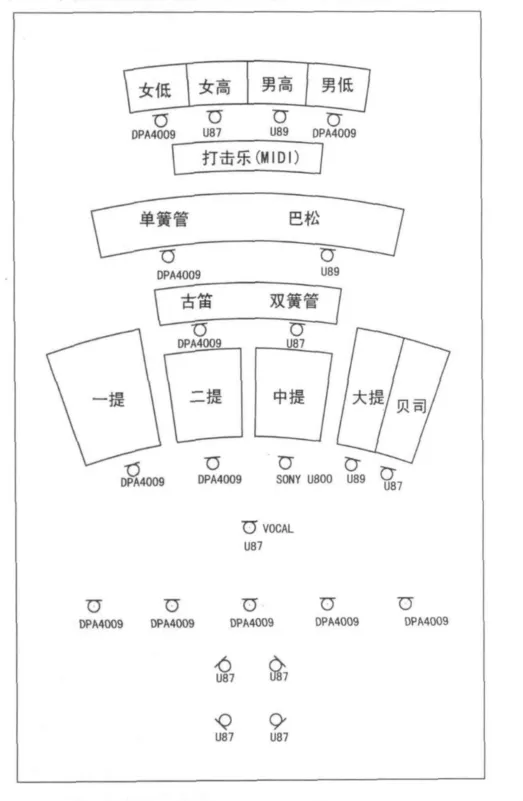
图1 录音棚乐队话筒摆位图
6 后期混音及效果制作
DMS重放系统在分配声道时,根据相关性的定义要求,相关性强的(例如直达声)分配至前方声道,相关性弱的(例如混响声和反射声)分配至后方和侧方声道。
为制作自然而且宽广的声场,本文采用分层式多声道录音阵列。五点线阵列中的话筒提供了不同方向的信号输出。在录音时要确保线阵列准确的定位以做到能重现正确的前方声像,在播放时,正面采集的声场信息主要分配给前方声道,使得音乐有良好的乐器均衡和声音质量。辅助点话筒拾取到的主要是直达声,按照乐队真实的摆位分配至前方声道,从而重现出较好的临场感和真实感,对立体声拾不到的近场声音与效果给以比较好的补偿。环境声场用的话筒阵列具有左、右、左后和右后四个声道输出,并分配至后方和侧方的放音声道,它们给出良好的宽广空间感。这个阵列中话筒的最佳位置应当选择直达声尽量少而又能丰富地拾取到混响声的地方。本次录音是在录音棚中进行的,混响环境不好,因此可以在第三层上补充多声道人工混响,即利用混响效果器通过调整一些参数,弥补环境话筒混响的不足。
在重放时,观众的视点在前方,主要的音乐成分设置于前方;具有空间信息的混响和间接声重现于后方和四周。这个设计充分利用了给定的声道数目重建出了实际录音棚里乐队的真实效果。
在DMS动声系统实验室中共排布有30个扬声器,分为上下两层排列在DMS电影厅实验室中,第一层共有17个扬声器,第二层共有13个扬声器。图2所示为DMS系统平面布局图,图中清晰的显示了30个音箱的摆放位置及声道数目情况。
我们根据以上理论分配声道。首先将辅助话筒拾取到的每个声部根据其在乐队中的位置加以一定量的延时、混响,分配至1-12声道。其中弦乐组离听音者最近,管乐组经过一定延时处理分配至3、4、7、8声道,独唱通过均衡、压缩处理分配至5、6声道。合唱组经延时、混响处理分配至1-8,13-17声道。主话筒5点线阵列分配至18-22声道。环境话筒分配至23-30声道。

图2 DMS系统平面布局图
7 主观评价
7.1 音频信号的选取
(1)DMS系统播放的音频信号
DMS系统播放的音频信号是利用DMS录音方法在录音棚里录制并按照DMS的后期制作方法制作成的30声道的民歌《大中原》,总时长5分32秒。
(2)立体声系统播放的音频信号
立体声的音频信号制作是在制作完的DMS系统的音频信号基础上完成的。将整首曲目分成5小段,每小段都是30个声道的音频文件,将其按照图3的声道间的比例关系计算并分配到立体声的左、右两个声道上,便形成了5段1分钟的立体声系统播放的音频信号。立体声系统播放的音频信号与DMS系统在名称、内容、特点、时长上保持完全一致。

图3 实验室音响布局球形图
7.2 实验环境
本次实验在中国传媒大学综合楼8层的媒介音视频教育部重点实验室的DMS动声系统实验室进行。该系统的平面布局图如图2所示。根据扬声器之间的距离及空间位置,通过角度的计算,得出实验室音响布局球形图,如图3所示:
同时利用DMS动声系统可以实现双声道立体声的播放,即选择低层的3、8两个声道放音,其他28个声道静音。沙发位置是DMS系统和立体声系统的最佳听音位置。
7.3 实验流程
实验的基本思路为对比实验,即随机用DMS系统和立体声系统播放同一段音频信号,由受试者进行打分。实验流程如图4所示:

图4 实验流程图
本次实验共有被试者21人,分别为8名男性,13名女性,年龄在20-30岁之间,听力状况良好。在被试者中共有18人有音乐基础,3人无音乐基础。
由于实验室座位数量的限制,本实验共分为三次进行。第一次实验8人,音频信号的播放顺序为A1(立体声)-A1(DMS)-A2(立体声)-A2(DMS)-A3(立体声声)-A3(DMS)-A4(立体声)-A4(DMS)-A5(立体声)-A5(DMS),用时10分钟。第二次实验6人,音频信号的播放顺序为A1(DMS播放)-A2(立体声播放)-A1(立体声)-A2(DMS)-A3(立体声)-A4(立体声)-A5(DMS)-A4(DMS)-A3(DMS)-A5(立体声),用时10分钟。第三次实验7人,音频的播放顺序为A1(DMS)-A1(立体声)-A2(DMS)-A2(立体声)-A3(DMS)-A3(立体声)-A4(立体声)-A4(DMS)-A5(立体声)-A5(DMS),用时10分钟。用三种不同的顺序播放,可以防止受试者产生主观评价的惯性和刻板印象,能够获得更加准确和科学结果。每段音频信号之间间隔5秒钟,从而对每段音频的播放做了区分,让被试者有充分的时间进行打分,也保证了受试者的合理听音状态。
7.4 评价方法——语义细分法
对音质而言,人的主观感受是多方面的,音质的好坏也可以分为多方面的评价指标[10]。在本次实验中,一共选择了14个音质评价指标,每个评价指标的含义如下所述:
响度:即直达声和混响声的响度,对被试者而言是听到音频声音的大小。
清晰度:声音干净清楚,从中可以辨认出每种声音音色。播放音效时,能辨认是何种声源发声。播放音乐时,能辨认每个乐器的音色,听清每个音符。
明亮度:指中高音的听音感觉,音频中高频成分丰富,重放声明亮,反之昏暗。
低音感:即低音的听音感受,低音是否丰满动听,低音表现的是否好。
丰满度:声音是否丰满动听,高中低音表现是否适度,听感是否温暖、舒适、有弹性。
平衡感:音频信号的各部分比例和谐,各声道的一致性好,音频信号的整体声音效果是否协调。
空间感:受试者被充满声音的空间包围,声像方位基本准确。
宽度:声音在空间的横向表现上是否宽阔,主观感觉声音表现范围宽。
深度:声音在空间的纵向表现上是否有纵深感,主观感觉声音表现范围较深。
临场感:听众听到声音是否有身临其境的感觉。
力度:声音坚实有力,反应声源的动态,反之单薄,干瘪。
真实感:听到的声音是不是和真实声源发声相同。
动感:声音的动态效果是否好。
整体感:对这种声音系统播放声音的整体感觉[11]。
语义细分法是一种多元尺度的分析方法。语义分析法是运用语义区分量表来研究事物的意义的一种方法。它是由美国心理学家奥斯古德和其同事所创立的。该方法以纸笔形式进行,要求被试在若干个七点等级的语义量表上对某一事物或概念(如汽车、邻居)进行评价,以了解该事物或概念在各被评维度上的意义和强度。等级序列的两个端点通常是意义相反的形容词,如诚实与不诚实、强与弱、重要与不重要。本实验采用语义细分法来获得对DMS动声系统和立体声系统的多个评价指标的相对心理尺度。实验选择了14个评价指标,因此共有14对语义对,语义对及分数标准如表1所示,被试者根据表格所示的内容进行打分。例如,为了评价清晰度,有清晰与模糊这对语义相反的语义对,在清晰与模糊之间有7个层次的分数,含义不同。1代表极度清晰,2代表非常清晰,3代表比较清晰,4代表既不清晰也不模糊,清晰度适中,5代表比较模糊,6代表非常模糊,7代表极度模糊[12]。

表1 语义细分法评价指标
7.5 语义细分法的结果
DMS系统的14个评价指标的平均值与立体声的14个评价指标的平均值的对比结果如图5所示:

图5 立体声与DMS对比结果
7.6 实验结果分析
在折线图中,根据DMS与立体声的总体对比结果,可以发现除了响度这一评价指标以外,DMS系统在各项评价指标上都明显优于立体声系统,尤其是空间感、临场感、深度、动感四项指标上差距较大。说明与传统立体声相比,DMS系统确实能够给听众提供一个更加开阔、更具动感、更加真实的听音感受。由于采用了DMS音源综合与声场综合的方法,DMS系统采用的声道数远远小于波前综合法所需要的众多播放声道。
综上所述,通过语义细分法本文验证了DMS动声系统音质水平全面高于传统立体声系统,声音表现力较强,能给听众带来动态主观感受。其次,DMS动声系统更适合于播放内容丰富且具有空间动态特点的音频。DMS可以应用于还原音乐厅的现场演出效果,将多种乐器的演奏逼真再现,使听众仿佛置身交响乐队中间;还可以应用于电影院中,生动呈现人声、音乐、音效,给人身临其境的享受。最后,为了拓展DMS系统的应用范围,让更多的听众享受DMS动声系统,给他们带来更完美的听音感受,未来还要考虑性别、年龄、喜好等因素对于声音系统的影响,展开融合心理学、行为学、艺术学等多种学科的深入研究。
[1]Stevens SS,Newman E B.The localization of actual sources of sound[J].Am J Phychol,1936,48:297-306.
[2]ITU-R BS.775.Multi-Channel Stereophonic Sound System with or without Accompanying Picture[C].International Telecommunications Union,Geneva,Switzerland(1993).
[3]Rumsey F.Spatial Quality Evaluation for Reproduced Sound:Terminology,Meaning,and a Scene-Based Paradigm[J].J Audio Eng Soc,2002,50:651-666.
[4]Christof Faller.Multiple-Loudspeaker Playback of Stereo Signals[J].J Audio Eng Soc 2006,54(11):1051-1064.
[5]Komiyama S.Subjective Evaluation of Angular Displacement between Picture and Sound Directions for HDTV Sound Systems[J].J Audio Eng Soc,1989,37(4):210-214.
[6]Theile G.On the Performance of Two-Channel and Multi-Channel Stereophony[C].presented at the 88th Convention of the Audio Engineering Society[J].JAudio Eng Soc(Abstracts),1990,38.379.
[7]K Hamasaki,K Hiyama,et al.Advanced multichannel audio systems with superior impression of presence and reality[J].AES 116th Convention,Berlin,Germany,Convention paper 6053(2004).
[8]M M Boone,et al.Spatial Sound Reproduction Based on Wave Field Synthsis[J].JA E S,1995,43(12):1003-1011.
[9]孟子厚.音质主观评价的实验心理学方法[M].北京:国防工业出版社,2008.
[10]David M.Howrd,Jamie Angus.音乐声学与心理声学[M].北京:人民邮电出版社,2010.
[11]甘怡群,等.心理与行为科学统计[M].北京:北京大学出版社,2005.
[12]Farina A,et al.Ambiophonic Principles for the Recording and Reproduction of Surround Sound for Music[C].in 19th Convention of the Audio Engineering Society(2001).
[13]K Hamasaki,S Komiyama,et al.5.1 and 22.2 multichannel sound productions using an integrated surround sound panning system[C].NAB BEC Proceedings,2005.
[14]Betlehem T,Abhayapala T.Theory and Design of Sound Field Reproduction in Reverberant Rooms[J].Journal of the Acoustical Society of America,2005,117(1):2100-2111.
[15]Ahrens J,Spors S.Reproduction of a planewave sound field using planar and linear arrays of loudspeakers[J].IEEE Int Symposium on Communications Control and Signal Processing(ISCCSP)(2008).
[16]Pulkki V.Virtual sound source positioning using vector base amplitude panning[J].J AES,1997,45(6).
[17]Davis M F,Fellers M C.Virtual surround presentation of Dolby AC-3 and Pro Logic signal[J].J Audio Eng Soc,1997,45(11):1010.
