基于特征选择技术的集成方法研究*
2013-09-05曹彦,王倩,周驰
曹 彦,王 倩,周 驰
(1.周口师范学院计算机科学与技术学院,河南 周口466001;2.许昌供电公司,河南 许昌461000)
1 引言
随着计算机技术的快速发展以及因特网的广泛普及,近几十年来产生了很多大型的数据库,已遍及生活中的方方面面,如银行存款、超级市场销售、天文学、政府统计、医学以及网络等领域。由于大规模问题和冗余特征的不断出现,使特征选择的研究和分类器技术受到了前所未有的重视。特征选择的任务是从一组数量为D的特征中选择出数量为d(D>d)的一组最优特征。合理而有效地选择有利特征,适当减少特征维数,一方面可以消除冗余,加快运算速度,提高分类效率;另一方面,可以降低分类器的复杂性,从而降低分类错误率。分类器技术是模式识别及机器学习的重要研究领域,目前已有的分类器算法有决策树、神经网络、K-近邻、SVM、Bayes分类等。随着高维数据的不断出现,要找到一个分类较好的单个分类器,一般情况下是比较难的。为此,Suen[1]等人在1990年提出了集成多分类器的概念。
目前,已有多个研究将特征选择应用于构建新的集成学习方法。1998年,Ho[2]研究了随机的特征选择方法。1999年,Opitz[3]提出了基于遗传算法的特征选择的集成学习算法,该算法中使用的集成分类器为神经网络,考虑了个体分类器和已生成的集成算法间的差异度。2002年Oliveira等人运用了多目标的遗传算法。2002年Zhou等人提出了GASEN算法,在神经网络的基础上通过遗传算法为Bagging集成方法选择特征子集。2003年Brylla等人提出了基于随机特征选择的特征bagging方法。2005年Tsymbal[4]等人研究了集成特征选择方法的不同搜索策略,继而又提出运用遗传算法进行集成特征选择。2006年 Li Guo-zheng和 Lin Tian-yu运用嵌入式特征选择方法和滤波式方法对在Bagging基础上产生的个体学习器进行最优特征子集的选择。先后有许多研究者都对集成分类器的多样性进行了研究,如对多样性度量与成员分类器复杂度的关系的研究[5],对分类器集成中的特征选择框架的研究[6]。从总体上来看,这些都是基于样本的集成学习方法。而在实际应用中,特征间的关系很复杂,特征间的相互作用也极为常见,常常难以辨识出特征是否和目标函数相关,寻找一个单一的好的假设函数很困难,这时基于特征选择的集成学习方法是一种很有潜力的方法。
本文在已经经过实验验证具有高准确率RGS(Relief+GA+SVM)算法的基础上,提出组合分类器设计方案。该算法中主要是通过降低成员分类器之间的相关性,来提高集成分类效果的能力,并通过实验表明了该算法的集成思路是优于Boosting方法的。
2 RGS算法
2.1 染色体的构成
本文中应用SVM作为分类器,其中使用的核函数是RBF核函数。支持向量机模型分类精度与惩罚因子C和高斯核函数的γ均存在一定的关系,为了获取最佳分类性能的SVM模型,需要得到最佳的(C,γ),显然这是一个优化问题。本文把参数的选择和特征选择同时进行,即在选择特征的同时找出与其对应的参数最优点。因此,可以利用遗传算法来进行SVM分类模型的参数优化,其染色体表示如图1所示。

Figure 1 Chromosome expression图1 染色体构成
为了与算法适应,还需要把参数C和γ解码为二进制,本文采用以下方式进行解码:
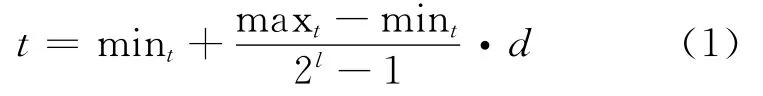
其中,mint表示l位二进制所能表示的最大值,maxt表示l位二进制所能表示的最小值,l是用于表示参数t的二进制位数,d表示l位二进制所对应的十进制值,t为解码后的十进制值。
2.2 遗传算法种群初始化
遗传算法是一种不确定搜索算法,其性能受初始种群影响很大,一个好的初始种群可以为遗传算法提供一批好的搜索起点。因此,本文利用ReliefF算法为遗传算法提供先验信息,使其能搜索到一个好的初始种群。具体步骤为:
(1)不同特征根据ReliefF评估结果进行排序,排序越靠前表示该特征和类别相关性越大。
(2)产生特征的被选概率。本文采用的是常用的轮盘赌方法。
(3)种群初始化。设初始种群大小为g,根据(2)产生g-1个个体;同时,为了充分利用已知信息,初始种群包含ReliefF本身进行特征选择得到的特征。其中,每个个体都表示为二进制串,当此特征被选择,相应位置上的二进制值为1,否则为0。
(4)按照图1构造染色体,创建遗传算法的初始种群。
利用遗传算法进行优化,就要考虑遗传算法中的参数选择问题。对于种群大小,种群数目太小会造成有效等位基因缺乏,生成具有竞争力的高阶模式的可能性极小。但是,种群数目也不可太大,太大将使个体适应性评价的计算量急剧增加,收敛速度显著降低。对于交叉和变异,交叉在遗传操作中起核心作用,交叉概率较大可增强遗传算法开辟新搜索空间的能力,但性能好的基因串遭到破坏的可能性较大,算法收敛速度降低,且不稳定;若交叉概率较小,则遗传算法搜索可能陷入迟钝状态。变异在遗传操作中属于辅助性的搜索操作,其主要目的是维持群体的多样性。较低的变异概率可以防止群体中重要的单一基因丢失,但降低了遗传算法开辟新搜索空间的能力;较高的变异概率将使遗传操作趋于纯粹的随机搜索,降低了算法的收敛速度和稳定性。
2.3 适应度函数

其中,参数α、β用来控制特征数目的减少和分类准确率的提高对评估函数的贡献,|X|表示特征子集X所包含的特征数目,n为所有特征的数目。等式右侧第一项表示特征子集对应的分类准确率越大,则评估函数取值越大;第二项表示特征数目越少,评估函数取值越大。用户可以根据不同问题和需要设置参数α和β的值,如当希望分类准确率高些时,则增加α的值,否则减少α的值;如果希望降维幅度大些时,则增加β的值,否则减少β的值。
本文所采用的分类准确率的计算方法为:分类准确率=真正率*真负率;真正率和真负率是根据混淆矩阵[7]来计算的。
个体的评估函数也是影响遗传算法性能的一个重要因素,对于特征选择算法,适应度函数应满足:分类准确率越高,适应度函数值越大;特征子集越小,适应度函数值越大。因此,适应度函数定义为:
2.4 RGS算法
RGS算法[8]的主要过程如下:
(1)首先对训练集的属性进行规范化。把大范围上的数据通过变化转换为小范围上的数据。本算法是通过式(3)把数据规范化到0~1。由于数据集的复杂度的降低,在一定程度上间接地增加了支持向量机的分类准确率。
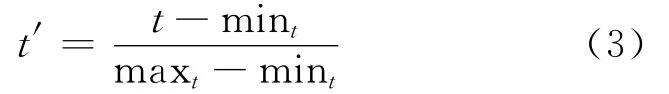
其中,t为原始的属性值,t′为规范化后的属性值,mint表示t的最小值,maxt表示t的最大值。
(2)通过ReliefF对特征进行排序。
(3)种群初始化。把支持向量机参数混编入染色体中,通过遗传算法实现特征子集和支持向量机参数的同步优化。
(4)解码支持向量机参数。把遗传后的二进制形式的支持向量机参数解码为十进制。
(5)计算假设的适应度值。对于每一个假设,根据解码后的支持向量机参数和选出的特征子集,计算该假设的适应度值。
(6)判断是否满足终止条件。如果满足,对该假设操作结束,更新种群;如果不满足,利用选择、交叉、变异对该假设进行遗传。
(7)选择适应度值最高的假设。
3 RGSE算法
在RGS算法中,每次的分类结果都只选择了具有最高适应度值的特征子集,而忽略了其他的个体,也许其余的特征选择方案中也包括了有用的信息,是否可以利用这些特征选择方案设计出更好的分类器呢?
3.1 不一致度量方法
经研究表明[9],对于训练获得的多个基分类器,并不是把它们全部进行集成操作得出的集成分类器效果最佳,而是应当根据成员分类器的差异度进行选择。成员分类器的多样性是一个重要的选择准则,这个准则是保证泛化能力的最佳选择。Kuncheava等人将多样性度量标准分为“成对度量标准”和“非成对度量标准”两类。成对度量标准用于衡量集成系统中任意两个分类器之间的分类差异,非成对度量标准从整体上计算群体的多样性。常用的成对多样性测量方法有Q统计量、不一致度量方法、Kappa度量法、相关系数法和双误度量。常用的非成对度量方法主要有熵度量、KW方差度量和K统计量度量。本文主要使用不一致度量方法,仅对该方法进行介绍。
在介绍具体的不一致度量方法之前,用简化的二分类问题为例引入需要用到的一些参数。给定大小为N的训练样本,训练出M个成员分类器,yij表示第i个输入样本在第j个分类器上的输出。当yij的值为0时,表示第j个分类器分类错误;当yij的值为1时,表示第j个分类器分类正确。对于两个分类器 Mi、Mj,Nab(a,b∈ {0,1})表示分类器Mi的输出结果为a、分类器Mj的输出结果为b的输入样本的数量。m(xi)表示分类器在输入样本xi上正确分类的样本个数,用公式表示为:
不一致度量方法是通过把分类器Mi、Mj输出结果不一致的样本与所有样本的比,作为这两个分类器的多样性度量标准。

Si,j的取值范围是0~1,当Si,j的值为0时,说明分类器Mi、Mj的预测结果相同,即同时分类正确或错误;当Si,j的值为1时,则说明分类器 Mi、Mj的预测结果不同。
集成的不一致度量方法也是成员分类器间的平均值,即:

3.2 算法设计思路
分类器集成一般包括两个过程:(1)基分类器的设计;(2)基分类器分类结果的融合算法。为了获得较好的集成学习算法,第(1)步中要尽量获得高准确率的分类器,第(2)步中要选择合适的集成方法。要想获得较高的分类准确率:(1)使特征子集和目标函数尽量相关;(2)设计出好的分类算法或者选择出使分类效果最好的分类器参数。这个已在提出的RGS算法中得到了体现。在实际应用中单个的支持向量机在进行分类时,往往因为找不到最优的支持向量机参数而降低了分类效果。同时,单个的支持向量机在处理无类标号的样本时,也不能获得较好的效果。为了克服单个分类器的这些缺点,可以通过对SVM分类器集成来提高处理数据的分类准确率。在集成方法中,各成员分类器的相关性越小,集成分类器的误差就越小。因此,实现成员分类器的多样性成为提高分类器组合泛化能力的主要手段,同时也是本文工作的重点。
3.3 算法设计
首先利用RGS算法训练基分类器,选择M个成员分类器进行集成。为了能够处理高维数据,当M(1+60%)大于总假设个数t时,从最终的种群中选择适应度值最高的M(1+60%)个个体建立成员分类器;否则,利用种群中所有的假设建立t个成员分类器。然后从t或者M(1+60%)个成员分类器中选择用于集成的M个基分类器。选择时利用给出的不一致度量方法对基分类器进行测量,选择出差异性较大的分类器集。这样,就可以保证用于集成的分类器的相关性较低,提高了集成分类器的泛化能力。具体算法描述如下(其中,M表示集成的成员分类器个数;t表示种群P中的特征子集个数(t≥M))。
步骤1 训练SVM成员分类器。
(1)在训练样本上利用RGS算法得到遗传后的种群P。
(2)在种群P中生成SVM分类器。
If(M(1+60%)<t)
{
根据适应度值从高到低的原则选择出M(1+60%)
个假设并用其训练SVM分类器;
}
Else{
选择t个假设训练出t个SVM分类器;
}
(3)用每个分类器测试检验样本集,根据测试结果,计算出每个SVM分类器的分类准确率。
步骤2 选择出最大差异度的分类器集
(1)If(M(1+60%)<t){
For(i=1,2,…,M(1+60%)-1){
For(j=i+1,…,M(1+60%))
计算出分类器Mi和Mj间的差异度Si,j;
}
}
Else{
For(i=1,2,…,t-1){
For(j=i+1,…,t)
计算出分类器Mi和Mj间的差异度Si,j;
}
}
(2)从所有的分类器中任意选出M个SVM成员分类器,利用平均值的方法求出这个新的分类器集的差异度。
(3)比较所有的分类器集的差异度,最终选择差异度最大的分类器集。
该算法主要分为两个步骤,第一步中是以RGS算法为核心,RGS算法的最坏时间复杂度为O(dl3),其中:d为特征维数,l为样本数;第二步的主要工作是选择最大差异度的分类器,最坏时间复杂度为O(t2)。因此,RGSE算法的时间复杂度为O(dl3+t2)。
4 实验与结果分析
4.1 实验描述
(1)实 验 环 境:PC 机 PentiumD 主 频 2.8 GHz,内存为512MB,操作系统为 WindowsXP,实现工具为Eclipse,开发语言为Java,数据挖掘工具为WEKA。
(2)实验数据:选择的实验数据如表1所示,这些数据集的特征维数10~100,属性值有连续型的也有离散型的,样本数目从几百到几万,这些数据集中有的数据集没有数据缺失,但有的有大量缺失,所选数据的多样性使这些数据具有广泛的代表性,可以较好地验证所提算法的性能。
(3)参数设置:ReliefF算法中,对于样本数大于1 000的训练数据集,迭代次数M为训练集的三分之一;否则,M 取值为训练集的大小,最近邻样本数K=2。本文中遗传算法的参数根据经验值[10]设定为:种群大小80,交叉概率0.7,变异概率0.02,x=y=20,z的大小根据特征的个数来定。终止条件为遗传迭代次数超过100次或者在最近10次迭代中,适应度函数变化不大。因为Hansen实验表明集成学习的性能在最初几个个体分类器集成时改善最明显,所以集成的个数不易设置过大,本文中个体分类器的个数M设定为50。

Table 1 Experiment data表1 实验数据
4.2 实验结果分析
为了验证RGSE算法,将此算法和Boosting算法相比较,其中,Boosting中所使用的分类方法为支持向量机,支持向量机中使用的核函数为径向基核函数,参数C和核函数参数γ是通过无穷搜索得到的。在将此算法和集成算法相比较的同时,还与RGS算法和SVM算法相比较。经计算,在表1给出的数据集上的分类结果如表2所示。

Table 2 Comparison of ensemble algorithms classification precision ratio表2 集成算法分类准确率比较
特征子集的大小如表3(RGSE特征子集的大小为单个分类器选取特征子集大小的均值)所示。
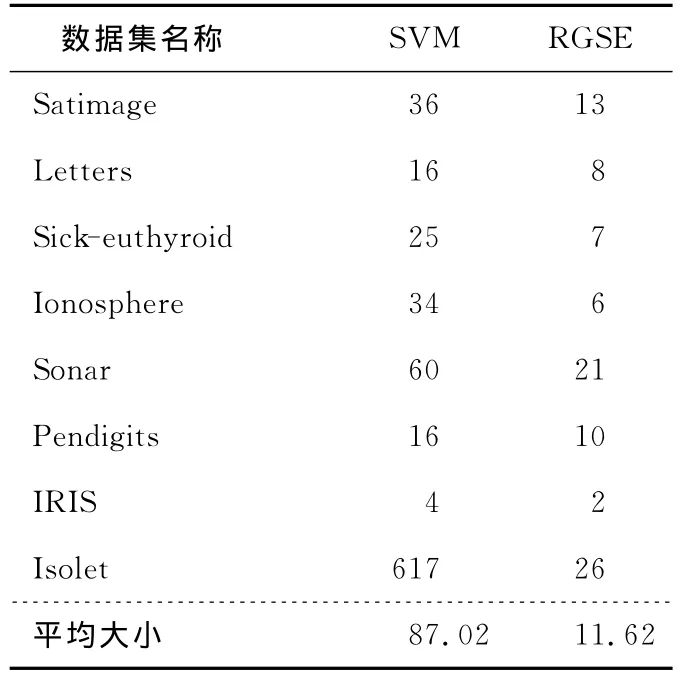
Table 3 Feature subset size of ensemble algorithms表3 集成算法的特征子集大小
从表2可以看出,总体来说,虽然RGSE算法不能够保证在所有的数据集上都能获得最高的分类准确率,但是总的平均准确率RGSE算法是最高的。RGSE算法在 Letters、Sick-euthyroid、Sonar、IRIS数据集上的分类准确率最高,和SVM比较,在以上三个数据集中,在Sick-euthyroid上的错误率降低最多为26.94%,在IRIS上的错误率降低最少为3.45%。RGSE算法比SVM算法的平均错误率降低了8.81%。RGSE算法和RGS算法相比较,可以看出RGS算法在数据集Ionosphere上的分类准确率最高,比RGSE算法的高出2.19%。但是,平均准确率RGSE却高出1.53%。RGSE算法和Boosting算法相比较,虽然某些数据集可能在Boosting上获得了高的准确率,从表3可以得出,RGS算法中所选择的特征子集相对于原数据集的特征集减小了很多,这就降低了数据集的复杂度,有利于提高分类算法性能。综上所述可以得出,不管RGSE算法和以上的哪种算法相比较,在总体上总是能在特征子集相对较小的情况下获得较高的平均准确率。这就说明,通过集成和成员分类器的多样性选择,大部分情况下能够提高分类效果。
5 结束语
随着大数据集和高维数据集的不断出现,很难找到一个最优的单分类器,因此,多分类融合技术应运而生,成为了一种新的数据处理技术。本文针对具有较高分类准确率的RGS算法,运用集成学习思想,提出了一种RGSE集成分类算法,即在RGS算法生成的多个成员分类中,采用不一致度量方法,从中选择出差异性最大的分类器集。该集成分类算法的实验结果也表明了该算法的有效性。
[1] Suen c Y,Nadal C,Mai T A,et al.Recognition of totally unconstrained handwriting numerals based on the concept of multiple experts[C]∥Proc of International Workshop on Frontiers in Handwriting Recognition,1990:131-143.
[2] Ho T.The random subspace method for construction decision forests[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20 (8):832-844.
[3] Optiz D.Feature selection for ensembles[C]∥Proc of International Conference on Artificial Intelligence,1999:379-384.
[4] Tsymbal M C.Search strategies for ensemble feature selection in medical diagnostics[C]∥Proc of the 16th IEEE Symposium,2003:124-129.
[5] Windeatt T.Diversity measures for multiple classifier system analysis and design[J].Information Fusion,2005,6(1):21-36.
[6] Tsymbal A,Pechenizkiy M,Cunningham P.Diversity in search strategies for ensemble feature selection[J].Information Fusion,2005,6(1):83-98.
[7] Fan M,Meng X F.The concept and technology of data mining[M].Beijing:Machine Industry Press,2007.(in Chinese)
[8] Wang S Q,Cao Y.GA-SVM-based feature subset selection algorithm[J].Computer Engineering and Design,2010,31(18):4088-4092.(in Chinese)
[9] Caruana R,Munson A.Getting the most out of ensemble selection [C]∥Proc of the 6th International Conference on Data Mining,2006:828-833.
[10] Li M Q,Kou J S.The basic theory and application of genetic algorithm[M].Beijing:Science Press,2003.(in Chinese)
附中文参考文献:
[7] 范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出版社,2007.
[8] 王世卿,曹彦.基于遗传算法和支持向量机的特征选择研究[J].计算机工程与设计,2010,31(18):4088-4092.
[10] 李敏强,寇纪淞.遗传算法的基本理论与应用[M].北京:科学出版社,2003.
