一种基于混合策略的推荐系统托攻击检测方法*
2013-09-05吕成戍王维国
吕成戍,王维国
(1.东北财经大学管理科学与工程学院,辽宁 大连116025;2.东北财经大学数学与数量经济学院,辽宁 大连116025)
1 引言
最近的研究表明,由于推荐系统的开放性以及用户的参与性协同过滤算法很容易遭到人为攻击[1]。攻击者通过向推荐系统注入虚假用户概貌,使其推荐结果符合自己的商业利益。这种攻击被称为“托攻击(Shilling Attacks)”或“用户概貌注入攻击”[2,3]。托攻击检测技术近年来引起了学术界的广泛关注,并已成为当前推荐系统领域的研究热点之一。
支 持 向 量 机 SVM (Support Vector Machines)[4]的成功促使其被应用到推荐系统托攻击检测中[5],使用支持向量机方法进行托攻击检测的效果虽然优于决策树、神经网络等传统机器学习方法,但是在托攻击检测中面临数据不均衡和代价敏感两个难题,直接应用支持向量机方法效果仍然不够理想。一方面由于攻击强度不宜过大,否则易于被检测[6],因此训练集中攻击用户样本的数量往往远小于正常用户样本的数量,即样本集呈现不均衡分布特性,这会直接影响支持向量机的泛化能力;另一方面,由于推荐系统中用户基数很大,推荐过程中错误地屏蔽一些正常用户并不会对推荐结果产生显著影响,但误判一些攻击用户就有可能会改变推荐结果[7],因此攻击用户和正常用户的误分类代价是不同的,以分类正确率作为方法的评价依据不适合处理代价敏感问题。目前,SVM在模式分类研究中已经部分解决这两方面问题。其中,有基于数据重采样的方法[8,9],对数据进行预处理,降低不均衡程度;也有基于代价敏感学习的方法[10,11],通过在支持向量机方法中集成不同误分类代价,使之适应代价敏感分类问题。但是,大多数研究仍集中于单纯的数据集重采样或者代价敏感学习,而忽略了实际模式分类问题,如推荐系统托攻击检测,需要同时考虑不同类别样本在数量上的差异和误分类代价不同这一事实。
本文将数据重采样和代价敏感学习两种不同类型的解决方案有机地融合在一起,提出了一种新的推荐系统托攻击检测方法。该方法首先用所提出的基于样本重要性的欠采样技术进行样本空间重构,平衡正常用户和攻击用户的比例,减弱不均衡数据集对支持向量机分类性能的影响。然后,对待识别的攻击用户赋以较大的代价,正常用户则赋以较小的代价,利用代价敏感学习算法CS-SVM(Cost Sensitive SVM)进行分类,从而解决样本误分类代价不同的问题。将实现的软件应用于推荐系统托攻击检测,实验结果表明了其有效性。
2 理论基础
2.1 单边采样技术
Kubat和 Matwin[12]提 出 的 单 边 采样技术OSS(One-Sided Selection)是一种具有代表性的欠采样方法,其工作原理如下:设xi表示一个多数类样本,xj表示一个少数类样本,d(xi,xj)表示xi和xj之间的距离,判断是否存在样本点z,使d(xi,z)<d(xi,xj)或d(xj,z)<d(xi,xj)成立,如果不存在z,则 (xi,xj)是边界点或者噪声点,将多类样本xi从样本集中删除。
2.2 代价敏感支持向量机
集成不同误分类代价的代价敏感支持向量机本质上是传统支持向量机的代价敏感形式的扩展。对两类问题,结合不同误分类代价,有训练样本集:
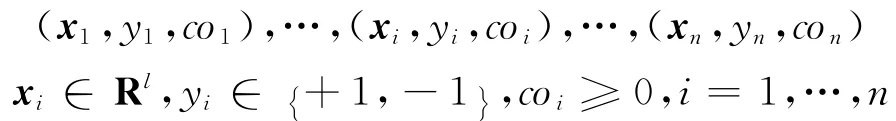
最小化目标函数:
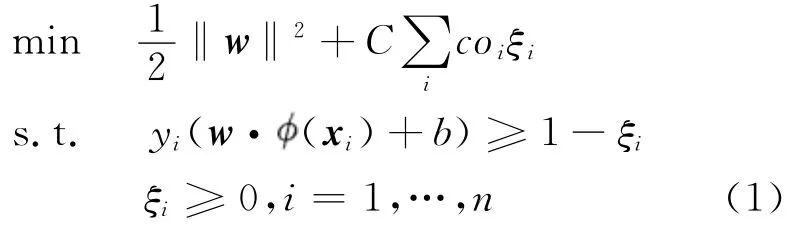
其相应的对偶形式:
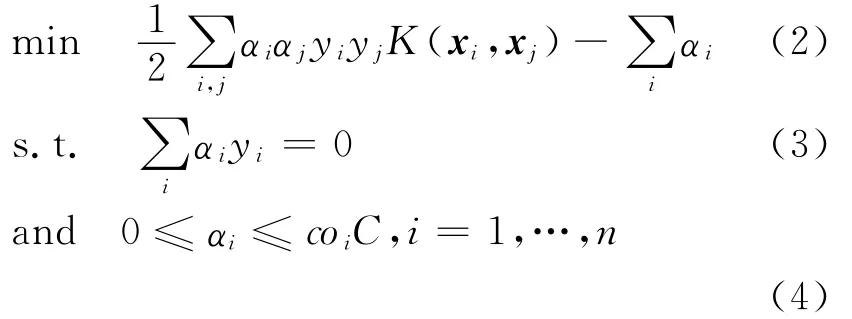
相应的决策函数为:
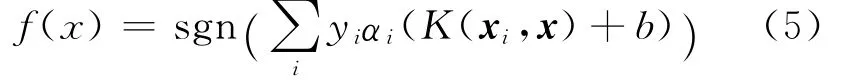
3 混合托攻击检测方法
3.1 均衡训练样本集
重采样是解决样本失衡的一个有效方法。重采样实现的途径有两种:增加少数类样本数的过采样技术和减少多数类样本数的欠采样技术。由于过采样技术会造成训练集规模的增大,加大计算复杂度,因此在某些需要进行快速分类和决策的场合,例如推荐系统托攻击检测,更适合使用减少多类样本的欠采样技术。单边采样技术被证明可以有效缓解数据集的不均衡程度,但是该方法简单地将边界点完全删除,会造成分类信息的严重丢失,对分类器的性能造成不良影响。
本文针对单边采样技术中存在的边界样本处理过于简单的问题,提出了一种基于样本重要性的欠采样技术SIUT(Sample Importance based Undersampling Technique)。SIUT首先使用单边采样方法定位多数类边界点和噪声点。然后,利用K近邻法分离噪声点和边界点。对于噪声点直接排除于样本集之外,对于剩下的样本,也就是边界样本,使用式(6)计算每一个样本的重要性。

其中,TPR(True Positive Rate)是攻击用户的检测率,检测率=正确检测的攻击用户数量/总的攻击用户数量;FPR(False Positive Rate)是正常用户的误检率,误检率=被错误判断为攻击用户的正常用户数量/总的正常用户数量。在推荐系统托攻击检测的实际应用中,我们希望在检测率处于最高的前提下,尽可能地降低误检率。因此,I(xi)值的大小可以表明此样本对分类支持的重要性。相应地,I(xi)值越大表明此样本的重要性越大;反之,I(xi)值越小表明此样本的重要性也越小。迭代删除I(xi)值最小的多数类样本,就可以消除对分类决策面“不重要”的多数类样本,控制两类数据使用比例的同时又能保留绝大多数对分类超平面有用的“重要”样本。利用SIUT算法实现训练样本均衡的具体过程如算法1所示。
算法1 SIUT算法
输入:原始不均衡训练样本集T;
输出:均衡训练样本集T′。
(1)将数据集T分解为两个子集:多数类样本集N = {n1,n2,…,nnnum}和 少数类样本 集 F ={f1,f2,…,ffnum},其中nnum、fnum 为多数类和少数类样本的个数。
(2)对每一个少数类F中的样本fi(i=1,2,…,nnum)计算它在整个样本集T中的最近邻样本zi,如果zi属于多数类,则计算zi的K 近邻。
(3)如果zi所有的K 个最近邻样本都属于少数类,则这个多数类样本被认为是噪声,直接删除;否则判断其为边界样本。设边界样本集Bordline={f′1,f′2,…,f′bnum},其中,0≤bnum ≤fnum 。
(4)删除Bordline中的第一个样本f′1,形成新的边界样本集合Bordline′。用SVM对Bordline′和F构成的训练集进行训练,计算I(f′1)。
(5)对Bordline中的每一个样本重复步骤(4),得到I(f′1),I(f′2),…,I(f′bnum)。
(6)删除Bordline中对应I(f′i)值最小的样本f′i。
(7)循环(4)~(6),直到多数类边界样本和少数类样本数目相对均衡为止。
(8)将修剪后的多数类边界样本集和少数类样本集移入T′。
3.2 托攻击检测
本文设计了基于混合策略的托攻击检测方法,其流程如图1所示。该方法对数据样本的处理可分为两个阶段,首先利用本文提出的SIUT算法对原有的训练样本集进行均衡化处理,然后利用代价敏感支持向量机集成不同的误分类代价对均衡后的训练集进行分类。
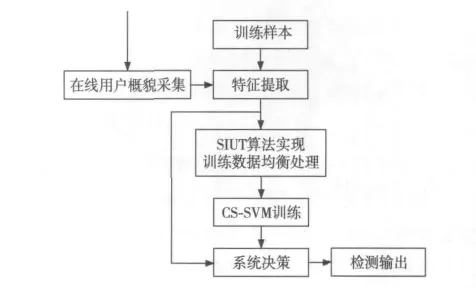
Figure 1 Detecting shilling attacks method using hybrid strategies图1 基于混合策略的托攻击检测方法流程图
对于重构后的样本集,利用代价敏感支持向量机进行托攻击检测的具体过程如算法2所示。
算法2 托攻击检测算法
输入:重构后的训练样本和测试样本;输出:托攻击检测结果。
(1)初始化重构样本集和模型参数。
(2)使用代价敏感支持向量机训练重构后的样本集,执行交叉验证操作,保存中间计算结果。
(3)判断结果是否达到最佳的检测性能,如果是,进入下一步;否则,返回到第(2)步。
(4)获得训练集上的最佳参数模型。
(5)计算式(5)中的决策阈值b,得到代价敏感支持向量机的决策函数。
3.3 混合策略分析
下面分析本文方法对推荐系统托攻击检测性能的影响。在最优化求解式(2)过程中得到的αi可能会有三种情况:
(1)αi=0,这时对应的xi被正确分类。
(2)0<αi<coiC,这时对应的xi称为普通支持向量,代表了大部分样本的分类特性。
(3)αi=coiC,这时对应的xi称为边界支持向量,代表所有误分的样本点。边界支持向量的比例在一定程度上反映了支持向量机分类的正确率。
设NBSV+和NBSV-分别代表攻击用户和正常用户中边界支持向量的个数,NSV+和NSV-分别代表攻击用户和正常用户中支持向量的个数,N+和N-分别代表攻击用户和正常用户的数量,co+和co-分别代表攻击用户和正常用户的误分类代价。
由式(3)有:

由式(4)可知,对于攻击用户αi的最大值是co+C,因此有:
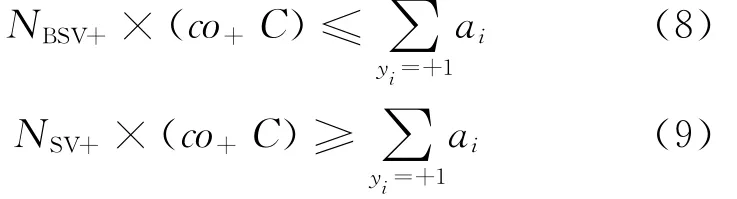
将式(8)和式(9)结合,得到:
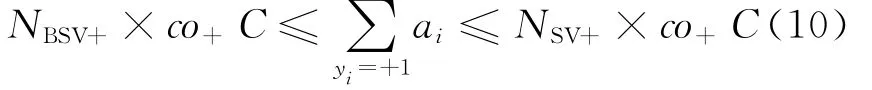
类似地,可以得到正常用户的不等式:

用co+CN+和co-CN-分别除以式(10)和式(11),并且设=F,得:

由式(12)和式(13)可知,边界支持向量比例的上界和支持向量比例的下界由N+、N-、co+和co-这几个参数决定。当攻击用户和正常用户的误分类代价相等时,即co+=co-,由于攻击用户的数量小于正常用户的数量,即N+<N-,这时攻击用户中边界支持向量比例的上界将大于正常用户边界支持向量比例的上界。这意味着攻击用户被误分的比例比正常用户被误分的比例大。在本文方法中,进行样本集重构能够减少N-,平衡两类样本的比例,同时代价敏感支持向量机对攻击用户设定较大的误分代价co+,综合起来将攻击用户被误分的比例上界F/co+CN+降低,从而提高攻击用户的检测精度。
4 实验与分析
4.1 实验准备
(1)数据集。
实验数据来自明尼苏达大学GroupLens研究小 组 通 过 MovieLens 网 站 (http://movielens.umn.edu)收集的 MovieLens100K 数据集[13],该数据集包含了943位用户对1 682部电影的100 000条1~5的评分数据,每位用户至少对20部电影进行了评分。数据集被转换成一个用户-项目评分矩阵R,并假设MovieLens数据集中不存在攻击用户评价行为。整个实验分为训练和测试两个阶段,按照80%~20%的比例拆分数据集构造训练-测试数据。
(2)特征提取。
特征提取是托攻击检测的基础,托攻击检测常用的特征信息包括[14]:用户的预测变化值、用户评价值背离程度、与其他用户相适度、邻居用户相似程度和背离平均度等指标。本文根据以上反映用户评分信息异常度的统计属性,对用户-项目评分矩阵R中每个用户的评分数据进行统计整理,得到5个检测属性,加上用户编号(userID)和分类属性(class)构成一条关于某个用户评分数据的检测数据。
4.2 实验结果分析
实验采取3×3×5的设计模式,攻击类型(随机攻击、均值攻击、流行攻击),攻击强度(3%、5%、10%),填充率(3%、5%、10%、15%、20%)。每组实验配置下,分别独立地向数据集注入10次攻击,最终实验数据是10次攻击检测的均值。使用SVM方法、CS-SVM方法、OSS和SVM相结合的方法、SIUT和SVM相结合的方法这四种方法和本文提出的方法做比较,选取G-MEAN值作为评价指标。实验中SVM方法采用高斯核函数,宽度为1,CS-SVM方法的误分类代价co+=3,co-=100,SIUT方法的K近邻取值为6。实验结果如图2~图4所示。
从图2~图4可以发现,无论是面对随机攻击、均值攻击还是流行攻击,本文方法的G-MEAN值都是所比较的五种方法中最优的,并且随着攻击强度的增加,其G-MEAN值逐渐提高,几乎可以检测出全部攻击用户,提高了对攻击用户的检测能力,进而能够很好地帮助推荐系统得到准确的用户评分数据,以确保系统的安全。具体分析如下:CS-SVM方法的G-MEAN值和SVM 方法的GMEAN值相比提高不明显,这是由于攻击用户和正常用户的误分类代价通常只能根据样本数目的比例进行选取,这种单纯靠调整惩罚因子的方法不能有效地提高SVM方法在类别不均衡和代价敏感情况下的分类性能。另外,从实验中可以看出,OSS和SVM相结合的方法大幅提高了SVM方法的分类性能,说明通过OSS方法进行预处理,能有效提高SVM方法的分类能力。但是,从实验结果可以看出,本文提出的SIUT方法对改善SVM方法处理不均衡数据分类问题的效果更加明显,这是由于SIUT在消除大量噪声信息的同时,又能保留绝大多数对分类学习有用的样本点,保证了信息损失最小,从而增大了后续分类方法对攻击用户的决策空间,因此分类性能较OSS方法更优。最后,值得一提的是,SIUT +CS-SVM 方法的G-MEAN值和SIUT+SVM方法的G-MEAN值相比有较大幅度的提高,说明通过对SVM方法进行代价敏感的改善能进一步提高算法的性能。
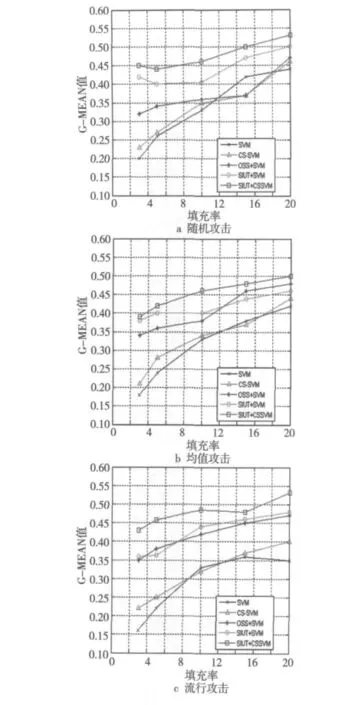
Figure 2 G-MEAN for detecting random attack,average attack,and bandwagon attack under attack size=3%图2 攻击规模为3%时检测随机攻击、均值攻击和流行攻击的G-MEAN值
5 结束语

Figure 3 G-MEAN for detecting random attack,average attack,and bandwagon attack under attack size=5%图3 攻击规模为5%时检测随机攻击、均值攻击和流行攻击的G-MEAN值
本文结合数据重采样和代价敏感学习两类解决方案的优点提出了一个新的托攻击检测方法。利用所提出的基于样本重要性的欠采样技术——SIUT对数据集进行重采样,在消除噪声样本减少数据不均衡程度的同时又保证信息损失最小。结合代价敏感支持向量机算法对重构后的训练样本进行检测。实验结果表明,本文方法在不同的攻击强度下对不同的攻击模型均获得了良好的检测效果,检测性能较传统SVM算法有显著提高。同时,不均衡数据和不同误分类代价的分类问题在现实世界中广泛存在,因此本文提出的方法还可以推广到其他应用领域。

Figure 4 G-MEAN for detecting random attack,average attack,and bandwagon attack under attack size=10%图4 攻击规模为10%时检测随机攻击、均值攻击和流行攻击的G-MEAN值
[1] Mehta B,Hofmann T.A survey of attack-resistant collabora-tive filtering algorithms[J].Data Engineering Bulletin,2008,31(2):14-22.
[2] Lam S K,Riedl J.Shilling recommender systems for fun and profit[C]∥Proc of the 13th International Conference on World Wide Web,2004:393-402.
[3] O’Mahony M,Hurley N J,Kushmerick N,et al.Collaborative recommendation:A robustness analysis[J].ACM Transactions on Internet Technology,2004,4(4):344-377.
[4] Vapnik V N.Statistical learning theory[M].USA:Wiley,1998.
[5] Williams C A,Mobasher B,Burke R.Defending recommender systems:Detection of profile injection attacks[J].Service Oriented Computing and Applications,2007,1(3):157-170.
[6] Li Cong,Luo Zhi-gang,Shi Jin-long.An unsupervised algorithm for detecting shilling attacks on recommender systems[J].ACTA Automatica SINICA,2011,37(2):160-167.(in Chinese)
[7] Bhaumik R,Williams C,Mobasher B,et al.Securing collaborative filtering against malicious attacks through anomaly detection[C]∥Proc of the 4th Workshop on Intelligent Techniques for Web Personalization(ITWP’06),2006:1.
[8] Weiss G M.Mining with rarity:A unifying framework[J].ACM SIGKDD Explorations Newsletter,2004,6(1):7-19.
[9] Liao T W.Classification of weld flaws with imbalanced class data[J].Expert Systems with Applications,2008,35(3):1041-1052.
[10] Zheng En-hui,Li Ping,Song Zhi-huan.Cost sensitive support vector machines[J].Control and Decision,2006,21(4):473-476.(in Chinese)
[11] Hong X,Chen S,Harris C J.A kernel-based two-class classifier for imbalanced data sets[J].IEEE Transactions on Neural Networks,2007,18(1):28-41.
[12] Kubat M,Matwin S.Addressing the curse of imbalanced training sets:One-sided selection[C]∥Proc of the 14th International Conference on Machine Learning,1997:217-225.
[13] http://www.grouplens.org/node/73.
[14] O’Mahony M,Hurley N,Kushmerick N,et al.Collaborative recommendation:A robustness analysis[J].ACM Transactions on Internet Technology,2004,4(4):344-377.
附中文参考文献:
[6] 李聪,骆志刚,石金龙.一种探测推荐系统托攻击的无监督算法[J].自动化学报,2011,37(2):160-167.
[10] 郑恩辉,李平,宋执环.代价敏感支持向量机[J].控制与决策,2006,21(4):473-476.
