基于有序二叉树的RDF存储模型研究
2013-09-03李心科秦冬生
李心科, 秦冬生
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
0 引 言
语义网作为第三代Web正越来越受到业界的青睐。语义网中的资源以RDF进行描述,基于RDF框架描述的语义Web数据不仅可以被人理解,而且可以被机器自动地共享和处理,从而实现了Web信息的自动处理,提高了Web数据的利用率。语义网的不断发展使得语义数据大量增加,原始简易的存储模式不可避免地遭遇了性能的瓶颈,从存储能力到响应性能上都已不能满足用户日益增长的需求。为了解决上述问题,不少研究人员关注语义网与云计算相结合的可能性。
近年来,云计算领域得到了快速发展,Google发表的分布式文件系统GFS、分布式数据库Big-Table及并行计算框架MapReduce等成果是当前云计算研究领域的热点之一。上述技术在Google的各项应用中得到了大量的使用,在开源社区也出现了与之对应的开源实现,Apache Hadoop[1]是其中应用最广泛的项目。这些开源分布式项目的涌现以及云计算本身具有的海量数据存储和处理能力,使得不少研究人员试图将云计算与语义Web结合起来解决海量语义Web数据存储和查询问题,该方面的研究尚处于起步阶段。
传统的RDF存储系统主要依托RDBMS和一些底层的存储载体,Vertically Partitioned方法[2]、Hexastore方案[3]及Jena系统[4]等均是经典的解决方案。
传统集中式的RDF存储系统已无法满足RDF数据爆炸式增长的趋势,研究人员开始将目光转向分布式领域。分布式系统所具有的海量数据存储和并行计算能力被认为是解决海量RDF数据存储难题的一个适宜的解决方案。
对于现有的分布式存储方案,研究人员从存储模型定义、底层存储系统选择及查询连接处理等不同角度提出了新的解决方案。文献[5]提出一个在hadoop上存储RDF数据的方案,在RDF数据存储方面,将RDF文档数据存储在hdfs中,在查询方面,实现了启发式搜索算法。文献[6]给出一种处理RDF数据查询的MapReduce多路连接策略,该策略很好地解决了RDF数据查询中连接操作复杂问题。文献[7]实现了hadoop与传统RDF管理框架sesame相结合的RDF数据存储系统HadoopRDF。文献[8]提出了基于HBASE的RDF存储系统。但现有的分布式解决方案都存在着文件索引结构复杂、查询响应策略不能保证查询效率等问题。
本文提出一种适合于云计算环境的RDF数据存储和查询方案。为支持海量RDF数据的存储和快速查询,提出基于有序二叉树结构的语义Web数据存储模型,该模型封装RDF文本数据信息到二叉树节点中,实现了语义Web数据分类存储,此外为了提高数据查询效率,引入了排序权值和结点层次的概念。
1 基于有序二叉树的RDF存储模型
RDF数据指以RDF三元组形式组织的语义网数据,通常由RDF、RDFS或 OWL语言及RDF图模型描述。RDF图以有向图作为存储模型,其中主体和客体作为节点,谓词充当边,边的方向由主体指向客体。依据文献[9]的方法给出RDF图的定义。
1.1 RDF图存储模型
定义1 设U、B、L分别表示资源集合、空节点集合以及文字集合,RDF数据用主体、谓词、客体三元组表示,其中,主体∈(U∪B ),谓词∈U,客体∈ (U∪B∪L) 。RDF图为RDF三元组的集合,图中的每个三元组表示一个节点-边-节点的连接。资源集合为Web上以URI标识的事物集合,文字集合包括所有字符串或数据类型的值,空节点集合则是所有起连通作用的匿名资源。
实际的RDF图如图1所示。
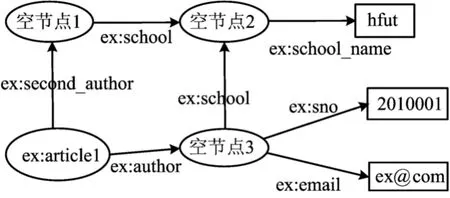
图1 RDF图
图1 所表述的含义是论文article1的第1作者、第2作者均来自同一学校hfut,且第1作者的学号为2010001、邮箱地址为ex@com。其中ex为本文假设的一个名称空间前缀;椭圆形节点表示资源;文字用方节点表示。图1中的数据用RDF图模型可表示为7个RDF三元组,即
ex:article1,ex:author,空节点3
ex:article1,ex:second-author,空节点1
空节点1,ex:school,空节点2
空节点3,ex:school,空节点2
空节点2,ex:school-name,hfut
空节点3,ex:sno,2010001
空节点3,ex:email,383235673@qq.com
RDF图模型可以直观地表达RDF数据,但存在如下缺点:① 空节点无法解析;② 无法进行等价节点判定;③ 缺乏合理的RDF数据聚合方法。
此外,传统RDF图模型忽略了结点层次关系的表示方法,导致无法辨别歧义三元组。如图1无法区分三元组 (空节点1,ex:school,空节点2)和(空节点3,ex:school,空节点2)。
有序二叉排序树既具有数组的元素搜索便捷特性,也具有链表灵活的元素删除和插入操作的优点,且能够准确地表述层次关系,此外还具有较高效率的遍历算法。有序二叉树的这些优点恰好能解决传统RDF图模型存在的一些问题。
合理的RDF数据分类方法是研究RDF存储模型的一个非常重要的问题,其中空节点的识别是一个关键点。针对上述问题,文献[10]提出利用本体的owl:Functional-Property(FP)、owl:InverseFunctionalProperty(IFP)属性对空节点进行识别。本文利用上述基本思想实现对RDF三元组的分类。
1.2 基于有序二叉树模型的三元组分类
定义2(函数型属性FP) 如果P为函数属性,存在P(x,y)与P(x,z),那么蕴含y=z。
定义3(反函数属性IFP) 如果P为反函数属性,存在P(y,x)与P(z,x),那么蕴含y=z。
根据上述定义,将RDF节点(三元组中的主体和客体部分)划分为以下3类:
(1)自然类节点。如果A为自然类节点,那么A∉空节点。
(2)功能类节点。如果A为功能类节点,那么A∈空节点,且满足以下任意条件:① ∃三元组T(A,P,B),其中P为反函数属性,B∈ (自然类节点 ∪ 功能类节点);② ∃ 三元组T(S,P,A),其中P为函数属性,S∈(自然类节点∪功能类节点);③ ∃ 节点B,A⇔B且B ∈ (自然类节点∪功能类节点)。
(3)其他类节点。如果A为其他类节点,那么A∈空节点,且A∉(自然型节点∪功能型节点)。
RDF三元组的节点类型直接决定了三元组含义的显隐属性。如果三元组不包含任何空节点,整个三元组表现为显式属性,不含任何的歧义性;如果包含空节点,由于空节点所表达的是未知对象,三元组表现出隐式属性,只能经过复杂的处理来消除歧义性。因此,本文依据三元组中的节点类型将RDF三元组分为:
(1)完全已知三元组。完全已知三元组中只包含自然类节点。
(2)部分已知三元组。部分已知三元组包含自然类节点和至少1个功能类节点。
(3)未知三元组。未知三元组包含自然类节点和至少1个其他类节点。
1.3 基于有序二叉树存储模型的结点描述
针对传统RDF图模型缺少描述节点关系的情况,本文将RDF有序二叉树结点结构定义为一个六元组O=(FS,ID,T,I,OP,NB),其中FS为子结点标识号;ID为结点标识号;T为结点类型;I为结点排序权值;OP为结点选项;NB为兄弟节点标识号。
(1)子结点排序号。子结点标识号是结点的子孙结点编号。
(2)结点标识号。结点标识号是结点在整个存储结构中的编号,对应唯一的三元组,由结点创建时生成,不能修改。
(3)结点类型。“0-know”表示结点为“根类型”节点,其子孙结点为谓词相同的完全已知三元组;“0-unknow”则表明结点是“根类型”节点,其子孙结点谓词相同且都包含空节点;“1”表示结点为“非根类型”。
(4)结点排序权值。结点排序权值表示结点被查询的期望值,权值越高表明结点被查询的可能性越大。该值仅对完全已知三元组结点有效。
(5)结点选项。结点选项用于记录解析空结点的上下文结点标识号,完全已知三元组结点该项为空。
(6)兄弟结点标识号。结点的兄弟结点标识号是结点的兄弟结点编号。
1.4 基于有序二叉树存储模型的结构描述
有序二叉树模型中的左子树结点表示孩子结点,右子树结点表示兄弟结点,结点可分为根类型结点和信息类型结点。
与树的根结点含义不同,本文中的根类型结点用于标识结点的子孙节点谓词相同且包含的三元组类型亦相同。即根类型结点是某类信息类型结点的开始标记。信息类型结点则是实际RDF数据的索引结点。
同类三元组集合的谓词信息只记录在“根类型结点”中,其他结点无需记录,这样大大减少了存储空间。
1.5 RDF图模型到有序二叉树存储模型的转化
将RDF图转化为有序二叉树存储模型,主要面临以下几方面的问题。
(1)在树形结构中存储RDF数据应考虑空节点的识别问题[11]。空节点提供多个三元组间必需的连通作用,与URI引用和文字不同,空节点标识符并不被认为是三元组的一个实际组成部分,它所表示的是一个匿名资源,要准确解析出空节点含义,必须结合语义上下文以及本体。
(2)RDF数据存储必须考虑文件组织形式[12]。不同的数据组织形式将直接影响数据查询方式和效率。
此外,传统的RDF图模型并未考虑节点层次关系的表示方法。
在空节点识别问题上,本文处理方法是利用本体的函数属性和反函数属性,结合空节点的上下文,消除空节点的歧义性,并记录上下文结点标识号。在实际的RDF查询中,如果三元组中拥有匿名的空节点,可以结合上下文结点解析空节点。本文给出的实例如下。


上例表示姓名为chin的学生认识1个姓名为assemble的计算机专业学生。考察三元组t1、t2、t3、t4,t1只含有自然类节点,所以属于完全已知三元组;假设谓词ex:major在本体中是反函数属性,t2、t3由于含有自然类节点和未知节点,属于未知三元组;t4含有自然节点和功能类节点,属于部分已知三元组。
因此完全已知节点有{t1},部分已知节点有{t4},未知节点有{t2}、{t3}。空节点?x在三元组集{t2、t4}、{t3、t4}中含义明确,故?x的歧义性可以联合三元组t2、t4或t3、t4消除。
本文用二叉树的父子关系[13]描述部分已知三元组和未知三元组的层次关系。对于三元组A(S1,P1,O1)和B(S2,P2,O2),其中S1、O1中至少1个为空节点,S2、O2中至少有1个为空节点。在有序二叉树结构中A、B关系为:
(1)如果S1=S2,则A、B为兄弟结点。
(2)如果O1=S2,则A为B的父亲结点。
(3)如果S1=O2,则A为B的儿子结点。
未知三元组节点 (:1,p,:2)、(:2,p,:3)、(:2,p,:4)在有序二叉树存储模型中的表示如图2所示。

图2 树形存储中层次关系的表示
本文给出RDF图模型转为有序二叉树模型的一般步骤如下。
(1)对RDF图中所有三元组结点构成n颗二叉树集 合 T = {T1,T2,…,Tn},并标 记 结点类型。
(2)对所有谓词为p、类型为完全已知的二叉树Ti,…,Tj,合并Ti,…,Tj为一根新树,将合并至T,删除Ti,…,Tj,。
(3)对所有谓词为p且三元组类型为部分已知或未知的树Tm,…,Tn,根据结点层次关系生成新树,删除Tm,…,Tn。如果谓词为p且类型为完全已知的树存在,将插入中;否则合并至T。
(4)借助树的孩子-兄弟链表表示法,将森林T转化为二叉链表结构的二叉树。
RDF图模型转化有序二叉树存储模型的实例如图3所示。
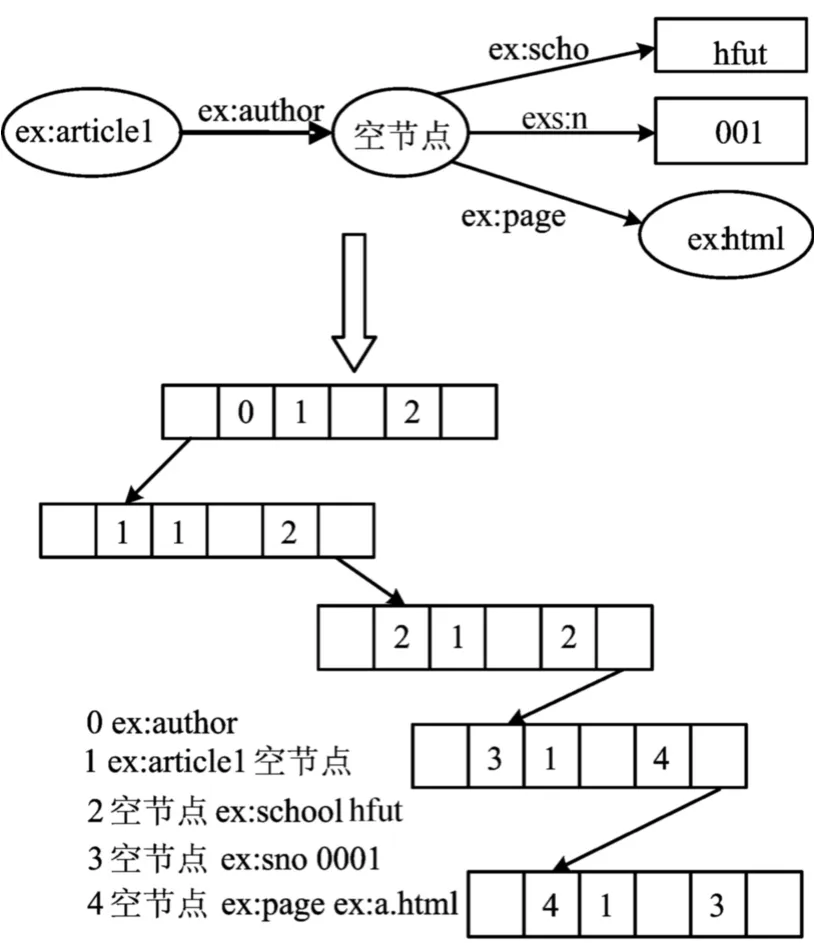
图3 基于有序二叉树存储模型实例
2 查询策略
2.1 排序权值
有序二叉树模型中RDF三元组的查询处理实质是查找满足条件的二叉树节点。为了使符合条件的节点被更早地查询,本文引入排序权值的概念。
定义4(排序权值) 设结点u被查询次数为SUM(Qu),其中命中条件M次,Bu为同等谓词结点集合,L(u)为Bu集合包含元素的数目,则排序权值为:

其中,ξ为参照因子,用于平衡结点命中率与结点的谓词被查询概率之间的关系。该计算方法使得经常被查询且命中率高的树节点权值高,被查询次数少且命中率低的树节点权值低。排序权值的引入,使得经常被查询且符合查询条件概率高的树节点最早被查询,在概率层面上减少了查询符合条件节点所需的查询次数。
在有序二叉树存储模型中,只有完全已知节点的排序权值才有意义,其他类型结点由于考虑到空节点的层次表示问题不能使用排序权值。结点的排序权值关系为:父节点的排序权值>左子树的排序权值>右子树的排序权值。
2.2 节点查询算法
为了提高树节点的查询效率,本文对实体三元组进行预处理,主要是建立标识号索引和谓词索引。标识号索引用于快速定位查询的三元组,将所有的三元组利用hadoop下的MaPreduce任务建立统一编号并存储于一个文件中,该文件是所有三元组的实际存储文件,有序二叉树中存储的是该节点的编号。
建立谓词索引是有序二叉树模型在数据查询时将连续地查找某一谓词的结点集合,这就要求能快速定位到谓词的开始标记处。
由于RDF数据的存储结构为有序二叉树,实际含有三元组信息的结点始终位于根类型节点的左子树中,其次,考虑结点的排序权值关系,这些特性决定了先序遍历法较适合本文中结点的查找。结点的查询算法描述如下。
算法1 节点查询方法
输入:查询三元组Q(x py),RDF数据集D(T)=〈T1∪T2∪…∪Tn〉
输出:确定的查询结果三元组


算法1先取出有序二叉树BST,从BST的根节点开始,沿着右子树方向查找谓词为p的根结点,这时所查询出的根结点即是谓词为p的完全已知三元组集合的开始标记结点,三元组集合在根结点的左子树上。由于模型中树结点的排序权值大小关系为:根结点>左孩子结点>右孩子结点,为了尽量用较少的步骤查询出符合条件的结点,算法1用先序遍历法遍历左子树。如果左子树中包含符合条件的结点,返回查询结果。否则,完全已知三元组集中不包含所查询的三元组。如果BST中包含结点谓词为p且类型为未知的根结点,则该结点左子树包含所有谓词为p的未知结点集,先序遍历左子树。如果查询某未知结点符合条件,这时结合选项中的结点,解析出目标结点,返回结果,将解析出的结点加入至BST中。否则,查询失败。
3 实验分析
本文针对查询响应、查询预处理性能进行了对比实验。实验以RDF图模型为基础,选取存储结构的Sesame[14]作为对比系统。
实验采用4台Ubuntu搭建的hadoop集群,以LUBM基准数据集为测试数据集。对于LUBM数据集中16个标准查询分别在不同的数量级上进行查询测试,结果如图4、图5所示。
由图4可看出,实验数据在较小数量级时,本文模型与Sesame系统的平均查询响应时间几乎相等;当数据量较大时,有序二叉树模型能够大幅度地缩短查询响应时间。
由图5可得出,有序二叉树模型在预处理阶段比Sesame系统消耗时间长,但与查询响应时间相比在很小的数量级上,故其产生的影响可忽略不计。
此外,本文模型为追求更快的查询性能,建立了多个索引,故需要更多的存储空间。云计算具有较强的可扩展性,可以通过向集群中添加更多的机器以获取更大的存储能力及更强的运算能力,存储空间和计算能力不会成为束缚有序二叉树模型的因素 。因此,本文的有序二叉树模型更加适合海量RDF数据存储。
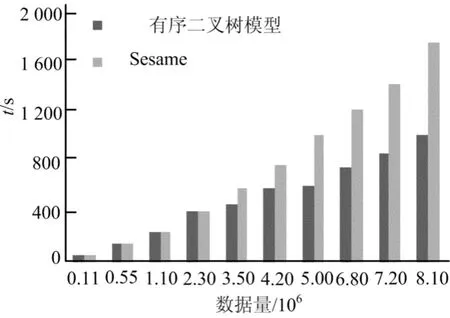
图4 查询响应性能实验结果
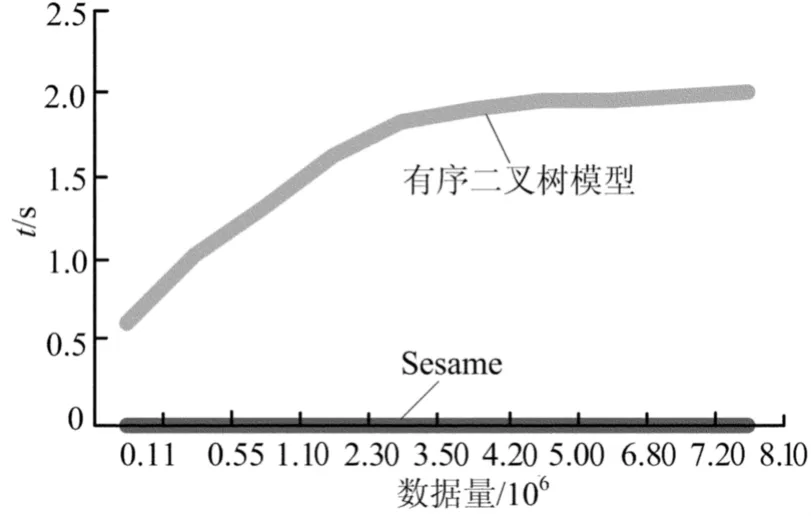
图5 查询预处理性能实验结果
4 结束语
本文提出了基于有序二叉树的海量RDF数据存储模型,并实现了RDF数据的查询算法,对比实验结果证明了该模型的可行性和有效性。在后续的工作中,将进一步优化查询响应策略,提高RDF数据查询成功率。
[1]Borthakur D.The hadoop distributed file system:architecture and design[EB/OL].[2012-08-16].http://hadoop.apache.org.
[2]Abadi D J,Marcus A,Madden S R.SW-Store:a vertically partitioned DBMS for semantic web data management[J].The VLDB Journal,2009,8(2):358-406.
[3]Weiss C,Karras P,Bernstein A.Hexastore:sextuple indexing for semantic web data management[J].The VLDB Endowment,2008,1(1):108-119.
[4]Owens ASeaborne AGibbins N.Clustered TDBa clustered triple store for jena[EB/OL].[2009-05-02].http://eprints.soton.ac.uk/266974/.
[5]Husain MF,McGlothlin J,Masud MM.Heuristics-based query processing for large RDF graphs using cloud computing[J].IEEE Transactions on Data and Knowledge Engineering,2011,23(9):1312-1327.
[6]Myung J,Yeon J,Lee S G.SPARQL basic graph pattern processing with iterative mapreduce[C]//Proceedings of the 2010Workshop on Massive Data Analytics on the Cloud,2011:1-6.
[7]Tian Yuan,Wang Haofen,Jin Wei,et al.A pattern-based approach for efficient query processing over RDF data[J].Transactions on Large-Scale Data-and Knowledge-Centered Systems V Lecture Notes in Computer Science,2012,7(10):70-90.
[8]Choi H,Son J,Cho Y,et al.SPIDER:a systeMfor scalable,parallel/distributed evaluation of large-scale RDF data[C]//The Conference on Information and Knowledge Management,2009:2087-2088.
[9]Klyne G,Carroll J J,etal.Resource description framework(RDF):concepts and abstract syntax[EB/OL].[2012-01-20].http://www.w3.org/TR/rdf-concepts/.
[10]Lee Berners,Connolly T,Delta D.An ontology for the distribution of differences between RDF graphs[EB/OL].[2009-8-12].http://www.w3c.org/DesignIssues/Diff.
[11]McGlothlin J P,Khan L.Materializing and persisting inferred and uncertain knowledge in RDF datasets[C]//Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence,2010,23(9):1312-1327.
[12]Mcglothlin J P,Khan L T.RDFKB:efficient support for RDF inference queries and knowledge management[C]//IDEAS’09Proceedings for the 2009International Database Engineering and Application Symposium,2009:259-266.
[13]Arora N,Tamta V K,Kumar S.Modified non-recursive algorithMfor reconstructing a binary tree[J].International Journal of Computer Applications,2012,43(10):25-28.
[14]Broekstra J,Kampman A.Sesame:ageneric architecture for storing and querying RDF and RDF schema[C]//Proceedings of the First International Semantic Web Conference(ISWC2002),2002:54-68.
[15]邓 青,韩江洪,周 健.基于混合决策树的自适应数据集成方法[J].合肥工业大学学报:自然科学版,2011,34(8):1165-1169.
