基于GPU加速的光线跟踪渲染算法研究
2013-08-21江兰帆
陈 昱 江兰帆
(福州大学 数学与计算机科学学院,福建 福州 350108)
1 引言
光线跟踪是一种基于物理的图形渲染算法,相比于实时流水线光栅化算法,更方便实现真实环境中的反射、折射、透明、阴影等全局光照效果。光线跟踪算法产生的画面真实感强,被广泛应用于电影后期制作等领域。
光线跟踪算法需要跟踪每一条光线,将其与场景中几何对象执行相交测试,计算量很大。因此,目前光线跟踪主要应用于离线渲染,在实时渲染中的应用还处于试验阶段。如果光线跟踪算法的性能可以达到实时交互,必然可以极大地提高该算法的应用领域,对计算机图形学相关应用(如游戏,电影等)将产生重大影响。
2 光线跟踪算法加速分析
为了提高光线跟踪算法的速度,一种思路是改进算法(如研究提高求交计算的效率,采用加速结构减少求交的次数等),另一种则是从硬件体系出发。光线跟踪渲染中每条光线独立计算,十分适合并行体系结构。近年来,集成大量处理核心的GPU(图形处理器)在计算能力方面增长迅速,在特定类型计算中已远超CPU[1]。光线跟踪算法理论上可以利用GPU架构的数据并行性获得较高的性能,利用GPU实现光线跟踪的实时交互成为了一个新的思路。
本文采用NVIDIA公司的CUDA作为GPU编程平台,采用BVH作为加速结构,对三角形网格模型进行渲染,针对CUDA体系结构进行了算法的重新设计与优化。实验结果表明10万三角形的场景在目前主流型号GPU上算法已可以达到实时交互的性能,与CPU实现相比加速比达到5倍以上;与采用Kd-tree作为加速结构的实现相比[2,3],在同等复杂度的场景下性能更好。
3 基于GPU的光线跟踪渲染
3.1渲染算法流程
渲染算法的流程和阶段如图1所示。整个渲染分成两个工作阶段:
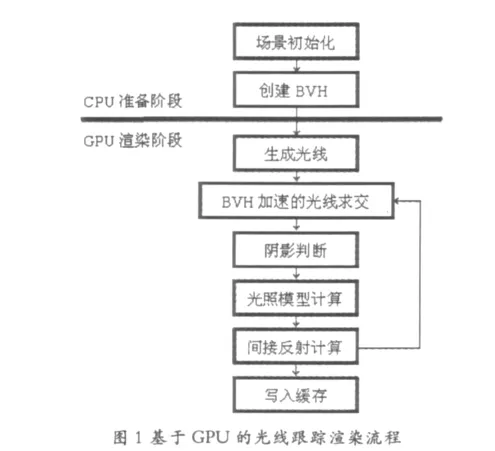
1、CPU准备阶段是在CPU上运算完成的,负责读取场景数据和创建BVH。在得到这些数据之后,将其复制到显卡的显存中,供GPU渲染时使用。
2、GPU渲染阶段是通过CUDA的kernel函数实现光线跟踪渲染算法,编译后运行于GPU上。首先从视平面的像素点向场景空间中投射光线,获取光线与场景中对象的最近碰撞点,利用BVH加速结构进行快速相交测试。接着判断该碰撞点是否处在阴影区域,如果不在则利用光照模型计算该位置的直接光照强度。如果考虑间接反射情况,则应继续跟踪光线,计算碰撞点的间接光照强度。将直接光照和间接光照叠加起来,即可计算出视平面的像素点的颜色值。在GPU中每一个线程计算一条光线方向,计算出像素颜色后写入OpenGL PBO缓存区域,最终显示在窗口中。
3.2 场景初始化
程序首先完成场景数据(包括对象,光源和照相机)的初始化。其中场景中的对象使用三角形网格(Mesh)进行描述,实现了从模型文件中读取顶点数据(坐标,颜色,法向量)和多边形定义。光源可在程序中设定其初始位置,类型采用点光源。照相机默认采用透视投影。光源和照相机位置在程序执行过程中可以动态改变。这些场景数据的数据量比较大而且要能供所有线程访问,因此只能通过CUDA API将其以数组的方式拷贝进GPU的全局内存或纹理内存,供GPU渲染程序使用。
3.3 生成光线
根据观察方向和视平面分辨率,可以计算得到每个像素的坐标;结合照相机位置,就可以得到从投影中心到每个像素的主光线的参数方程。在GPU中,每个线程计算一条光线在场景中的反射光强度,即像素的颜色值。每个线程块(Block)分配的光线数用以下公式计算:(SIZEX*SIZEY+THREADS_PER_BLOCK-1)/THREADS_PER_BLOCK。其中SIZEX和 SIZEY为屏幕窗口长宽方向上的像素数,THREADS_PER_BLOCK为CUDA中每个block的线程数。
3.4 BVH的构建与遍历
在生成光线后,渲染程序需要将光线与场景进行相交检测,获取距离视点最近的物体交点。一种简单的做法是将光线与场景中的所有几何对象进行碰撞检测,通过比较获取最近的碰撞点。这种做法易于实现,但所需的计算量也是极为庞大,时间复杂性为O(N),N为场景中对象的数量,而使用BVH和Kd-tree等加速结构的时间复杂性为O(logN),判断效率提高明显[4]。
1、BVH 的构建
BVH(层次包围盒)的基本思想是按照某一空间维度将原包围盒分成两部分,每部分再接着往下分,直到满足结束条件,其过程与二叉树类似。BVH中内部节点不包含三角形,但包含两个子节点的索引,而叶子节点包含一个三角形列表。创建过程是一个递归地划分包围盒的过程,每次包围盒划分位置的确定将影响BVH的生成结果,并影响整个加速结构的遍历性能。比较常用的方法是划分时采用表面积启发式(Surface Area Heuristic)代价模型,估算光线穿越包围盒的期望代价,求得近似最优解。
基于SAH评估的BVH创建过程如下[4]:
(1)将当前节点包围盒的最长轴的方向作为分割方向;
(2)将三角形列表按照包围盒的中心点在分割方向上的位置N等分,产生N-1种备选划分方式:左边1份,右边N-1份,…,左边N-1份,右边1份;
(3)对每种分割方式分别计算两部分包围盒的表面积,再应用SAH代价模型估算当前划分方式的代价,选取代价最小的分割方式划分当前节点;
(4)以同样的方式递归生成孩子节点,一直到三角形数量小于设定的阈值为止,即可完成BVH的创建。
在CPU中完成BVH的构建后,将其数据结构拷贝到显存中,供GPU渲染程序用于遍历。
2、GPU中遍历BVH进行相交测试的实现
BVH的遍历是一个深度优先的递归过程。从根节点开始,光线与节点的包围盒进行相交测试。如果没有相交,返回。如果相交,将光线与该节点的两个子节点进行相交测试;或者该节点是叶子节点,则与该节点的三角形列表逐一进行相交测试。
在CUDA平台上实现BVH遍历的问题是,CUDA前期的架构版本(G80/GT200)是不支持递归函数调用的,所以为了实现更好的GPU兼容性,需将BVH遍历修改为非递归算法,将原本指向节点的指针用节点索引替代,并引入堆栈保存节点列表。算法如下:
初始化节点列表为空,将根节点添加到节点列表中
初始化当前相交的最近距离为无限远:min_t=INEnd While

3.5 阴影计算
当确定光线和场景中三角形的最近交点后,下一步需计算交点处的反射光强度(即颜色值)。首先要判断的就是在交点和光源之间是否有物体遮挡,如有遮挡则光源对该像素点的颜色无直接贡献;否则在计算像素颜色时需要考虑该光源的贡献。当确定光线和场景中三角形的最近交点后,可以在光源与交点之间生成阴影检测光线,并利用3.4节中基于BVH的相交测试算法进行遮挡测试。
3.6 光照模型计算
为了计算光线所对应的像素颜色(即交点处反射向视点的光线颜色),在交点处可以使用常用的Blinn-Phong光照模型公式[5]计算其在每个光源下的反射光颜色并叠加:
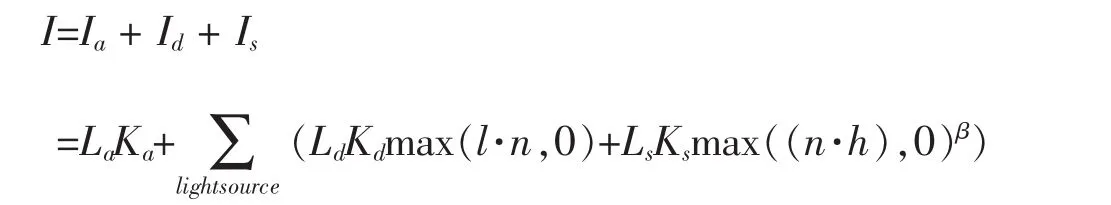
CUDA支持float4数据类型,十分方便进行上述公式中向量的计算。其中镜面反射分量计算时需要交点处的法向量n,通过三角形三个顶点处的法向量(从模型文件中读取)结合交点处的质心坐标(Barycentric Coordinates)插值计算得到,实现Phong插值着色,这样计算得到的物体表面的反射光颜色过渡较为自然。
3.7 间接反射计算
在光线跟踪渲染中,光线与场景第一次相交后通常还需计算间接反射情况。像素的颜色除了包含光源的反射光颜色之外,还需其他表面产生的间接反射光颜色。光线每反射一次便需计算一次交点处的颜色值,这样经过多次反射后,像素点最终色彩便是多个间接反射颜色的累加。
上述间接反射过程是一个递归的计算,实现中为了函数在有限时间内返回,需定义递归的深度(即跟踪的反射次数),可以表示成以下的伪代码:

//利用传入的光线参数查找最近相交点intersec-

上述光线跟踪的递归算法十分简洁,但为了在CUDA上实现上述算法,必须进行非递归模式的改写。由于RayTrace函数中变量众多,如果用3.4节中添加堆栈的方式改写该算法,代码的改写量大、改写后可读性差。因此,本文利用C++的模板元编程(Template Meta Programming,TMP)技术解决这个问题。所谓模板元编程,是C++将计算从运行期转移至编译期、由编译器在编译期执行部分计算的技术统称[6],利用其中的“递归模板实例化”技术可以实现编译期递归结构。
在原递归函数声明前加上template
template
Color RayTrace(Vector3 ray,Vector3 origin,...){
....
//利用传入的光线参数查找最近相交点intersectionPoint
//计算交点处光照模型下的颜色值.phongColor
//计算反射光线reflectionRay
...
return color+RayTrace
再定义如下形式的完全特化(Specialization)后的模板函数,其中的递归深度被预先定义的常量MAX_DEPTH(比如4)特化了,从而得到递归结束时的函数如下:
template<>
Color RayTrace
return BLACK;//这里结束了递归
在编译过程中,编译器会分析depth在执行过程中可能的值的情况,根据函数模板生成depth值不同时的函数版本,即生成从RayTrace<0>(这是主光线时的情况)到RayTrace
从上述代码片段可以发现其对原算法的代码改变是很小的,并且克服了CUDA无法编写递归函数的问题。当然,元编程也有其缺点,比如编译时间变长,执行文件变大,不宜调试等。
4 实验结果及分析
实验采用不同顶点数和多边形数的场景对上述渲染算法的GPU和CPU实现进行性能测试,测试过程中设定一个点光源,视点位置绕固定轴旋转一周,记录下渲染360帧(即旋转360度)所需时间后求每秒平均帧数(FPS)。测试平台软硬件配置如下:
*CPU:AMD Athlon II X2 255 3.1GH,双核心
*GPU:NVIDIA GeForce GTS 450,192 个流处理单元
*CUDA Toolkit:版本 4.2.9
测试场景分别为两个3DS模型文件 (Chess和Gundam),两个Stanford提供的PLY模型 (Horse和Armadillo),渲染结果如下:

4.1 GPU线程配置测试
在CUDA中,kernel函数执行的性能受到底层硬件配置和软件配置的影响,从软件层面的优化来说,很主要的是合理配置其线程参数,以便达到较好的处理器利用率。CUDA中的线程以两层结构的形式组织管理,即网格(Grid)包含多个线程块(Block),线程块包含多个线程(Thread)。如果每个块的线程数太少,无法充分利用多核心的处理能力,也无法通过调度隐藏访问显存的延时。如果一个块的线程数太多,由于在一个多核流处理器 (Streaming Multiprocessor,SM)上同时执行的线程数受到寄存器数量、共享内存数量等硬件资源限制,又会使得许多线程处于等待状态,无法并行执行[7]。
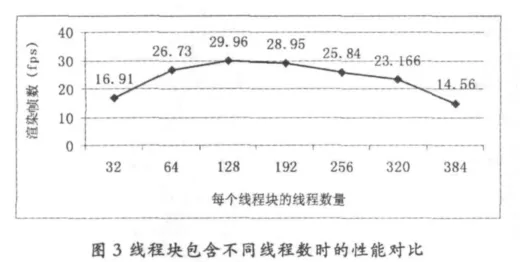
对线程块包含不同线程数时的Chess场景渲染测试的结果如图3所示:
图3测试结果表明,对上述光线跟踪算法GPU实现在测试平台上的最佳数配置是每个线程块包含128个线程。这与光线跟踪的kernel函数需要的寄存器数量比较多有关系,更多的并发线程所需的寄存器数量无法在硬件上得到满足。
4.2 GPU和CPU渲染对比测试
对上述光线跟踪渲染器的GPU和CPU实现进行性能测试,其中GPU测试采用每块128线程配置下的测试结果;CPU也是用BVH加速结构,并且采用OpenMP实现多线程并行计算,以利用CPU的多个核心。测试结果见表1。
从表1可以看出,GPU实现的渲染引擎可以在512x512分辨率下对10万个三角形以内的场景实现大于15 fps的渲染速度,相比CPU的实现 (使用OpenMP优化)有5倍以上的性能提升。渲染速度与场景的构成(顶点数量,三角形数量)、模型表面多反射的发生数量以及渲染的视角都有关系。总的来说,顶点数量和三角形数量少的场景渲染速度较快,物体表面相互反射较少时速度较快,物体占据画面的面积较小时速度较快 (空白背景的像素光线直接穿越,BVH可以快速判断此情况)。
5 总结
本文在基于BVH加速结构的光线跟踪算法基础上,根据CUDA平台的特点重新对渲染算法进行了设计与优化,在GPU上实现了具有实时性的光线跟踪算法。测试结果表明,主流GPU在512x512分辨率下,10万个三角形以内的场景可以达到超过15 fps的渲染速度,可实现实时交互;与采用Kd-tree作为加速结构的实现相比[2,3],在同等复杂度的场景下性能更好。
经过实验,也发现GPU在实现光线跟踪渲染上的不足之处。由于光线跟踪渲染算法代码复杂,编译后线程所需的寄存器数量较多,限制了可同时并发的线程数量[8];虽然程序使用了CUDA手册中的多种优化技巧,但渲染更高的分辨率和更复杂的场景仍需要性能更强大的GPU才有希望实现实时性。
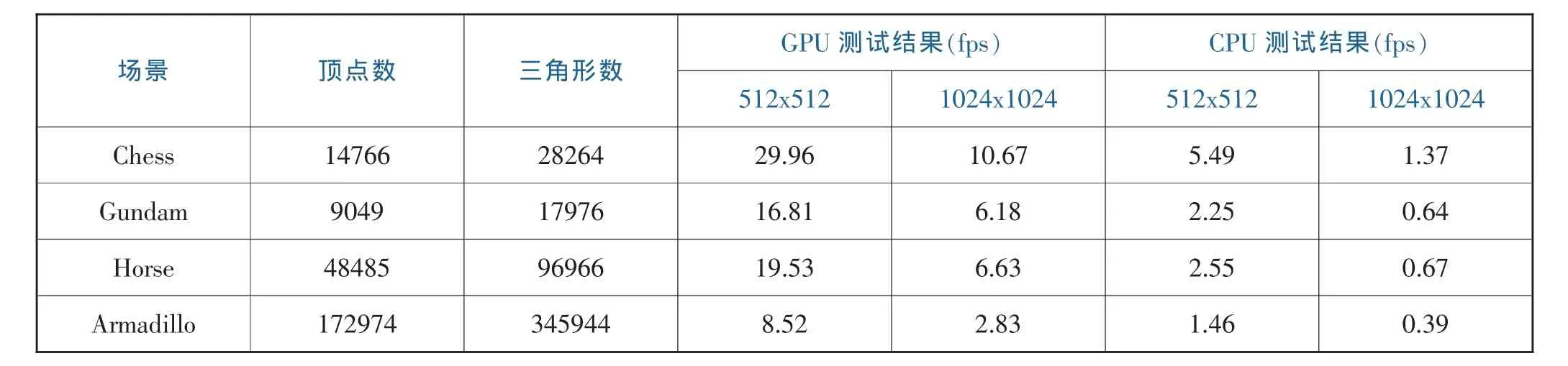
表1各场景在不同分辨率下的渲染性能测试结果
[1] 吴恩华,柳有权.基于图形处理器(GPU)的通用计算[J].计算机辅助设计与图形学学报,2004,16(5):601-612.
[2] 陆建勇,曹雪虹,焦良葆等.基于GPU交互式光线跟踪算法的设计与实现[J].南京工程学院学报(自然科学版),2009,7(3):61-67.
[3] 曹家音.基于KD-Tree遍历的并行光线跟踪加速算法[J].科技传播,2010,(17):233-233,224.
[4] Matt Pharr,Greg Humphreys.Physically Based Rendering,Second Edition:From Theory To Implementation[M].Morgan Kaufmann,2010.217-222.
[5] Edward Angel著,张荣华等译.交互式计算机图形学—基于OpenGL的自顶向下方法(第五版)[M].北京:电子工业出版社,2009.222-226.
[6] David Abrahams,Aleksey Gurtovoy著,荣耀译.C++模板元编程[M].北京:机械工业出版社,2010.
[7] David B.Kirk,Web-mei W.Hwu著,陈曙晖等译.大规模并行处理器编程实践[M].北京:清华大学出版社,2010.59-60.
[8] NVIDIA.CUDA C BEST PRACTICES GUIDE v4.2[Z].NVIDIA Corporation,2012.48-53.
