视频中的人体检测算法
2013-08-18常州先进制造技术研究所王敏赵娜娜刘忠杰黄榜
常州先进制造技术研究所 王敏,赵娜娜,刘忠杰,黄榜
中国科学院合肥物质科学研究院先进制造技术研究所 宋小波
常州先进制造技术研究所 朱擎飞
1 简介
一般情况下,有两种主要方法来解决图像中的人体检测。一种是用人身体部位位置的几何模型来对人体建模,在文献[1]中,身体部位用组合关节和位置的直方图来表示。用独立的Adaboost算法检测器训练多个身体部位的模型。尽管这项技术能够提供一个通用的对象识别框架,但是难以达到快速实现的目的。此外应该考虑到,人体的自然状态可能不完全适用于处理低分辨率的人体图像上,这种情况在监控录像中经常遇到。
第二种方法建立在对给定图像的所有可能的子窗口进行人体检测的基础上。检测图像中目标的最简单方法之一,就是用滤波器卷积图像或用目标响应建立模板。卷积的输出应该产生一个大响应来显示目标;同时抑制背景响应。卷积输出超过阈值的时候,就意味着检测到目标。这种方法的主要优点是,它非常简单而且速度非常快。
基于滤波器的目标检测算法是否成功取决于滤波器区分目标和背景能力。产生滤波器的典型方法是从训练图像中剪裁目标的模板。不幸的是,一幅图像基础上的模板往往不能充分捕捉外观变化,因此只能用在高度控制的对象检测的方案之中。为了弥补这一缺陷,有一些技术从大量的模板中提取滤波器,这样才能更准确地反映目标的外观。例如,可以通过平均模板产生一个滤波器。但是也存在另一个缺点,这种滤波器往往不能充分区分目标和背景。
更复杂的基于综合鉴别函数(SDF)[2]的方法也可用来产生滤波器,对训练模板有良好的反应,并产生清晰和稳定的峰值。SDF的一个问题是在训练中没有考虑完整的卷积输出。相反,它只强调在输出中滤波器与目标对准时的一个点。这些技术的目的,强调良好的目标峰值,但当它涉及到相似背景的抑制峰值的效果就差了很多。
最近训练滤波器引入一个新的概念,所谓平均合成精确的滤波器(ASEF)[3]。ASEF考虑到滤波器完整的卷积操作的整个输出。比起传统技术,通过利用卷积定理产生的ASEF滤波器更像是反卷积。文献[3]的结果表明,ASEF滤波器定位在脸上眼睛的效果很好,因为滤波器很好地抑制了其他面部特征的响应。这项研究将显示ASEF滤波器在一个更一般的检测问题上,能产生良好的目标与背景分离,参见2009年的PETS数据集[4]。
ASEF滤波器基础上的检测器有许多优点。训练只需要少量的手注解图像和几秒钟计算时间。由此产生的检测器要专门对于相机设置进行调整。比起其他竞争技术,检测技术非常简单,而且是在非常规则的卷积的基础上,这意味着它非常适合于嵌入式系统或现有的信号处理芯片。基于滤波器的检测比竞争技术快许多倍,而它的精度差不多甚至更好。
2 方法
本文的目的是从固定摄像机捕获的实时视频中检测人体。为了检测视频中的人体,每一秒都必须对成千上万的检测窗口进行评估。绝大多数这些窗口对应着背景,而且必须被忽略。因此,必须构造一个分类,能够可靠地拒绝掉提交给它的大多数检测窗口;但是,当实际存在一个人体的时候,就要避免错误地拒绝窗口。这可能是一个重大的挑战。
原则上,在每一帧标记视频中,对于所有可能的检测窗口训练检测器都是有意义的。但是这样做对常用类型的检测器(如VJ级联分类检测器),往往要求过高的计算能力。虽然推动这种类型的训练是明智的,多次迭代后可以产生很好的检测器,但是过程中难以实现自动化,并在实践中可能会出现问题。
与此相反,这里所介绍的技术本身在每一个可能的检测窗口自然参与有效的培训。这是因为分类器是基于卷积的,而且训练可以实现高效率地利用卷积定理。具体说来,本研究提出的滤波器是花费了12秒在3145728个检测窗口中被训练出来的。
2.1 大小归一化和预处理
创建一个基于滤波器的检测器,其中一个挑战是规模变化的问题。在PETS2009数据集中,人体的高度从最小的50个像素变化到最大的150像素。这带来了两个问题。第一个问题是训练都是假定人体为大致相同的尺寸的。第二个问题是在测试中,滤波器需要被应用在多尺度下。这两个问题的解决方案是利用相机设置的几何形状。由于相机的升高而且在一个近似平面的场景向下看,相机定位的人体很好预测一个人的高度。这里的方法是按照大致比例把场景分割为一些区域。然后这些区域重新调整,使人们在每个区域中都是大致相同的高度。重新缩放的区域比整幅图像中的人体平均身高按比例而言,方差小得多。这些区域可以在人行道上着重检测工作,那里已经涵盖了视频中的大部分动作。设置均匀尺寸的区域,简化了滤波器的训练,又确保了图像的大小与FFT兼容。
图1(a)显示的是高度完整的视频图像中的人,可以很好地使用线性模型来近似。图1(b)显示了在重新调整的检测区域中人的高度。在重新缩放区域,人的高度变化要小得多。
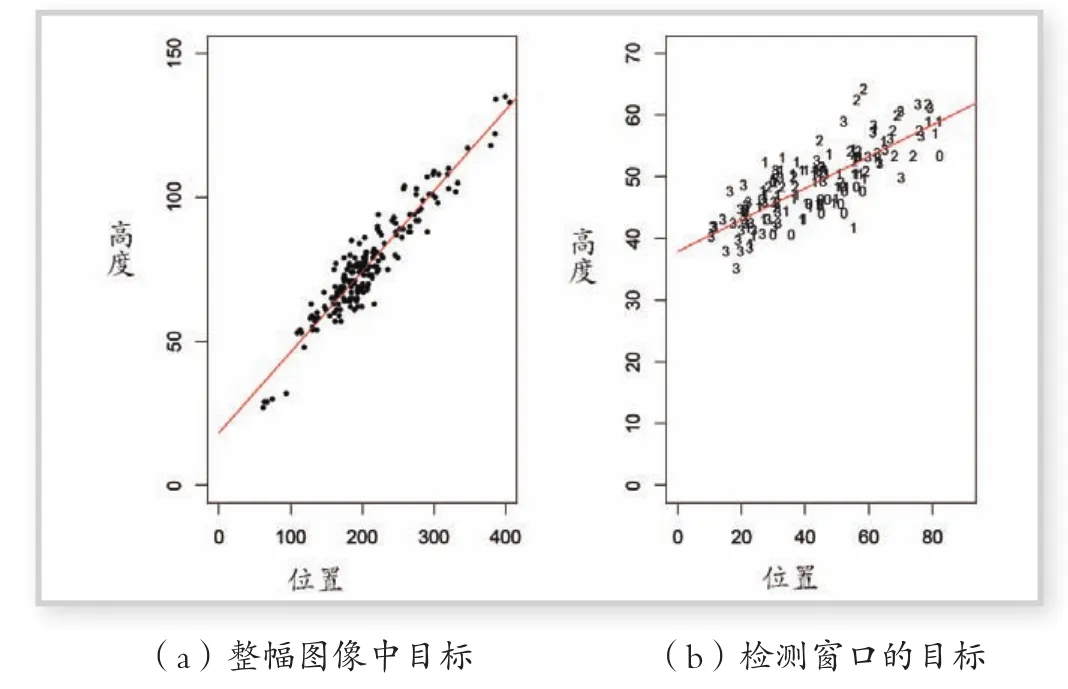
图1 目标大小归一化
另一个挑战是一个事实,即一个人的外表受服装的影响很大。许多检测算法都专注于基于梯度的特征来解决这个问题[5~7]。基于梯度特征集中于边缘信息的检测过程中,检测较少依赖于像素的绝对强度值。因此,在检测区域中图像使用标准的Sobel算子对每个像素进行预处理,产生梯度幅值。此步骤创建一个新的图像,里面的人体主要由轮廓来定义。然后,通过给像素值取对数的方法对这些照片进行归一化,而且调整照片使一个区域内归一化的值在零和单位长度之间。
2.2 训练ASEF滤波器
滤波器的训练过程的例子如图3所示,在[3]中有详细讨论,使用了Pyvision库实现滤波器[8]。ASEF滤波器学习了从源图像到目标图像的映射。更正式地说,他们选中图像f∈RP×Q,并将其映射到一个新的图像g∈RP×Q。该映射的参数化由滤波器和卷积变换来定义,其中卷积g=f⊗h。
在训练标准检测器的时候,每个检测窗口都会被标注:如果存在一个人体,就标注为一个正面的例子;如果是对应于背景,就标注为负例子。与此相反,对于复杂的场景,ASEF滤波器的训练同时包含正面和负面的例子。如果存在一个人体,整个图像被标记为峰,值是1.0,背景值就为0.0。ASEF过程学习了从训练图像到标记输出的映射。
更正式地说,对于每个训练图像if,将产生一个合成输出ig,其图像里的每个人都对应一个峰。ig里的峰将按二维高斯的形状分布:
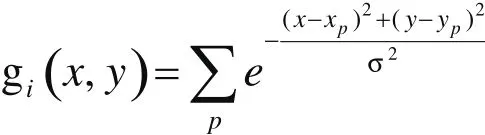
其中,(xp,yp)是训练的图像中的人p的位置,σ控制峰值的半径。
接着,对于每个训练图像,将要计算一个精确的滤波器hi,精确地将图像fi映射到gi。在傅立叶域中,这种计算是有效的。卷积定理指出,卷积在傅立叶域中变为元素相乘。因此,这个问题可以从空间域中的:
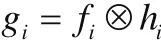
转化为在傅立叶域中的:
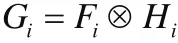
其中,Gi,Fi和Hi是他们小写字母的傅立叶变换,⊗ 明确表示对应元素乘积。确切的滤波器现在可以通过求解下面的公式进行快速计算:
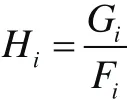
该方法将学习一个“匹配”滤波器,这意味着它在空间域的x轴和y轴将同时翻转。也可以通过采取在傅立叶域中的复共轭执行这翻转。该滤波器上也以像素(0,0)为中心。
所得的滤波器可以被认为是一个弱分类器。映射到高维特征空间中的过程是缓慢的,所以选择建立在完整图像特征空间基础上的弱分类器。如图3所示,精确的滤波器看上去不像模板,更像是噪音响应了人体的轮廓。要产生一个更一般的分类器,就要对于每一幅训练图像进行计算精确的滤波器,然后取平均值。平均精确的滤波器的目的可以参见文献[9]。简单的滤波器集中收敛于方差误差最小化的滤波器。对于同一个实例,平均得到的特征是特定的,于是思考平均过程的更直观的方式是:通过多次滤波后保持特征不变。因此,最终ASEF滤波器被计算为:
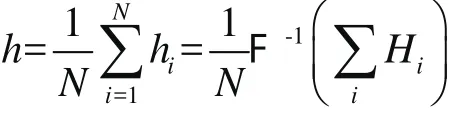
其中N是训练图像的数目。平均有一些很好的特性,使得ASEF滤波器的训练速度快又很容易计算:它不会过度拟合训练数据,对于每个图像,它仅需要一个单一步骤,只需要足够内存来存储一个滤波器。
ASEF有一个限制是:它通常需要大量的训练图像,以收敛到一个好的滤波器。有两种方法可以减少所需的培训总帧数。第一,从[3]可知,是重复使用因小缩放、小旋转、小变换与影响而变动的训练图像。这增加了训练图像的数目,而且还鼓励滤波器对于旋转和缩放的小变化变得更强大。
本文介绍的改进技术改善了精确滤波器的稳定性。在求解滤波器的公式中,训练图像中携带较少功率的频率,在相应的精确滤波器中占有较大比重。这些频率会导致精确滤波器变得不稳定,并且在极端的功率为零情况下,会引起被零除的错误。为了纠正这个问题,精确滤波器使用iF的最大频率来构造,iF包含图像95%的总功率。
删除小的频率似乎会除去精确滤波器的很多“噪音”。在测试中,这种发现就允许了ASEF滤波器以较少的图像进行训练,而其准确性或外观不会有不利影响。
2.3 基于滤波器的对象检测
使用滤波器的目标检测器简单又快捷。各个检测区域进行相同的重新调节和预处理过程,作为训练。图像使用公式2的FFT方法与ASEF滤波器卷积,得到这些梯度幅度图像。
由此产生的相关输出,当人体存在的时候,应该有峰值;当为图像背景的时候,响应被抑制。然后扫描相关输出,寻找局部极大值。任何超过了用户定义的阈值的最大值就被认为是检测到了一个结果。参阅图2和图4的例子。
3 实验结果与分析


图2 实时视频中的人体检测结果例一

图3 例一的前景识别结果

图4 实时视频中的人体检测结果例二
图4是实时视频中的快速人体检测实例,显示效果良好,尤其是例二中,运动人体在身侧的深色玻璃上产生镜面反射,于是在视频中的部分图像中,很清楚地显示出了镜中的人影,但是本文使用的算法很好地避免了这种情况的误检测。
实验结果表明,算法可以处理超过每秒25帧的图像,并实现了对于稀疏人群实现94.5%的检出率。滤波器训练也很快,训练32手动注释图像的检测器只需12秒。本文的的检测算法能够更好地处理复杂背景下的不明显运动人体目标检测,减少前景图像中图像的空洞,从而精确地实现运动人体的目标检测。
4 结束语
本文采用基于滤波器的相关边缘幅度图像的人体检测算法。关键是训练滤波器所使用的技术:平均合成的精确滤波器(ASEF)。ASEF检测算法效果好、精度高、准确度高、鲁棒性强,大大改善了复杂背景下的人体检测率,本文算法能够很好地对运动视频中的人体进行提前检测,从而更准确地实现运动人体检测。
[1] K. Mikolajczyk, C. Schmid, and A. Zisserman. Human detection based on a probabilistic assembly of robust part detectors. In Europe Conf. Comp [C].Vision (ECCV),2004,1:69-81.
[2] B.V.K. Vijaya Kumar, A. Mahalanobis, and R.D. Juday. Correlation Pattern Recognition. Cambridge University Press, 2005.
[3] D.S. Bolme, B.A. Draper, and J. Ross Beveridge. Average of synthetic exact filters[C].In CVPRMiami Beach, Florida,2009.2105-2112.
[4] J. Ferryman and A. Shahrokni. An overview of the pets2009 challenge[C].In PETS,2009,25-30.
[5] N. Dalai, B. Triggs, I. Rhone-Alps, et al. Histograms of oriented gradients for human detection[C].In CVPR,2005,886-893.
[6] O. Sidla, Y. Lypetskyy, N. Brandle , et al. Pedestrian detection and tracking for counting applications in crowded situations[C].In IEEE International Conference on Video and Signal Based Surveillance,2006.
[7] B. Wu and R. Nevatia. Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors[C]. In ICCV,2005,90-97.
[8] D.S. Bolme. Pyvision - computer vision toolkit[EB/OL]. http://pyvision.sourceforge.net, 2008.
[9] L. Breiman. Bagging Predictors[J].Machine Learning,1996,24(2):123-140.
