面向网络流的正则表达式匹配改进算法
2013-08-13吴君钦
吴君钦,王 凯
(江西理工大学 信息工程学院,江西 赣州 341000)
在网络安全监控中,深度报文检测技术是一种主要的手段,它通过字符串匹配算法把网络中捕获到的数据流与特定的字符串进行匹配。这里所说的特定字符串是指在分析数据报文协议的基础上提取的特征字符,通过这种方式可以识别并阻断某些数据流,实现有效的网络安全防范。
在深度报文检测技术上,经典的字符串匹配算法有单模式匹配的KMP和BM算法,改进的多模式匹配的AC算法、CM算法、WANG方法和 Wu-Manber算法,然而这些算法都采用字符串匹配为基础。随着网络的不断发展,应用软件特征字符识别的复杂度越来越大,采用字符串匹配已难以匹配识别,因此这些算法的局限性也凸显出来。基于正则表达式的多模式匹配具备了优越的表达匹配能力和灵活性,相比传统的字符串匹配更加精确高效。
基于正则表达式的多模式匹配是把正则表达式转变为自动机,自动机分为两种:非确定有限自动机(NFA)和确定有限自动机(DFA)。NFA的优点是占用内存和系统资源少,但是需要对每个字符进行遍历,处理状态集里的所有状态,很耗费时间。如 good(day|night|evening):若要搜 goodday,NFA需要把goodday、goodnight、goodevening全部遍历一次才能完成搜索。相比之下,DFA搜索一个字符只需要访问一个状态,但是若把所有的正则表达式都转变为DFA将会占用非常大的系统内存资源,目前的硬件条件还无法满足这一点。
结合NFA和DFA各自的优缺点,本文提出了一种猜测-分组-检验的匹配算法。使用DFA在猜测的基础上添加分组,能够更有效减少系统内存占用率;然后再结合NFA检测确保算法具备高匹配度。
1 正则表达式相关算法
深度报文包检测技术是基于系统规则库对在网络中捕获的数据包中的每一个字节进行扫描和识别,标准的字符串匹配算法有:Aho-Corasiek[1]、ComentZ-Walter[2]和Wu-Manber[3]算法。如今随着网络协议复杂度日益增加,传统的字符串匹配算法难以精确地识别出复杂多变的协议类型[4]。
SOMMER R和 PAXSON V[5]认为,用正则表达式描述网络中数据协议行为比用字符串表达更为高效、灵活。KUMAR S[6]等通过将DFA的某些状态用单条缺省边来代替,提出一种称为延迟输入DFA,实验结果表明,相比于传统的DFA存储空间可减少95%以上。但是引入缺省边导致处理一个字符需要多次访问内存,参考文献[7]对参考文献[6]进行改进,提出一种目录寻址的D2FACD2FA,用包含部分状态信息的目录标签来代替状态的ID,而这些信息一般是保存在状态表的条目中,使得一次转移只消耗一个字符。
YU F等人提出了将正则表达式进行分组的思想[8]。其方法是:计算正则表达式两两之间是否引起状态增长,在进行分组时,选择一条与其他表达式具有最小相关度的正则表达式开始,然后按照相同的原则向这个组里不断添加,直到这个组形成的DFA内存超过预先设定的阈值,再开始创建另一个新组。重复这个过程,直到所有的表达式都被分配出去为止。
[9]提出了一种混合自动机的方法,其基本思想是:将整个规则集编译成一个NFA结构之后,并不对它进行完全的确定化,而是在确定化之前判断状态之间跳转的原因。进行部分确定化的结果就是形成了一个混合的自动机结构,它的前面一部分是DFA的状态,而在每个边界状态之后都带有一个NFA,这个NFA以边界状态作为初始状态。
张树壮等人提出了一种基于猜测-验证的匹配方法[10]:首先使用DFA对正则表达式中的部分子特征进行搜索,完成特征存在性的猜测。当猜测到有可能匹配某个特征后,再使用NFA进行验证。这种方法既充分利用了DFA的高效性,减少了对相对较慢的验证过程,又借助NFA避免了内存消耗过于巨大。
本文在深入研究和分析以上算法的基础上,针对DPI规则库这样十分庞大的规则系统,借鉴一些经典正则表达式匹配算法,提出一种猜测-分组-检验算法。该算法把分组作为核心步骤,利用正则表达式之间的相关性组合后进行分组,能够十分有效地降低系统内存资源的使用率。结合NFA验证,该算法能够对输入进行有效的匹配和识别。
2 算法描述
正则表达式匹配算法分为三个步骤:猜测、分组和检验。总体来说,在安全监控中所使用的规则一般都可以分为若干个特征子块 Sub-feature,如图1所示,每个子特征之间通过正则表达式运算符连接在一起。获取到这些特征子块之后,可以简单地把它们合并转换为一个DFA。然而这样一个DPI的规则库,将会占用十分庞大的系统内存资源。所以在获得特征子块后,需要采用相似性度分析对这些子块进行分组,把相似程度高的子块聚合在一起,并通过子集构造法转换为一个DFA,再通过正则运算符把各个组的DFA连接在一起。分组后的DFA占用系统内存资源小,可以有效减少空间使用率,进而提高资源的有效利用率。若某个输入与猜测选择出的特征子块匹配,则把输入进行NFA验证,验证方法是基于DPI库中的每条规则转变为NFA得到的。

图1 特征子块示意图
2.1 猜测
在面向网络数据流匹配的基础上,安全监控中使用的规则可以明显地分为若干个部分(Sub-feature)。首先从系统规则库保留的某条规则中还原出Sub-feature,然后以Sub-feature的出现为依据猜测输入是否与某些规则匹配。在本文中,根据规则库每条规则中某段字符串出现的概率来选取Sub-feature进行输入猜测。
2.2 分组
若正则表达式两两之间具有相似性 (这里的相似性定义为:当正则表达式单独转换为DFA所需要的状态数大于正则表达式联合在一起转换为DFA所需要的状态数,那么称正则表达式具备相似性),则它们联合在一起转变为DFA所需要的状态数小于其单独转换所需要的状态数总和,这将大大减少占用的系统内存资源。若两个正则表达式具有相似性,例如abde、abdz两个正则表达式,将它们单独转换为 DFA,如图2、图3所示,联合起来转换为DFA,如图4所示。结果表明,联合转换需要7个状态,而单独转换共需要10个状态,联合转换比单独转换减少了3个状态。

图2 abde转换状态图

图3 abdz转换状态图
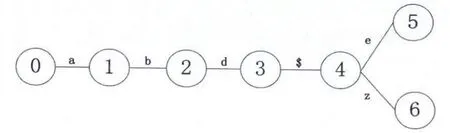
图4 abde和abdz联合转换状态图
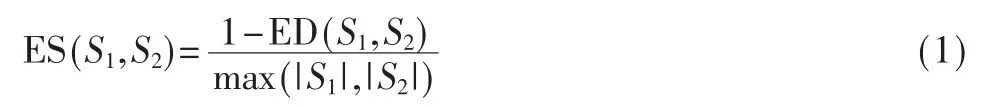
其中S1和S2分别为代表两个需做比较的正则表达式,ED(S1,S2)是指 S1和 S2之间编辑距离,max(|S1|,|S2|)是选择两个正则表达式中字符多的一个。若两个正则表达式完全一样,则计算结果为1;若两个正则表达式完全不同,则计算结果为0。式(1)的字符串相似度算法复杂度小、精确度大,采用其进行相似度计算能够有效减少内
相似性计算中采用字符串相似性计算法,如式(1)所示:存消耗并且确保极高的匹配率。
采用上述的相似性计算法将每个Sub-feature进行相似度分析并分组。首先,在所有未分组的Sub-feature中选取一个与其他Sub-feature具有相似性的Sub-feature加入一个新组并记为group0;其次,在所有未处理的Sub-feature中,选取一个与 group0中所有 Sub-feature具有相似性的Sub-feature加入group0中;然后,重复以上步骤,把相似度低的或者未处理的正则表达式另行分组为 group1、group2、group3 等。
Sub-feature分组后, 对每个组 group0、group1、group2及group3等分别进行DFA转换,分组转换后的DFA要比没有分组直接转换DFA所需要的状态数少,有效地降低了系统资源使用率。
2.3 检验
经过上述的猜测和分组过程可以将大部分不满足条件的输入过滤掉,只剩少数数据可以与某条规则中的网络数据流所有特征子块相匹配从而需要进行完整验证过程。因此可以使用速度相对较慢、但内存需求较低的NFA来完成。NFA是通过从特征子块中提取的各条完整规则,经过Thompson构造法转换得到的。该检验方法通过占用系统内存资源不大的NFA来实现,保证了匹配结果的精确性。
为方便描述现定义:S表示规则中所有的正则表达式集合,r为集合中的正则表达式,rk为 Sub-feature,Gd表示基于相似度算法分组数:

该算法首先从正则表达式中搜索出Sub-feature作为猜测条件,根据相似性算法函数ES计算所有Subfeature的相似度,并选出相似度大于70%的 Sub-feature,储存在分组函数 groupi(i=0,1,2,…,d-1)中,共有 d个分组。在输入前,通过函数make_DFA、make_NFA生成预处理的DFA和NFA。当有输入时,算法进行匹配,若输入能够满足猜测并与DFA匹配成功,则对输入的完整规则进行NFA匹配。
3 实验结果与分析
正则表达式匹配算法性能是否优越的一个评价标准是系统内存占用率。本实验将猜测-检验算法进行对比和分析。实验采用的正则表达式来自Linux Lay er-7 filter(L7)以及snort规则集中常用的 Web-misc规则类;并用编译工具在VC上生成NFA和DFA。
实验配置:主机 CPU频率 2.69 GHz;1.99 GB内存;Window XP操作系统,网络配置器是Realtek RTL8169/8110 Family Gigabit Ethernet NIC。
实验步骤:(1)在 L7和snort规则集中提取出Subfeature;(2)采用式(1)中字符串相似性算法把相似性大于70%的Sub-feature分为一组,实验中对L7和Web-misc类的Sub-feature进行分组;(3)将每组中的正则表达式分别通过编译工具生成DFA,并最终合并为一个DFA;(4)对比猜测-检验算法。
实验结果与分析:表1、表2分别给出了 L7和 snort中的Web-misc规则采用本文算法与猜测-检验算法所占内存需求对比。由实验结果可以看出,基于L7规则库,猜测-分组-检验算法所占用的内存比猜测-验证算法减少了35%;而基于snort中Web-misc规则库,猜测-分组-检验算法所占用的内存比猜测-验证算法减少了5%,且猜测-分组-检验算法的DFA状态数大幅度小于猜测-验证算法。由此可知,本文所提正则表达式算法能更有效地减少系统内存资源的使用。本文在深入学习、研究正则表达式和探讨了优化

表1 L7规则上的内存需求对比

表2 snort中Web-misc规则上的内存需求对比
NFA与DFA的基础上,借鉴一些经典的正则表达式匹配算法提出了一种新的面向网络数据流正则表达式匹配算法:猜测-分组-检验算法。这种算法首先使用分组算法对正则表达式中的Sub-feature进行相似性分组,然后完成对输出的特征子块猜测,最后将通过猜测的输出进行完整的NFA检验。算法通过对比猜测-验证算法进行实验分析,验证了该算法具备系统内存资源占用率低和匹配能力强的优点。
参考文献
[1]AHO A V,CORASIEK M J.Effieient string matehing:an aid to bibliographic searerch[J].Communications of the ACM,1975,18(6):333-340.
[2]WALTER B C.A string matching algorithm fast on the average[J].Processing of ICALP,1979,71(7):118-132.
[3]WU S,MANBER U.A fast algorithm for multi-pattern searching[C].Department of Computer Science,1994.
[4]Qi Deyu,Qian Zhengping,Zheng Weipin.Fast dynamic pattern matching for deep packet inspection[C].Proceedings of 2008 IEEE International Conference on Networking,Sensing and Contriol,ICNSC,2008.
[5]SOMMER R,PAXSON V.Elthaneing byte-level network intrusion deteetion signatures with context[C].ACM conf,on Computer and Communication Security,2003.
[6]KUMAR S,DHARMAPURIKAR S,YU F.Algorithms to accel-erate multiple regular expressions matching for deep packet inspection[J].Computer Communication Review,2006,36(4):339-350.
[7]KUMAR S,TUMER J,WILLIAMS J.Advanced algorithms for fast and scalable deep packet inspection[C].ACM,2006.
[8]YU F,CHEN Z F,DIAO Y L,et al.Fast and memoryefficient regular expression matching for deep packet inspection[C].In:Proc.of the IEEE/ACM Symp.on Architectures for Networking and Communications Systems.San Jose,2006.
[9]BECCHI M,CROWLEY P.A hybrid finite automaton for practical deep packet inspection[C].In:Processing of the ACM CoNEXT 2007,2007.
[10]张树壮,罗浩,方滨兴,等.一种面向网络安全检测的高性能正则表达式匹配算法[J].计算机学报,2010,33(10):1976-1986.
