基于最大熵的哈萨克语词性标注模型
2013-08-04新疆大学信息科学与工程学院乌鲁木齐830046
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.国家语言资源监测与研究中心 少数民族语言中心 哈萨克和柯尔克孜语文基地,乌鲁木齐 830046
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.国家语言资源监测与研究中心 少数民族语言中心 哈萨克和柯尔克孜语文基地,乌鲁木齐 830046
1 引言
在自然语言中,词是语言的基本单位,而词性(POS)是词汇最重要的特性。词性标注是为句子中的每一个词标注一个正确的词性,是实现自然语言分析和理解的一个重要中间环节,此环节出现的错误,将在后续处理链中被放大。例如在机器翻译中,词性标注错误有时会导致错误地理解整句话。许多自然语言处理任务,如:信息抽取、信息检索、文本分类、机器翻译等都依赖于词性标注的精确结果才能最终取得理想的效果[1]。
哈萨克语属于阿尔泰语系突厥语族的克普恰克语支,拼音文字,是黏着语言类型;与汉语、英语等相比具有自己的特点。
2 研究现状
词性标注的方法有基于规则、统计以及规则与统计相结合的方法。Ratnaparkhi[2]较早展开了应用最大熵模型进行英文词性标注的研究,使用的特征有包括每个单词本身词形,前面两个词的词形和词性,后面两个词的词形以及单词中是否含有数字、连字符、大写字母等,测试的语料采取华尔街日报,取得了96.63%的标注准确率。在汉语研究方面赵岩[3]等应用最大熵模型进行了汉语的词性标注研究,使用的特征有包括每个单词本身词形,前面两个词的词形和词性、后面两个词的词形以及词的前缀、后缀、重叠词等,在《人民日报》语料库上进行了大规模测试,词性标注的准确率均在96%以上。在哈萨克语词性标注研究方面,达吾勒等[4]使用基于规则的词性标注,准确率为74%。刘艳等[5]使用统计与规则结合的方法进行了探索,其中的统计方法使用了隐马尔科夫模型(HMM),封闭测试准确率达到了86%。侯呈风[6]使用了改进的HMM,封闭测试准确率达到86.8%,开放式测试的准确率为81.4%。本文基于最大熵的方法构建哈萨克语词性标注模型,在封闭与开放测试中准确率分别达到了96.8%和86.1%。
3 基于最大熵的词性标注模型
3.1 最大熵模型原理
最大熵模型(Maximum Entropy,ME)的工作原理是,对未知部分的知识,不做任何假设,选取符合这些知识使熵值取最大的概率分布。熵是对一个随机变量的不确定性的定义,熵最大的时候对应的随机变量最不确定。最大熵原理的实质:在已知部分知识的前提下,符合已知知识最不确定或最随机的推断就是对未知部分最合理的推断,这是可以做出的唯一最接近事物真实状态的选择,对于任何其他的选择,都意味着增加了其他的约束和假设条件。
最大熵模型能把各种不同的特征在同一个框架中刻画出来,并且不需要特征的独立性假设,能够对文本中的上下文信息有效地利用,根据己有的事实提取表达特定任务的特征集合,在有效的约束条件下可以得到与训练数据一致的概率分布,该模型已广泛应用于分类问题的处理中。
3.2 最大熵模型框架
形式化描述最大熵模型:随机过程所有输出的值构成一个有限集,设为Y,对于每个输出结果 y∈Y,输出的结果都受到上下文x的影响,x属于有限集X。对于自然语言处理的许多问题都可以这样来描述,对于哈语词性标注任务来说,x表示待标注词上下文的环境,y表示输出结果属于所有的词性标记集合Y,实现的任务是:在实例或上下文x的条件下,构造一个模型,能精确地估计出分类标记结果 y出现的概率即P(y/x)。所有的条件概率分布的集合用P来表示,那么对P(y/x)就是P的一个元素。但是对于所有可能的(x,y),要做到完全精确地确定P(y/x)一般是不可能的,所以需要构造出一种模型,通过x和 y的统计特征,当给定上下文信息x∈X时,能够较准确地估计出输出y∈Y的条件概率 p(y/x)。
根据最大熵原理,p(y/x)的取值符合下面的指数模型:

fi(x,y)就是所谓的特征函数,y表示标注结果,当 x满足特定的上下文条件时,特征值为真。
λi是特征参数,代表每个特征的重要性。Zλ(y/x)是归一化因子,它的引入是为了保证P*(y/x)是概率,也就是。公式(1)使模型由求概率值转化为求参数值λi,一般的估计方法是Darroch和Ratcliff[7]的通用迭代算法(Generalized Iterative Scaling,GIS),用来得到具有最大熵分布的所有参数值λi。Pietra等[8]则描述了一个改进的迭代算法IIS。
3.3 最大熵模型的特征表示
最大熵模型的关键在于如何针对特定的任务,为模型选取特征集合。采用简单的特征表示复杂的语言现象,承认已有的可观察到的事实,不做任何独立性假设,这些观察到的事实表示为最大熵模型的特征集合。在汉语词性标注研究中,基本上都采用基于词的上下文特征[9]。哈萨克语与汉语、英语不同,哈语是以词为单位,这方面像英语,但是哈萨克语具有粘着性和丰富的上下文信息,哈语词的词形变化要比英语丰富得多。基于哈语自身的特点,本文特征空间定义为:
词,当前词及其前后各一个词。
词干,当前词的词干及其前后各一个词的词干。
词性,前一个词的词性,及后一个词的词性。
词缀,由于哈语的词缀变化较多,这里只选择前一个词及当前词的最后一个词缀。
根据这个特征空间,本文定义了模型中的模板,如表1所示。在这个表中每个模板只考虑了一种因素,称之为原子模板。原子模板也可以看作是对于当前上下文的一个特征函数。
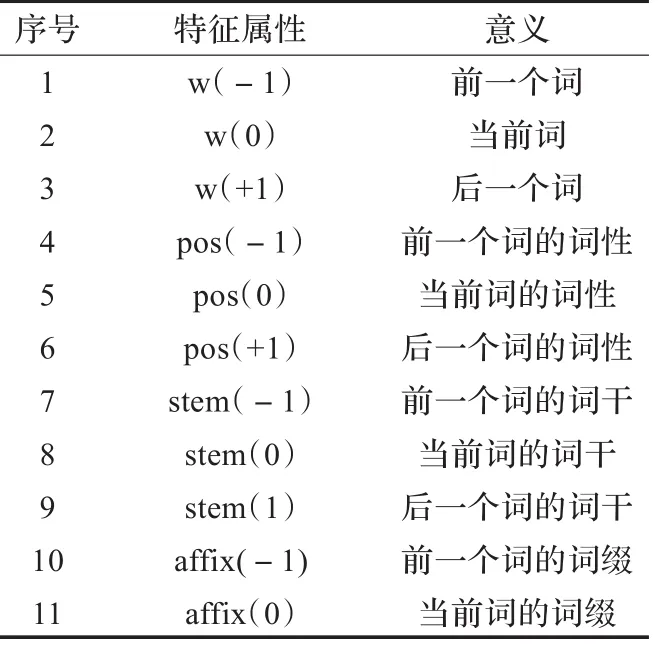
表1 原子特征模板
当特征函数取特定值时,则该模板被实例化,得到具体的特征。特征一般由两部分来组成,一部分称为条件或上下文x,另一部分则是在条件满足时采取的行动,或称为目标概念类y。特征值一般可以定义为下面的一个二值函数形式:

在上下文中,仅仅使用原子特征不足以表示上下文中的一些现象。故本文对表1中的各种原子模板进行了组合,构成一些复合模板来表示更复杂的上下文环境,如表2所示,由于文章篇幅,这里只列出了一部分。原子特征模板和各种复合特征模板共同构成了模型的所有特征模板,共有40种摸板。同样,对于复合特征模板,也是首先对各个原子模板进行实例化,对模板函数取值后,输出某种标注,从而产生一个特征,为复合特征。复合特征表示为二值特征函数的形式与原子特征相似,只是在取值时需要满足的条件变多。
3.4 特征选择
通过对人工标注的熟语料进行训练,从候选特征集中提取一个数量庞大的特征集合,然而并非所有特征都适合引入到最大熵模型中,因此,需要进行特征选择,通常选择下面两种办法。
(1)基于频数阈值的特征选择:只保留那些频数大于等于一定阈值k的特征。基于频数阈值的特征选择认为不常出现的特征是噪声或不相关的,只有那些出现频数大于k的特征才真正代表了数据的特性,可以选作特征。阈值k的选定与任务和数据相关,可以通过实验来确定。多数研究者[10]通常取5,在3到20之间都可以找到较好的阈值。
(2)增量式特征选择:使用增量法来选择区分度最高的特征作为特征集。增量式特征选择以特征信息的增益来判断是否引入该特征,通过计算每一个要加入特征的增益,再从中选取增益最大的一个,并且重新计算加入该特征的最大熵分布,重复该步骤直到增益不显著为止。
文献[11]将方法(1)和方法(2)进行了比较:当k值选取适当时,两种方法性能上差别不大,均有相同的召回率和准确率,但在训练时间上,第一种方法较为简单,训练时间相对较短,优于第二种方法。本文采用第一种方法进行特征选取,经过反复实验,将特征频数的阈值定为5,表示只使用特征频数大于5的特征。考虑到哈语的特殊性,如有的词是合成词,有的词没有词缀(如:词根)等,需在进行特征提取时将上下文中含有空值的特征去掉。

表2 复合特征模板
4 系统设计
基于最大熵模型的哈萨克语词性标注系统,核心的是训练模块和标注模块。
4.1 训练模块
图1是训练模块的数据流图。图中的候选特征是通过特征模板从语料库中进行的抽取;在候选特征的基础上通过基于频数阈值的特征选择,只保留那些出现频数大于等于5的特征,建立特征集。将特征结果组织好后送到最大熵工具包进行训练,本文中选择IIS算法进行参数估计。

图1 训练模块数据流图
4.2 标注模块
首先进行识别之前的预处理工作,将语料组织成符合识别模块接口标准的形式。输入文件是经过词干提取之后的语料,语料中包括词、词干、词缀等信息。为了能提高模型的标注准确率,在语料中加入了部分词的词性信息:
(1)根据电子词典能唯一确定词性的,标注其词性并添加一个标签记为var=0。
(2)不能确定其唯一词性,但是可以获得所有可能词性的,将这些词性一起标注,使用#号分隔不同的词性,并添加标签var=1。
(3)其余的词添加标签var=2。
标注模块的主要任务就是给定一个需要词性标注的句子W=(w1,w2,…,wn),找到一个与此对应的词性序列T= (t1,t2,…,tn), 使得
本文的算法如下:
步骤1读入一个句子,从左向右依次标注每个哈语单词wi,根据特征模板实例化其上下文特征向量Xi。
步骤2使用训练阶段得到的模型计算得到Xi的每个特征取值的概率P(Yi|Xi),选取概率最大的前n项作为候选词性(这里取n等于3)。局部最优算法在这一步只是选择概率最大的一个词性,因此它也就没有下面的步骤3,选择一个概率最大的词性标准序列。因为基于局部最优算法得出的只有一条标准序列。
步骤3依次将这n个词性加入下一个词的上下文特征向量中,以此类推直至句子结束。最终选出一条使P(T|W)取值最大的词性标注序列。
5 实验结果与分析
5.1 实验数据
本文实验数据来自本实验室的现代哈萨克语综合语料库,它的内容来自于2008年《新疆日报》哈语版,题材涉及政治、经济、体育、卫生、文化、艺术、娱乐等。目前该语料库已完成词干切分、词缀的提取,以及部分的词性标注。本文采用2008年1月份的已完成人工词性标注和校对后的语料进行实验,包含646篇文章共31 695条语句,图2给出了一个语料的样例。在31天的语料中1~28号的语料作为训练语料,其余作为开放测试语料,并其在测试时从训练集中随机抽取3天的语料作为封闭测语料。其中pos表示单词的词性,stem表示单词的词干,affix表示单词的附加成分,var为词类标记符号(var为0时表示电子词典中词性唯一;var为1时表示兼类词;var为2时表示人工修改的词性)。

图2 语料样例
根据本阶段语料库建设的需要和训练语料的规模,本文词性主要包括一级词性。具体词性及对应的标记集见表3。

表3 哈萨克语一类词性标注集
5.2 实验结果
为评估本文中方法的有效性,在相同的语料上分别做了HMM及局部最优的最大熵方法的对照实验,标注结果对比如表4所示。
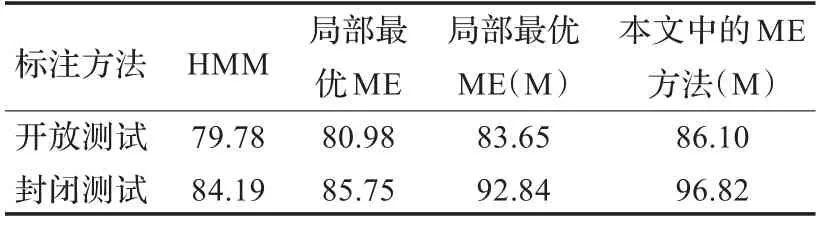
表4 标注结果准确率比较 (%)
表4中(M)表示使用经过本文语料预处理所得的语料。这里的结果并未对最大熵模型在其他语言中词性标注的结果作对比,不同的语言、不同的语料标注以及词性标注集的大小等都会对模型的标注结果产生一定的影响,因此这里仅对本实验室相同语料下的不同标注方法作了结果对比。由结果可以看出加入部分确定性词性后标注准确率有了明显的提高,这主要是因为部分词的标注过程中可以用到后一个词的词性特征(如果其后一个词的词性是预先标注好的),这是一般最大熵模型不会用到的特征。使用本文中的标注方法后准确率相比局部最优的最大熵也有提高,本文的方法中考虑到了词性标注序列的整体最优,当然这增加了时间复杂度,但是这里可以设置取每个词的最优前n个词性,既照顾了整体的最优,又不会过多地增加模型的时间、空间复杂度。
5.3 错误分析
由实验数据可以看出准确率仍有很大的提升空间,经分析标注错误主要来自以下几个方面:
(1)词法分析中的错误产生的积累,即词干提取、词缀的切分错误在词性标注中的影响。因为词干、词缀作为模型的原子特征,其中词缀或词干的错误造成了词性标注的错误。
(2)专有名词、固定词组标注错误。习语、固定词组和专有名词的构成不完全符合语法规则而且这些词出现次数又极少,对其中的词标注词性时常规特征概率较大,系统对这些词组中的词按一般词进行标注,因而出现错误。
(3)组合词的标注错误。未登录词在词性标注中是一个难点,哈语中未登录词的一大部分是组合词,即两个或两个以上的词用下划线连接组成新的词如(玩笑),这些词不能很好地确定其词干、词缀等,数据稀疏加上本身的特征信息又少,此类词标注的正确率也就不高。
6 结束语
本文使用最大熵模型进行哈萨克语的词性标注,在语料预处理中对有唯一确定词性的词进行了预先标注,增加了可以利用的上下文特征;改进了标注算法,在计算量不过多增长的同时考虑了词性序列的整体最优化,提高了词性标注的准确率。实验结果表明开放测试的准确率仍然有很大的提高空间,原因在语料的预处理阶段中,词干、词缀的自动切分正确率不是很高、专有名词等未能提前处理,在接下来的工作中可以考虑从提高词干切分的准确率、预先识别专业名词等方面来提高整个系统的标注准确率。
[1]买合木提·买买提.基于统计的维吾尔语词性标注研究与实现[D].乌鲁木齐:新疆大学,2009.
[2]Ratnaparkhi A.A maximum entropy model for part-of-speech tagging[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,1996:133-141.
[3]Zhao Yan,Wang Xiaolong.Applying class triggers in Chinese POS tagging based on maximum entropy model[C]// The 3rd InternationalConference on Machine Learning and Cybernetics,Shanghai,2004:1641-1645.
[4]达吾勒·阿布都哈依尔,古丽拉·阿东别克.哈萨克语词法分析器的研究与实现[J].计算机工程与应用,2008,44(19):146-149.
[5]刘艳,古丽拉·阿东别克,伊力亚尔.哈萨克语词性自动标注研究初探[J].计算机工程与应用,2008,44(20):242-244.
[6]侯呈风,古丽拉·阿东别克.改进的HMM应用于哈萨克语词性标注[J].计算机工程与应用,2010,46(36):147-149.
[7]Darroch JN,RatcliffD.Generalized iterative scaling for log2 linear models[J].Analysis of Mathematical Statistics,1999,43(5):1470-1480.
[8]Pietra S D,Pietra V D,Lafferty J.Including features of random fields[J].IEEE Transactionson Pattern Analysisand Machine Intelligence,1997,19(4):380-393.
[9]Chen Jinying,Xue Nianwen,Palmer M.Using a smoothing maximum entropy model for Chinese nominal entity tagging[C]// Proceedingsofthe1st International Joint Conference on Natural Language Processing,Hainan Island,2004:493-499.
[10]RatnaparkhiA.Learning to parse naturallanguage with maximum entropy models[J].Machine Learning,1999,341(3):151-176.
[11]Berger A L,Della Pietra S A,Della Pietra V J.A maximum entropy approach to natural language processing[J]. Computational Linguistic,2002,22(1):39-71.
基于最大熵的哈萨克语词性标注模型
桑海岩1,2,古丽拉·阿东别克1,2,牛宁宁1,2
SANG Haiyan1,2,Gulia·Altenbek1,2,NIU Ningning1,2
1.College of Information Science and Engineering,Xinjiang University,Urumqi 830046,China
2.The Base of Kazakh and Kirghiz Language,Minority Languages Branch,National Language Resource Monitoring and Research Center,Urumqi 830046,China
Maximum entropy model can make full use of context,agilely take multiple characteristics.This paper uses maximum entropy model to part of speech tagging of Kazakh,designs feature template according to tackiness and rich shape,and joins the backward relying part of speech feature template.In this paper,the module is improved,which takes the previous n words of highest probability to join the characteristic vector of next word and so on until the end of the sentence,and finally it selects a probability optimal sequence of part of speech tagging.The results show that feature template choice is correct,and the improved model accuracy rate reaches 96.8%.
natural language processing;part-of-speech tagging;maximum entropy model;Kazakh
最大熵模型能够充分利用上下文,灵活取用多个特征。使用最大熵模型进行哈萨克语的词性标注,根据哈语的粘着性、形态丰富等特点设计特征模板,并加入了向后依赖词性的特征模板。对模型进行了改进,在解码中取概率最大的前n个词性分别加入下一个词的特征向量中,以此类推直至句子结束,最终选出一条概率最优的词性标注序列。实验结果表明,特征模板的选择是正确的,改进模型的准确率达到了96.8%。
自然语言处理;词性标注;最大熵模型;哈萨克语
A
TP391
10.3778/j.issn.1002-8331.1212-0193
SANG Haiyan,Gulia·Altenbek,NIU Ningning.Kazakh part-of-speech tagging method based on maximum entropy. Computer Engineering and Applications,2013,49(11):126-129.
国家自然科学基金(No.61063025)。
桑海岩(1982—),男,硕士,研究领域为自然语言信息处理;古丽拉·阿东别克(1962—),女,教授,博士生导师,研究领域为自然语言信息处理、人工智能等;牛宁宁(1988—),女,硕士,研究领域为自然语言信息处理等。E-mail:sang_haiyan@163.com
2012-12-17
2013-03-06
1002-8331(2013)11-0126-04
