区间树在DDM区域匹配中的应用
2013-08-04东北石油大学计算机与信息技术学院黑龙江大庆163318
东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318
东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318
1 引言
现代仿真应用已经从集中式仿真发展到了分布式交互仿真,分布式仿真技术作为一种重要的研究手段正广泛地应用于军事以及国民经济的各个领域[1],为了实现仿真应用的互操作性和资源的可重用性,美国防部提出了高层体系结构(HLA)仿真框架[2],HLA体系结构主要由3部分组成:HLA规则、HLA接口规范、HLA对象模型模板[3]。接口规范说明是对HLA的运行时间支撑系统RTI(Runtime Infrastructure)的接口规范的描述。RTI提供了一个通用的、相对独立的支撑服务程序,将仿真应用与底层的支撑环境分开,从而使各部分可以相对独立地进行开发。
数据分发管理DDM是RTI提供的六大服务之一[4],是RTI所提供的一类很重要的服务,其功能是实现数据的过滤,尽可能地减少不相关数据的产生,以减少网络带宽的占用,同时降低仿真接收冗余数据时引起的处理开销[5]。它是实现HLA/RTl的关键技术,也是实现大规模分布式交互仿真的可扩展性的重要手段。数据分发管理运用维(dimension)和区域(region)对数据进行过滤。更新成员利用一系列区域组成的更新区域集声明它要公布的信息,订购成员利用订购区域集来声明它感兴趣接收的数据,通过对公布区域集和订购区域集的匹配计算,RTI决定是否在发送者和接收者之间建立连接并传送数据,而且公布区域和订购区域都是动态变化的。因此,如何对公布区域集和订购区域集进行有效的组织管理是提高DDM过滤效率的有效途径[6]。
目前,比较常用的匹配算法有基于区域的完全匹配法。该算法采用区域直接匹配的方法,即每个公布区域必须和所有的订购区域进行匹配,判断区域是否相交。一旦公布区域或订购区域改变,RTI将重新进行区域匹配。该算法优点是实现简单,匹配精确,但是不适合大规模复杂系统中更新和订购区域数量都很大的情况[7]。基于网格的DDM算法是将路径空间均匀分隔成由格子组成的网格,每个格子的维数即路径空间的维数。订购与公布区域的匹配不是直接进行,而是通过每个成员将其公布和订购区域映射到路径空间的网格上,通过判断公布与订购区域是否覆盖了同一个网格来确定哪些区域是重叠的。该算法过滤计算开销低,但是会产生虚假连接以及冗余连接问题。而基于排序的匹配算法通过有序表的建立一次性将公布区域和订购区域的重叠区域匹配完,匹配精度高。但缺点是一旦更新区域时,都需要重新建立有序表,匹配效率降低。
2 DDM数据过滤流程
DDM的过滤流程主要包括以下四个步骤:
区域声明:在预先定义好的路径空间中,数据公布者在其中创建区域,利用数据分发管理提供的服务,向联邦声明产生数据的区域;数据订购者则创建区域,声明它需要的数据所在区域。
区域匹配:RTI根据公布者和订购者各自声明的区域,按规则进行匹配。一个订购区域和一个公布区域匹配成功,需要两个区域在每一维上的范围都有重叠时,整个区域才称为重叠,区域才能匹配成功。
建立连接:区域匹配成功后,根据区域匹配结果,在发送方和接收方之间建立数据连接,分配组播地址。
数据发送:将公布平台产生的信息通过网络传输给合适的接收成员,同时尽可能使冗余信息减少。
数据分发的四个步骤中,区域匹配算法直接影响着数据分发管理的过滤效率。而DDM过滤机制所要解决的问题就是如何对动态变化的公布区域和订购区域进行匹配计算,找出相重叠区域,以及如何高效地将重叠区域的数据分发到订购方。
3 基于区间树的DDM匹配算法
3.1 区间树的结构
区间树是一种扩展红黑树,红黑树是一种二叉查找树,但在每个结点上增加一个存储位表示结点的颜色可以是RED或BLACK。树中每个结点包含五个域:color,key,left,right,p。color为红黑状态,key为结点的关键字,left,right,p则分别指向结点的左儿子,右儿子及父结点。如果某结点没有一个子结点或父结点,则该结点相应的指针(p)域包含值为NULL,视为外结点,而把带关键字的结点视为树的内结点。
红黑树具有如下性质:
(1)每个结点或是红的,或是黑的。
(2)根结点是黑的。
(3)每个叶结点(NULL)是黑的。
(4)如果一个结点是红的,则它的两个儿子都是黑的。
(5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
区间树定义:设 Σ为n个半开区间的集合,并设这n个区间的边界值取自集合U={x1<x2<…<xv},即 Σ={[li,ri),其中 li,ri∈U,li<ri,1≤i≤n}。关键字为区间的低端点 li。基于U对Σ构造的区间树是一棵平衡二叉树T[8],T中有V个叶结点以及一些双向链表。每个叶结点代表来自U的一个元素。所有非叶结点u用一个分裂值max(u)进行标记,若某查询到达该点,max(u)就作为一个判别值,以判断查找应沿结点的哪个分支继续。图1说明了区间树是如何表示一个区间集合的。

图1 一棵区间树
区间树是一种完全动态的空间索引数据结构,插入、删除和查询可同时进行,并且不需要周期性的索引重组。区间树支持由区间构成的动态集合的操作,它能保证在最坏的情况下,时间为O(lgn)。
3.2 区间树的DDM区域匹配算法实现
DDM匹配算法的核心问题是判断公布域和订购域是否重叠,其实质是矩形的相交问题。区间树是一种基于多维的空间索引技术,最早是为了提高空间数据库的查询效率。多维空间结构的匹配(相交)查询是其基本服务之一,这就为DDM匹配算法的实现提供了理论基础。
3.2.1 ITBM算法原理
算法的基本思想是:在定义好的路径空间上,经过映射,建立多维坐标系统,将公布区域集合与订购区域集合的相同维的坐标值,按照从小到大的顺序排列,区域的低边界与高边界构成一个区间,在同维坐标系统中,形成区间集。从此区间集中选择公布区域区间构建公布区间树,在区间树上进行搜索匹配,找出公布区域和订购区域重叠的区间结点。若存在公布与订购区域在所有公共维上都发生重叠,则此公布区域与订购区域有相交部分,匹配成功,否则公布区域与订购区域没有相交部分,匹配失败。以图2举例说明。
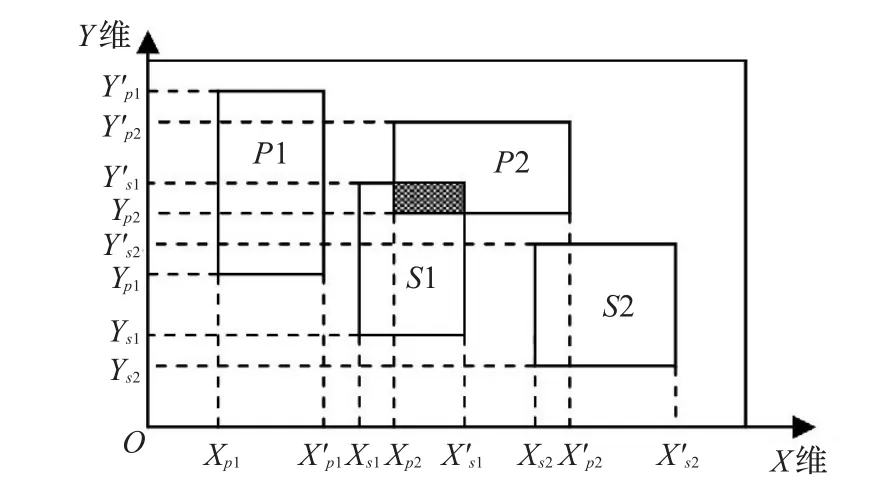
图2 二维坐标系统中区域分布示意图
如图2,在二维坐标系统的路径空间中,公布区域为分别P1,P2,订购区域分别为S1,S2。在X维上,公布区域范围分别为 P1(5,12),P2(16,28),订购区域的范围分别为S1(14,21),S2(26,34);在Y维上,公布区域的范围分别为P1(10,22),P2(14,20),订购区域的范围分别为S1(6,16),S2(4,12)。首先将区域范围映射到区间集上。图3为X维上范围映射的区间集。根据公布区域的区间集构建公布区域的区间树。

图3 公布区域与订购区域的区间集
3.2.2 区间树的操作
ITBM算法要完成路径空间的映射,区间树的建立、更新及搜索。初始时,建立一棵空区间树,然后将公布区域或订购区域的区间集逐一地加入到此区间树中,仿真运行过程中,动态地对区间树进行维护,删除无效的区域,插入更新的区域,并在区间树中搜索出相匹配的公布区域和订购区域。
在对区间树进行操作时,树的结构会发生变化,为了保持区间树的红黑性质,就要改变树中的某些结点的颜色以及指针结构。
区间树的区域匹配算法操作主要有以下几种:
(1)区间树的旋转(RotateValtree())
树中的指针结构的修改是通过旋转来完成的,这是一种能保持二叉查找树性质的查找树局部操作。图4给出了两种旋转:左旋和右旋。
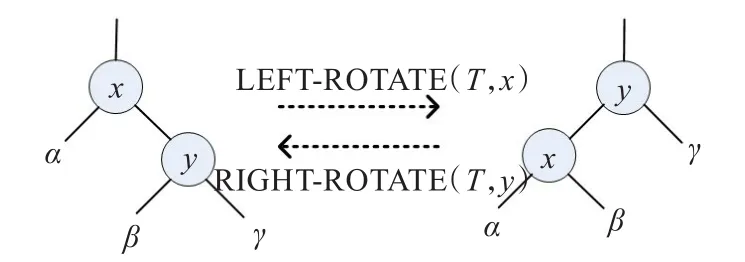
图4 区间树的旋转操作
如图4所示,左旋操作 LEFT-ROTATE(T,x)通过改变常数个指针来将左边两个结点的结构转变成右边的结构。右边的结构可以使用相反的操作右旋RIGHT-ROTATE(T,y)来转变左边的结构。字母α,β以及γ代表任意的子树。旋转操作保留二叉查找树的属性;α的关键字在key[x]之前,key[x]又在β的关键字之前,β的关键字在key[y]之前,key[y]在γ的关键字之前。左旋和右旋都是在O(1)时间内执行。在旋转时只有指针被改变,而结点中的所有其他域都保持不变。
(2)区间树的插入(InsertValtree())
在区域的动态匹配过程中,区域可能会随时间而变化,此时,其所映射的区间也同时发生了变化,要将新的区间结点加入到区间树中,任何一个即将插入到已有区间树的新结点的初始颜色都应为红色。因为插入黑点会增加某条路径上黑结点的数目,从而导致整棵树黑高度的不平衡。但如果新结点父结点为红色时,将会违反红黑树性质:一条路径上不能出现相邻的两个红色结点。这时就需要根据以下几种情况,通过一系列旋转操作来使红黑树保持平衡。插入操作分为以下几种情况:
情况1:新结点位于树的根上,没有父结点。
情况2:新结点的父结点是黑色。
情况3:新结点的父结点及其叔叔结点都为红色。
情况4:父结点是红色,叔叔结点是黑色或叶结点。
情况5:父结点是红色,而叔父结点是黑色或者是叶结点。
含n个结点的区间树的高度为O(lgn),因而区间树的插入要花O(lgn)时间。
(3)区间树的删除(DeleteValtree())
DDM仿真系统中的公布区域和订购区域是不断变化的,所以需要删除区间树原有的无效区域,动态地对区间树进行维护。删除操作中真正被删除的必定是只有一个红色孩子或没有孩子的结点。如果真正的删除点是一个红色结点,则它必定是一个叶子结点。和区间树的插入操作一样,对区间树中的一个结点的删除要花O(lgn)时间。
(4)区间树的匹配搜索(SearchValtree())
动态区间树的匹配搜索是在区间树中搜索出公布区域与订购区域中相重叠的区域。匹配搜索的步骤为从根结点开始,逐步下降。将搜索区间的低端点与区间树中的结点的关键字比较,如果小于结点关键字,则需搜索左孩子结点与右孩子结点,如果大于结点关键字,则只搜索右孩子结点即可。当找到一个重叠区域后,将其存储,并沿着此结点继续搜索至叶子结点,最后查找出相匹配的所有公布区域。因为基本循环的每次迭代要花O(1)时间,又含n个结点的红黑树的高度为O(lgn),所以区间树的搜索过程的时间为O(lgn)。搜索算法从根结点向下搜索公布区域的区间树,根据匹配的结果,结点下的子树可能需要被搜索,在任意结点上,如果不重叠,则搜索总是沿着一个安全的方向前进的:如果树中确有重叠的区间,则该区间必定会被找到。因此,通过对区间树的动态维护,算法总体的搜索速度与性能都是良好的。
4 仿真实验及结果分析
4.1 仿真实验
影响DDM匹配算法效率的主要因素有限域的总数、区域的平均限域数和区域重叠率[9]。区域的数目又决定了限域的总数,因此,区域的数目在仿真效率中起着重要的作用。而重叠率与限域的数量以及限域的平均尺度有关,重叠率的大小直接决定着与给定矩形相交的矩形数量的多少。
在匹配算法中,限域总数与重叠率变化的情况下,基于区域的完全匹配法没有一种有效的方式对联邦中的公布区域和订购区域进行组织管理。虽然排序法和网格法具有良好的总体性能,特别是当重叠率提高的情况下,排序法的效率下降得比较平缓。但是网格法中对于网格的划分却是项非常困难的工作,特别是当矩形在空间中分布不均的情况下,如果根据网格分配组播组,将导致网络流量传输得严重不稳定。排序法虽然在各种情况下性能最为稳定,但它的动态维护代价较高,仅适用于静态DDM。而区间树法正好克服了上述几种方法的缺陷,可以保证目标数据对象在树结点中的均衡分配,同时具有较高的动态维护性能。
在仿真实验中,通过区域数目和重叠率的变化考察了ITBM算法的插入、匹配、动态维护等性能。图5为区间树构造时间随重叠率的变化趋势图。图6为平均搜索时间随重叠率的变化趋势图。

图5 构造时间随重叠率的变化趋势
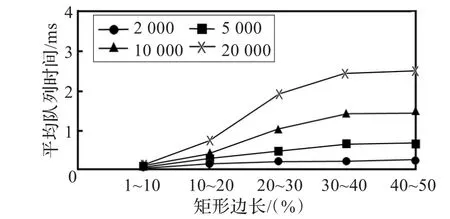
图6 平均搜索时间随重叠率的变化趋势
仿真实验在Windows XP平台上进行,CPU 2.5 GHz,内存为1 GB。在1 024×1 024的二维路径空间中,随机生成500,1 000,2 500,5 000,10 000个矩形区域,根据映射区间构建动态的区间树。由于排序算法稳定,所以,选定了排序匹配算法与ITBM算法分别从构造时间和搜索匹配速度进行了比较。排序法的具体步骤参见文献[10]。
图7为基于排序的区域匹配算法与ITBM算法的构造时间的比较。图8为两者的平均搜索时间的比较。
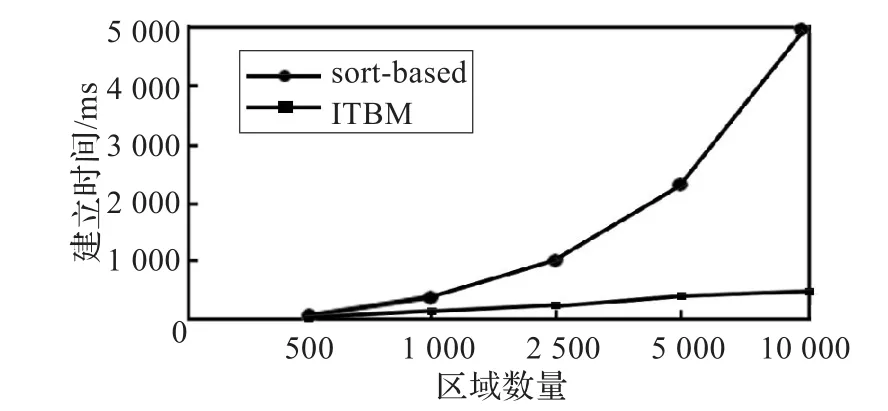
图7 排序法和区间树法构造时间的比较

图8 排序法和区间树法平均搜索时间的比较
4.2 实验结果分析
决定匹配算法效率的关键因素中的重叠率,其直接决定因素是矩形的边长和公布域矩形的数量。如图5和图6所示。图中矩形边长在一定范围内随机产生,如图中的横坐标“1~10”是指矩形边长在坐标空间边长中的比例在1%~10%之间。平均搜索时间为随机生成的1 000个订购矩形的平均搜索时间值。由图5可知,给定公布域,ITBM的构造时间受矩形边长的影响不大;由图6可知,平均搜索时间随边长的增加而增大,但是矩形边长为40%~50%的20 000个公布矩形构成的区间树的平均搜索时间不到3 ms,可见ITBM算法在重叠率和公布矩形数量很大的情况下同样具有较好的匹配效率。
公布域的修改是由区间树的插入和删除操作共同完成的。插入操作的性能可由图5中区间树的构造时间考察。同时,对矩形的删除性能也做了相关实验,虽然删除矩形的平均时间波动较大,但是平均删除时间不超过3 ms,因此,可以满足实际仿真应用中的需求。
从图7中可以看出,排序法的构造时间随着区域数量的增加而上升,且上升趋势明显高于ITBM算法的构造时间。排序法虽然在各种情况下性能最为稳定,但其动态维护代价较高,每次区域更新都需要重新建立有序表,且构建的代价又是巨大的,而ITBM算法只需动态地插入或删除更新区域的结点即可。在图8中,排序法的匹配搜索时间随着区域数量的增加逐渐上升,而ITBM算法的搜索匹配在区域数量达5 000之后开始趋于平稳,因此ITBM相对于排序法来说,在构建及动态维护上,都要优于排序法,且更适合大规模的仿真演练。
5 小结
影响DDM效率的关键问题是匹配算法的实现。本文提出了一种动态的基于区间树的DDM区域匹配算法,研究了算法的基本原理和实现方法,通过区间树的建立及更新实现对区域的动态组织管理,并通过实验验证了其优于传统区域匹配算法排序法的性能。结果表明ITBM算法是一种高效的动态匹配算法。以此为基础,会进一步研究分布式环境下的ITBM算法的实现和优化策略。
[1]张贵生,张霞,李德玉.基于权重函数的混合DDM算法[J].计算机工程与设计,2008,29(4):797-799.
[2]Boukerche A,Dzermajko C.Scalability and performance evaluation of an aggregation/disaggregation scheme for data distribution managementin large-scale distributed interactive systems[C]//Proceeding of the 37th Annual Simulation Symposium.Washington,DC,USA:IEEE Computer Society,2004:238-244.
[3]周彦,戴剑伟,蒋晓原.HIA仿真程序设计[M].北京:电子工业出版社,2002.
[4]Petty M D,Paterson D J.Data distribution management issues for HLA implementations[C]//Proceedings of the Spring 2000 Simulation Interoperability Workshop.Orlando FL:SISO,2000.
[5]Lu Tainchi,Lee Chungnan,Hsia Wenyang,et al.Supporting large-scale distributed simulation using HLA[J].ACM Transactions on Modeling and Computer Simulation,2000,10(3):268-294.
[6]王磊,张慧慧,李开生,等.基于动态R_树结构的DDM区域匹配算法[J].计算机工程,2008,34(3).
[7]张霞,黄莎白.高层体系结构中DDM实现方法的研究[J].系统仿真学报,2003,15(5):670-673.
[8]Manolopoalos Y,Theodoridis Y,Tsotras V J.Advanced database indexing[M].Boston:Kluwer Academic Publishers,1999:61-81.
[9]Petty M D,Mukherjee A.Experimental comparison of d-rectangle intersection algorithms applied to HLA data distribution[C]// Proceedings of the 1997 Distributed Simulation Symposium,Orlando FL,1997:13-26.
[10]Yu Jun,Raczy C,Tan G.Evaluation of sort-based matching algorithm for the DDM[C]//The 16th Workshop on Parallel and Distributed Simulation,Washington,USA,2002.
区间树在DDM区域匹配中的应用
尚福华,张海波,解红涛
SHANG Fuhua,ZHANG Haibo,XIE Hongtao
School of Computer and Information Technology,Northeast Petroleum University,Daqing,Heilongjiang 163318,China
Data Distributed Management(DDM)is the effective method to reduce network redundant data,region matching algorithm is the key of data distributed management.The current variety of matching algorithms such as direct matching method,the grid method,sorting method are insufficient ideal because of the poor filtration or long time-consuming.Through the fully research of data filtering mechanism,the region matching algorithm based on interval-tree—ITBM is proposed,which is mapped range to an interval,uses the interval trees to store the area range,through the direct operation of interval-tree to complete matching work.The results show that ITBM can greatly reduce the time of matching calculations,effectively save the cost of matching process of dynamic DDM.
data distributed management;region matching;interval-tree
数据分发管理(DDM)是降低网络冗余数据的有效手段,区域匹配算法又是数据分发管理实现的关键。当前的多种匹配算法如直接匹配法、网格法、排序法等效率都不够理想,或者过滤效果不佳,或者耗时较长。通过对数据过滤机制的深入研究,提出了基于区间树的区域匹配算法——ITBM算法,该算法将范围的上下界映射到一个区间内,使用区间树来存储区域范围,通过对区间树的直接操作来完成匹配工作。结果表明,ITBM算法大大减少了匹配计算的时间,有效地减少了动态DDM的维护开销。
数据分发管理;区域匹配;区间树
A
TP391.9
10.3778/j.issn.1002-8331.1110-0299
SHANG Fuhua,ZHANG Haibo,XIE Hongtao.Application of interval-tree in region matching for DDM.Computer Engineering and Applications,2013,49(11):110-113.
国家自然科学基金(No.61170132)。
尚福华(1962—),男,教授,研究方向为人工智能、机器学习、数据挖掘、虚拟现实、图像处理等。
2011-10-17
2012-01-16
1002-8331(2013)11-0110-04
CNKI出版日期:2012-03-08 http://www.cnki.net/kcms/detail/11.2127.TP.20120308.1521.047.html
