基于双词典机制的中文分词系统设计
2013-07-19李玲
李 玲
(中北大学 电子与计算机科学技术学院,山西 太原 030051)
1 中文分词及分词算法概述
对于中文来说,中文字符串可逐步细化为段、句、词、字。字、句和段能通过明显的标点符号分界符来简单划界,也易于让机器“看”,只有词需要用分词算法来划分,即中文分词。现有的分词算法可分为3大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[1]。基于字符串匹配的分词方法是按照一定策略将待分析汉字串与词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。该方法需要确定三个要素:词典、扫描方向、匹配原则[2]。基于字符串匹配的分词方法原理简单,实现相对容易,并能达到较高的准确度,是最常用的分词策略,缺陷是容易产生歧义切分。词典是字符串匹配的分词方法中很重要的基础部分,因此该方法又称为基于词典的分词方法。
2 双词典设计
目前有三种典型的中文自动分词词典机制,分别是基于整词二分的词典机制、基于TRIE索引树的分词词典机制和基于逐字二分的分词词典机制[3]。整词二分法是一种广为使用的分词词典机制[4]。本设计采用一种双词典机制,它由改进的整词二分法标准词典、辅助的临时词典和临时高频词表三部分组合而成。
2.1 标准词典
2.1.1 首字散列表
词条首字用散列表来存储。国家标准规定,汉字编码中汉字的区位码值从16区开始到87区,每区94位,标识6 763个汉字。即每个汉字都有唯一的区位码。汉字的机内码通过编程很易获取,又有机内码与区位码换算公式如下:
机内码高位=区码+0xA0,
机内码低位=位码+0xA0。
若区位码表示为十六进制数,其中区码为区位码的前两位,位码为区位码的后两位。据此特点,可用散列表方式来存储词条首字,实现首字的迅速定位。根据机内码与区位码及数组特点,设散列函数为(ch1-0xB0)*94+ch2-0xA1,其中ch1为机内码高位,ch2为机内码低位。首字结点设计见表1。

表1 首字结点结构表
2.1.2 词索引表
根据统计,汉语词语中二字词占大多数,有3万多,其次是三字词和四字词,都是3千多,五字词及以后则很少。所以二、三、四字词的查询效率直接影响分词速度。为提高查询效率,本词索引表结点具体设计见表2。

表2 词索引表结点结构表
若要匹配的词为二字词,从“二字词起始位置”到“三字词起始位置”间进行查询。以此类推。
2.1.3 标准词典正文
标准词典正文为线性表结构,存储每个词条中除首字外的字串,以及通过语料库学习后统计出的该词条的总词频。字串与总词频间用“/”间隔,字串间用空格作为间隔。
对同一首字的词条,首先按词条的字数顺序排列,同长度词条则按次字的区位码排序,以此类推。首字已在首字散列表中确认,故不需要再存储。例如:首字为“中”的标准词典词索引表及部分正文如图1所示。其中,各字的区位码见表3。
2.2 临时词典
在人们用语言进行交际活动时,语言成分的使用呈现一定的规律性,因此可以采用统计方法对其进行研究统计,这就是互信息原理。从形式上看,词是稳定的字的组合。因此在上下文中,相邻字出现的次数越多,就越可能构成一个词。因此字与字相邻共现的频率能够较好地反映成词的可信度[5]。基于此论断,本设计中增加一个临时词典,用于存储待分析文本中出现的二字词、三字词、四字词及其在本文的词频,以便处理分词歧义。我们所用的绝大部分词都是四字以下词,所以不考虑四字以上出现的新词。
临时词典结构类似标准词典,仍使用首字散列方式设计,但不再需要词索引表,直接是词典正文,首字结点结构见表4。该首字散列表格式类似标准词典格式,区别在于最后一个数据项,此处为指向以该字为首的词典正文第一位。临时词典的词典正文结构见表5。

图1 “中”词索引表结点结构及词典正文结构图

表3 字区位码表

表4 临时词典首字结点结构表

表5 临时词典的词典正文结构表
比如以“诺”为首的字,其词典正文为“2基102/3基亚102/4基亚手27/”。说明待分析文本中以“诺”为首的词有“诺基”、“诺基亚”、“诺基亚手”三个词。“诺基”词长为2,词频为102;其他以此类推。
2.3 标准词典更新
扫描临时词典,若某词的出现频率极高,词密度极大,且未被标准词典收录,则将该词增入标准词典及用于构造标准词典的原始数据中,总词频为该词在本文本中词频。词密度公式为:
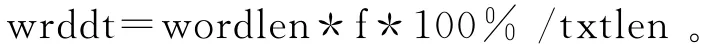
其中:wrddt为词密度;wordlen为词长度;f为词频;txtlen为待划分文本长度。
通过统计,本设计将词密度临界值设置为0.5%。若某词的词密度≥0.5%。则将其加入标准词典中。
2.4 临时高频词表
为提高分词正确率,加入一个临时高频词表。将临时词典中词密度≥0.1%的词存入一个高频词表中,以便分词时使用。高频词表为线性表。
3 扫描方式、匹配原则及歧义处理
3.1 扫描方式和匹配原则
本设计使用基于词典机制的分词算法,它的核心思想是切分出单字串,然后和词库进行比对,如果是一个词就记录下来,否则通过增加或者减少一个单字,继续比较,直到还剩下一个单字则终止,如果该单字串无法切分,则作为未登录处理。按照扫描方向不同,该方法分为正向匹配和逆向匹配。本设计同时使用正向最大匹配算法和逆向最大匹配算法即双向最大匹配算法进行分词。
3.2 歧义处理
3.2.1 匹配法无关歧义处理
汉语句子中,连续的三个单字概率非常小。因此,对于一个字串,若分词结果中存在连续的三个或三个以上单字,意味着可能出现分词错误。这时,对这些连续单字组成的词,查询临时高频词表。若存在,将其划分为词。
3.2.2 匹配法相关歧义处理
对于一个字串,若正向最大匹配法与逆向最大匹配法分析的结果不同,说明出现歧义,在此使用临时词典机制与标准词典协同对其处理。首先,获取两种匹配法分词结果不同处的词语(为说明方便,用A、B两字符模糊代表两种匹配法);然后根据分词结果不同处的词语的特点按下述方式处理:①分别查询“分词结果不同处的词语”是否存在于临时高频词表中,若存在,则将含有高频词的分词结果作为最终分词结果,歧义处理结束,若不存在,转下一步处理;②对“分词结果不同处的词语”查询临时词典,若A匹配法中分词结果不同处的某词的词频较B匹配法中所有分词结果不同处的词频都呈量级差别,则取A匹配法的分词方式为最终结果,歧义处理结束,否则,转下一步处理;③对“分词结果不同处的词语”查询标准词典,若A匹配法中所有不同词的词频和大于B匹配法中所有不同词的词频和,则取A匹配法的分词方式为最终结果,歧义处理结束。
4 实验结果及分析
以上述理论为基础,在VC++6.0开发环境下,实现了一个中文分词系统。这里应用3个txt文档作为测试数据,分别采用本双词典机制中文分词系统和普通词典机制的中文分词系统对3个txt文档进行分词,分词结果统计见表6。
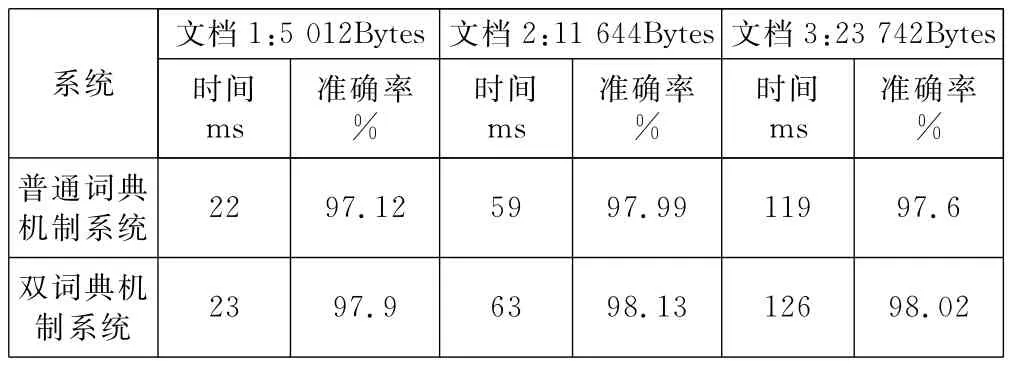
表6 分词结果统计表
由分词结果统计可见,本双词典机制中文分词系统准确率较高,但花费时间要多一些。准确率较高说明双词典机制在处理歧义上起到了一定的作用,是合理有效的一种方法,这是我们可继续深入研究的一个切入点。时间花费多与分词过程中双向最大匹配算法的使用有很大关系,因此,在不影响准确率的前提下,如何通过改双向最大匹配算法为逆向最大匹配算法从而提高本分词算法的时间性能将是后续要探讨的课题。
[1]付年钧,彭昌水,王慰.中文分词技术及其实现[J].软件导刊,2011,10(1):18-21.
[2]奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,55(2):43-47.
[3]柴宝杰.中文自动分词若干技术的研究[D].秦皇岛:燕山大学,2007:56-57.
[4]费洪晓,胡海苗,巩燕玲.基于Hash结构的机械统计分词系统研究[J].计算机工程与应用,2006,42(5):163-165.
[5]朱晓娟,陈特放.词频统计中中文分词技术的研究[J].仪器仪表用户,2007(3):78-79.
