支持向量机在低信噪比语音识别中的应用
2013-07-11张雪英刘晓峰
郭 超,张雪英,刘晓峰
1.太原理工大学 信息工程学院,太原 0300242.太原理工大学 理学院 数学系,太原 030024
支持向量机在低信噪比语音识别中的应用
郭 超1,张雪英1,刘晓峰2
1.太原理工大学 信息工程学院,太原 030024
2.太原理工大学 理学院 数学系,太原 030024
语音识别技术的目的是使计算机能听懂人类的语言,实现人机语言通信,方便自然快捷地操作计算机。传统的语音识别模型,如隐马尔可夫模型(Hidden Markov Models,HMM)和人工神经网络(Artificial Neural Network,ANN)都是基于统计学理论的,只有当训练样本集充分大时,识别性能才会最好。但实际问题中样本数目有限,因而实际应用中往往难以达到理想的效果。
支持向量机是20世纪90年代中期兴起的一种模式识别方法,其理论基础是统计学习的理论(Statistical Learning Theory)中的结构风险最小化(Structural Risk Minimization)原理和VC(Vapnik-Chervonenkis)维理论。与HMM、ANN等传统的模式识别方法相比,SVM能较好地解决小样本、过学习和局部极小点等实际问题,具有更好的泛化能力和分类精确性。
支持向量机具有很强的非线性分类能力。它通过引入核函数(需满足Mercer条件),将输入空间的非线性划分问题转化为高维特征空间的线性划分问题,有效解决了有限样本条件下构建高维数据模型的问题[1]。此外,采用核函数计算代替了高维空间中的内积计算,避免了因维数升高而导致的计算困难,从而简化了计算。利用不同的核函数,可以构造不同的支持向量机。
1 支持向量机
当训练样本集为线性近似可分时,需引入非负松弛变量ξi≥0,i=1,2,…,l,上述最优分类超平面的求解问题变为:
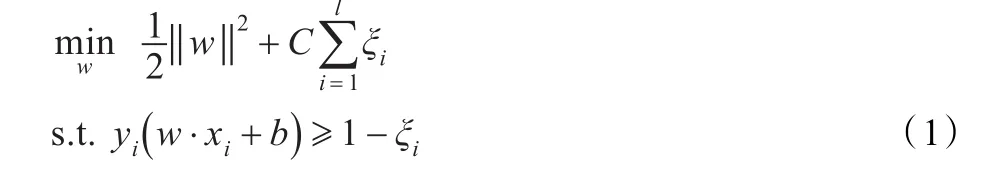
其中,C>0称为惩罚参数,C越大表示对错误分类的惩罚越大。引入Lagrange乘子法可以将上述最优化问题转化为一个二次规划对偶问题,即
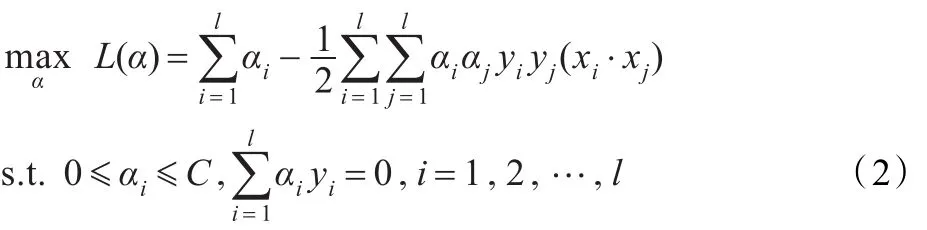
其中,αi为与第i个样本对应的Lagrange乘子,非零αi对应的样本点就是支持向量。对问题(2)求解后,可以得到相应的决策函数:
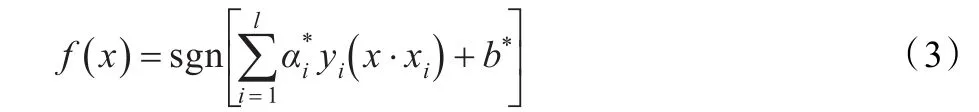
其中,α*i(至少有一个α*i≠0)为最优解,b*为分类阈值,x为待识别的样本。
对于非线性可分的数据集,可以通过一个非线性函数φ()·将训练集数据x映射到一个高维线性特征空间Z,其对应的决策函数变为:
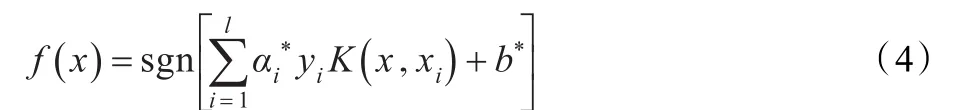
其中,K(x ,xi)=φ(x)·φ(xi)称为核函数,它是输入空间中的两个样本矢量映射到高维线性空间的像的内积,即用核函数来代替映射函数φ(·)的内积运算。因此,只需要知道核函数K(x ,xi)就可以确定一个支持向量机,而无需显式地知道特征空间Z和映射函数φ(·)。
目前常用的核函数有以下几种:(1)多项式核函数

(2)Gaussian径向基(Radial Basis Function)核函数

(3)Sigmoid核函数

2 语音识别系统
典型的语音识别系统包括预处理、特征提取和训练识别网络等三个部分。对语音信号的预处理主要包括反混叠失真滤波、预加重以及端点检测等内容。经过预处理后,对语音信号进行特征提取。将这些特征数据保存成特定的特征文件作为SVM的输入来进行训练和识别。
本实验预处理包括对原始语音信号进行预加重、加窗和分帧等处理。预加重通过一个传递函数为H() z= 1-αz-1( ) 0.9<α<1.0的滤波器进行滤波;加窗分帧选用Hamming窗。
经过预处理后,本实验提取改进的MFCC参数作为语音特征参数。传统的MFCC特征提取算法过程如下:语音信号在预处理分帧加窗后,通过离散傅里叶变换(DFT)得到其频谱,然后将语音能量谱通过一组Mel频率上均匀分布的滤波器,求出各个滤波器输出,对其取对数,并作离散余弦变换(DCT),即可得到MFCC参数。改进的MFCC参数是将Bark小波变换取代DCT,由此得到的Mel频率离散小波倒谱系数(Mel-Frequency Discrete Wavelet Cepstral Coefficients,MFDWCs)更符合人耳的听觉特性,鲁棒性更好[3]。MFDWCs特征参数经动态时间调整进行时间归一化处理后,得到统一的1 024维的语音特征矢量序列,即每个输入样本维数为1 024。改进的MFCC参数与传统的MFCC参数,利用SVM进行语音识别的结果见表1。
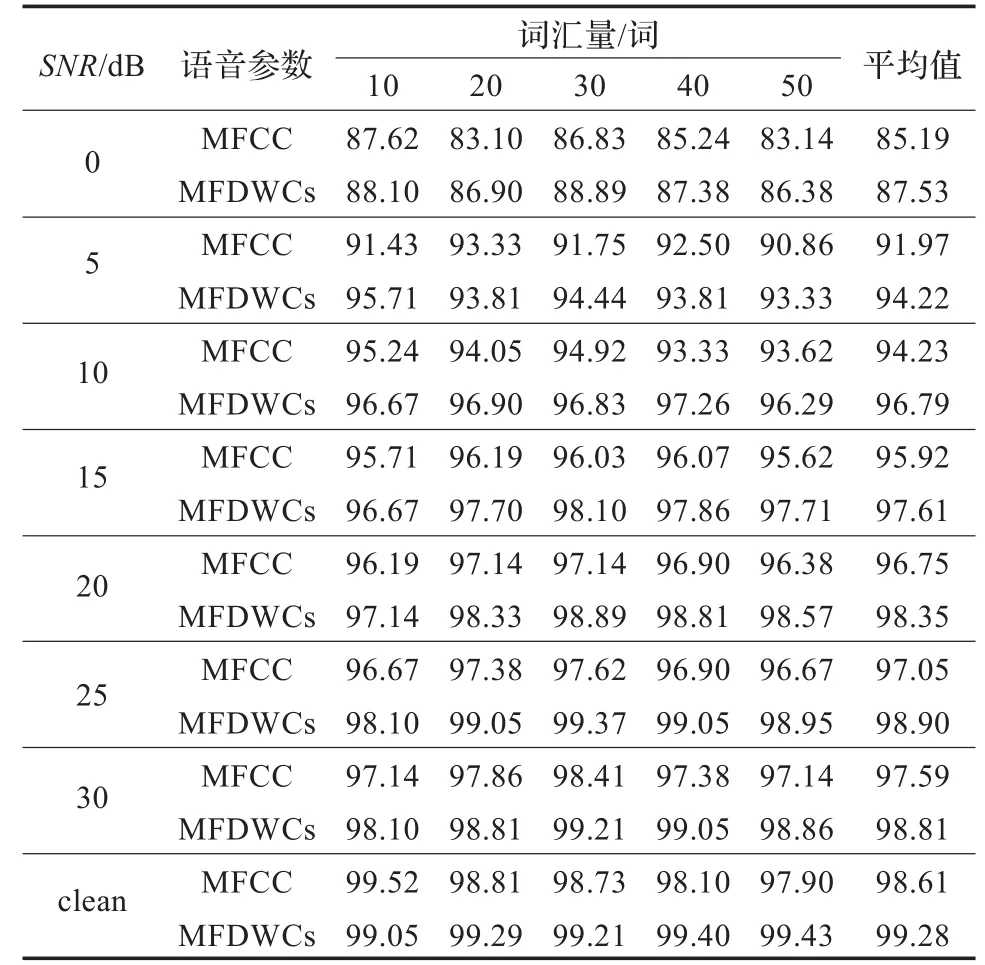
表1 改进的MFDWCs参数与传统MFCC参数识别率比较(%)
提取出语音特征参数后,对特征参数进行归一化处理。归一化的最大优点在于统一基本度量单位,这样可以避免同一维参数中,过大参数的权值作用掩盖掉较小参数的权值作用。此外,归一化还可以有效简化计算过程中的数值复杂度,加快收敛速度[4]。本文采用将参数值归一化到[-1,1]的最大最小线性归一法,对应公式为:
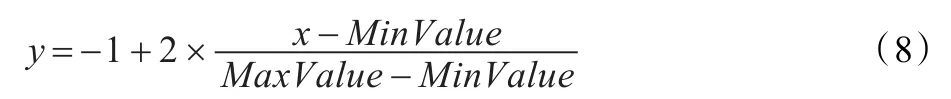
其中x和y分别为归一化前后的原始值和目标值,MinValue 和MaxValue为同一维属性中的最小值和最大值。
3 多类分类方法与实验环境
SVM本身是一个两类问题的判别方法。对于小词汇量的非特定人语音识别,需要将k个词汇分开( ) N>2。这是一个多类分类问题,因此涉及到多类问题到二类问题的转换。本实验采用一对一分类法来进行SVM多类分类[5],即在k个不同类别训练集中找出所有不同类别的两两组合,构建M=k( ) k-1 2个两类分类器。将待识别样本分别用M个SVM子分类器进行测试,统计在M个决策函数结果中各类别的得票数。最后,得票数最多的类别为该待识别样本的类别。若有两个以上类别的得票数相等且最多,则判定该待识别样本为标号最小的类别。
本实验使用9人在不同SNR(0 dB,5 dB,10 dB,15 dB,20 dB,25 dB,30 dB,无噪音)下的发音作为训练数据库,语音样本分别为10词、20词、30词、40词、50词韩语发音,且每人每个词发音3次。因此,整个数据库在不同SNR下分别有10、20、30、40、50个类别,对应的训练样本分别有270、540、810、1 080、1 350个。语音信号采样率为11.025 kHz,语音帧长为256点,帧移为128点。语音中的噪声为高斯白噪声。使用另外7人在相应SNR下的发音样本作为识别数据库。实验平台为VC++6.0,实验工具为开放源码的LIBSVM[4]。
实验中首先对SVM的惩罚参数C和Gaussian核参数γ利用网格搜索法进行参数寻优。将C分别取{20,21,22,…,214,215}等16个值,γ分别取{20,2-0.5,2-1,…,2-9.5,2-10}等21个值,使用这16×21对( ) C,γ组合分别利用训练数据库训练SVM,从而将在不同词汇量和不同信噪比情况下,综合识别率最高的( ) C,γ组合作为最终的SVM参数。实验最终选定的参数为(C ,γ)=(29,2-9),得到如表1的不同信噪比和不同词汇量下的识别准确率,并与基于RBF神经网络语音识别(输入的特征参数为相同的MFDWCs)结果作比较。
4 实验结果与结论
从表2中可以看到,基于SVM识别网络的语音识别系统比基于RBF人工神经网络更高的识别准确率。在0~30 dB以及纯净语音的情况下,SVM的平均识别率均高于RBF人工神经网络的识别率。特别是在0 dB、5 dB低信噪比的情况下,SVM的识别率分别为87.53%、94.22%,而RBF的识别率分别为82.14%、91.98%,这表明SVM的识别精度下降比RBF要小很多,充分证明SVM具有非常良好的鲁棒性和泛化性能。图1是SVM与RBF在不同信噪比下的平均识别率的对比图。
本文主要研究了基于支持向量机的小词汇量语音识别系统。与RBF人工识别网络相比,特别是在低信噪比情况下,支持向量机具有更高的识别率。今后的工作中,需要进一步从理论上研究SVM具有优良抗噪性能的原因。此外,将对支持向量机在更大词汇量语音识别系统中的性能进行实验研究。
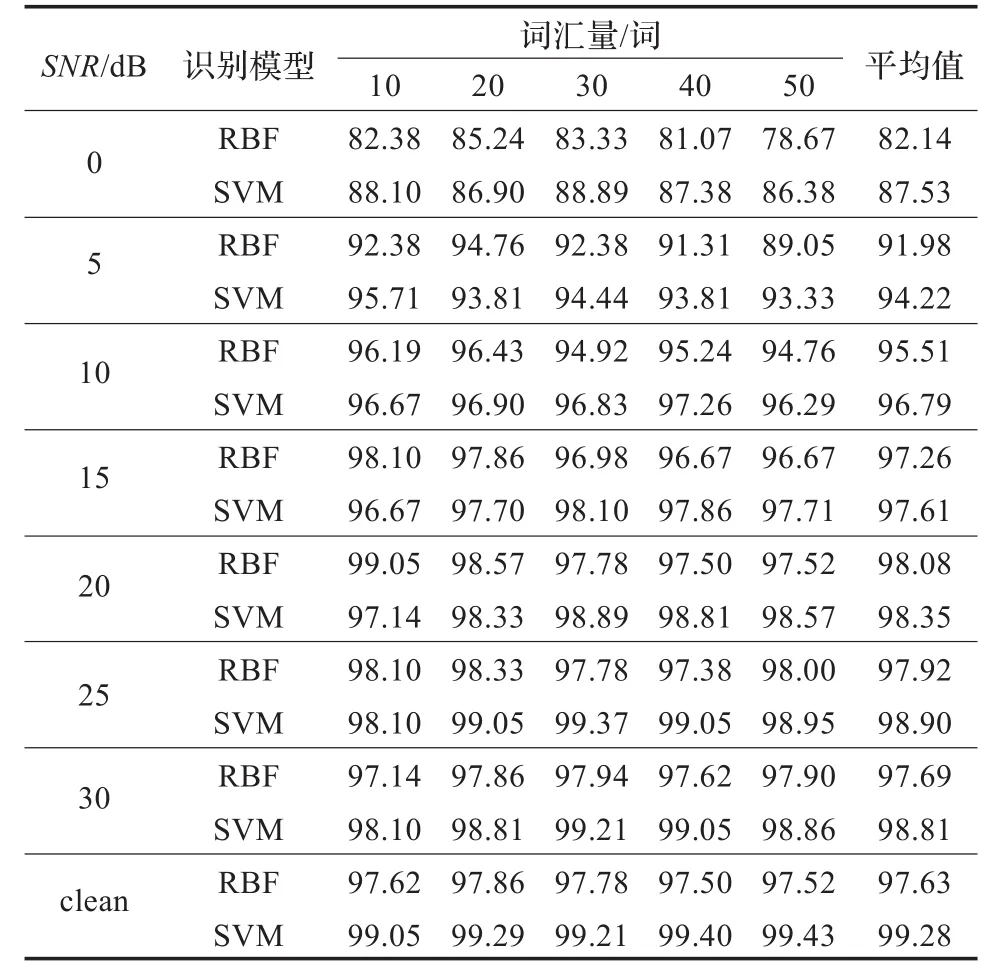
表2 不同信噪比下SVM与RBF识别准确率的比较(%)
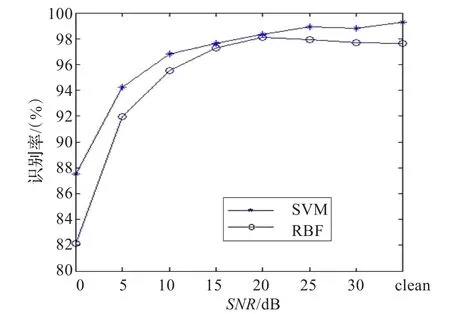
图1 SVM与RBF平均识别准确率的比较
[1]Vapnik V N.Statistical learning theory[M].New York:John Wiley and Sons,1998.
[2]邓乃扬,田英杰.支持向量机——理论、算法与拓展[M].北京:科学出版社,2009.
[3]Zhang Xueying,Bai Jing,Liang Wuzhou.The speech recognition system based on bark wavelet MFCC[C]//8th International Conference on Signal Processing.Beijing:[s.n.],2006:16-20.
[4]Chang Chih-Chung,Lin Chih-Jen.LIBSVM:a library for support vector machines[EB/OL].[2010-10-15].http://www.csie. ntu.edu.tw/~cjlin/libsvm.
[5]Hsu Chih-Wei,Lin Chih-Jen.A comparison of methods for multiclass support vector machines[J].IEEE Transactions on Neural Networks,2002,13(2).
GUO Chao1,ZHANG Xueying1,LIU Xiaofeng2
1.College of Information Engineering,Taiyuan University of Technology,Taiyuan 030024,China
2.Department of Math,College of Science,Taiyuan University of Technology,Taiyuan 030024,China
A low SNR speech recognition system for isolated words and non-specific speakers is constructed in this paper.Improved MFCC speech features(Mel-Frequency Discrete Wavelet Cepstral Coefficients,MFDWCs)are adopted and Support Vector Machines(SVM)is utilized as classification algorithm.The system obtains higher recognition accuracy,comparing to the results based on RBF Artificial Neural Network(ANN).The experimental results show SVM possesses better robustness than RBF ANN,especially in low SNRs.
support vector machines;Gaussian kernel;speech recognition;low Signal Noise Ratio(SNR)
采用改进的MFCC语音特征参数(Mel频率离散小波倒谱系数),使用支持向量机作为分类算法,构建了低信噪比环境下的孤立词非特定人语音识别系统,取得了较高的识别率。将实验结果与基于RBF神经网络的识别结果进行比较,结果表明在低信噪比时,SVM的识别率比使用RBF神经网络有较大提高,具有非常好的鲁棒性。
支持向量机;Gaussian核;语音识别;低信噪比
A
TN912
10.3778/j.issn.1002-8331.1107-0460
GUO Chao,ZHANG Xueying,LIU Xiaofeng.Application of support vector machines in low SNR speech recognition. Computer Engineering and Applications,2013,49(5):213-215.
国家自然科学基金(No.61072087)。
郭超(1987—),男,硕士研究生,主要研究领域为语音信号处理;张雪英(1964—),女,教授,博士生导师,主要研究领域为语音信号处理;刘晓峰(1979—),男,博士研究生,讲师,主要研究领域为智能算法、数值计算。E-mail:tyzhangxy@163.com
2011-07-22
2011-09-23
1002-8331(2013)05-0213-03
CNKI出版日期:2011-11-14 http://www.cnki.net/kcms/detail/11.2127.TP.20111114.0939.030.html
