一种低延时片上网络路由器的设计与实现
2013-06-23杜慧敏邓军勇
山 蕊,蒋 林,杜慧敏,邓军勇
(1.西安邮电学院 电子工程学院,陕西 西安 710061;2.西安邮电学院 研究生学院,陕西 西安 710061)
随着设计复杂度的提高,以总线为通信基础设施的SoC面临着全局连线增长、延迟增加、扩展性能变差、全局同步困难等问题,近些年来,学术界提出采用片上网络(Network on Chip,NoC)来解决SoC所面临的问题。 在片上网络的研究中,结点之间的通信延时一直是研究的热点,目前普遍采用虚通道流控机制来降低通信延时[1-2]。作为片上网络的核心部件包交换路由器,其设计直接影响整个NoC的通信效率。一般的路由器设计均采用流水线结构[3];文献[4]提出了预先路由的方法来降低路由器的流水线级数;文献[5]对虚通道(Virtual Channel,VC)分配和交换分配进行了改进,提出了并行VC分配和交换分配的策略;文献[6,7]对快速VC分配和交换分配的方法进行了详细的解释。本文在上述方法[5-7]的基础上,设计了一个具有快速VC分配和交换分配机制的低延时的片上网络路由器。在相同网络负载情况下,本文所设计的路由器能够极大降低片上网络的通信延迟,提高片上网络的通信效率。
1 相关研究
近年来,片上网络路由器作为SoC的重要基础部件,已经成为学术界研究的热点问题之一。大量文献中提出了各种片上路由器的实现机制,如文献[3]中提出了四级流水线结构的路由器:第一级流水线完成路由功能;第二级流水线完成虚通道(Virtual Channel,VC)分配功能;第三级流水线完成交换分配功能;第四级流水线完成数据包的物理链路传送功能。文献[4]中提出了一种两级流水线结构的路由器:第一级流水线进行预先路由和预测分配,预先选择一条最优的物理链路;第二级流水线进行数据包物理链路的传送。同时,该路由器中的路由算法采用自适应路由算法。文献[7]中提出了一种无流水线结构的路由器,该路由器采用预先路由,预测分配,快速分配,全响应,冲突检测等机制,使得该路由器能够在单时钟周期内完成数据包的转发功能。
文献[7]中指出资源预分配而产生的冲突情况只会出现在网络负载很轻的情况下,对于网络负载较重的情况下,全响应和冲突检测的功能则被闲置。因此,在文献[7]的基础上,本文提出的片上路由器去除了全响应和冲突检测的机制,对关键路径和设计模块进行了优化,提高片上路由器的工作频率,满足技术指标要求。
2 低延时路由器的设计
文中设计的低延迟路由器是单周期的路由器,总体结构如图1所示。路由器主要包括输入模块、虚通道(Virtual Channel,VC)分配模块、交换分配模块,交叉开关和输出模块。其中输入模块包含4个虚通道,每个虚通道由4个40位的数据片深度的FIFO构成;虚通道分配模块采用快速分配机制实现;交换分配模块采用快速交换分配机制;交叉开关和输出模块采用crossbar构成。为了降低数据转发的延时,在输入模块中采用了提前路由策略,VC分配和交换分配采用了并行机制和快速响应机制。路由器在单个时钟周期内完成整个路由转发过程,大大降低了数据转发的延迟,提高了网络性能。

图1 低延时路由器结构框图Fig.1 Implementation architecture of low latency router
2.1预先路由机制
路由的功能是根据本级路由器网络地址及目标网络地址,利用路由算法计算出本级应该输出的端口号。从流水线结构路由器[3-4]中我们可以看出,路由算法占用一级流水,只有完成了路由的功能后才能够进行后续的VC分配、交换分配以及物理链路传送。所以,降低流水线级数应该从路由算法开始。在本文的设计中,目标网络地址信息可以从数据中获得(与具体包格式有关),根据一定的编码规则,可以通过上一级路由器来完成本级的路由计算。这样,在本级所需要的路由信息在上一级路由器中可预先得到,并将路由计算结果随着数据一起下发到本级路由器。通过提前路由,可以减少路由器一级流水线,从而降低网络延迟。
2.2 VC分配和交换分配并行工作机制
在虚通道路由器的设计中,必须获得了下一级虚通道资源时才能进行交换分配。即交换分配等待VC分配的结果。VC分配是利用下一级路由器中虚通道的可用资源作为分配依据;交换分配是利用输出端口号来控制交换开关为交换请求分配输出带宽,VC分配和交换分配的计算并没有直接的关系,所以文献[5]提出了一种将VC分配和交换分配并行执行的算法,即假设VC是在已经分配好的情况下,对交换请求进行分配。
在并行执行的过程中,为了避免交换分配器在存在已经分配好VC的请求的情况下对等待VC分配的请求进行响应,文中将交换请求标记为2种请求:1)已经分配好VC号的请求;2)等待VC分配的请求。交换分配器只有在没有1)的情况下,才会对2)进行响应。而对于2)是否最终分配好VC号,则在数据进入交叉开关时进行检查。这样就可以将流水级数降低一级,从而进一步降低网络延迟。
2.3 VC分配和交换分配快速工作机制
虽然VC分配和交换分配已经并行执行,但是其仍然要占用一级流水,为了将整个路由器的流水级数降为一级即无流水线工作方式,必须将VC分配,交换分配及物理链路传送并为一级。文献[7]提出了一种快速VC分配和交换分配的工作机制,通过利用缓存在输入虚通道中数据片的信息,提前仲裁出下一个时钟周期对VC和物理链路资源的分配结果并暂存,当下一个时钟周期到来时,将缓存的分配结果和当前的请求信号进行相应的组合逻辑操作,快速的产生输入端口和物理链路所需的控制信息。
2.4 VC分配和交换分配内部模块说明
2.4.1 快速响应模块
VC分配模块的快速响应单元主要是利用当前VC请求和上一个时钟周期缓存的分配结果进行相应的组合逻辑操作,产生当前请求的响应信号,以及分配好的VC号。其工作过程为:当前请求信号到达VC分配模块后,与上一个时钟周期缓存的预先分配使能信号进行对应位(如虚通道1的请求信号对应于各个时能信号的最低位)的“与”逻辑操作,然后对各个操作结果,进行对应位(如所有操作结果的最低位)的“或”逻辑操作,操作的结果即为所要产生的响应信号。根据所请求的输出端口号,通过“多路选择电路”产生分配好的VC号。具体实现结构,详见图2。

图2 VC分配快速响应模块Fig.2 VC allocation fast response unit
交换分配模块的快速响应单元主要是利用当前交换请求和上一个时钟周期缓存的分配结果进行相应的组合逻辑操作,产生分配好的两级控制信息:第一级控制信号,用于产生从输入端口中请求输出的四个虚通道之间的仲裁信息;第二级控制信号,用于产生端口与端口之间的对于请求同一个输出端口的仲裁信息。需特别注意,对于某一个输出端口,两级控制信号应该能够同时得到响应。其工作过程为:当请求信号到达交换分配模块后,与上一个时钟周期缓存的第一级预先分配使能信号进行对应位(如输入端口1中虚通道1,2,3,4的请求信号对应于输入端口1的预先分配使能信号)的“与”逻辑操作,利用操作的结果,通过“多路选择电路”,选择出第一级允许输出虚通道所请求的端口,利用该端口号和第二级预先分配使能信号进行对应位的“与”逻辑操作,从而产生第二级控制信号。利用第二级控制信号和第一级“与”的操作结果,产生第一级控制信号。从而保证两级控制信号应该能够同时得到响应的要求。具体实现结构,详见图3。

图3 交换分配快速响应模块Fig.3 Switch allocation fast response unit
2.4.2 下一个时钟周期请求计算模块
此模块的主要功能是精确地计算下一个时钟周期所需要的请求信号(VC请求和交换请求),以便于预先分配器模块能够对计算出来的请求信号进行仲裁。
对于VC请求而言,我们利用当前请求信号,请求响应信号、下一个被缓存数据片是否头片信息和输出端口信息,精确的计算出下一个时钟周期是否会有VC请求信号,电路的实现结构详见图4。而对于交换请求信号,出于对时钟频率和设计复杂度的考虑,只是利用目标VC空/满状态来进行计算,电路的实现结构详见图5。

图4 计算下一节拍VC请求电路Fig.4 Computing next cycle’s VC request circuit

图5 计算下一节拍交换请求电路Fig.5 Computing next cycle’s switch request circuit
2.4.3 预先分配器模块
预先分配器模块主要由一组仲裁器构成,其能够在多个请求之间进行裁决,将目标资源分配给一个确定的请求,仲裁的原则我们采用轮循的方式。
2.5 时钟频率优化
如图6所示,该电路的关键路径:请求信号产生—>VC请求快速响应/交换请求快速响应—>输入端口选择输出数据片—>输出端口选择输出数据片。产生请求信号所需要的信息为输出端口号和VC是否分配信号,这些信号均可以提前一个时钟周期得到。为了提高时钟频率,将请求信号产生电路提前到上一个时钟周期,这样关键路径更新为:VC请求快速响应/交换请求快速响应—>输入端口选择输出数据片—>输出端口选择输出数据片,详见图7。为了进一步优化时序,减少不必要的译码电路,关键路径上的信号均采用独热码译码。由于减少了产生请求信号和电路进行译码所需耗费的时间,电路的时钟频率得到显著提高。
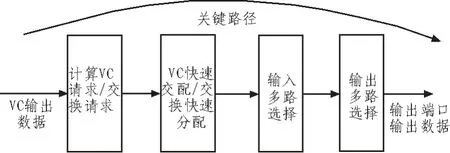
图6 关键路径Fig.6 Key path

图7 更新后的关键路径Fig.7 Improved key path
3 ASIC实现与测试
本文设计的低延时路由器芯片采用SMIC 0.13um Mixedsignal/RF 1.2V/3.3V工艺进行流片,其中核心逻辑采用基于标准单元的方法。由于SMIC的IO PAD最高支持27 MHz的时钟[8],故在芯片内部设计了一个中心频率260 MHZ,最高频率320 MHz的环振。因此整个芯片属于数模混合设计,芯片布局图如图8所示。

图8 路由器芯片布局图Fig.8 Layout of router chip
为了测试芯片功能的正确性,增加了必要的外围电路:流量产生器和数据包收集器。在300 MHz的工作频率下,采用软件控制寄存器配置,通过ARM LPC2214芯片产生读写配置寄存器时序,经串口发送给PC机,完成芯片性能的测试。测试结果如图9显示:当吞吐量较低时,数据包长度对于网络的平均延迟影响较小;当吞吐量较高时,数据包的片数决定了网络的平均延迟。数据包片数较少时,随着吞吐量的增加,网络平均延迟变化不大;当数据包的片数增加到一定程度,数据包网络平均延迟随着吞吐量的增加而急剧增加。
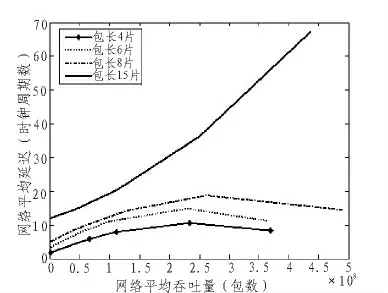
图9 芯片测试结果Fig.9 Test result of chip
4 结束语
与流水线结构的片上路由器相比,本文提出的路由器结构在一个时钟周期内完成数据片的传送,降低了网络延迟;同时,通过对关键路径的优化,时钟频率得到显著提高。与文献[7]中所提出的低延迟路由器相比较,考虑文献[7]中所提到的由于资源预分配而产生的冲突情况只会出现在网络负载很轻的情况下,对于网络负载较重的情况下,全响应和冲突检测的功能则被闲置,根据这样的情况,本文通过对电路的结构进行优化,去掉了文献[7]中的全响应和冲突检测的模块,这样不仅减小了电路规模,同时降低了电路实现的复杂度,但是其网络性能却没有降低。同时,通过对电路关键路径和部分内部模块(快速分配模块,仲裁器等)的优化设计,使得本文所设计的低延迟路由器,在所有输入端口在相同负载的情况下,可以稳定工作在300 MHz;在只有一个端口接收数据的情况下,时钟频率可以达到355 MHz。
[1]Salminen E,Kulmala A,Inen TDHML.Survey of Networkon-chip Proposals[C]//White Paper,OCP-IP,MARCH,2008.
[2]Brackenbury L E M,Plana L A.Jeffrey Pepper.System-on-Chip and Implementation[J].IEEE Transactions on Education,2010,53(2):272-281.
[3]Kumar,A.A 4.6 Tbits/s 3.6 GHz single-cycle NoC router with a novel switch allocator in 65nm CMOS[C]//Computer Design,2007:63-70.
[4]Kim J,Park D,T.Theocharides et al.A low latency router supporting adaptivity for on-chip interconnects[C]//The 42nd annual Design Automation Conference,2005:559-564.
[5]Peh L S,Dally W J.A delay model and speculative architecture for pipelined routers [C]//In International Symposiumon High-Performance Computer Architecture,Jan 2001:255-266.
[6]Mullins,R.,West A,Moore S.Low-latency virtual-channel routers for on-chip networks[C]//The 31st annual international symposium on Computer Architecture,2004:188-197.
[7]Mullins,West R A,Moore S.The design and implementation of a low-latency on-chip network [C]//ASP-DAC ’06 Proceeding of the 2006 Asia and South Pacific Design Automation Conference,2006:164-169.
[8]VeriSilicon SMIC 0.13m 1.2V/3.3V I/O Cell Library Databook[S].Semiconductor Manufacturing International Corporation,2006.
