面向混合属性数据集的双重聚类方法*
2013-06-08陈新泉
陈新泉
(重庆三峡学院计算机科学与工程学院,重庆 404000)
1 引言
从数据挖掘的角度看,聚类分析的目的是获取数据集的空间分布结构,进而描述那些有意义、有实际价值的数据集分布结构。现今多数聚类算法只能处理数值型数据集,对类别属性数据集和混合属性数据集的研究不够深入。由于实际中的聚类分析需求多数是面向混合属性数据集,所以近年来针对类别属性及混合属性数据集的聚类分析得到一些研究人员的重视。如Huang Z X[1]将经典的K-means算法[2]扩展到混合属性数据集中,提出了K-prototype算法。Hsu C C等[3]提出了一种可处理混合属性数据集的层次聚类算法。Bai L等[4]将探测最优聚类数目和发现初始聚类中心这两个过程结合起来,从而达到有效处理类别属性数据集的目的。Liang等[5]为解决混合属性数据聚类的一个重要难点,提出了一种基于信息理论的探测最优聚类数目的方法。到目前为止,虽然已发表了不少面向混合属性数据集的聚类分析研究成果,但没有一种算法对所有类型的数据集都是有效的。
本文第2节先对问题作简要的描述;第3节提出了一种面向混合属性数据集的双重聚类方法;第4节通过仿真实验来比较分析本文所提聚类算法的聚类效果;第5节对本文作简要的总结,并指出进一步的研究方向。
2 问题描述
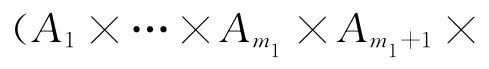
其中,Xi=(xi1,xi2,…,xim)和Xj=(xj1,xj2,…,xjm)分别为第i个数据点和第j 个数据点在m 个属性上的取值。易知,对任意的两个数据点,都有disorder(·,·)∈[0,+∞),dissort(·,·)∈[0,m2]。
3 混合属性数据集的双重聚类方法
定义1 混合数据集S={X1,X2,…,Xn}中点P 的双重近邻点集NN(P)定义为:

其中,disorder(X,P)为S 中的点X与点P 在有序属性上的相异度,dissort(X,P)为S 中的点X与点P 在无序属性上的相异度,DTorder为有序属性上的相异度阈值,DTsort为无序属性上的相异度阈值。
定义1的实质是,NN(P)是从S={X1,X2,…,Xn}中选取与点P 在有序属性上的相异度不超过DTorder、在无序属性上的相异度不超过DTsort的其它点所构成的集合。
3.1 双重聚类方法的基本流程
混合属性数据集的双重聚类方法包括如下五个步骤:
(1)根据应用问题的领域知识,构造有序属性上的相异度计算式和无序属性上的相异度计算式,设定有序属性上的相异度阈值和无序属性上的相异度阈值。
(2)构造混合属性数据集的双重近邻点集及双重近邻无向图。
(3)采用一种搜索策略,构造双重近邻无向图的初级聚类簇并建立其聚类结构描述。
(4)(可选)采用一种聚类合并算法,对初级聚类簇中的聚类进行满足聚类合并条件的聚类合并操作,直到不能再合并为止。
(5)最终获得的聚类簇即为该算法的输出结果。
接下来对这个基本流程的具体步骤作进一步的说明,并在算法实现方面给出若干讨论。
3.2 双重近邻无向图的简易构造算法
算法1 双重近邻无向图的构造算法
输入 数据集S={X1,X2,…,Xn}、有序属性上的相异度计算式disorder(·,·)、无序属性上的相异度计算式dissort(·,·)、有序属性上的相异度阈值DTorder、无序属性上的相异度阈值DTsort。
输出 S={X1,X2,…,Xn}的双重近邻无向图。
步骤1

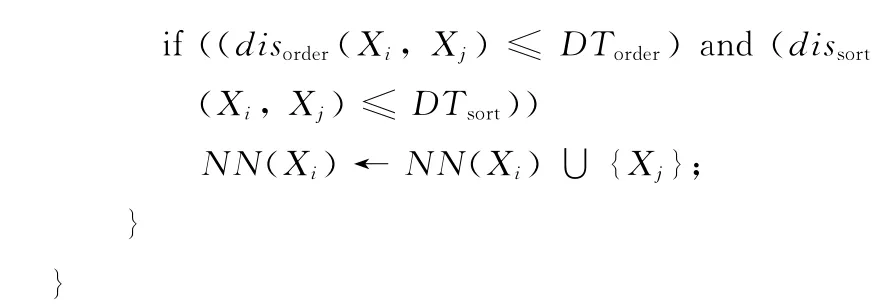
步骤2 根据S 中每个点的双重近邻点集NN(Xi)(i=1,2.…,n),构造出一个双重近邻无向图G=(S,E)。其中,E={(u,v)|u ∈NN(v),u,v ∈S}。注意:根据双重近邻点集的定义,u ∈NN(v)成立,意味着v ∈NN(u)也成立。
算法说明:
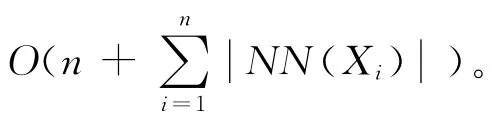
3.3 双重近邻无向图的改进构造算法
在算法1 中,每一个数据点对Xi和Xj的相异度要计算两次。算法1 的改进构造算法(算法1*)对每一个数据点对Xi和Xj的相异度只需计算一次,从而达到改进时空效率的目的。算法1*的具体描述可参见文献[6],它的优缺点简述如下:
(1)算法1*的优点。
①在算法1*中,存储双重近邻点集NN(Xi)(i=1,2.…,n)的邻接表空间可减少一半;
②若边(Xi,Xj)(i<j)是双重近邻无向图G=(S,E)的一条边,如果在后续的搜索过程中采用宽度优先策略,算法1的搜索过程必然存在对边(Xj,Xi)的搜索操作,而算法1*在宽度优先搜索过程中,入对、出对操作量可减少一半。
(2)算法1*的缺点。
①构造出的双重近邻点集NN(Xi)(i=1,2.…,n)不完全满足定义1;
②由算法1*构造出的|NN(Xi)|(i=1,2.…,n)不一定等于点Xi的双重近邻点数目。
3.4 基于分离集合并的双重近邻图聚类算法
算法2 基于分离集合并的双重近邻图聚类算法
输入 数据集S={X1,X2,…,Xn},有序属性上的相异度计算式disorder(·,·)、无序属性上的相异度计算式dissort(·,·)、有序属性上的相异度阈值DTorder、无序属性上的相异度阈值DTsort。
输出 S={X1,X2,…,Xn}的聚类簇描述。
步骤1 根据设定的有序属性上的相异度计算式disorder(·,·)、无序属性上的相异度计算式dissort(·,·)、有序属性上的相异度阈值DTorder和无序属性上的相异度阈值DTsort,采用算法1或算法1*构造出S={X1,X2,…,Xn}的一个双重近邻无向图G=(S,E)。其中E={(u,v)|u∈NN(v),u,v ∈S}。
步骤2 对S={X1,X2,…,Xn}中的每个点,执行如下的三个步骤:
步骤2.1

步骤2.2

步骤2.3

步骤3 由数组ClusterIndex[1..n]很容易得到S 的初级聚类簇C0={InitC1,InitC2,…}。
三步骤4 (可选)采用一种基于合并的层次聚类方法,反复地对从步骤3获得的初级聚类簇中的聚类进行满足合并条件的聚类合并操作,直到不能再合并为止。
步骤5 从步骤3或步骤4 获得的聚类簇即为本算法的输出结果。
算法说明:
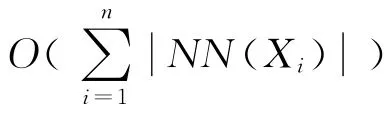
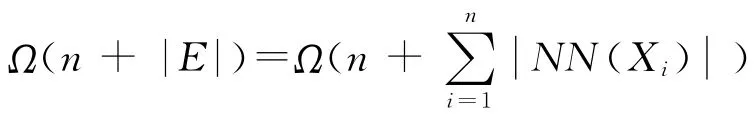
(3)在步骤2中,经过步骤2.2的Union()操作后,UFSTree[1..n]可能会成为一个具有两层或两层以上树结构的聚类点归属指向数组,所以本算法必须在步骤2.3 中的for循环下加上一个while循环才能获得“一个连通子图的所有结点都指向一个父结点,所有连通子图的连通信息都存储在分离集数组结构中”的期望结果。仿真实验程序也证明了在步骤2.3 中的for循环下,加与不加while循环,最终得到的ClusterIndex[1..n]值往往是不同的。
经过这种基于分离集的合并操作后,可获得双重近邻无向图G 的若干连通子图。其中,双重近邻无向图G 的若干连通子图的连通信息保存在UFSTree[1..n]中(该数据结构的详细定义及三种基本操作的实现算法可参见实现本算法的源代码),每个连通子图对应数据集S 的一个初级聚类。
(4)在步骤3中,若事先给出了孤立点集的判定阈值,当双重近邻无向图G 的某连通子图的数据点数小于该判定阈值时,则可判定由该连通子图所形成的初级聚类为孤立点集。
3.5 基于宽度优先搜索的双重近邻图聚类算法
基于宽度优先搜索的双重近邻图聚类算法(算法3)首先构造出数据集的一个双重近邻无向图,接着采用修改后的宽度优先搜索技术搜索出该双重近邻无向图的所有连通子图,从而获得数据集的初级聚类结果。该算法的具体描述及讨论可参见文献[6]。
3.6 基于深度优先搜索的双重近邻图聚类算法
基于深度优先搜索的双重近邻图聚类算法(算法4)也是首先构造出数据集的一个双重近邻无向图,接着采用修改后的深度优先搜索技术搜索出该双重近邻无向图的所有连通子图,从而获得数据集的初级聚类结果。该算法的具体描述及讨论可参见文献[6]。
3.7 性能比较
本文几个算法的时间与空间复杂度比较如表1所示。

Table 1 Comparison of time and space complexity in several algorithms表1 几个算法的时间与空间复杂度比较
4 仿真实验
4.1 仿真实验设计
在Intel Pentium(R)Dual-Core CPU T4500 2.30GHz、2GB内存、Windows XP SP3下的Visual C++6.0开发环境下采用C 语言来进行仿真实验验证。实验数据集有人工数据集和UCI标准数据集两大类。
(1)人工数据集。作者编程生成的不带噪声的具有五个或七个显著聚类区域的二维实值数据集。该数据集有四类,具体描述如下:
DS1:400个数据点,五个聚类的人工无噪声数据集;DS2:400个数据点,七个聚类的人工无噪声数据集;DS3:10 000个数据点,五个聚类的人工无噪声数据集;DS4:10 000个数据点,七个聚类的人工无噪声数据集。
(2)UCI 标准数据集。选 用Iris、Glass、Waveform、Wine、Vertebral、German 和Credit[7]七个数据集。除Iris外,其余几个UCI数据集的有序数值属性部分都规整到区间[0,1]中。
人工数据集和UCI数据集作为算法的数据输入,以图形显示的方式来验证双重近邻无向图的构造算法及其改进算法的正确性;以图形显示及聚类结果输出的方式来验证采用三个聚类算法(基于分离集合并的双重近邻图聚类算法(标记为A2)、基于宽度优先搜索的双重近邻图聚类算法(标记为A3)和基于深度优先搜索的双重近邻图聚类算法(标记为A4))构造初级聚类簇的正确性,并以Kmeans算法[2]和AP 算法[9]作对比来分析它们的算法效率及聚类精度。
在本仿真实验中,分离集数据结构定义及其三个基本操作是在文献[10]的基础上进行了一点修改而实现的。
用来衡量算法的性能及聚类效果的指标有:算法所花费的时间(采用ST 标记,单位为秒)、聚类数目(采用NC 标记)、预设的聚类数目(采用PNC标记)、所有数据点到其聚类平均点的平均距离(采用ADM 标记)和聚类纯度(采用CP 标记)。
参数DTorder的设定方法:通过多次实验探测或根据数据集(或其样本)的最小生成树来估计。
4.2 仿真实验结果
表2列出了三个基于不同搜索策略的双重近邻图聚类算法(A2、A3和A4)与两个知名聚类算法(K-means算法和AP 算法)处理四类人工数据集的对比实验结果。表3列出了三个双重近邻图聚类算法(A2、A3和A4)与两个知名聚类算法(Kmeans算法和AP算法)处理五个UCI有序属性数据集的对比实验结果。表4列出了三个双重近邻图聚类算法(A2、A3和A4)与两个知名聚类算法(K-means算法和AP算法)处理两个UCI混合属性数据集的对比实验结果。
4.3 实验结果分析及结论
从表2、表3和表4中可以看出,算法A2、A3和A4的聚类结果相同。无论是反映双重近邻无向图的连通子图的个数(即聚类数目),还是反映聚类紧密度的一个度量(如所有点到其聚类平均点的平均值)都是一样的。算法A2、A3 和A4 仅在所花费的时间代价上有时会存在一点差别。这个实验结果与三个算法的理论分析结果完全相吻合。
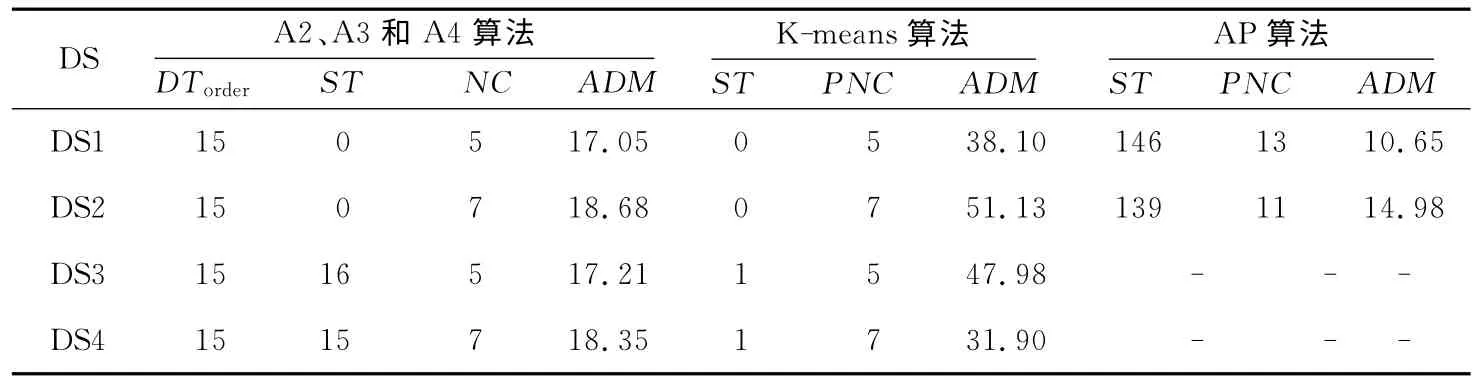
Table 2 Experimental results contrast of five clustering algorithms for four class artificial data sets表2 五个聚类算法处理四类人工数据集的对比实验结果
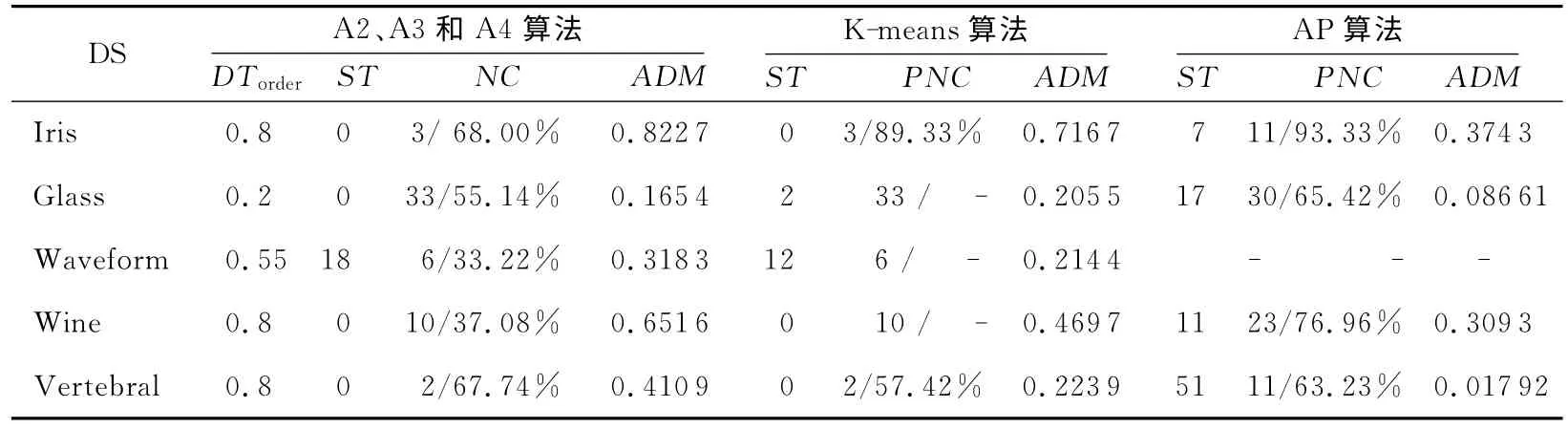
Table 3 Experimental results contrast of five clustering algorithms for five UCI ordered-attributes data sets表3 五个聚类算法处理五个UCI有序属性数据集的对比实验结果

Table 4 Comparison experimental results of five clustering algorithms for two UCI mixed-attributes data sets表4 五个聚类算法处理二个UCI混合属性数据集的对比实验结果
从实验结果图示及表2可以看出,当设置合适的参数DTorder后,算法A2、A3和A4对于四类人工数据集的聚类质量要远远好于K-means算法和AP算法。这是因为这些数据集具有良好的聚类分布结构,且没有近邻噪声点干扰而导致相近的聚类区域被连通成一个聚类。
从表3和表4 可以看出,算法A2、A3 和A4并非对所有的UCI数据集都能取得比K-means算法和AP算法更好的聚类质量。未能取得高聚类质量的首要原因是算法A2、A3和A4在计算这些数据集的相异度时,设定这些UCI数据集(除Iris外,其余数据集都对有序属性部分进行了规整化)的属性权重都为1,并未考虑有些属性权重取值为1与该数据集的类别分布相差甚远。另外一个原因是算法A2、A3和A4进行聚类分布探测的根基是通过发现近邻连通子图的方式来进行的,这类算法一般都难以探测出不具有明显聚类分布结构的数据集。当存在较多近邻噪声时,甚至多个相近的“球型”聚类区域也会被连通起来。
事实上,算法A2、A3和A4更适合发现那些具有明显聚类分布结构且无近邻噪声点的数据集。可以想见,在设定DTorder和DTsort后,如果存在一些近邻噪声点把所有的典型聚类分布区域连通起来,那么这三个算法就会判定它们是一个大聚类。这种算法的近邻互连性可解释为什么这三个算法在聚类有些UCI数据集时会取得更差的聚类质量。
5 结束语
面对动态、海量的混合属性数据集的数据预处理需求,本文提出了一种可以处理混合属性数据集的双重聚类方法。通过四类人工数据集和七个UCI标准数据集的仿真实验,验证了双重聚类方法的三个具体实现算法尽管所采用的算法策略不同,但最终取得的结果是一致的。仿真实验还表明,对于一些具有明显聚类分布结构且无近邻噪声干扰的数据集,这种方法经常能取得比K-means算法和AP算法更好的聚类精度,从而说明这种双重聚类方法具有一定的有效性。
将双重聚类方法与特征权重优化方法结合起来作进一步的改进研究,并与其它更多经典的聚类算法在算法速度及聚类质量方面对更多的数据集做更多的比较是下一步的工作。
[1]Huang Z X.Extensions to the K-means algorithm for clustering large data sets with categorical values[J].Data Mining and Knowledge Discovery,1998,2.3):283-304.
[2]Jain A K.Data clustering:50years beyond K-means[J].Pattern Recognition Letters,2010,31(8):651-666.
[3]Hsu C C,Chen C L,Su Y W.Hierarchical clustering of mixed data based on distance hierarchy[J].Information Sciences,2007,177(20):4474-4492.
[4]Bai L,Liang J Y,Dang C Y.An initialization method to simultaneously find initial cluster centers and the number of clusters for clustering categorical data[J].Knowledge-Based Systems,2011,2.(6):785-795.
[5]Liang Ji-ye,Zhao Xing-wang,Li De-yu,et al.Determining the number of clusters using information entropy for mixed data[J].Pattern Recognition,2012,45(6):2251-2265.
[6]Chen Xin-quan.Dual clustering method based on double-levels indexing structure facing to mixed-attributes data set[EB/OL].[2012-03-21].http://www.paper.edu.cn/index.php/default/releasepaper/content/201203-627.(in Chinese)
[7]Frank A,Asuncion A.UCI Machine Learning Repository[EB/OL].[2010-09-01].http://archive.ics.uci.edu/ml.
[8]Chen Xin-quan.Clustering algorithm research based on near neighbour point set[EB/OL].[2009-12-09].http://www.paper.edu.cn/index.php/default/releasepaper/content/200912-254.(in Chinese)
[9]Frey B J,Dueck D.Clustering by passing messages between data points[J].Science,2007,315(16):972-976.
[10]Cormen T H,Leiserson C E,Rivest R L,et al.Introduction to algorithms[M].Third Edition.New York:The MIT Press,2009.
附中文参考文献:
[6]陈新泉.面向混合属性数据点集的基于双层索引结构的双重聚类方法 [EB/OL].[2012-03-21].http://www.paper.edu.cn/index.php/default/releasepaper/content/201203-627.
[8]陈新泉.基于近邻点集的聚类算法研究[EB/OL].[2009-12-09].http://www.paper.edu.cn/index.php/default/releasepaper/content/200912-254.
