脚本测试技术在列控中心开发测试中的运用
2013-05-09北京全路通信信号研究设计院有限公司北京100073
崔 岩(北京全路通信信号研究设计院有限公司,北京 100073)
1 概述
列车运行控制系统是确保列车高速安全运行的关键。作为高速铁路列控系统地面设备的核心,列控中心(TCC, Train Control Center)被定义为SIL-4级安全设备。与计算机联锁系统具有相同的故障-安全等级要求,具备高安全、高可靠、高性能的特点。TCC的功能失效会造成列车无法正常安全运行,带来严重的人身和财产安全问题。[1]因此,TCC的功能测试是确认系统是否满足功能需求,是否具有足够安全防护能力的重要手段。测试结果是对TCC评估的重要依据。
目前,自动化测试凭借其高效率、高重复性、高一致性、高可信性等优点逐渐受到重视,尤其是基于脚本的自动测试更因其灵活、高效,在包括TCC在内的越来越多的安全系统软件测试过程中得到运用[2-5],实现了规则测试案例的脚本自动生成,执行和测试结果判定。所有的工作除了需要少量的人工介入,绝大部分都是由计算机自动完成的。然而,对于开发测试,测试案例具有不同特征,没有统一的规则可以依据,仍然采用的方法是人工编写测试案例,人工进行测试。这种方法虽然能够满足软件功能测试的一般要求,但仍然存在大量问题:1)测试结果对测试人员的专业知识和测试经验依赖大;2)测试效率低;3)回归测试代价大;4)测试覆盖不全面。因此,实现开发测试的自动测试具有重要意义。
因此,本文在基于脚本的TCC自动测试平台基础上,对TCC开发测试需求和测试案例进行分析归纳,构建了TCC测试案例词典;基于分词算法和格语法理论,提出了一种从测试案例到测试脚本的自动生成方法,从而实现了开发测试的自动化测试。

崔岩,男,硕士毕业于北京航空航天大学,助理工程师。主要研究方向:列控中心仿真测试系统。
2 TCC开发测试内容分析
2.1 TCC开发测试特点
TCC开发测试依据列控中心技术规范,通过模拟TCC的各种运营场景,验证TCC的输出是否正确。尽管测试任务具有不规则性,但可总结为以下功能特征点,如表1所示。

表1 TCC被测功能特征点
测试案例是对TCC测试任务的描述,体现测试方案、方法、技术和策略的文档。内容包括测试目标、测试环境、输入数据、测试步骤、预期结果等。其中,测试步骤和预期结果是测试脚本编写的依据。
综上,TCC开发测试的特点总结如下。
1)测试内容是TCC功能特征点有限集的子集2)测试案例与测试脚本具有直接对应关系
因此,TCC测试案例到测试脚本的转换问题即为特殊领域内的自然语言理解问题。
2.2 测试案例抽象定义
与广义的自然语言理解问题相比,对TCC测试案例的理解具有词汇少,词语搭配固定等特点。为简化理解过程,减少歧义发生,采用格语法理论对句子成分进行划分。
格语法[6]认为:句子的语义结构是由动词跟动词所联系的名词性成分之间的关系决定的。每一个动词都有一个预先就安排好的跟名词性成分发生特定联系的框架,即“格框架”。在格语法的基础上,添加了名词和形容词之间的特定联系,以及成分的类别属性,形成了TCC测试案例语法框架,表示为:
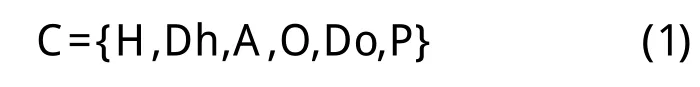
其中:
H为动作或命令的发起者;
Dh为动作或命令发起者的描述;
A为测试案例的动作或命令;
O为动作或命令的接收者;
Do为对动作或命令接受者的描述;
P为动作或命令的目标状态;
TCC测试案例语法框架要求:
* 各成分必须按照Dh、D、A、Do、O、P的顺序进行组合;
* 每个成分具有词性和类别两个属性;
* A是一个句子的核心,不可省略;
* H,O,P是A的附属格,其中H为施事格,O为受事格,P为状态格;
* Dh,Do分别是H和O的附属格,定义为限定格;
*附属格的属性分为“有”和“无”,因其所属成分而定,并且是其所属成分的固有属性;
*若附属格的属性为“有”,而句子中没有相应成分,认为句子不完整;
*成分之间具有严格的词性搭配关系,以及类别搭配关系。
例如,对“排列X→X3接车进路,X信号机开放,X信号机接近区段发U U S码”这样一个描述,其中动词包括:“办理”、“开放”、“发”,按照格语法框架进行分解,得到结果如表2、 3、4所示。
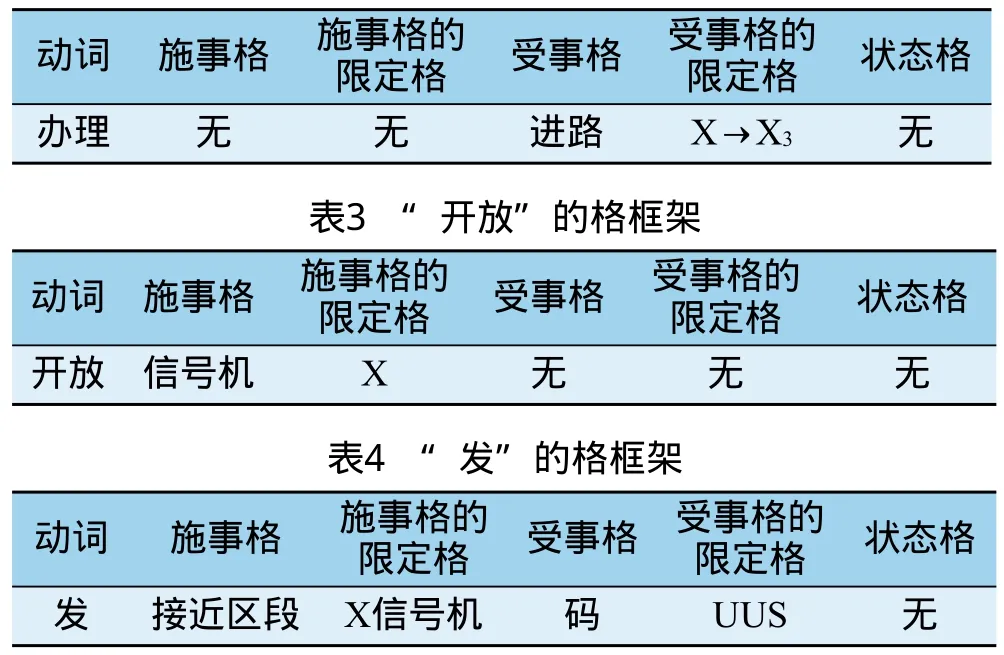
表2 “办理”的格框架
3 TCC开发测试词典
通过对测试案例的抽象定义,实现测试案例理解的基础即是对测试案例进行分词处理,提取出关键成分并进行搭配验证,进而转换成脚本。
现有的分词算法基本上可以分为3种:机械式分词、理解式分词和统计式分词[7]。在这3种算法中,机械式分词的准确率最高,对于机械式分词,需要一部词典作为后台依据,简单地说是通过将文档中的汉字串与字典中的词相匹配来完成词的切分。
3.1 词典分类
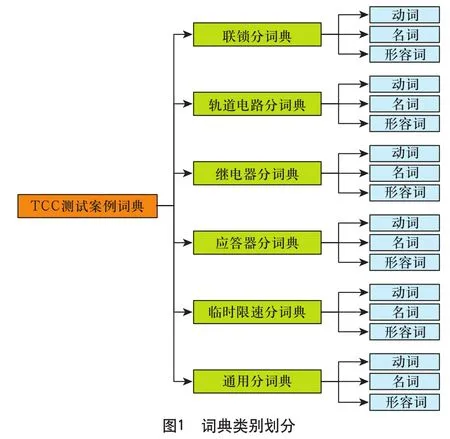
为了对词汇进行详细划分,测试案例词典按照设备类型又可以分为联锁子词典、轨道电路子词典、通用子词库等子词典,在各子词典中,又按照词性分为动词、名词、形容词词典,同时对各个词汇的搭配关系进行定义。如图1所示。
3.2 词典索引结构
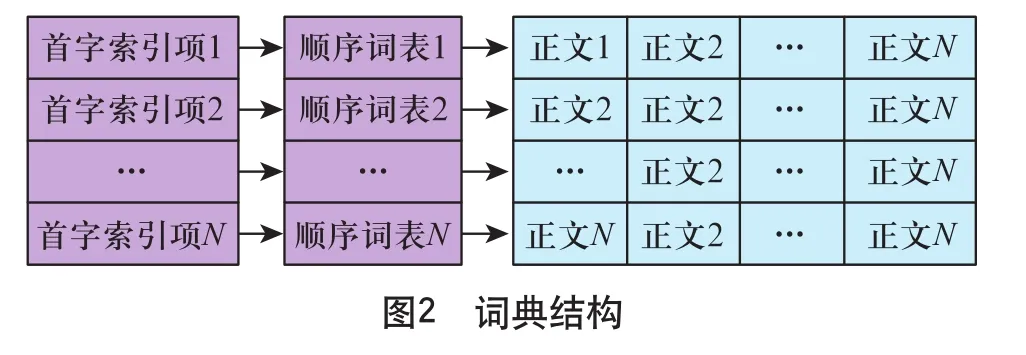
为加快词典的查找速度,采用整词二分的分词词典机制[8]进行词典结构定义。该词典的存储结构把词典分为首字H ash表、词索引表、词典正文3级。词典正文是以词为单位的线性表,词索引表是指向词典正文中每个词的指针表。通过首字H ash表的散列函数和词索引表很容易确定指定词在词典正文中的可能位置范围,进而在词典正文中通过整词二分进行定位。
因为一个动词可以与类型不同的名词进行搭配,因此,动词不与脚本进行对应关系,而是将动词与某一类型名词的搭配作为整体与脚本进行对应。
如图2所示。
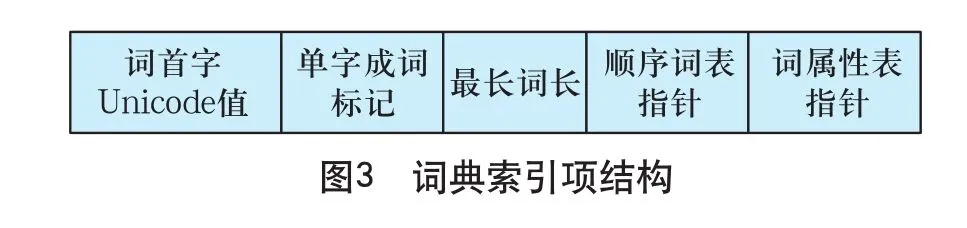
索引项结构如图3所示。
词典正文结构如表4所示。

词属性定义如图5所示。

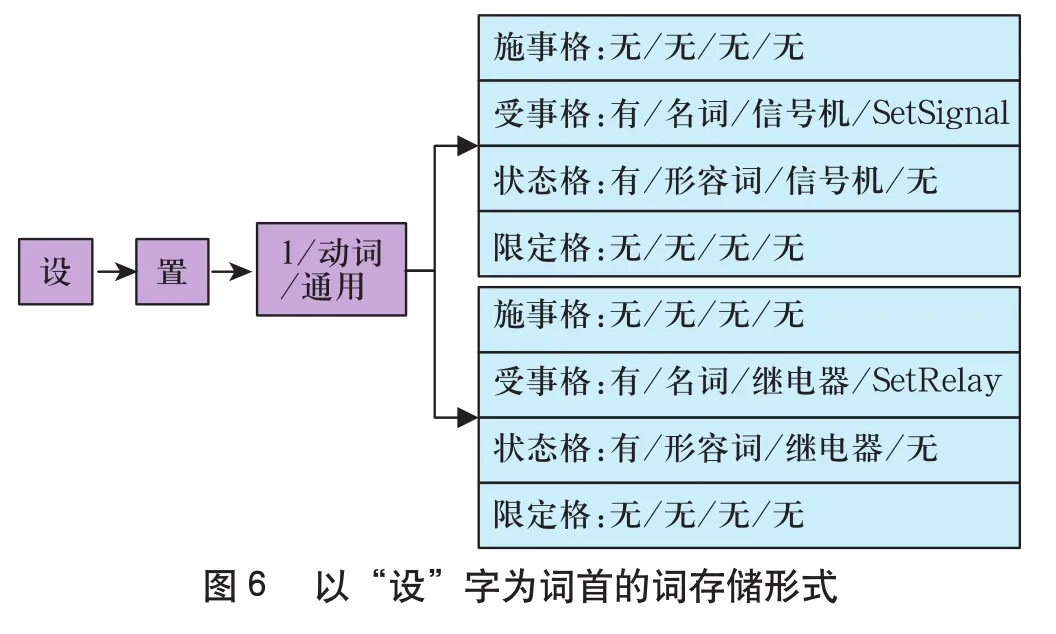
例如:以“设”字开头的词在词典的存储形式如图6所示。
4 脚本自动生成算法
脚本自动生成算法实现对句子的分词划分,提取满足格语法的句子成分,并按照词典定义进行脚本转换。需要经过句子预处理,基于正向最大匹配法的分词划分,基于格语法的成分提取和脚本转换。
4.1 案例预处理
测试案例由中文、英文、标点符号组成。首先将句子用英文字符串和标点符号进行第一次拆分,划分成汉字字组、英文字组、标点符号、特殊符号和数字的组。
4.2 正向最大匹配法
对于预处理后的汉字字组使用正向最长匹配算法:即按照从前到后的顺序,用最长词原则来匹配词库中的词,并把最长词从中逐个切分出来,对以上的汉字字组句段进行机械分词,对于其他句段则直接结合[9]。具体算法如下。
设待切分的汉字串S=S1S2…Sn。正向最大匹配算法描述如下:
1)取S1,通过H ash映射,找到词首字索引项,获取相关数据。
2)若词典中以S1为词首字的词最大长度Lmax,则S1为词首字的词表为空,将S1切分出来。令S=S2S3。继续下一次切分;若Lmax,则取Str1,在字典中查找Str1:
a.若Str1不是词,则增加一个字Str1=Str1+Sk+1,继续在字典中查找,直到查找成功。若k=n或k>Lmax,查找都不成功,则S1在此处可视为1个单字词,得到切分S=S1/S2S3。
b.若Str1是词,则增加一个字Str1=Str1+Sk+1,再查找,若Str1是词,继续增加一个字,直到k=n或k>Lmax,并记录词的最后一个字的位置p。则可暂时获得切分词:Stem p1=S1S2…Sp/Sp+1。
c.取S2为首字词,重复以上操作,则可获得另一切分词Stem p2,若Length(Stem p1)>Length(Stem p2),则得到切分词:Stem p1,否则,得到切分词:S1/Stem p2。
3)移动汉字串指针,进行下一次切分,直到整个串切分完成。
4.3 格框架生成及脚本生成
对切分后的句子从左到右进行处理,找到第一个词性为动词的词,以此词为基准找到它的施事格、受事格、状态格、限定格,进而找到各格的相关格定义,构建出该词如公式(1)所示的完整格框架结构。若不满足格语法要求,则转换失败;若满足格语法要求,则按照如下规则进行脚本生成:
*动词与其附属格作为一个整体关联的脚本作为脚本指令输出;
*按照施事格、受事格、状态格的顺序输出脚本指令参数;
*若施事格或受事格具有附属限定格,则将限定格作为脚本指令参数输出,而不输出施事格或受事格;
完成句子全部动词的转换后,脚本生成完毕。
5 举例说明
例如,以下测试案例实现当区间信号机L灯断丝时,验证TCC信号机显示。如表5所示。

表5 测试案例举例
句子分词结果如表6所示。

表6 分词结果
测试步骤中,动词为“设置”,按照图6“设置”一词在词典中的定义,其完整的格框架如表7所示。

表7 “设置”格框架
同理,预期结果中,动词为“点”,其完整的格框架如表8所示。

表8 “点”格框架
生成脚本为:
SetSignal(“967”,“L 灯断丝”);
CheckSignal(“967”,“U”);
6 结论
本文通过对TCC开发测试案例的分析和归纳,在格语法理论的基础上,给出了测试案例的抽象定义和TCC开发测试案例词典的结构设计。在此基础上,给出了基于正向最大匹配法的脚本生成算法,并以真实测试案例为例说明了该方法的实际应用,证明了该方法的可行性,实现了开发测试的自动测试,提高了测试效率。
[1]吴芳美.铁路安全软件测试评估[M].北京:中国铁道出版社,2001.
[2]王铁江,郦萌.基于关键字驱动脚本的安全软件自动测试系统[J].同济大学学报(自然科学版),2002,30(6):719-722.
[3]徐中伟,吴芳美.计算机联锁安全软件测试案例自动生成专家系统[C]//第八届全国容错计算学术会议论文集.北京:中国计算机学会容错计算专业委员会,1999:158-163.
[4]杜峰.通用脚本引擎的研究及其在自动测试中的应用[D].上海:同济大学,2006.
[5]张浩.基于通用脚本引擎的自动测试平台及在安全测试中的应用[D].上海:同济大学,2006.
[6] Fillmore, C. J. The case for case[M]. In: Bach. E., Harms R. eds. Universals in Linguistic Theory, New York: Holt, Rinehart and Winston, 1968.
[7]张春霞,郝天永.汉语分词的研究现状与困难[J].系统仿真学报,2009,17(1):138-147.
[8]孙茂松,左正平,黄昌宁.汉语自动分词词典结构的实验研究[J].中文信息学报,2000,14(1):1-6.
[9]张彩琴,袁健.改进的正向最大匹配分词算法[J].计算机工程与设计,2010,31(11):2595-2597.
