短波近红外光谱结合ν-SVM法快速无损鉴别淀粉种类
2013-05-05邹婷婷窦英王莹宋焕禄庞小一陶菲菲张秋晨
邹婷婷,窦英,王莹,宋焕禄,庞小一,陶菲菲,张秋晨
1(北京工商大学食品学院,北京,100048)2(天津科技大学理学院化学系,天津,300457)3(吉林省产品质量监督检验院,吉林长春,130022)
食用淀粉主要包括薯物淀粉、谷类淀粉、豆类淀粉等,其中玉米淀粉占有重要位置,目前应用最多且价格较为低廉。而大米和小麦因为价格高,且是主粮而相对用作加工淀粉及深加工较少,薯类淀粉中红薯淀粉和马铃薯淀粉价格相对偏高。因为不同种类淀粉颗粒的感官性状和物化指标差别不明显,难以辨认,部分生产者便在薯类淀粉和谷类淀粉中添加价廉的玉米淀粉出售,以赚取更高的利润。国家食品质量安全监督检验中心开展的“我国食用淀粉种类的鉴别技术研究”科研项目,采用经典方法,提取了24种不同植物来源的食用淀粉颗粒,运用扫描电镜技术,对不同种类食用淀粉颗粒的超微形貌特征进行了分析,建立了不同种类食用淀粉的定性分析方法[1],此种方法相对来说仪器价格较高。
近红外光谱是由于分子振动的非谐振性使分子振动从基态向高能级跃迁时产生的,记录含氢基团X—H(X C、N、O)振动的倍频和合频吸收[2]。近红外光谱技术具有样品前处理简单、无需化学试剂、仪器操作简单、检测速度快,稳定性好、可实现在线分析等优点,在食品领域有广泛研究和应用[3-4]。光谱学上通常将780~1 100 nm称为短波近红外光谱区,由于分子在该谱区的波频和吸收信号均较弱,谱带多且相互重叠,需借助于更强大的化学计量学方法分析处理数据。支持向量机(support vector machine,SVM)是一种新的机器学习算法,具有一定的处理高维有限数量的非线性数据的能力,有研究将聚类分析和SVM方法应用于淀粉分类[5]和葛粉掺假问题取得良好效果。
本研究引入一种新型SVM方法,即ν-SVM[6],建立淀粉种类鉴别模型,通过比较不同光谱预处理方法优化模型,并通过未知样品对模型性能进行评价。
1 材料与方法
1.1 试验材料
红薯淀粉、马铃薯淀粉和玉米淀粉,共112个样本,随机分为训练集和预测集。其中,训练集包含78个样本,测试集包含34个样本。

表1 淀粉样品分布的统计结果Table 1 The statistical results of the starch samples
1.2 仪器与软件
尼高力6700傅立叶红外光谱仪及积分球、样品杯等附件。SVM算法使用网络共享软件libsvm,由Chih-Chung Chang 和 Chih-Jen Lin 提供[7]。
1.3 测量条件
淀粉样品不作任何处理直接进行近红外光谱采集。测量时将样品装入样品杯,采用漫反射光谱法,扫描范围10 000~12 799 cm-1,分束器 CaF2,分辨率8 cm-1,扫描次数为64次。每个样品重复扫描3次,取平均值。图1为112个淀粉样品的短波近红外光谱图,由于短波近红外光谱的谱带较宽且灵敏度较差,吸收峰重叠严重,其相似性很难以肉眼判断,须借助化学计量学方法。
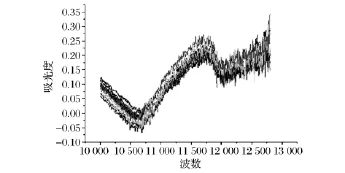
图1 112个淀粉样品的短波近红外光谱图Fig.1 Short-wave NIR spectra for 112 starch samples
1.4 C-SVM和ν-SVM概述
SVM最大的优势是根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,能较好地解决小样本情况下模型可靠性预测问题。SVM优良的推广性能实现,同模型中参数C、γ等有很大的关系,如何根据训练样本集选择合适的模型参数,以保证建立好的模型有很好的推广性能,成为建立SVM分类模型的关键一步。
在C-SVM中,有两个相互矛盾的目标:最大化间隔和最小化训练误差。其中的常数C起着调和这2个目标的作用,C值的选取常常比较困难。Scholkopf[6]提出了一种新型支持向量机ν-SVM,该支持向量机中参数ν能够控制支持向量的数目和训练误差的大小。本研究中分别使用C-SVM和ν-SVM 2种类型的支持向量机。C-SVM对正负类样本采用不同的惩罚函数Cp和Cn;ν-SVM在支持向量和错误训练的比率上相关性更好,C-SVM的参数C取值范围在[0,+∞],而ν-SVM的参数ν取值范围在[0,1]。
2 结果与分析
2.1 数据预处理方法
仪器采集的原始光谱中除包含与样品组成有关的信息外,同时也包含来自各方面因素所产生的噪音信号。平滑是滤除噪音最常用的方法,微分能有效消除光谱漂移,二者都是常用的光谱预处理方法。多元散射校正(multiplicative scatter correction,MSC)处理可以消除光谱在吸光度轴上的差异,从而消除散射效应的影响。本研究比较了4种光谱预处理方法,即平滑、一阶微分、二阶微分、多元散射矫正对所建模型的影响,见表2。
2.2 C-SVM和ν-SVM模型的建立与评价
类似于其他多元校正方法,SVM模型的泛化性能也是依赖于几个参数的恰当选择之上的,关键是在所给定的数据集上找到最佳的参数设置。经验表明高斯核函数具有良好的学习能力,这里也选用高斯核函数。其他3个参数的选择可以根据经验,自举法,交叉验证等方法进行确定,其中最常用的方法就是交叉验证法(Cross-Validation)。在建模中,采用全局寻优方式得到SVM的参数优化值,参数优化结果见表3。采用交叉验证正确率作为交叉验证的检验指标,以正确率来考察所建模型的性能和预测效果,最后用测试集数据对训练模型进行测试,结果如表2。

表2 C-SVM和ν-SVM鉴别淀粉种类的正确率比较Table 2 Different correct ratio of starch category of C-SVM and ν-SVM models
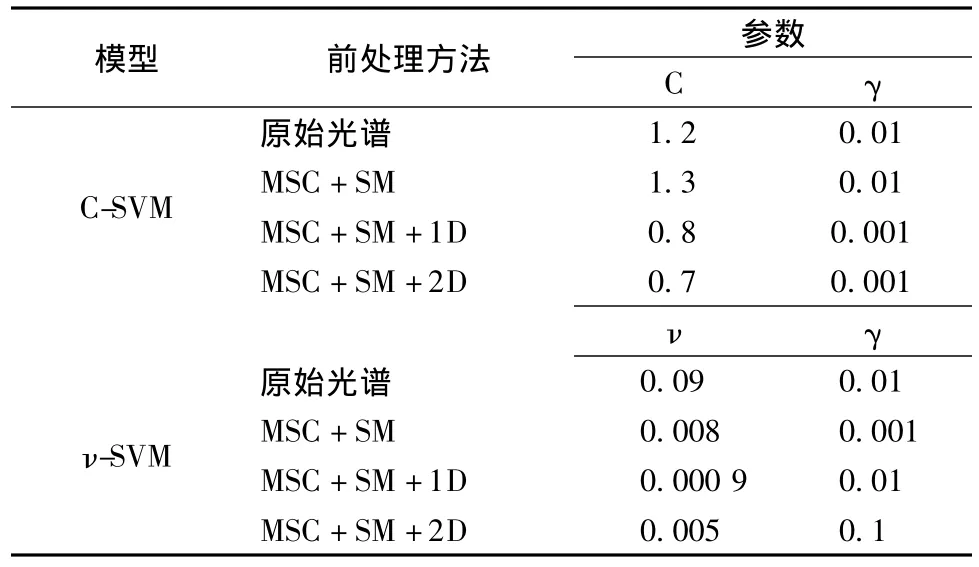
表3 C-SVM和ν-SVM参数优化Table 3 Optimized parameters used for construction of C-SVM and ν-SVM models
表2中数据显示,平滑、多元散射矫正、微分3种预处理方法后,ν-SVM的建模效果最好,训练集交叉验证正确率和测试集正确率均达到100%。
2.3 马氏距离判别分析结果比较
马氏距离判别分析法作为一种线性方法,也常用于近红外光谱的结果分析。但短波近红外光谱与属性间常常存在非线性关系,处理这样的光谱,采用马氏距离判别分析方法有一定的局限性。为了和非线性分析方法支持向量机作比较,本实验采用马氏距离判别分析法建立了红薯淀粉、马铃薯淀粉、玉米淀粉的识别模型,用主成分分析(principle component analysis,PCA)法将原始数据降维,消除众多信息共存中相互重叠的信息部分后,采用较少变量计算判别。在原始光谱的全波数段范围内,比较了4种光谱预处理方法,即平滑、一阶微分、二阶微分、多元散射矫正对所建模型的影响,同时对34个未知样品进行预测。马氏距离判别分析方法结果如图2和表4。
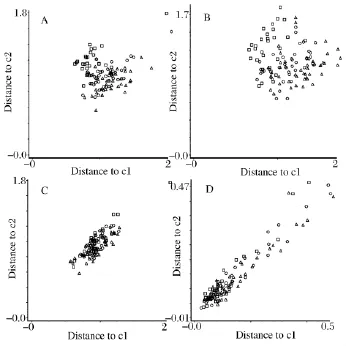
图2 马氏距离判别分析模型的样品分布图Fig.2 Sample distribution of Mahalanobis distance models
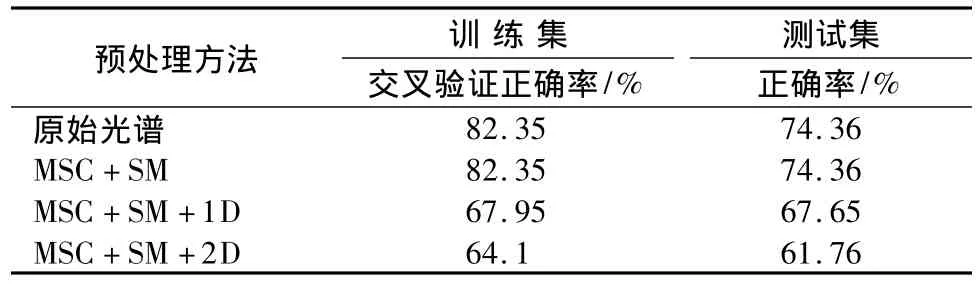
表4 马氏距离判别分析法鉴别淀粉种类的正确率Table 4 Different correct ratio of starch category of Mahalanobis distance models
3 结论
ν-SVM法同短波近红外漫反射光谱法结合,鉴别淀粉种类是可行的,同马氏距离判别分析法比较建模效果更好,且无须对样品进行处理,操作简单,可实现快速无损鉴别淀粉种类的目的。
[1] 我国淀粉种类鉴别技术研究获突破[N].中国质量报,2010-04-06.
[2] 陆婉珍,袁洪福,徐广通,等.现代近红外光谱分析技术[M].北京:中国石油化工出版社,2000:2-5.
[3] 李燕萍,钱莹,段钢.采用近红外光谱测定木薯乙醇发酵液中乙醇、甘油和葡萄糖含量[J].食品与发酵工业,2009,35(8):117-121.
[4] 熊成,董庆利,曾静,等.近红外光谱分析技术在肉品品质检测中的应用[J].食品与发酵工业,2010,36(12):141-145.
[5] 孙晓荣,刘翠玲,吴静珠,等.SVM方法在淀粉分类问题中的应用[J].食品工业科技,2011,32(11):431-433.
[6] Scholkopf B,Smola A J,Williamson R C,et al.New support veuor algorithms[J].Neural Computation,2000,12(5):1 207-1 245.
[7] Chang C C,Lin C J,台湾大学,2012.http:/www.csie.ntu.edu.tw/_cjlin/libsvm.
