网络论坛教学评论的自动情感分析方法——以湖南商学院枫华论坛为例
2013-03-26曾伏秋罗毅辉胡清洁
曾伏秋,罗毅辉,杨 刚,胡清洁
(湖南商学院,湖南长沙410205)
一、引言
随着网络的发展,校园网成为了大学生们进行教学评价的平台。与传统的教学评教方法相比,这种网上评教拥有许多优点,其中最重要的一点就是教学评价过程不受时间、地点的约束,也不需要教师或者教辅人员组织和管理,因此得到的评教信息更加真实合理,能够更准确地反映教师的教学水平,而传统的教学评价受到上述因素的影响,使得评价结果倾向更多的正面结果。另外,使用网上评教,管理部门不再需要打印、分发、回收纸质调查表,节省了人力物力,减少了经济支出,消除了人工统计可能引起的误差,使教师和教学管理部门能够实时、准确、快速地获取反馈信息,实现师生间的快捷交流。
尽管现有的网上评教系统拥有传统评教所不具备的优点,然而实际调查发现,网上评教活动也面临着各种问题。首先,一般网上评教时间集中在课程教学活动结束后的最后两周,因此获得的教学反馈是滞后的,具体来说,就是教学反馈信息不能对本课程的这次教学施加影响,只能在该课程的下一次教学中改进。其次,网上教学评价的指标体系固定,不能体现不同学科、不同性质和不同教学形式的差异,造成教学反馈信息形式单一,不能充分反映学生的受教感受和教学建议。
网络论坛具有开放性、自由性和公平性等优点,为网络的互动性做出了巨大贡献。大学生通过校园网论坛可以随时发布教学评论,克服了现有网上评教系统教学评价集中在学期末的缺陷,同时由于网上评论大多以非结构化或者半结构化的文本形式出现,学生可以使用语言文字充分表达教师课堂教学的优缺点。本文旨在利用文本情感分类方法充分挖掘校园网络论坛中的教学反馈信息,给教学管理部门和教师提供决策支持,方便他们进行动态的教学管理。枫桦论坛是湖南商学院的官方论坛,在本校大学生中间有广泛的知名度和影响力,因此成为本文获取教学评论样本的来源。
二、常用文本情感分析方法
文本情感分类是指通过挖掘和分析文本中的立场、观点、看法、情绪、好恶等主观信息,对整个文本的情感倾向做出类别判断。从当前的研究来看,文本情感类别通常分为两类(好评、差评)或三类(好评、差评和中立),且以考虑两种类别者居多。尽管文本情感趋向分析的研究相比文本分类起步较晚,但是已经成为当前研究的一个热点,并且近年来在有害信息过滤、社会舆情跟踪、产品质量评价、博客兴趣分析等应用领域取得了一系列研究成果。
目前在文本情感分类上采用的分类算法大致分为两类,一类是基于有监督学习的分类算法,这类方法一般直接采用传统文本主题分类中常用的算法或者对其进行简单的改进,然后利用具有情感分类标记的文档集训练出算法包含的参数。如Pang等人采用了朴素贝叶斯(NB)、最大熵模型(ME)和支持向量机(SVM)三种分类器对单特征词文本表示模型表示下的英文电影评论进行了情感分类实验,测试结果表明,基于二元特征值的结果要好于词频特征值,同时基于SVM方法显示出最好的分类效果。但是Yu等人通过实验发现SVM分类器的性能并非在所有的文本情感分类数据集上都好于NB分类器。徐军等人也利用NB和ME方法进行了中文新闻及评论语料的情感分类研究,得到了与Yu等人类似的结论。另一类是基于无监督学习的分类算法,这类方法无需带有情感分类标记的训练集,取而代之的是确定一个具有情感趋向的单词或者短语的特征集,然后根据每个文档中包含的这些单词和短语的数量来判断它的类别。Turney等人首先定义一个情感基准词集合,然后采用逐点互信息(PMI) 和潜在语义分析(LSA) 两种方法度量给定词汇与情感基准词的关联度,确定词汇的语义倾向,最后将词汇的情感倾向用于判断句子或篇章的情感倾向。这种方法的性能很大程度取决于预先定义的情感基准词集合质量,并且情感基准词集合一般都是领域相关的,并不具有通用性。Kennedy和Inkpen设计的方法除了统计文本中的“正面”情感词和“负面”情感词的频数外,还考虑了对这些词的情感倾向极性或者程度存在影响的语境信息[6]。
文本情感分类效果除了依赖采用的分类算法以外,另一个重要的影响因素是文本表示中的特征。Tan等人采用了互信息(MI)、信息增益(IG)、卡方检验(CHI)、文档频数(DF)四种特征选择方法和常用的五种分类器,分别进行了中文文本情感分类实验,实验结果表明,IG特征选择方法和SVM分类器的组合得到了最好的分类结果。Kim和Hovy提出了一个句子级别的观点检测系统,通过对观点的定义来获取包含观点的句子和不带观点的词汇,进而用这些词汇识别包含观点的句子。
三、贝叶斯情感分类
1.数据的收集
枫桦论坛是湖南商学院的官方论坛,在本校大学生中间有广泛的知名度和影响力。本文设计并且使用网络爬虫抽取了2011年3月1日-6月30日这段时间该论坛主要板块的所有帖子935条,将这些帖子以HTML文件的形式保存在硬盘上。然后,将其转换成文本的形式,并且抽取文本主体信息、网页地址、发布时间、作者和其他信息。接着,利用通用字典进行分词,进行主题分类,获得文本的主题信息。接着,利用专业的教育字典比较关键字,抽取与本校教学相关的事件,形成教学评价情感数据库。本文采用有监督的文本情感分类方法,选取了两名大学生志愿者通过简单的训练对该数据库中的文本进行情感分类。他们根据每篇文本(评论)的内容,把文本手工标注成好评、差评和不确定三个不同类别。我们选取被他们两人同时分类成好评或差评的那些文本,排除了有争议的文本,这样获得了511个好评文本和317个差评文本。为了避免类别的倾斜,我们随机选取了300个好评文本和300个差评文本建立了包含情感分类标记的实验文档集,下文简称为人工标注结果。为了便于分析试验结果,我们按课程归属把它们分为了理论课和实验课,高年级课程和低年级课程。这里的高年级课是指大学三年级和四年级,而低年级课程则是指属于大学一年级和二年级。文档集的一些具体信息见表1。
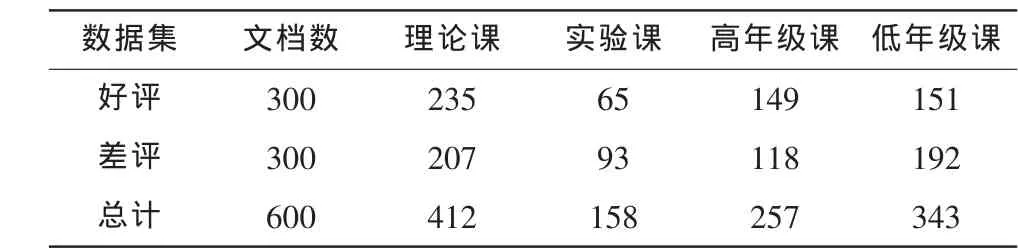
表1 课程信息统计
为了易于对比起见,不作复杂的文本预处理,只是去除英文单词、符号字符和停用词,对分词后的结果抽取单特征词。
2.文本的特征选择
在文本分类中,文本数据通常采用向量空间模型来进行描述。在这个模型中,每一个单词都成为特征空间坐标系中的一维,每一个文本是特征空间中的一个向量,这样一个文档可以表示为di=(xi1,xi2,……,xi|v|),其中V表示整个文档集中出现的不同单词集合,xij表示文档di中单词集V的第j个单词出现的频数。这种表示简单直接,但是也使得文本向量空间变得非常的高维和稀疏,从而使文本分类的性能急剧下降。为了解决这个问题,采用文本特征选择来进行降维成为了文本分类的一个重要的预处理步骤。
信息增益特征选择方法衡量的是某个词的出现与否对判断这个文本是否属于某个类所提供的信息量,在中文文本情感分类应用中取得了很好的效果。在文档二元特征表示下其计算公式如下:
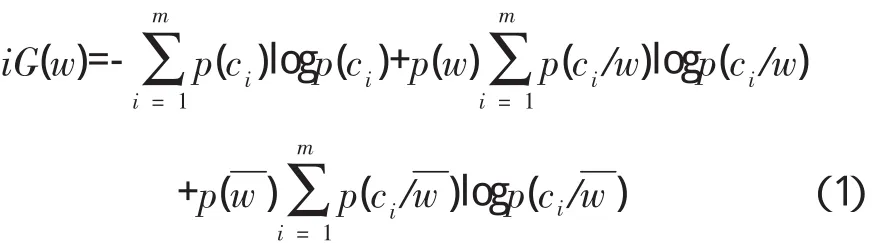
其中,m=2表示好评类和差评类,ci表示一个类别,w和w分别表示某单词在文档中出现和不出现。所有单词按公式(1)计算得到的信息增益的降序排列,本文参考文献[7]中的参数设定,选取那些信息增益大于0.001的单词作为文本的特征向量。
3.贝叶斯分类器
简单贝叶斯分类是一种常用的文本分类方法,它的主要思想是使用单词和类别标记的联合概率来估计给定的文档的分类标记,这种模型的简单性来源于它做出的单词之间相互独立性假设。本文假设文本文档是根据多项事件模型产生的,这样在给定模型参数p(wt/cj)和先验概率p(cj)的条件下,文档di最可能属于的类别概率计算如下:
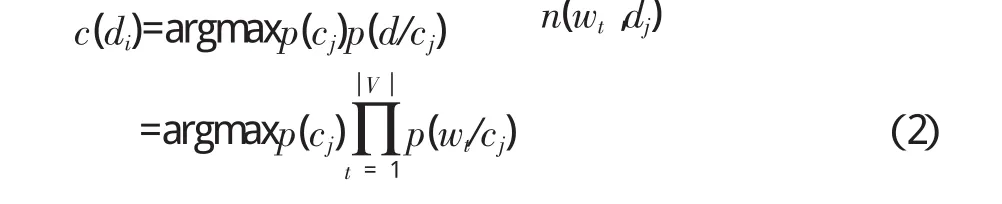

四、教学评论情感分类结果分析
1.性能评价指标
教学评论情感分类的性能评价使用了文本分类和检索中最常用的查准率和查全率,其中查准率是指分类器判别为某个类别的文本中实际属于该类别的文本所占的比例,查全率是指实际属于某个类别的文本中分类器判别为该类别的文本所占的比例。本文中它们的计算公式分别如下:
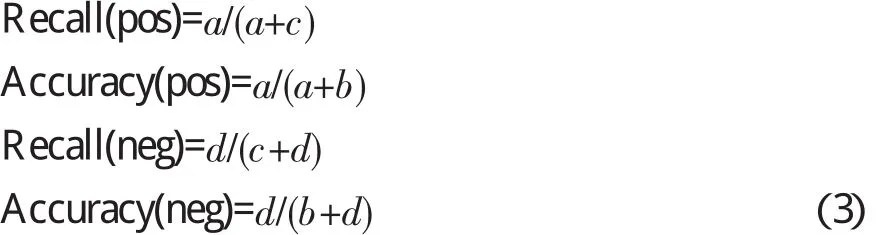
其中a、b、c为列联表2中反映的参数,pos和neg分别表示好评和差评。查准率和查全率分别反映分类器不同方面的性能:查准率反映分类器的准确性,查全率反映分类器的完备性。这两个评价标准通常情况下是互补的,单纯提高其中一个标准会导致另一个标准的下降。理论上讲,一个优良的分类器应该同时具备较高的查准率和查全率。然而实际上,大多数分类器需要在两者之间做出一些折衷,以免其中某个标准过高或过低。测度就混合使用了查全率和查准率,具体公式描述如下:


表2 分类器指派类别-实际情感类别列联表
对于多分类问题,可以使用宏观平均值或者微观平均值两种评价标准评价分类器对整个文本集分类的性能,本文采用宏观平均值作为分类器性能的度量。宏观平均值简称宏平均(Macro-averaging),先利用文本集中每个类别的局部列联表计算分类器对该类别分类的查准率和查全率,然后计算分类器对文本集中所有类别分类查准率和查全率的平均值。文本采用的具体宏平均F1的计算公式如下:

其中C表示文本集中所有类别的集合,|C|表示类别集合C中类别的数目。
2.结果分析
参照3.1小节人工标注的结果,本节首先检验本文提出方法的整体分类性能,然后分别对好评和差评中的课程属性和所属年级的分布进行比较。为了验证整体分类性能的有效性,我们采用简单贝叶斯分类器进行5交叉验证。为了考察文本特征集规模对分类性能的影响,我们在不同规模的文本特征集上分别运行贝叶斯分类器,图1显示了5交叉验证的平均值结果。该图采用原始文本特征集的百分比作为水平轴,宏平均测度为垂直轴。从图1中我们观察到特征选择降维方法可以提高自动教学评论情感分类的性能,具体来说,当选择的特征子集规模达到原始特征的20%时,宏平均的5交叉验证平均值可达到最高值87.3%;在特征子集规模小于原始特征集20%的区间,贝叶斯分类器性能随着特征规模的增加而提高,相反,在特征子集规模大于原始特征集20%的区间,随着特征规模的增加贝叶斯分类器性能反而有下降的趋势。
本文使用10%的统计置信度来检验自动分类结果与人工标志结果中的分布差异,主要考查好评和差评中课程属性和所属年级的分布。具体结果如表3所示,从表中可以看出,最小的卡方检验置信度等于60%,大大超过我们设定的阀值,因此文本自动分类结果和人工标注结果中的分布不存在统计意义上的差异。
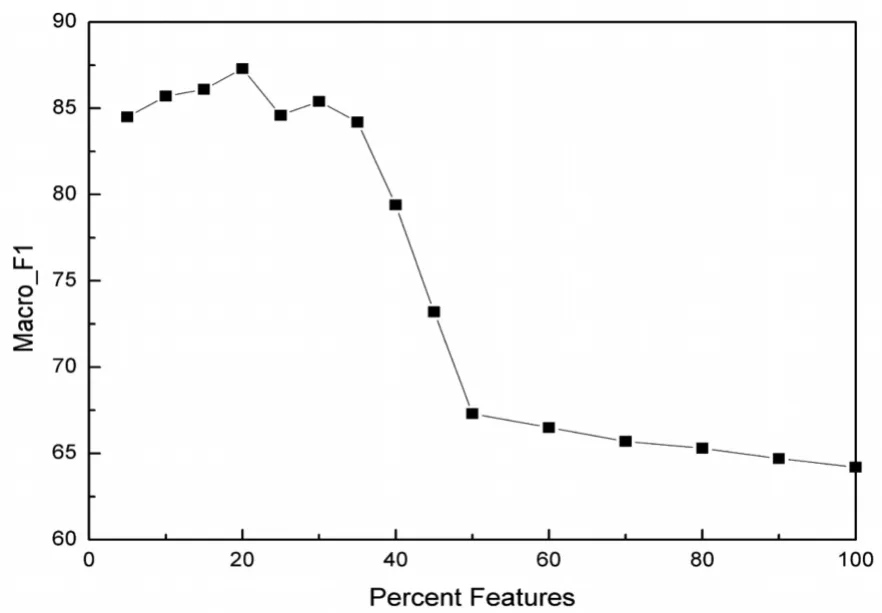
图1 枫桦论坛教学评论的微平均结果
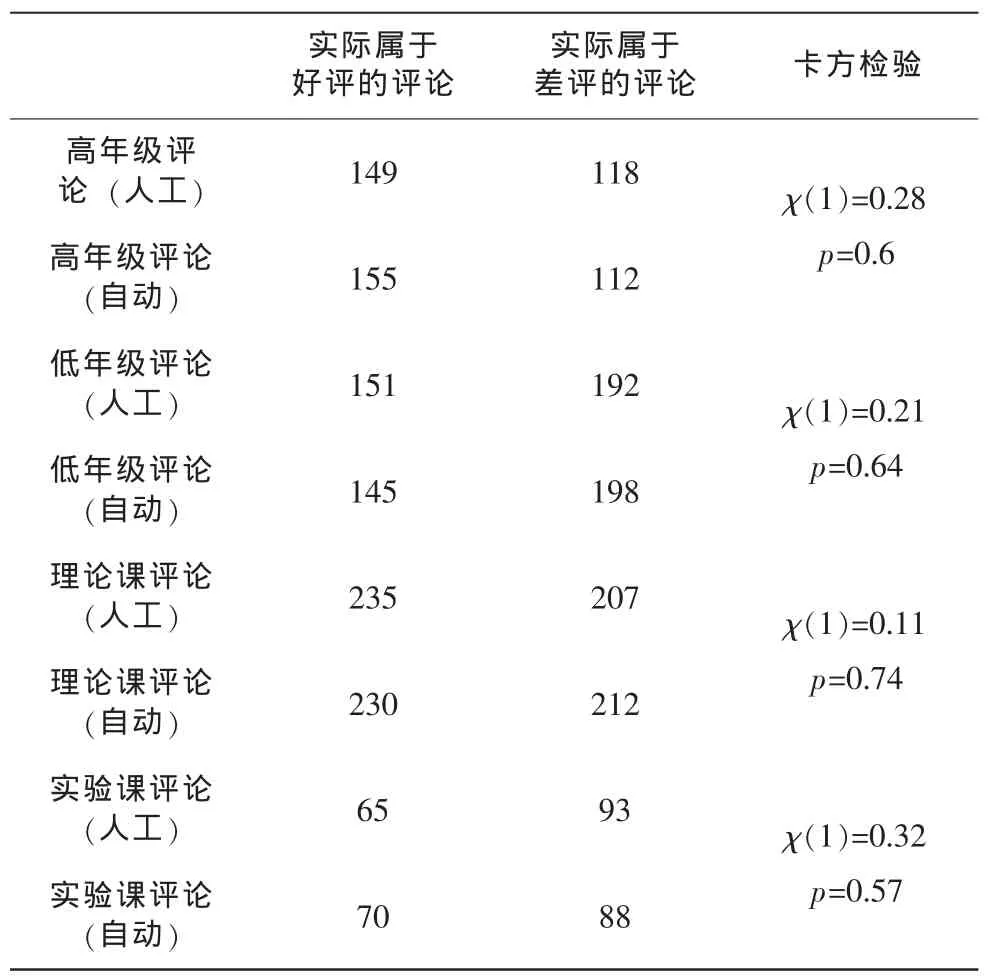
表3 自动情感分类-人工标注分布比较
值得注意的是,无论是人工标注和自动分类的结果都显示高年级同学和低年级同学的教学评价存在明显不同的特点,最主要的差别就是高年级同学正面评价要多于低年级同学;另外实验课的负面反馈要明显多于理论课程。同样我们设定10%的统计置信度来具体分析自动分类结果中这两个分布的差异,具体情况如表4所示:
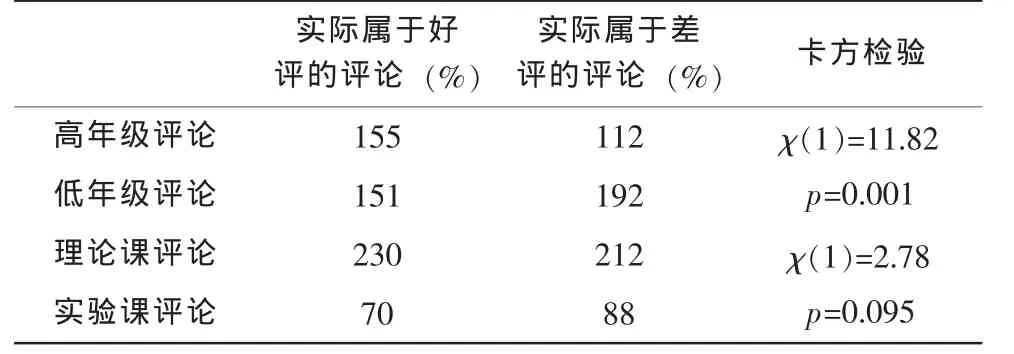
表4 自动分类结果中的分布比较
从表4可以看出,高年级同学评论为好评的比例从统计意义上要高于低年级同学,它们对应的百分比分别为59%和44%;同时理论课获得的好评从统计意义上高于实验课,它们对应的百分比分别为52%和44%。深入分析其原因,我们发现主题词“进度”和贬义情感词“过快”在给出差评的低年级评论中频繁出现,反映了低年级学生从高中较慢的教学节奏过渡到大学较快的教学节奏中存在许多不适应现象,因此低年级学生给出差评比例要高于高年级学生;同时也发现在给出差评的实验课评论中,主题词“辅导”和贬义情感词“过少”则频数出现,表示学生对实验课中获得个别辅导机会少这一现象表示了不满。
五、结束语
为了充分发挥校园网的优势,本文提出了一种教学评论自动情感分类方法,在湖南商学院枫华论坛抽取的教学评论数据集上的实验结果表明了该方法的有效性。下一步的研究目标是将该方法与自动搜索技术相结合,这样就可以无需人的干预,有目的地在校园网论坛上随时收集大学生教学评论信息并且进行情感分类,为教师和教学管理部门实施动态教学管理提供一种新的思路。
[1]Dommeyer,C.J.,Baum,P.and Hanna,R.W..College Students’Attitudes Toward Methods of Collecting Teaching Evaluations:In-Class Versus On-Line.[J].Journal of Education for Business,2002,78(1):11-15.
[2]徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007,21(6):95-100.
[3]Pang,B.,Lee,L.,Vaithyanathan,S..Thumbsup?Sentiment classification using machine learning techniques[C].//Proceedings of the 2002 conference on empiricalmethods in natural language processing.University of Pennsylvania,Philadelphia,USA,Association for Computational Linguistics Stroudsburg,2002:79-86.
[4]Yu,H.,Hatzivassiloglou,V..Towards answering opinion questions:Separating facts from opinions and identifying the polarity of opinion sentences[C].//Proceedings of the 2003 conference on empirical methods in natural language processing.Morristown,NJ,USA.Association forComputational Linguistics,2003:129-136
[5]Turney,P.D.,Littman,M.I..Measuring praise and criticism:inference of semantic orientation from association[J].ACM Transon Information Systems,2003,21(4):315-346.
[6]Kennedy,A.,Inkpen,D..Sentiment classification ofmovie reviews using contextual valence shifters[J].Computational Intelligence,2006(22):110-125.
[7]Tan,S.,Zhang,J..An empirical study of sentiment analysis for Chinese documents[J].Expert System with Applications,2008,34(4):2622-2629.
[8]Kim,S.M.,Hovy,E..Determining the sentimentofopinions[C].//Proceedings of the 20th international conference on Computational Linguistics.University of Geneva,Switzerland,Association for Computational Linguistics Stroudsburg,2004:1367-1373.
[9]李纲,王忠义,寇广增.情感分类中情感词的情感倾向度的计算方法研究[J].情报学报,2011,30(3):292—298.
