High Efficient Methods of Content-based 3D Model Retrieval
2013-03-01WUYuanhaoTIANLingandLIChenggang
WU Yuanhao , TIAN Ling and LI Chenggang
1 Department of Precision Instruments and Mechanology, Tsinghua University, Beijing 100084, China
2 Baidu Online Network Technology (Beijing) Company, Limited, Beijing 100085, China
1 Introduction
With the popularity of computer aided technology, more and more 3D models are accumulated during the daily work of designers. 3D model repository has become valuable knowledge assets of companies. Consequently, 3D model retrieval technology becomes necessary and gains much significance. A survey done by GUNN[1]shows that in the process of new product design, more than 40% of the components and parts can be obtained by directly reusing the existing designs. In addition, designers often refer to existing designs to inspire innovative ideas during conceptual design. Compared to text documentary or handbooks, 3D model may better inspire designers because of its intuitiveness. So for the designers, how to retrieve the 3D model in need efficiently from the huge model repository becomes an important issue.
Text-based search engine is widely used today to retrieve multimedia data, including 3D models. For example, the product data management(PDM) system deployed in many companies provides a way for designers to retrieve the model repository by using the name or number of the models. However, during conceptual design, the designer’s concept is usually not clear enough to get the name of a 3D model, let alone the exact model number. Also, the text-based retrieval interface usually lacks sufficient meaningful description for 3D models. Because of these disadvantages, text-based 3D model retrieval cannot support the designers to reuse 3D models very well.
Content-based 3D model search and retrieval method provides a better way to reuse 3D model. It is especially suited for the conceptual design and industrial design,because the search is based on the shape similarity of 3D models. Designers can find similar models easily and then revise the model to get a new design. The search results are also more instructive to innovative ideas.
Although it is an important issue, at present there is still no commercial content-based 3D model retrieval system.Google provides 3D model search service, but only text query interface is available. On the other hand, lots of researches on the content-based 3D model retrieval were done in the academic field[2–4]. “3D model search engine”developed by Princeton University is the earliest and the most famous prototype system[5], which provides text, 2D sketch, 3D sketch, and 3D model query interface.
In order to measure shape similarity between 3D models,the shape descriptor should first be extracted. A Shape descriptor is in nature the mathematical representation of a shape which a computer is able to process. According to the way they describe the shape, the existing descriptors can be divided into two categories: outline-based descriptor and topology-based descriptor.
Outline-based descriptor is usually extracted by the analysis of the model surface data. For example, by taking proper samples on the model surface, FUNKHOSER, et al[6], used the spherical harmonics to perform transformation and get a feature matrix as the shape descriptor. OASDA, et al[7], proposed a shape distribution(D2) algorithm. They took samples on the distances between two points on the model surface, and then accumulated them into bins of different intervals to form a distance distribution histogram as the model shape descriptor. This histogram based method is widely used due to its robustness under geometric transformation and easiness to implement. Other histogram based methods, for example, Poisson histogram method[8], have also been proposed to extract shape descriptors after D2 algorithm.However, D2 algorithm still has limitations. Lots of research works have been done to improve the accuracy of D2 algorithm. For instance, in D2 algorithm, the point sampling is area weighted and depends on the structure of the model surface. To solve this problem, SHIH, et al[9],combined the exterior and interior shape features to improve accuracy of the algorithm; BIAN, et al[10],developed a new method named “Volume D2”, which instead use volumetric distributions to calculate the shape descriptors; ZHANG, et al[11], gave a preprocess method on the model which can be performed before the sampling process of D2 algorithm. Another problem with D2 is that it has low discriminating capabilities when the models become complicated. A typical work to solve this issue was done by CHENG, et al[12]. They combined the D2 method and the negative feature decomposition, and then propose a hierarchical algorithm to measure shape similarity between complicated CAD models.
Topology-based descriptor, which is extracted from the topology structure of the 3D model, usually has more semantic information than the outline-based descriptor. For example, HILAGA, et al[13], proposed a Reeb graph based method. By decomposing the model into subsections and detecting the connectivity of the subsections, it can produce a Reeb graph to describe the shape. El-MEHALAWI, et al[14–15], developed an algorithm to extract a topology graph with attributes from the STEP format of CAD models,which are represented by B-rep method. GOH[16]gave a discussion on the strategies to improve the shape matching method using skeletons.
The above methods to extract shape descriptor are mainly general methods. Researchers also propose some special methods which are suited for the shape comparison between mechanical part models. Examples can be obtained in Refs. [17–18]. The main ideas of these works are to combine the general descriptor extraction algorithm with the special feature of mechanical parts, e.g., the assembly feature, so as to gain more accuracy.
Model repository index is another vital technology to build content-based 3D model search engine, especially when the number of models becomes large, as it will take too much time to compare each model in the repository.Traditional inverted index used in text retrieval systems is not fit for the content-based 3D model retrieval because of the particularity of the shape descriptor. Different descriptors need different index methods. For the descriptors with the form of a vector, index methods of vector space can be used. LOU, et al[19], used the R-tree to build the 3D model index and the performance of the index is also studied. Cluster is another index method fitting for the vector space. LI, et al[20], developed a 3D model retrieval index, based on the hierarchical clustering algorithm and special dealing with isolated clusters. For other kinds of descriptors, researchers need to develop corresponding index according to their shape descriptors.HORIKOSHI, et al[21], used the quadratic curves fitting the model surface to describe the shape, and build an index on the set of quadratic curves to facilitate the retrieval process.IYER, et al[22–23], used the skeleton graph as the shape descriptor, and build an index on the model repository through the edge and ring feature in the model graph. A decision tree is used when searching similar models.
The previous works have built a good foundation, but drawbacks still exist. The time complexity of present shape descriptor extraction methods is still too high, especially to extract the topology-based descriptor. Although topologybased descriptor can describe the shape of 3D model in a high sematic level, to compare two different graphs precisely is a NP-hard problem, which means it is not likely to be implemented in industries. Though D2 algorithm is widely used, there have been few studies to improve the efficiency of D2 algorithm. Most improvements made on the existing descriptor extraction methods focus on the distinguish accuracy. As for the model repository index method, fewer researches have been done compared with the researches on the method of shape description.Moreover, graph-based index also has low efficiency because it still needs to make comparisons between graphs.Index built on the graph also has the precision problem,because local shape feature cannot represent the whole shape. Vector space index methods, such as the R-tree,always face the problem of low performance when the vector’s dimension becomes big, which is very common for the shape descriptor.
This paper focuses on high efficient methods of both shape descriptor extraction and 3D model repository index.A new algorithm named “Quick D2”, which greatly reduces the time cost of D2 algorithm, is proposed. Then an index,namely, RBK index with tree structure is built on the 3D model repository. Compared to the linear index, searching with RBK index can efficiently prune the search space and speed up the model retrieval process. Finally, on the basis of the above work, a 3D model retrieval system is developed and applied in a manufacturing enterprise. The time cost for the system to respond one query online is tested and practical query examples during a case of the automobile rear axle design are shown.
2 Shape Descriptor Extraction
Shape descriptor extraction is to build the map from the shape space human understand to the mathematical representation space a computer is able to process. Based on shape descriptor, similarity between shapes can be measured quantitatively. D2 algorithm[7]is a widely used shape descriptor extraction algorithm. The main steps are as follows.
Step (1): Take N2samples of the distance between two points on the model surface, where N is usually 1 024.
Step (2): Standardize the distances contained in the sample, and then allocate the distances into bins of different value intervals, which results in a discrete distance distribution of the 3D model. Let V be the number of bins,which is usually 64, then the distribution is a V-dimensional vector mathematically.
Step (3): Use the V-dimensional vector as the model’s shape descriptor and the Minkowski one-order distance between two vectors as the shape similarity measurement.
Because D2 algorithm only depends on the distances between two points on the model surface and the values of distances are standardized, the descriptor extracted by D2 will be stable to the geometric translation, scale, and rotation of the model. Moreover, D2 algorithm is robust to the partial differences or small damages of models, if the sample size is large enough. So D2 algorithm is widely adopted after it was proposed, and lots of works[9–12]have been done to improve D2 algorithm. However, as discussed in the section 1, the emphasis of the previous works is to improve the accuracy limitation. In this section, an improvement on the efficiency of D2 algorithm will be shown.
2.1 Quick D2 algorithm
Let F be the number of faces a model consists of and N2be the size of distance samples. Taking N2distances needs to get 2N2points on the surface of the model. The operation of getting one point randomly with respect to the face area in D2 algorithm has the time complexity of O(lg(F)). Thus,the time complexity of whole sample generation is O(2N2lg(F)). Considering the sample size is large, it is not hard to imagine that replicate points exist, leading to unnecessary time cost. So one way to reduce the time complexity of D2 algorithm is reducing the number of points needed to get.
Based on the above idea, “Quick D2” algorithm is developed, which spilt the sample generation process of D2 algorithm into two steps.
Step (1) : Take N samples of the points on the surface of the model.
Step (2) : Calculate the distances between every two points of the N points, which will produce N(N–1)/2 distance samples.
The key of Quick D2 algorithm is to take samples on the points instead of the distances, so the number of points that the algorithm need to get is greatly reduced. As analyzed before, taking one point has the time complexity of O(lg(F)), so the sample generation process of QuickD2 algorithm has the time complexity of O(Nlg(F)), compared to O(2N2lg(F)) of D2 algorithm. On the other hand, we don’t lose many distances, because the N points will provide N(N – 1)/2 distances compared with the N2distances in D2 algorithm. Moreover, because the points are also randomly sampled, the distance distribution histogram should represent the shape just as D2 algorithm,which will be shown in the next subsection.
Quick D2 algorithm only changes the sampling phase of the D2 algorithm, and keeps other procedures same with D2 algorithm. That means Quick D2 algorithm not only can be applied to improve the efficiency of D2, but also can be applied to improve the efficiency of some algorithms which are based on D2. For example, the method proposed in Ref.[12] contains one procedure that uses D2 algorithm to extract descriptors of simple unit models. If D2 algorithm is replaced by Quick D2 algorithm in this procedure, the efficiency of the whole method will be better while there is no need to change other parts of the whole method.
2.2 Comparison
In this subsection, the D2 and Quick D2 algorithm are compared from two aspects: the time efficiency and the shape descriptors they extract from the same model. Four CAD models from the engineer shape benchmark (ESB)[24]developed by Purdue University were used as test cases.Fig. 1 shows the snapshot of the four CAD models.
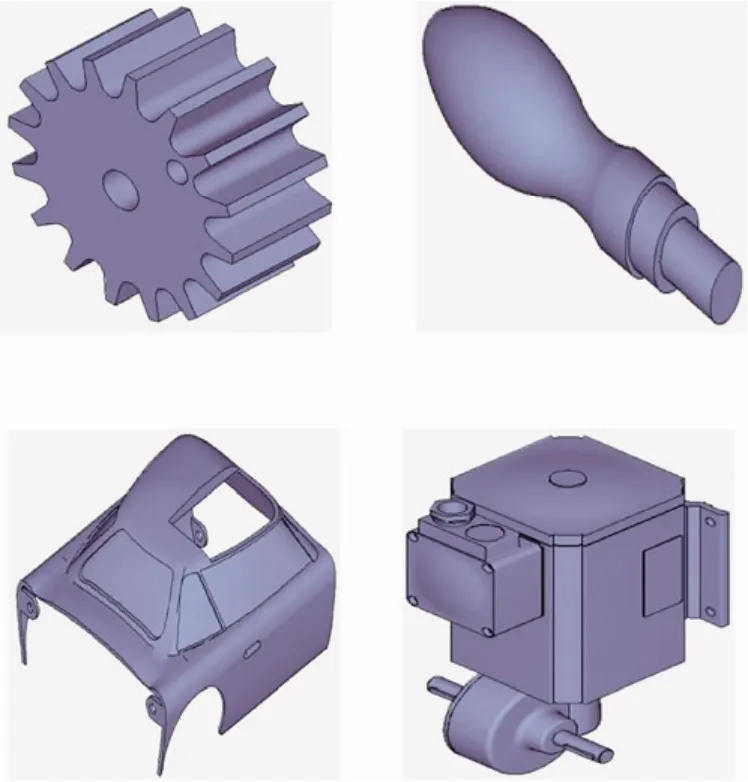
Fig. 1. Test CAD models form the ESB
Both the D2 and Quick D2 algorithm were tested to extract the shape descriptors of the four models. The time costs are shown in Table 1. Results show that, just as analyzed before, Quick D2 algorithm is much faster than D2 algorithm. To be more precise, all the models from ESB were tested to compare the time efficiency. The average time of extracting the descriptors of all the models from ESB Quick D2 used is 0.068s while for D2 it is 0.933s, so the time efficiency of D2 algorithm is improved 14 times approximately by using Quick D2 algorithm.
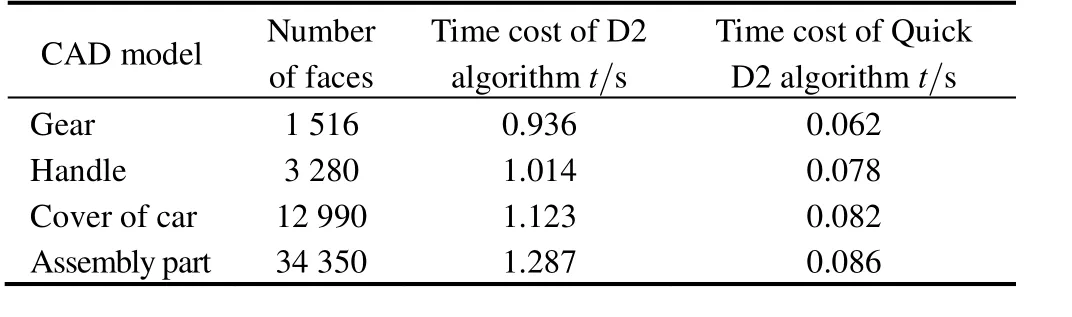
Table 1. Comparison of the time cost between D2 algorithm and Quick D2 algorithm
Fig. 2 shows the descriptors of the four test models extracted by the two algorithms. The descriptors are demonstrated as the discrete distance histograms. The line with solid squares and the line with open circles are the results of Quick D2 and D2 algorithm respectively. Notice that both the two algorithms are based on statistical method,so the results will be slightly different every time the two algorithm run. However, results show the extracted descriptors of the two algorithms are almost the same,which prove the effectiveness of Quick D2 algorithm.
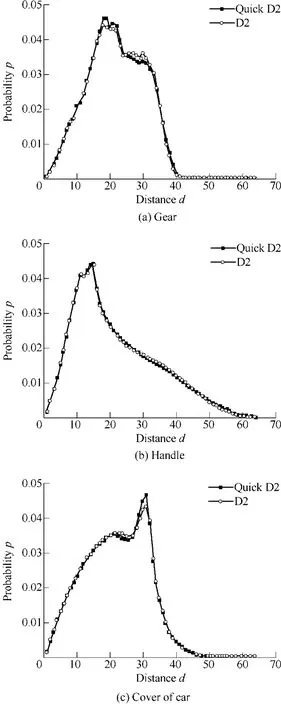
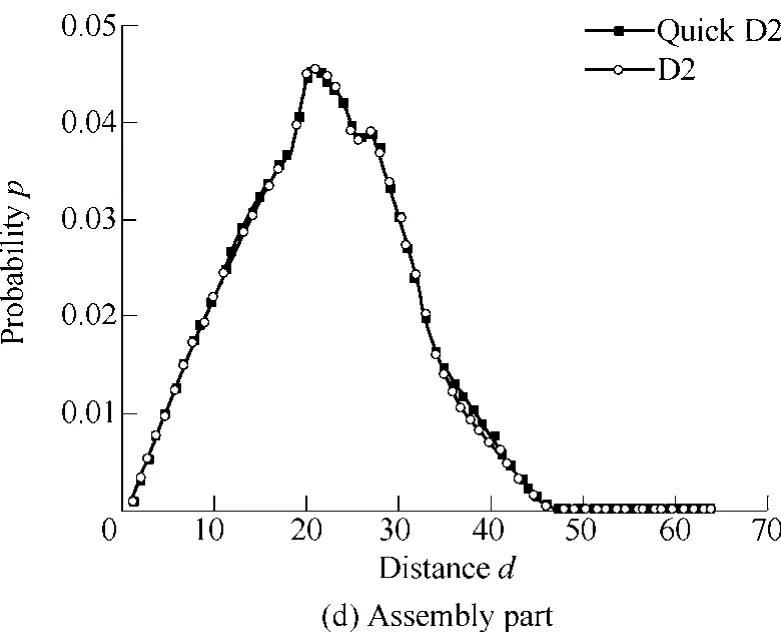
Fig. 2. Comparison of the descriptors extracted by D2 algorithm and Quick D2 algorithm
3 Model Repository Index
As described in the previous section, the shape descriptor extracted by Quick D2 algorithm is a V-dimensional vector.The Minkowski one-order distance between two vectors could be used as shape similarity measurement. To be specific, the similarity function d between two descriptors is defined as follows:
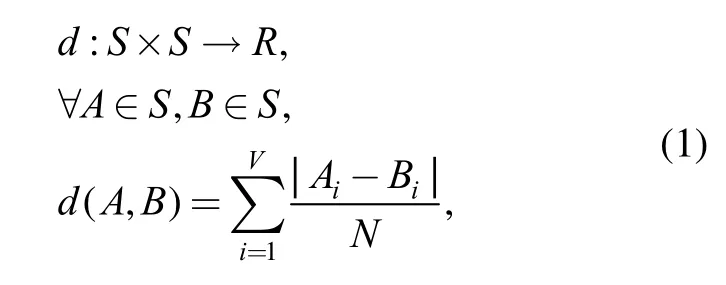
where S is the set of all descriptors of 3D models in the repository; A and B are any two model descriptors form set S; R denotes the set of real numbers; N denotes the total number of distances in the distance samples in Quick D2 algorithm.
So the content-based 3D model retrieval problem can be described as: For a given model T, find K models in set S having the least distance from T. Of course all the distances between T and every model from set S can be calculated,and then the required K models with smallest distances will be owned. Nevertheless, it is obviously too time-consuming when the number of models in set S is large. Pretreatment on set S should be done so as to speed up the searching process, and here, it is to build an index.
3.1 RBK index
BK tree is a structure proposed by BUKHARD and KELLER[25]to tackle the string matching problem. It is built on the metric space with a discrete distance function.However, as defined before, the distance function d between shape descriptors is continuous. In order to build an index on the model repository, a new structure named RBK tree (Range BK tree) is proposed, which is also suitable in the metric space with a continuous distance function.
First we prove that the descriptor’s set S with the similarity function d defined by Eq. (1) is a metric space,i.e., the following expressions are true:
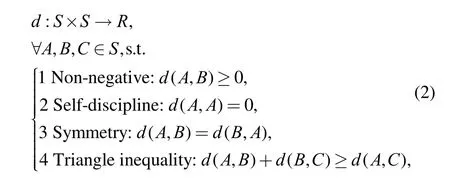
where A, B, C are any different descriptors from the descriptor’s set S. The first three properties are easy to prove. The triangle inequality can be proved as follows:
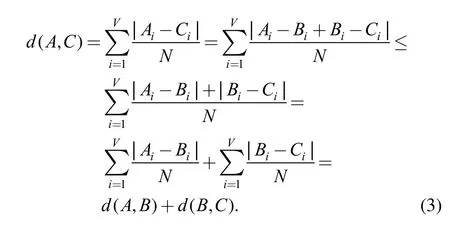
Suppose that the models which have distances smaller than r from the given model T should be returned. In other words, we need to find a subset of S, in which every model x is subject to

According to the triangle inequality property, for any model A in set S, the distance between model x which is subject to Eq. (4) and model A will have the following properties:
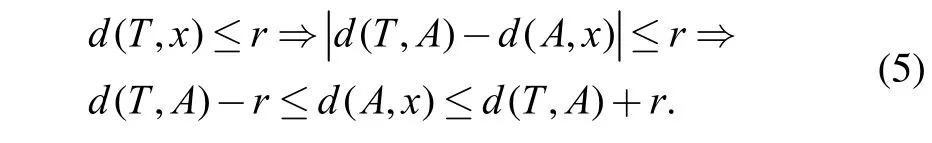
This means to find model x with distances less than r from a given model, the distance between model x and model A must locate in the interval
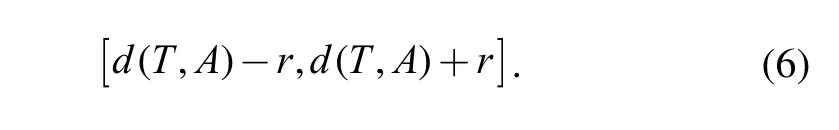
If the distances between model A and all the other models are calculated in advance, then the models that do not satisfy Eq. (5) can be passed right away. Only the models satisfying Eq. (5) need to be processed then.Following this idea, the RBK index can be constructed by the following steps.
Step (1) : Initialize the current subset as the whole set S,and initialize the parameter t which denotes the number of branches every parent node has.
Step (2): Calculate the number of the models in the current subset. The Number is denoted by N.
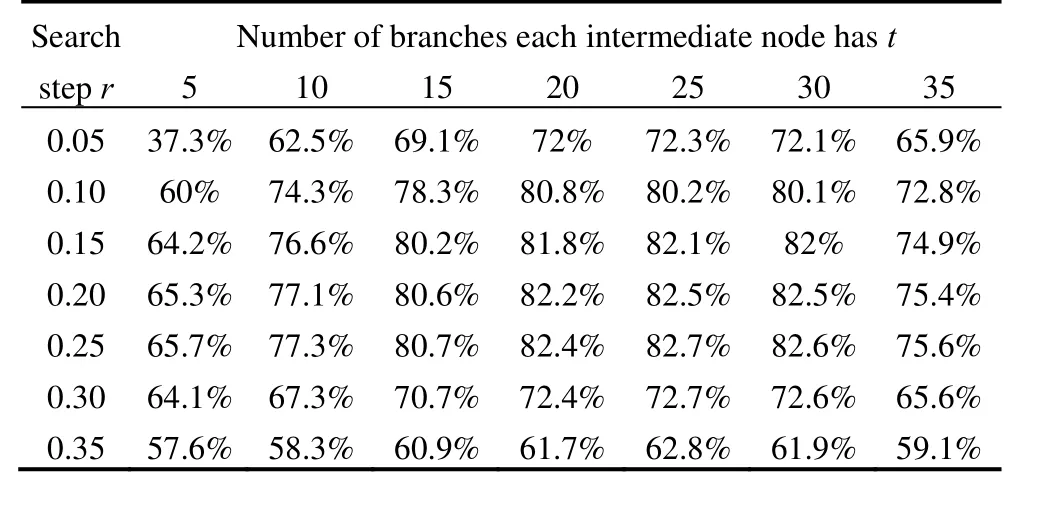
Step (3) : If N Step (4):Select one model as the root node of the current subset, and calculate the distances between the root model an all the other models in the subset. Step (5): Find the maximum of the distances and split the interval [0, max] to t intervals with the equal width, namely,[0, max/t], [max/t, 2max/t]…[(t–1)max/t, max]. Step (6): According to the intervals they locate, separate all the other models into t subsets. Make all the subsets the child node of the root in the current sub-set. Step (7):Process every subset as the current subset and return to step (2) recursively. After the RBK index being built, range retrieval on the model repository can be done efficiently using the range retrieval algorithm below. Step (1): Initialize an empty result list to contain search results and an empty queue to contain the nodes waiting to be visited. Initialize the distance threshold r and target model T. Step (2): Push the root of RBK index into the queue. Step (3) : Pop one node as the current node from the queue. If the queue is empty, then the search process is finished. Return the result list. Step (4): Calculate the distance d between T and the current node. If the distance is smaller than or equal to r,put the current node in the result list. Step (5) : If the current node is leaf node, return to step(3). Step (6): Put the child nodes of the current node into the queue, if the distance interval where the child nodes locate has intersection with the interval [d−r, d+r]. Return to step(3). To illustrate how the range retrieval algorithm works,suppose there are only 9 models in the repository, and the RBK tree has already been built through the construction algorithm, which is as Fig. 3(a) shows. A, B,…, I are the nine models, and the interval on each branch is the distance range between the parent node and all child nodes in the branch. Suppose the given model is T, and the distance threshold r is initialized as 0.1. First calculate the distance between root node A and T, suppose it is 0.3, then the validated interval is [0.2, 0.4], which means the sub-tree with C as the root can be pruned. Then move to the left sub-tree.Calculate the distance between B and T, suppose it is 0.4,then the validated interval is now [0.3, 0.5], which means the sub-tree with D as the root can be pruned too. Then move to the right sub-tree. Calculate the distance between E and T, suppose it is also 0.4, then the validated interval is now [0.3, 0.5]. All the sub-trees of node E have intersection with the validated interval, so all the sub-trees need to be visited. Since H and I are all just leaf nodes, calculate the distances between them and T, suppose the results are 0.05 and 0.2 respectively, then the only model with the distance from T less than 0.1 is found, and that is model H. Looking back we find that, as Fig. 3(b) shows, among the nine models, by using RBK tree only five models need to be visited to get the expected result, and the efficiency will be better promoted when there are more models. Fig. 3. Illustrative example of range retrieval on RBK index There is still one thing needs to be noted. The search algorithm which is developed based on RBK index is a range retrieval method while for model retrieval it is a K nearest neighbor search. The risk exists that less than K models can be found if the distance threshold r is initialized too small. To solve the problem, r, 2r, 3r…will be used as the distance threshold sequentially, until all the K nearest models are owned. So the parameter r is used as the search range step. Of course, the step should be chosen carefully,and this is part of the discussion shown in next subsection. There are two parameters that determine the performance of RBK index. One is the number of branches each intermediate node has in the RBK tree, namely, t; the other is the search range step, namely, r. The value of the two parameters should be chosen properly. Too large or too small value of the parameter t and r will lead to lower performance of RBK index, which will be illustrated and analyzed by an experiment later. Each 3D model in the repository can be abstracted to a point in the metric space S. When the RBK index is under construction, it is not the exact coordinates of each model that matter, but the distances between the models. So the values of distances between the models have an important impact on the optimal values of the two parameters. A fact which can be found easily is that the optimal value of search range step r should be doubled while t should be unchanging, if all the values of distances are doubled.Another factor that affects the value of the two parameters is the parameter k which stands for the number of models need to be returned in one query. Parameter r should be positively correlated with k, because the distance threshold should be larger so that more models can be included in the results returned. The last factor is the total number of the models in the repository. Every model in the repository will be one node of the RBK tree. Suppose the total number of models grows bigger and bigger, the parameter t, which stands for the number of branches each intermediate node has, should also be growing to prevent linearization of the tree structure. On the other hand, the parameter r tends to be small, because the quantity of models meeting the same distance threshold requirement tends to grow. Although the factors that influence the value of two parameters can be analyzed qualitatively as above, it is still hard to find the theoretical optimal solution of t and r because of the complexity of constructing RBK index.However, the experiment shown below provides a way to find optimum values of the two parameters. Note that although the following is an experimental method, it still has regularity. It can be applied to any 3D model repository and can be implemented easily. The values of t and r obtained by the experiment are not accurately the optimal values, but they are good enough to be used in practice. First, a benchmark named prune rate is defined to evaluate the performance of RBK index. Prune rate is the percentage of the number of unvisited nodes among the total number of nodes in one query. Apparently, the larger the prune rate, the higher the retrieval efficiency. Therefore the main idea of the experiment is to calculate the average prune rates of the system under different values of parameter t and r, and then find the largest one. Particularly,in this experiment, parameter t takes the test values of 5, 10,15, 25, 30, 40 and 50, and parameter r takes the test values of 0.05, 0.10, 0.15, 0.20, 0.25, 0.30 and 0.35 (Notice that the largest distance between models in the whole repository is 2). Every model in the repository is used as the query model and prune rate is calculated with different t and r values. Then the average values of prune rate with different t and r are calculated, which are shown in Table 2. Table 2. Average prune rate under different parameter t and r The results in Table 2 show that average prune rate grows when t grows until t is larger than 25, and so is r until r is larger than 0.30. So the best prune rate is reached at t=25 and r=0.25, which is 82.7%. It means that by using RBK index with proper parameters, fewer than 17% of all the models need to be visited for one query on average. It is a great improvement on the retrieval efficiency. Such variation rule of the prune rate can be explained as below. Parameter t stands for the number of branches each node has in RBK tree. If t is small, the quantity of model in each branch will be large and then more models turn to be visited during the search process. For the extreme case, if t equals to 1, the tree will be a vertical linear chain and therefore prune rate will be 0. On the other hand, if t is too large, the RBK tree will turn to be a horizontal linear chain,which will lead to low prune rate too. Parameter r is the distance threshold growing step. It is not hard to notice that if r is too large, prune rate will be low because there are more sub-trees satisfying the request distance. However,the risk that one search process cannot find all K nearest models grows as r becomes small, so the prune rate will also decrease when r becomes small. The Quick D2 algorithm and RBK tree index are implemented in a content-based 3D model retrieval system called “3D Searcher”, which is developed to facilitate the reuse of existing designed models. Fig. 4 shows the homepage of 3D Searcher. It contains four functional components. The first is 3D model search component, which provides both the text query interface and the 3D model query interface. Similar search on the returned result and online browse of 3D model are also enabled. The second is 3D model resources management component, through which the system manager can examine the status of the repository, add new models manually, and launch the web crawler to download the 3D models on the Internet. The third is index management component, through which system managers can refresh or rebuild the RBK index of the model repository. The last one is system configuration component, through which the system manager can configure the authority of different designers, the store path of repository, and the parameters of the RBK tree index, etc. Fig. 4. Homepage of 3D Searcher The efficiency of the developed system is promoted both online and offline by the methods proposed in this paper.For offline, with Quick D2 algorithm, the shape descriptor extracting process of handling close to three thousands models takes about 39s, compared to more than 300s with D2 algorithm before. The online retrieval process includes two procedures: to extract the descriptor of the input query model and to find the similar models. Quick D2 algorithm and RBK index can speed up the two procedures respectively. A test was carried out to validate the online efficiency of the system. Ten models selected randomly were taken as the query models. For each query, the time costs of 3D Searcher and a comparison system which was developed using D2 algorithm and linear index were recorded. The results are shown in Table 3. As expected,the online retrieval efficiency of developed 3D Searcher is much better than the comparison system due to the Quick D2 algorithm and RBK index. The average time cost of 3D Searcher to respond one query is 0.453s. It is only about a quarter of average time cost of the latter system, which is 1.634 s. Table 3. Comparison of the online retrieval time cost of two systems 3D Searcher can aid designers in two ways. On one hand,at the beginning of conceptual design, designers can search models through the key words, e.g. the design domain key words, category of the desired model, etc. Some problems,such as low recall rate and low accuracy, may exist in text query, but designers can use the similar search function on the good search results returned by text query. After designers having found the satisfied model, they can browse the model and check the design parameters of the model online. On the other hand, if the design concept is formed, designers can build a rough model quickly through other modeling systems and upload it to 3DSearcher to check whether there are similar designs. As stated before,more than 40% of the components and parts can be obtained by directly reusing the existing design, so it is meaningful for designers to improve the design efficiency. The system has already been applied in an auto parts production enterprise. Currently the model repository has close to three thousands models from both Internet and the enterprise databases. Here is an illustrative example. First designer uses “auto rear axle” as the key words to search the model repository. The results are shown in Fig. 5 and they are the existing parts related to the auto rear axle.Designers can find the models of interest and browse them online, as Fig. 5 shows. Designers can also use the similar search function on the models of interest to find more models. All the existing design models are of great help to inspire designers. Fig. 6 also shows designers using the 3D model query interface to find similar models. If designers have the model that is close to what he or she wants to design, it is convenient to find other similar designs. Fig. 5. Using key word query in 3D Searcher system Fig. 6. Using 3D model query in 3D Searcher system This paper is concentrated on the high efficient methods to build a content-based 3D model retrieval system. Two new methods, which are concerned with the shape descriptor extraction and model repository index respectively, are presented. The conclusions are as follows: (1) The proposed Quick D2 algorithm is more efficient than D2 algorithm. Experiment shows the time cost using Quick D2 algorithm is reduced by 14 times on average while the descriptor extracted is the same as that of the D2 algorithm. (2) The RBK index constructed on the 3D model repository can significantly improve the retrieve efficiency.The presented experimental method could be implemented to find the optimal value of parameters of RBK index. With proper parameters, the average prune rate can be as high as 82.7%, as the experiment shows. (3) “3D Searcher”, a content-based 3D model retrieval system, is developed in this paper. With the two methods proposed in this paper, the online time taken by 3D Searcher to respond one query is reduced by 75% on average. The 3D searcher system has already been applied into an auto parts production enterprise. It is helpful to inspire designers during conceptual design and to facilitate the reuse of existing designs. [1] GUNN T G. The Mechanization of design and manufacturing[J].Scientific American, 1982, 247(3): 114–130. [2] IYER N, JAYANTI S, LOU K Y, et al. Three-dimensional shape searching: state-of-the-art review and future trends[J]. Computer-Aided Design, 2005, 37(5): 509–530. [3] ZHENG B C, PENG W, ZHANG Y, et al. A Survey on 3D model retrieval techniques[J]. Journal of Computer-Aided Design &Computer Graphics, 2004, 16(7): 873–881. (in Chinese) [4] JOHAN W H, TANGELDER R C, VEKTKAMP. A survey of content based 3D shape retrieval methods[J]. Multimedia Tools and Applications, 2008, 39(5): 441–471. [5] MIN P. A 3D model search engine[D]. Princeton: Princeton University, 2004. [6] FUNKHOUSER T, MIN P, KAZHDAN M, et al. A search engine for 3D models[J]. ACM Transactions on Graphics, 2003, 22(1): 83–105. [7] OSADA R, FUNKHOUSER T, CHAZELLE B, et al. Shape distributions[J]. ACM Transactions on Graphics, 2002, 21(4):807–832. [8] PAN Xiang, YOU Qian, LIU Zhi, et al. 3D shape retrieval by Poisson histogram[J]. Patten Recognition Letters, 2011, 32(6):787–794. [9] SHIH J L, CHEN H Y. A 3D model retrieval approach using the interior and exterior 3D shape information[J]. Multimedia Tools and Applications, 2009, 43(1): 45–62. [10] BIAN Q W, WANG J L, HE Y J. Retrieval 3D shapes using volume D2[J]. Electronic Letters, 2009, 45(23): 1 163–1 165. [11] ZHANG Ming, LI Juan. Improved shape distribution retrieval algorithm of 3D models[J]. Journal of Computer Applications, 2012,32(5): 1 276–1 279. (in Chinese) [12] CHENG H C, LO C H, CHU C H, et al. Shape similarity measurement for 3D mechanical part using D2 shape distribution and negative feature decomposition[J]. Computers in Industry, 2011,62(3): 269–280. [13] HILAGA M, SHINAGAWA Y, KOHMURA T, et al. Topology matching for fully automatic similarity estimation of 3D shapes[C]//Proceedings of the 28 Annual Conference on Computer Graphics and Interactive Techniques, New York, USA, August 12–17, 2001:203–212. [14] EI-MEHAKAWI M, MILLER R A. A database system of mechanical components based on geometric and topological similarity. Part I: representation[J]. Computer–Aided Design, 2003,35(1): 83–94. [15] EI-MEHAKAWI M, MILLER R A. A database system of mechanical components based on geometric and topological similarity. Part II: indexing, retrieval, matching and similarity assessment[J]. Computer–Aided Design, 2003, 35(1): 95–105. [16] GOH W B. Strategies for shape matching using skeletons[J].Computer Vision and Image Understanding, 2008, 110(3): 326–345. [17] XU Jinghua, ZHANG Shuyou. 3D shape and structure retrieval method of mechanical parts based on recursive segmentation[J].Journal of Mechanical Engineering, 2009, 45(11): 176–183. (in Chinese) [18] DONG Yan, XU Jing. Part 3D model retrieval method based on assembly structure similarity[J]. Journal of Mechanical Engineering,2009, 45(4): 273–280. (in Chinese) [19] LOU K Y, IYER N, JAYANTI S, et al. Supporting effective and efficient three-dimensional shape retrieval[C]// Proceeding of the TMCE, Lausanne, Switzerland, April 13–17, 2004: 199–210. [20] LI Xiaofang, WU Zhongke, FAN Yachun, et al. Using fast neighbor query in 3D model retrieval[J]. Journal of Beijing Normal University(Natural Science), 2011, 47(5): 473–477. (in Chinese) [21] HORIKOSHI T, KASAHARA H. 3D shape indexing language[C]//Conference Proceedings of Ninth Annual International Conference on Computers and Communications, Scottsdale, USA, March 21–23,1990: 493-499. [22] IYER N, KALYANARAMAN Y, LOU K Y, et al. A reconfigurable 3D engineering shape search system Part I: shape representation[C]//Proceedings of ASME DETC, Chicago, Illinois, USA, September 2–6, 2003: 89–98. [23] IYER N, KALYANARAMAN Y, LOU K Y, et al. A reconfigurable 3D engineering shape search system Part II: database indexing,retrieval, and clustering [C]// Proceedings of ASME DETC, Chicago,Illinois, USA, 2003: 169–178. [24] JAYANTI S, KALYANARAMAN Y, IYER N, et al. Developing an engineering shape benchmark for CAD models[J]. Computer-Aided Design, 2006, 38(9): 939–953. [25] BURHARD W A, KELLER R M. Approaches to best-match file searching[J]. Communications of the ACM, 1973, 16(4): 230–236.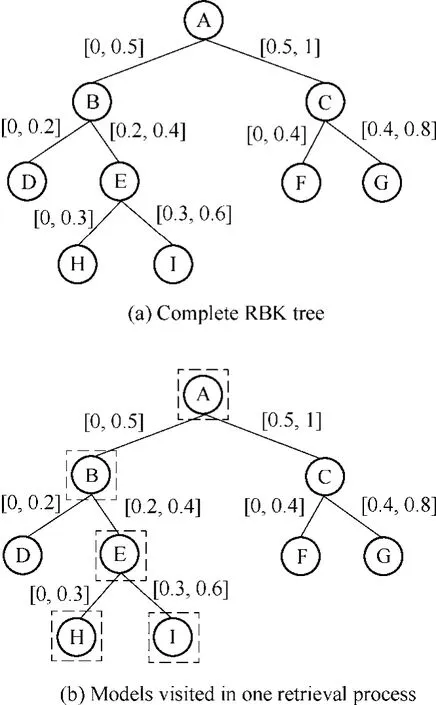
3.2 Parameters Selection and Validation of RBK index
4 Implementation and Illustrative Examples
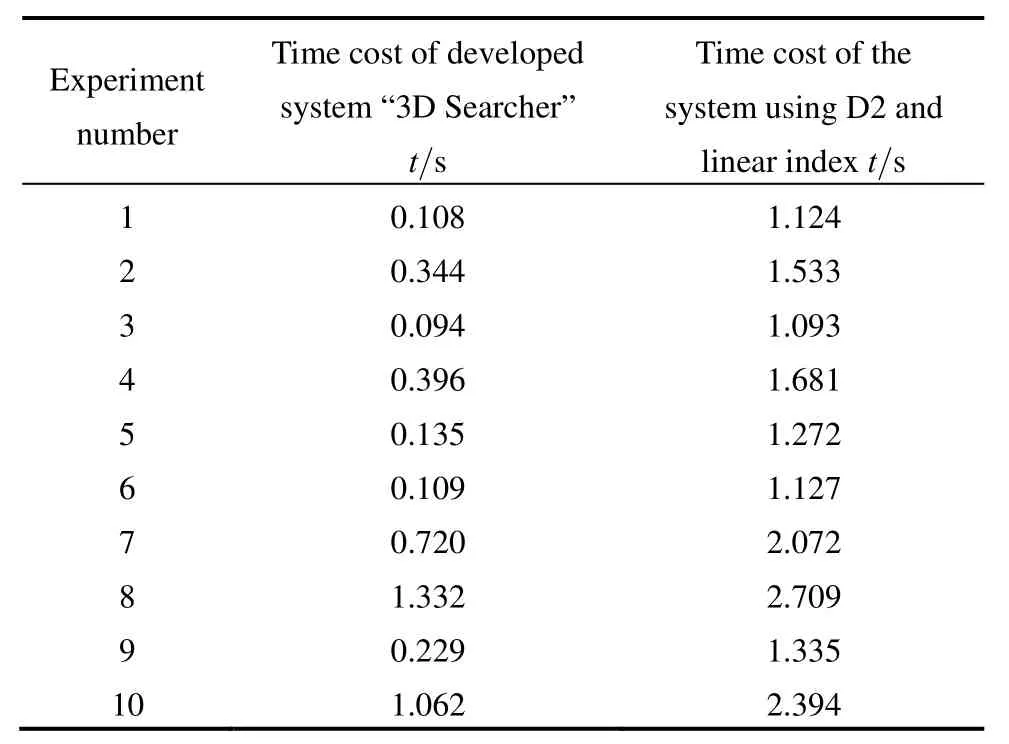
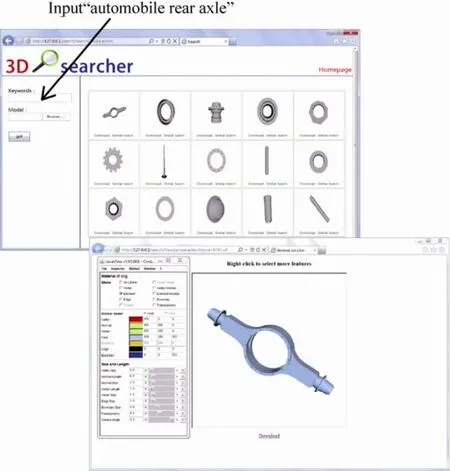
5 Conclusions
杂志排行

Chinese Journal of Mechanical Engineering的其它文章
- Metamorphic Manipulating Mechanism Design for MCCB Using Index Reduced Iteration
- Innovative Group-Decoupling Design of a Segment Erector Based on GF Set Theory
- Sewerage Force Adjustment Technology for Energy Conservation in Vacuum Sanitation Systems
- Simulation Research on the Effect of Cooled EGR, Supercharging and Compression Ratio on Downsized SI Engine Knock