数据驱动模式在英语写作教学中的运用*
2013-02-26张德凤
张德凤
(北京农学院外语教学部,北京102206)
一、引言
根据教育部颁布的《大学英语课程要求》,大学英语的教学目标是培养学生英语综合应用能力,即学生的听说读写译能力(教育部高等教育司2007)。然而,我国大学英语写作教学举步维艰,学生的写作水平止步于模板式作文,从篇章结构到词汇选择几乎千篇一律(郝军、田巍2009:161),导致大学生英文写作成绩普遍较差,学生的作文能力很欠缺。因此,如何提高学生的写作能力是一个值得研究的课题。
数据驱动学习(data driven learning,简称DDL)是美国学者Tim Johns在20世纪90年代初期提出的一种基于语料库的外语学习方法。语料库数据驱动学习是以建构主义理论和语言习得理论为依据,主张将语料库中丰富的真实语言作为输入提供给学习者,来为他们创造真实的语言学习环境(Granger 1998:199)。此方法还将语言学习者视为“语言研究者”(John 1991:2)。数据驱动学习并不是直接教授某一语言特征,而是向学生提供语言事实,学生通过对索引行观察、分析和比较最终归纳语言使用规律,从而运用正确的语言进行写作。
数据驱动学习方法是一新型外语学习方法。国内有不少学者对语料库数据驱动学习在英语词汇教学中的运用进行了研究,王均松就数据驱动学习模式在词汇自主学习能力培养方面进行了研究(王均松2010:24),张北镇,周江林就数据驱动学习的课堂实现模式效果进行了研究(张北镇,周江林2012:41),吴江,江兰就数据驱动学习在词汇搭配学习中的作用进行相关探讨 (吴江,江兰2012)。然而,目前就如何在大学英语写作中合理运用数据驱动学习的研究几乎为一片空白,它也就成为当前DDL面临的新课题。
数据驱动学习的资源可以来自美国当代英语语料库 (Corpus of Contemporary American English,简称COCA),它是如今网上最大的免费英语语料库。美国当代英语语料库是由美国Brigham Young University的Mark Davies教授开发,目前单词容量为4.25亿,收集了自1990年到2012年的英语语料,是美国目前最新的当代语料库,同时也是当今世界上最大的英语平衡语料库。该语料库的的语料每年更新,检索功能强大,因此它是英语学习的助手,也是英语教师最好的教学资源之一。每月有近10万人使用该语料库以及Davis开发的其他几个语料库用于学习或科研,是使用者不可多得的一个英语参考资源,也是查询和观察美国英语使用和变化的一个极好窗口。(汪兴富2008:27)在写作课堂教学中,运用在线大型语料库加强学生任务式、探索式、研究式、自主式学习,能使学生获得更好的学习效果,从而有效地提高写作能力。
二、研究方法
2.1 研究对象
本研究从北京农学院大一和大二的学生中选取8个班级共471名学生作为研究对象,学生涉及不同专业的文科和理科学生。研究小组有4名英语教师,在开学初进行一次写作测试,由两位老师一起按10分满分对学生进行打分。根据班级的平均分,从中选取水平相当的4个班级为最终的实验对象。
2.2 研究问题
本研究围绕两个主要问题:(1)如何有效利用数据库数据驱动来进行写作课堂教学? (2)数据库数据驱动学习在写作教学中的效果如何?通过选取英语写作水平相当的两个班级作为控制组和实验组,比较前测和后测的写作成绩,来分析DDL有教学中的效果。
2.3 研究方法
研究小组的教师就如何有效利用数据库数据驱动来进行写作课堂教学问题进行探讨,研究在课堂中如何引导学生利用关键词或者词块进行检索,从而对真实的语言进行分析和总结,主动探索语言使用规律,进行自下而上的归纳式学习。
为了研究数据库数据驱动学习在写作教学中的效果,通过选取英语水平相当的4个班级作为控制组和实验组,比较前测和后测后的写作成绩,来分析DDL有教学中的效果。
2.4 研究步骤
英语写作课每两周上一次课,一学期共上8次写作课,安排在语音室上课,每位同学都有自己可以使用的电脑。在对照班,采用传统的写作教学方法,根据给出的作文题目,教师直接给学生提供相关的词汇,给出一两篇范文,然后让学生在课堂30分钟内写出指定题目的作文。在实验班,老师引导学生利用美国当代英语语料库(COCA),教会学生进行关键词、词块以及句式的检索,让学生自己对语言进行分析和总结,然后在课堂30分钟内写出指定题目的作文。
以作文题目How I Finance My College Education为例。在具体的写作课堂上,教师可以引导学生列出一些关于finance的一些词汇,如money,tuition,fees,bank loans等等。然后指导学生在美国当代英语语料库(COCA)进行检索,让学生在语料库中寻找他们的应用实例,进一步了解这些词的具体用法。学生还可以就一些相关的句式进行检索。通过检索来获取丰富的语言文化信息,这样能更好地培养学生的语言应用及分析、综合、批判性思维等能力。
三、结果与讨论
在实验开始的时候,对8个班进行写作测试。Sakyi指出,评分教师所关注的文本特征主要是:(1)内容和组织;(2)语法和规范类错误;(3)句子结构与词汇。(邹申,2011)
评分教师通过总体评分的方法分别给对照班和实验班打分,根据平均分的比较,找出分数最接近的四个班。对照班和实验班的写作成绩的平均分如表1。

表1 实验班和对照班的作文前测平均分
在接下来的一学期中,A和B班为实验班,C班和D班为对照班,4个班采用不同的教学模式。通过为期一学期的实验,给学生统一的作文题目,在30分钟内完成,通过评分,可以看出基于美国当代英语语料库数据驱动模式在英语写作教学中的作用。

表2 实验班和对照班的作文前测平均分
从数据分析可以看出,在实验开始的时候,两个实验班的平均成绩为7.305,两个对照班的平均成绩为7.345,,相差0.04。在为期一学期的实验结束后,两个实验班的平均成绩为8.265,两个对照班的平均成绩为7.75,分数相差0.515。由此可见,在基于语料库的数据驱动教学模式的作用下,实验班的写作成绩有了比较明显的提高。
笔者还对实验班和对照班在同一作文题目使用词汇的情况进行了统计。词汇密度(lexical density)是指作文中实义词(Lexical/content words)所占的比重。这里的实义词主要是指名词、动词、形容词和副词,词汇密度的计算方法为:


表3 实义词分布及词汇密度统计结果
词汇多样性(lexical variation)是指类符数(types)与形符数(tokens)的比值,主要用来衡量学生作文中使用不同单词的比重有多高,这一数值越大,说明学生使用词汇的范围越宽。词汇多样性的计算方法为:

根据词汇密度统计结果,实验班在使用实义词的总数上要多于对照班,词汇密度也高于对照班。同样,在词汇多样性方面,实验班使用词汇的范围宽,用词多样化。因此,实验班使用词汇的丰富性明显高于对照班。
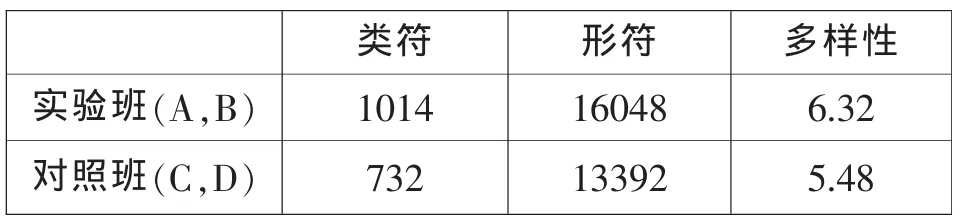
表4 词汇多样性统计结果
从成绩分析来看,运用基于语料库的数据驱动方法,学生可以一边观察真实的语料,一边不断地假设、求证,从而使学习的过程变成了自我探索和自我发现的过程,学习更加有意义,体系化,他们的学习兴趣和探索精神会得到进一步的激发与加强。
笔者研究发现,利用COCA进行数据驱动学习,能改变学生的写作习惯—套用模板,学生以教学主体的身份参与到写作教学的各个环节,通过课堂活动,从个人兴趣出发,完成选材、选词、选择修辞方法等各个写作程序,真正成为学习的主体,这有助于在以后的实际写作中培养学习者的自主、思索、研究能力,从而提高学习效率。
同传统外语教学相比,数据驱动学习外语具有以下优点:
第一,促进学生的自主学习能力。目前,在位于主流地位的外语写作教学模式中,教师依然是整个教学过程的主角,具有不容置疑的权威性;教师控制着教学安排、课堂组织、教学内容以及有关活动。这种教学极易磨灭部分学生的学习兴趣,挫伤学习积极性。数据驱动学习与这种教学模式则不同,它强调学生的自主学习,完全以学生为中心,发挥其个性特点。它要求学生在学习过程中自我管理、自我监察和自我评估。锻炼自主学习能力,将对学生的其他因素产生积极影响,如学习目的、动力、方式、需求、情感等等;这些因素共同作用,最终达到促进学习的目的。数据驱动学习环境下,教师的作用也极为重要:他们是过程的组织者、协商者和引导者,帮助学生通过DDL方法加深对所学知识的印象,培养他们自主学习的能力。
第二,营造真实语言环境。由于种种因素所致,目前的外语教学仍然以教师的语言输出和教材为学生的主要语言信息来源。学生对词汇语义上的细微差异把握不好,或者受母语的影响,会导致学生混淆使用该类词汇。而基于语料库的数据驱动学习则可较好地解决这样的问题。它以真实语言为主要语言输入,提供给学生的语言数据具有两大特征,一是其高质量输入,二是其大数量输入。它提供给学生的语言数据都来源于真实的交际活动和具体的交际语境,语言材料属于自然语言,而非为了教学目的而自造。基于语料库的数据驱动学习为学生营造真实语言环境,提高他们的语言直觉,帮助他们掌握地道的语言。
第三,强调探索和发现的学习过程。建构主义学习理论认为,语言知识的习得不是一个从教师到学生的简单过程,而是一个由学生自己发现和探索的过程。真正意义上的学习指学生积极参与学习,自下而上、归纳式的学习,通过吸收新的语言信息并与大脑中已有信息发生联系,以及同学习环境和学习伙伴相互作用,不断建构完善知识体系。学生积极地参与语言知识的建构、处理、改造和试验,从而使知识更加有意义、体系化和长久。数据驱动学习外语重视学生学习过程。它基于语料库提供给学生大量真实的语言数据,引导学生自己监察学习过程,根据需求去经历、探索、发现语言知识。这样,学生获得的语言知识会更地道、印象更深、体系性更强、储存更持久。
四、结语
从以上分析可以看出,基于美国当代语料库(COCA)的数据驱动英语写作学习具有自主学习、真实语言输入、自我探索和自我发现、自下而上的归纳式学习方式等主要特征。教师不再需要事先告知学生语法规则,而是让学生在观察大量真实语言后归纳出语法规则和使用特征。数据驱动学习外语的具体过程和环节多种多样,主要的手段包括关键词索引、分析搭配、扩展语境等。手段和做法之间并非孤立的,而是相互联系的。教师只有根据实际需要,灵活使用,才能达到最佳效果。
然而,数据驱动学习外语在硬件上要求配置各种学习硬件,如语料库、检索软件、多媒体及网络技术等。在软件上要求老师自身对授课的内容十分了解,如何有机地利用语料库更好地组织好课堂教学,是以后值得继续研究的问题。
Granger,S.(1998).The computer learner corpus:A versatile new source of data for SLA research[A].In S.Granger(ed.)Learner English on Computer[C].New York:Longman.
Johns,T. (1991).Should you be persuaded:Two examples of data-driven learning[A].In T.Johns&P.King(eds.)Classroom Concordancing[C].Birmingham:ELR.
郝军,田巍 (2009).基于语料库的英语专业写作教学模式探究 [J].沈阳师范大学学报 (2)。
王均松 (2010).数据驱动学习模式与词汇自主学习能力培养——基于COCA语料库的一项教学实验[J].中国外语教育 (3)。
教育部高等教育司 (2007).大学英语课程教学要求 [M].上海:上海外语教育出版社。
汪兴富,Mark Davies,刘国辉 (2008).美国当代英语语料库(COCA)——英语教学与研究的良好平台上海[J].外语电化教学(5)。
吴江,江兰 (2012).试论语料库数据驱动学习在外语词汇教学中的应用 [J].长江师范学报 (8)。
张北镇,周江林 (2012).数据驱动学习的课堂实现模式研究 [J].外语与外语教学(3)。
邹申 (2011).英语专业写作教学语料库建设与研究 [M].上海:复旦大学出版社。
