多类分类预选取的SVM 在语音识别中的应用
2013-02-22贺元元张雪英刘晓峰
贺元元,张雪英,刘晓峰
1.太原理工大学 信息工程学院,太原030024
2.太原理工大学 理学院 数学系,太原030024
1 引言
语音识别技术是人机交互的基础,随着计算机科学技术的发展,语音识别技术取得显著进步,逐渐开始从实验室走向市场。支持向量机作为一种新型的模式识别方法,是建立在统计学习理论的VC维理论和结构风险最小原理[1-2]基础上的,已经成功地运用到语音识别中。但是随着语音识别系统规模的增加,支持向量机算法复杂度随着所求解二次规划问题规模的增大呈指数增长,且计算量大,训练速度慢,其不适宜大规模数据问题的应用,已成为影响支持向量机发展的主要因素。
训练样本的支持向量(SV)预选取能够将训练样本中对支持向量机所构造的判决函数有贡献的样本数据筛选出来。最近几年来,人们对支持向量机中样本预选取的关注越来越多,并提出了很多简便有效的方法[3]。本文提出了基于核模糊C 均值聚类的样本预选取算法,并且运用到语音识别中。本文方法减小了训练样本的规模,使得训练时间得到了明显的减少,进而增加了支持向量机的分类效率。
2 非线性支持向量机
对于非线性分类问题,给定训练集T={(x1,y1),(x2,y2),…,(xl,yl)}∈(Rn×Y)l,其中引入核函数K(xi,xj)以及惩罚参数C >0,构造并求解凸二次规划问题:
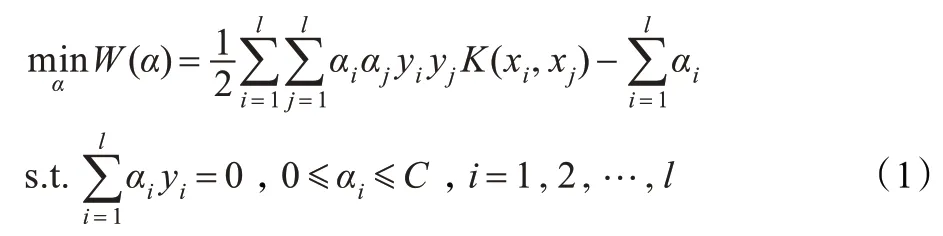
构造决策函数为:
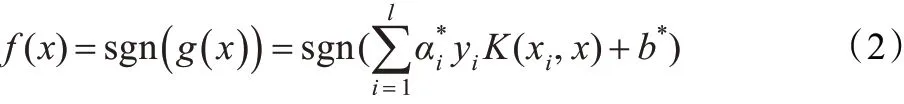
从决策函数表达式(2)可以看出,不是所有的训练样本都起作用,而只有对应于上述二次规划问题的解α*的分量非零的那部分训练样本对决策函数起作用[4],即:只有支持向量对应的训练样本对决策函数有贡献。
3 核模糊C 均值聚类样本预选取算法
3.1 核模糊C 均值聚类
FCM(模糊C 均值聚类)算法是由硬C-均值(Hard C-Means,HCM)算法演化而来的,它基于误差平方和目标函数准则,是一种常用的典型动态聚类算法。KFCM 算法把聚类归结成一个带约束的非线性规划问题,通过优化并求解获得数据集的模糊划分和聚类。文献[5]介绍了基于核函数的模糊C 均值聚类算法,其主要原理就是将常用的模糊C均值聚类算法中的欧式距离的计算用核模型来取代。
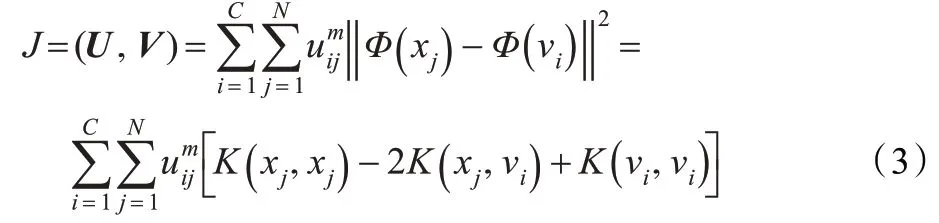
式中,U 为C×N 的隶属度矩阵;V 为聚类中心矩阵;m 为权重系数(一般取为2);K( x,y )为核函数。
根据拉格朗日乘数法可求得uij和vi为:
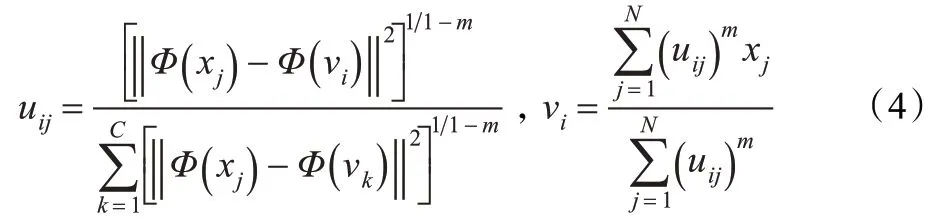
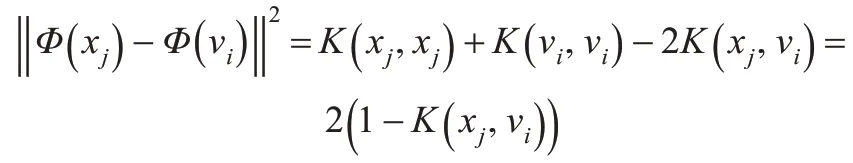
将上式带入式(3)和式(4)中,可以得到目标函数:
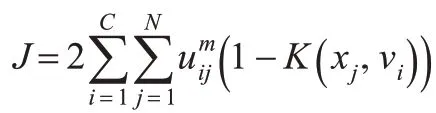
KFCM 算法增加了模式的线性可分概率,即扩大模式类之间的差异,在高维特征空间达到线性可聚的目的。样本点隶属于某一类的程度是用隶属度来反映的,不同的样本点以不同的隶属度属于每一类。
3.2 支持向量机的样本预选取算法
通过KFCM 算法,可以得到样本中所有类别的聚类中心V 。根据支持向量机的多类分类算法中一对一方法[9]的思路,可以把所有的C 个聚类中心任意的两个分为一组。分别求出所有样本点到每一组内两个聚类中心的距离,对于任一组聚类中心有:
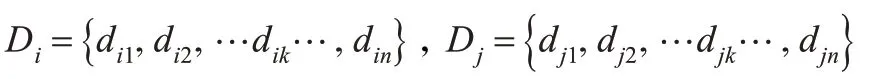
然后求出|Di-Dj|,若其中| dik-djk|<ε(ε 为一个阈值),说明该样本点在两个聚类中心的边界附近,可能属于支持向量样本,则标记该样本点;反之,该样本在聚类中心点附近,则不标记该样本点。依次重复循环,分别求出所有的聚类中心的组合中属于两个聚类中心之间附近的样本点。
最后按照一个准则:分别把样本集中属于同一类的样本数据取出,再把各类中的样本点按照其出现的次数由大到小排序,然后根据各类中所取样本的数量占该类样本总数的比例α(0 <α <1) 来决定每类中所保留样本的最后个数,由此得到所要选取的样本。
算法的流程图如图1 所示。
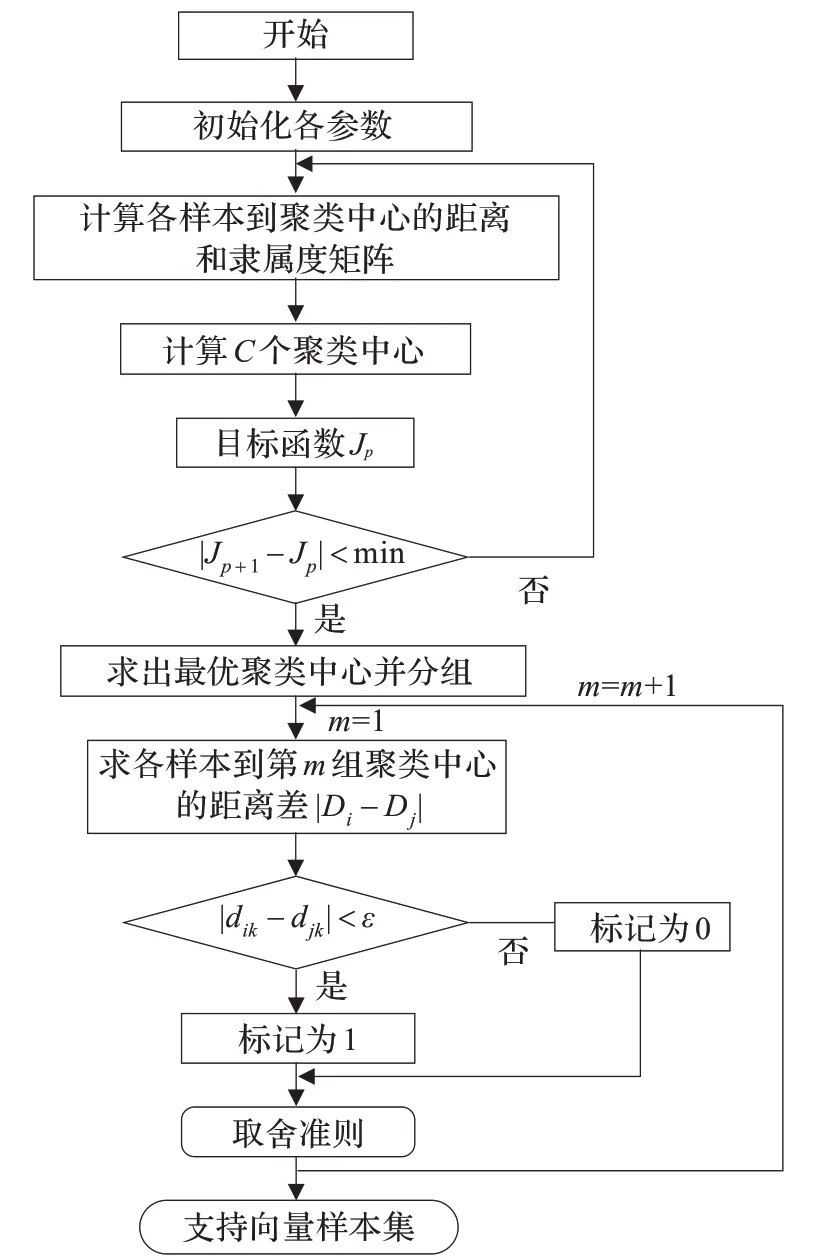
图1 KFCM 预选取算法流程图
本文算法旨在通过聚类的方法,把训练样本中可能属于支持向量的样本点,按照前文的方法取出来。算法对训练样本集中的所有样本都通过核函数把模式空间的数据非线性映射到高维特征空间中,增加了模式的线性可分概率,同时可以除去样本集中的一些野点数据的影响,从而提高支持向量机模型的稳定性及分类性能。
4 实验结果与分析
本实验选取了一个小词汇量的非特定人韩语语音库,该语音库在实验室环境下由16 人分别对50 个词进行录音,每人每个词发音3 次,选取其中9 人在词汇量分别为10词、20 词、30 词、40 词、50 词的数据为训练样本;同样测试样本为剩余7 人在各词汇量下的数据。录音的采样率为11.025 kHz,然后把采样系统得到的语音音频文件作为实验样本,语音中所加的噪声为高斯白噪声,分别在信噪比为25 dB、0 dB 和无噪声语音的情况下进行实验。原始语音样本经过MFCC(Mel 频率倒谱系数)特征提取得到特征样本数据,MFCC 特征提取的帧长N为256 点,帧移M为128 点。
实验过程先用本文提出的样本预选取算法对训练样本进行处理,然后再经过支持向量机进行训练并预测识别结果。支持向量预选取的实验参数在人工条件下,经过反复多次实验取得一组合理的参数,取高斯核函数的参数b=91,距离差的冗余度ε=1-4。支持向量机选用Libsvm-2.9程序包,其中核函数均选RBF 核函数,惩罚参数和核参数采用网格搜索法,求得最优值为:C=32,γ=0.000 122 07。实验环境:CPU 为Intel®CoreTM2 Duo 2.2 GHz,内存为2 GB;操作系统为Windows XP-SP2;在软件平台为Matlab 7.0。
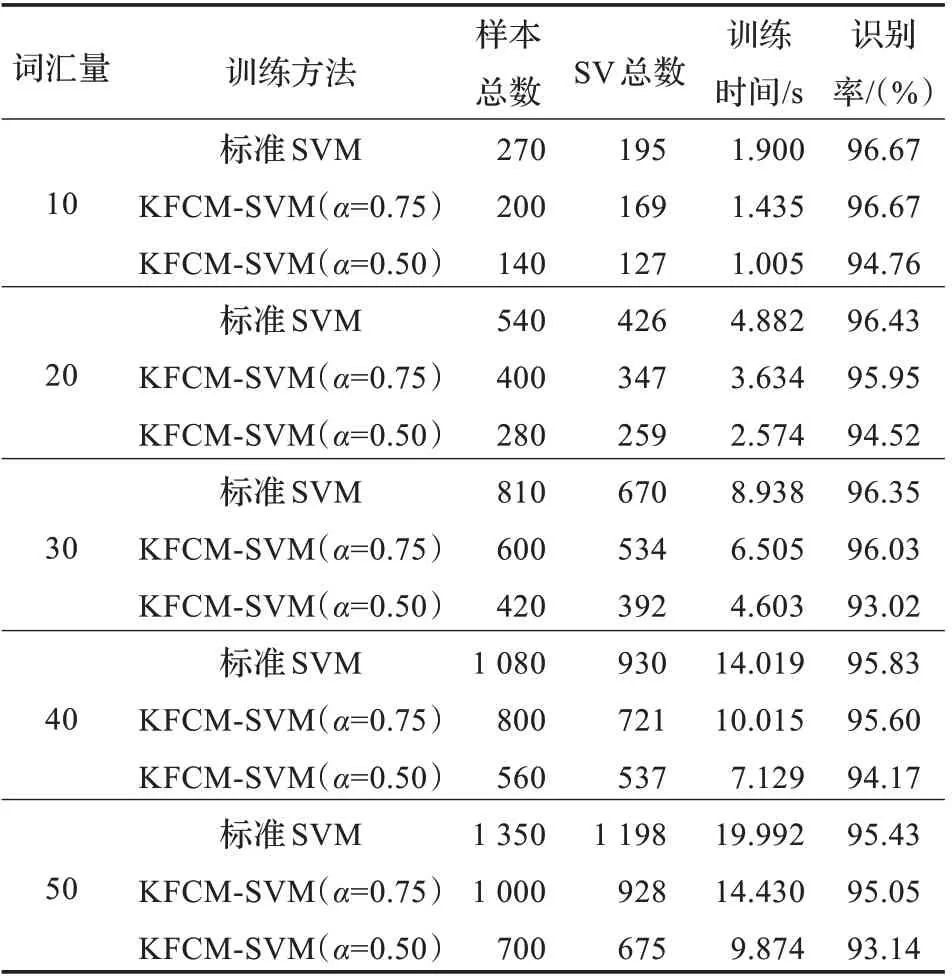
表1 SNR=25 dB 时预选取的实验结果比较
本实验由3 部分组成:
(1)原始训练样本集直接用标准SVM 进行实验;
(2)当α=0.75 时,即:选取原训练样本集中每一类样本个数的75%,用本文方法进行实验;
(3)当α=0.50 时,即:选取原训练样本集中每一类样本个数的50%,用本文方法进行实验。
在信噪比分别为25 dB、0 dB 和无噪声语音的情况下,逐个对10 词、20 词、30 词、40 词、50 词的训练样本按照上述的3 部分进行对比实验,其中的时间是重复3 次取平均值得到的。实验结果如表1和图2,表2和图3,表3和图4所示。
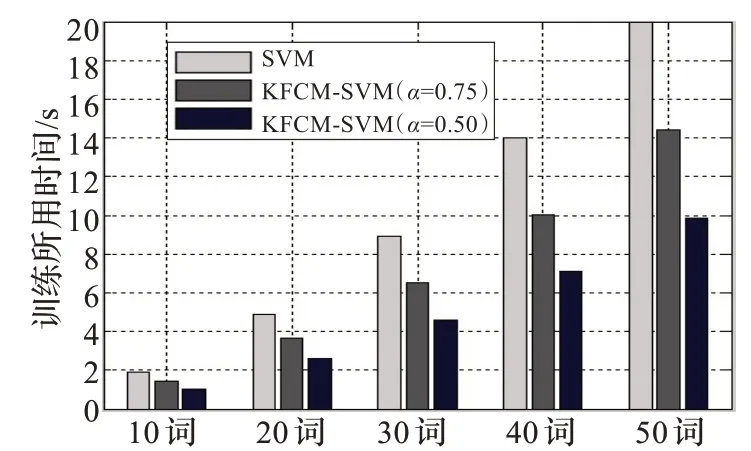
图2 SNR=25 dB 时表1 中的训练时间比较
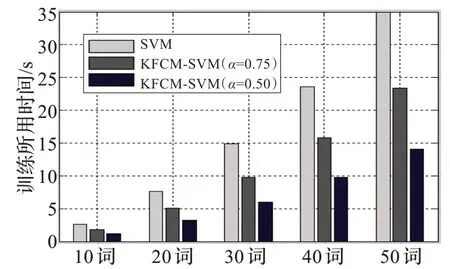
图3 SNR=0 dB 时表2 中的训练时间比较
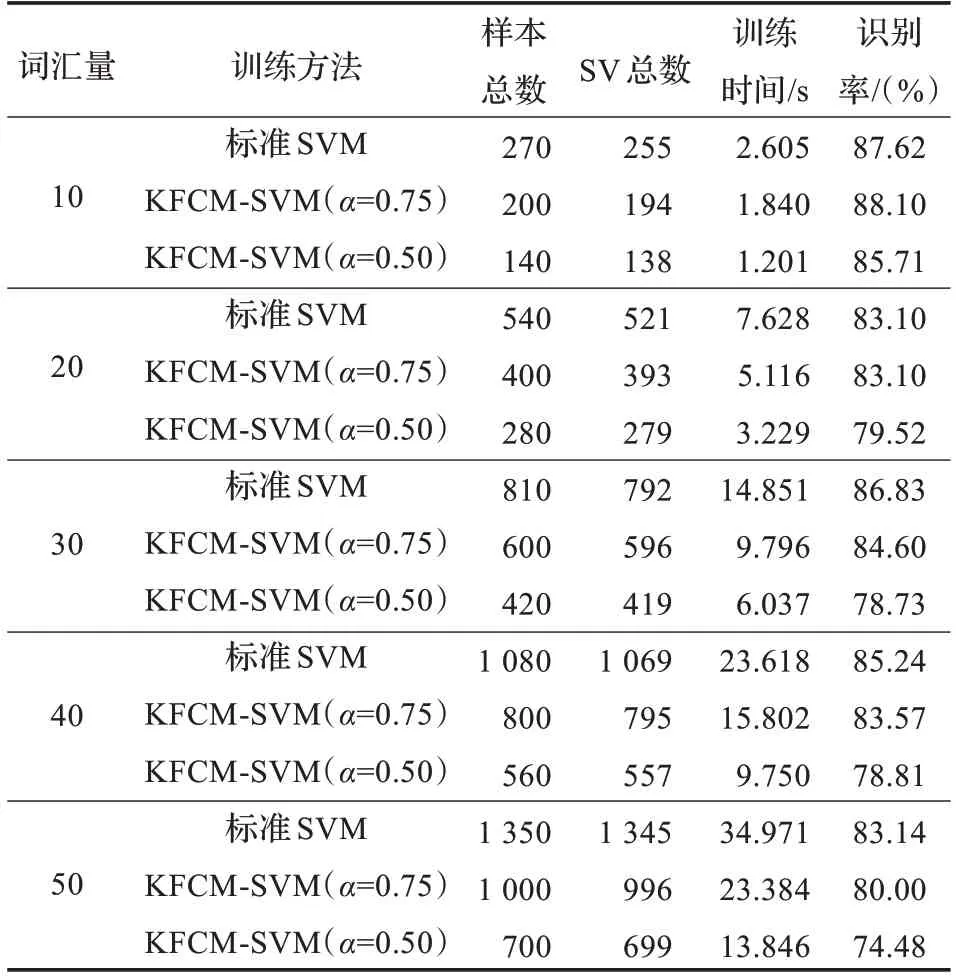
表2 SNR=0 dB 时预选取的实验结果比较
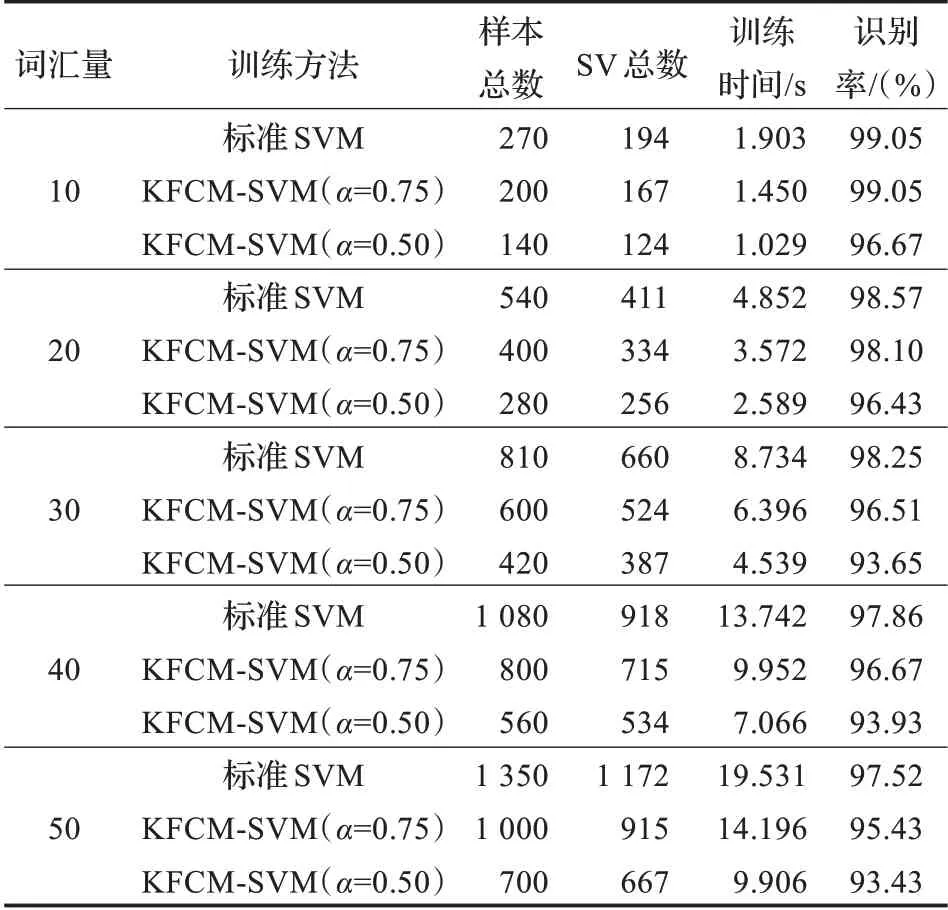
表3 无噪声语音时预选取的实验结果比较
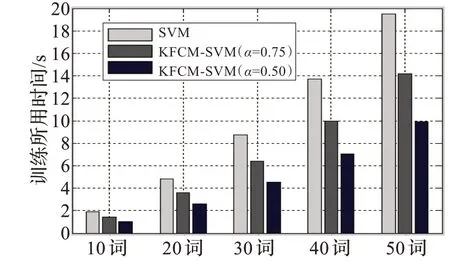
图4 无噪声语音时表3 中的训练时间比较
从以上实验结果可以得到,经过预选取的训练样本的支持向量总数明显减少,在不同信噪比的情况下,随着词汇量的增加,支持向量机的训练时间随之增加,同时预测样本的识别率有所减小,在信噪比为0 dB 时,由于噪声较强,故识别率受到一定的影响但均保持在较高的水平。运用本文的算法进行训练,当α=0.75 时,在各个信噪比下识别率保持不变或随词汇量增加识别率略受影响,而训练时间明显减少,说明此时所选的支持向量数对分类机的性能影响并不大,识别率仍然很接近;当α=0.50 时,训练样本集的识别率随着词汇量越大和信噪比的减小有所降低,但是从图2、图3、图4 可以很直观地看出,预选取后的训练时间大大减少,其中最大的减少了原时间的60.40%,取得了较为满意的实验结果。
5 总结
本文基于核模糊C均值聚类提出了一种样本预选取算法,并且在语音识别上进行了应用。该算法目的是把支持向量机训练过程中对计算构建最优分类超平面贡献大的样本点筛选出来,然后把这些样本数据组成一个新的训练样本集,这样删减了冗余的样本点,从而使得训练时间得以减少,提高了效率。从实验结果可以看出,随着信噪比的减小和词汇量的增加,训练时间逐渐变长,识别率几乎保持稳定,实验的效果在某种程度上受到了所选参数的制约,通过参数的优化将会提高算法的性能;另外,当训练样本中的冗余样本点较多时,本文方法的效果将会更加显著。运用本文方法进行样本预选取后的训练样本集在保证分类精度的前提下,训练时间明显减少,从而得到了较为理想的支持向量样本预选取效果。
[1] Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995:77-79.
[2] 张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[3] 韩德强,韩崇昭,杨艺.基于k-最近邻的支持向量预选取方法[J].控制与决策,2009,24(4):494-498.
[4] 邓乃扬,田英杰.支持向量机——理论、算法与拓展[M].北京:科学出版社,2009:97-101.
[5] Zhang D Q,Chen S C.Kernel-based fuzzy clustering incorporating spatial constraints for image segmentation[C]//Proceedings of the 2nd International Conference on Machine Learning and Cybernetics,2003.
[6] Du C,Sun D,Jachman P,et al.Development of a hybrid image processing algorithm for automatic evaluation of intramuscular fat in beef M longissimus dorsi[J].Meat Science,2008,80(4):1231-1237.
[7] 唐成龙,王石刚,徐威.基于数据加权策略的模糊聚类改进算法[J].电子与信息学报,2010,32(6):1277-1283.
[8] 伍学千,廖宜涛,樊玉霞,等.基于KFCM 和改进分水岭算法的猪肉背最长肌分割技术[J].农业机械学报,2010,41(1):172-176.
[9] Knerr S,Personnaz L,Dreyfus G.Single-layer learning revisited:a stepwise procedure for building and training a neural network[M]//Neurocomputing:Algorithms Architectures and Applications.New York:Springer Verlag,1990:236-241.
