关键词有序排列的全文检索算法
2013-01-15毕忠勤杜海舟
杨 珺,毕忠勤,杜海舟
(上海电力学院计算机科学与技术学院,上海 200090)
全文检索技术细化了信息检索的力度,提供了多角度、多侧面的信息检索体验.当前的检索模型要求在输入一组检索词组合的情况下,能够返回与之相关的文档,常用的检索模型有布尔模型和向量空间模型.
布尔模型是通过采用AND,OR,NOT等逻辑运算符,将多个检索关键词组合成一个逻辑表达式,继而通过布尔运算进行检索的简单匹配模型.此模型的缺点主要在于没有考虑文档和检索关键词的相关性问题,没有区分检索关键词的权重问题,导致查询结果与用户的意图差距较大.
向量空间模型使用了一个由关键词构成的文档向量 Di={d1i,d2i,...,dni}来表示文档集中的文档,此模型存在的主要缺陷就是无法解决某一词的同义词和近义词对其的干扰,同时使用n维向量来表示文档和检索词组合,采用内积来计算二者之间的相似度.
针对上述问题,文献[1]提出将检索关键词映射为实例、概念或属性,并设计了6种模板来匹配两个关键词的简单组合查询,当检索关键词多于两个时,由于存在组合爆炸的可能性,可以使用启发式方法来处理此种问题;文献[2]尝试通过本体提供背景知识的方式将关键词组合转换为描述逻辑连接查询;文献[3]针对“标引”提出语义树模型,针对“相似度计算”提出了3个可计算的窗口模型来近似语义张量;文献[4]在向量空间模型的基础上提出了基于本体的检索模型,将关键词查询映射为结构查询,同时还可以对检索结果进行排序.
本文首先分析了正排索引[5]和倒排索引[6]的适用范围及缺陷,针对各检索关键词在整个查询中的权重和由检索词组合顺序不同而导致暗含的语义存在差异的问题,在基于倒排索引和向量空间检索模型的基础上,给出了与检索词排列顺序相关的全文检索方法,以提高检索质量.
1 基于倒排索引和向量空间检索模型的全文检索算法
现有的检索算法中有两个重要问题,即索引的建立和相关度的匹配.目前广泛使用的是基于倒排的索引系统和基于向量空间模型的查询系统.
1.1 正排索引与倒排索引
1.1.1 正排索引
正排索引也称为“前向索引”,是创建倒排索引的基础,其字段如下:
(1)localId 表示一个文档的局部编号;
(2)wordId 表示文档分词后的词的编号,也可称为“索引词编号”;
(3)hitList 表示某个索引词在文档中出现的位置,即对于正文的偏移量,这是一个变长序列,记录关键词在文档中出现的所有位置,为了压缩存储的需要,此序列一般采用差分序列的方式存储;
(4)nHits 表示某个索引词在文档中出现的次数,由于hitList是变长的,因此需要nHits这个字段标记其长度,这样才能读出全部的正排索引数据.
从本质上说,正排索引以文档编号为视角看待索引词,也就是通过文档编号去寻找索引词.任意给出一个文档编号,就能够知道它包含了哪些索引词、这些索引词分别出现的次数,以及索引词出现的位置.然而全文索引是通过关键词而不是通过文档编号来检索的,因此正排索引不能满足全文检索的要求.
虽然正排索引不能满足全文检索的需要,但是正排索引为创建倒排索引创造了有利条件,它是计算倒排索引不可缺少的一环,也是我们改进算法的基础.
1.1.2 倒排索引
倒排索引是描述一个词项集合元素和一个文档集合元素对应关系的数据结构,记:
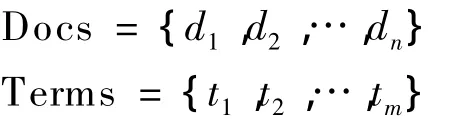
式中:di——第 i个文档,i=1,2,…,n;
tj——第 j个词项,j=1,2,…,m.
当以“文档”为出发点时,我们可以说di中包含哪些tj,或者某一个tj在di中出现了多少次,而“倒排文件”直接给出的是一个tj出现在哪些di中,进而还可以给出它在某一个dj中出现在哪些位置(含多少次).用PL(tj)表示tj出现于其中的文档记录的集合,称为对应于tj的倒排表.
倒排文件分为两部分:一是由不同词项组成的索引,称为词汇表;二是由每个词项出现过的文档集合组成,称为记录文件,每个词项对应部分称为倒排表,也称为记录表,可以通过词汇表访问.
在倒排文件中,每个不同的词会出现在一个词典中,这个词典除了包含每个词外,也包含这个词对应的倒排表的指针.每一个文档都有唯一的名字,可为他们赋予连续的不重复的数字.
倒排索引是现代大规模搜索的核心,通过它可以大大提高检索系统的响应时间和查询的吞吐量.
1.2 向量空间检索模型
向量空间模型是近年来在文本检索、自动文摘、文本分类等领域广泛使用的一种文本处理模型[7].特别是在文本检索领域,该模型对于文档与查询的相关度计算有较好的效果.
在向量空间模型中,文档和查询均被看作是由索引项构成的向量.其中文档 Di={d1,j,d2,j,…,dt,i},i表示文档集中的第 i个文档,t表示某个文档含有 t个词项.查询 Q={d1,q,d2,q,…,dt,q},t表示在查询q中含有t个词项.在权重方面使用的计算方法为TF-IDF方法,通过统计特征项的词频f值和逆向文本词频fid值形成权重计算公式.
文档Di和查询Q之间存在的相似程度一般通过计算两个向量的夹角余弦值来衡量.据此可采用以上两个向量的cos值作为相似度:
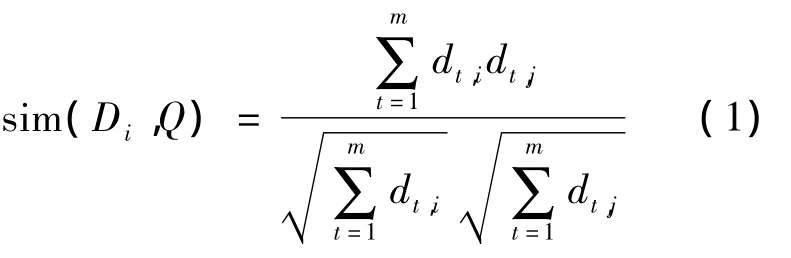
此相似度值可以看作是文档和检索词之间的相关程度,从而可以优先检索那些与检索词相似度较大的文档.
2 关键词有序检索方法
我们在基于倒排索引和向量空间检索模型的全文检索方法基础上,加入了检索预处理算法,即通过定义查询步进和文档关键词步进(简称文档步进),进而给出位置匹配函数,使之能够处理当检索结果与检索词组合顺序相关时的状况.
2.1 预处理算法
本文通过实例来给出相关的定义.首先,通过倒排文件来找到同时出现所有检索关键词的文档,即使用联合索引.假设检索词为“小张喜欢小王”,通过分词可得检索关键词向量为{“小张”,“喜欢”,“小王”},索引结果分别为:
I小张={1,5,9,14,20,23,25,30,31,33}
I喜欢={2,6,8,15,20,25,27,31,35}
I小王={3,7,12,14,20,24,25,27,31,36}
联合索引的结果为{20,25,31}.
然后,通过正排索引找出相关检索关键词在文档中的位置,并做如下定义:
令 pi,pj,pe分别代表检索关键词 qi,qj,以及最后一个检索关键词在整个查询中的位置,则相对查询步进定义为:
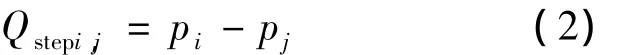
总体查询步进定义为:

以给出的查询“小张喜欢小王”为例:“小张”相对于“喜欢”的查询步进为step小张,喜欢=1-2=-1,而“小王”相对于“喜欢”的查询步进为step喜欢,小王=3-2=1;而检索的总体查询步进为stepall=3-1=2.
类似的,令 ri,rj分别代表检索关键词 qi,qj在相关文档中的位置,则相对文档查询步进定义为:

设re为最后一个检索关键词在相对文档中的位置,因此总体查询步进定义为:
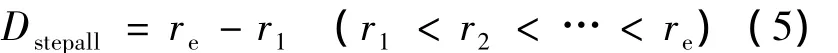
经由上述定义,通过对大量文档的统计分析发现:文档和查询之间的相似度与两个或多个查询关键词在文档中的步进成反比,同时又受到总体查询步进的影响,总体查询步进与相似度也成反比.由此我们定义位置匹配函数为:

只取Res>0的情况返回结果,如果出现如下情况:

此时:

则Res=100%,我们称其为完全匹配,也就是说在文档中检索到了与检索关键词组合完全一致的结果.
由于预处理的结果是一个序列,因此可使用二维数组来返回其结果.数组的每一行代表一个匹配到的文档,数组的第1列存放文档的编号,也就是正排索引中的localId,数组的第2列存放此文档与检索关键词组合向量的Res值,在实际应用中可根据具体编程语言的特点来选择具体的数据结构.
以Java为例:返回的值可以是一个ArrayList,存储所有经过预处理的文档,其中的每个元素具体可以是一个长度为2的一维数组,数组的第1个元素是文档的localId,第2个元素是分词后的查询与此文档的Res值,供后续阶段使用.
2.2 预处理算法的改进
2.2.1 扰动词的处理
如果查询文档中存在查询关键词的扰动词,比如说查询文档a中有“小张非常喜欢小王”,文档b中有“小张可能喜欢小王”;那么文档a中的“非常”和文档b中的“可能”就是查询扰动词,如出现这种情况我们先粗略地采用以下两种方式处理.
(1)将其作为同样的地位,此情况下两个文档与查询的语义匹配值相同:
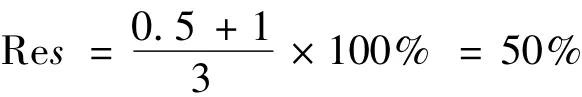
此情况只是考虑了词的匹配顺序,可以保证检索的效率,但是扰动词的具体含义也可能会对检索带来一定的影响.
(2)根据扰动词含义类型,将扰动词分为正向含义加强类型和逆向含义加强类型,并分别赋予正向增强权值和逆向增强权值(亦即正向减弱权值),这两个值互为相对数.例如将“非常”看作是正向含义加强类型词,把“可能”看作是逆向含义加强类型词,在获取肯定查询时分别赋予权值α和-α,(0<<1),由此可得,对于“小张非常喜欢小王”:

对于“小张可能喜欢小王”:

在此情况下需要一个本体库或语料库,例如howNet等的支持,而且如何确定含义的增强权值或减弱权值也需要考虑.
对于更加复杂的情况,例如:“小张可能非常喜欢小王”,我们可通过本体库或语料库的支持,根据其具体含义,递归地扩充检索匹配公式进行计算.
2.2.2 文档中匹配到的多个检索词的处理
检索词在文档中出现的位置不可能只有一处,而且正排索引中记录了各个关键词(索引词)在文档中的位置,因此可以利用正排索引来查找与关键词顺序相关且关键词间步进最小的检索词的位置进行预处理.
2.3 检索方法的总体描述
检索算法主要是在传统搜索引擎算法的基础上增加了预处理的步骤:
(1)对查询关键词分词,使用逻辑表达式来表示查询,例如“小张喜欢小王”可以表示为“小张”AND“喜欢”AND“小王”;
(2)采用布尔模型的方法得到结果文档列表;
(3)使用关键词有序预处理算法对上一步骤中得到的文档进行筛选,取Res值大于某一阈值的文档;
(4)将预处理过的文档向量化,并计算与向量化查询之间的向量相似度,再计算此向量相似度与对应文档Res值的乘积作为文档与查询之间的相似度;
(5)按照最终相似度排序输出检索结果.
3 实例验证
仍以“小张喜欢小王”为例,假设通过索引从文档集中匹配到的文档中分别包含如下内容:
(1)小张非常喜欢小王;
(2)小王喜欢小张;
(3)小张和小王都喜欢户外运动.
如果采用传统的方法,这3个文档均可被检索出,但因次序的顺序组合不相符导致得出的结果不理想.采用关键词有序检索方法需经过如下预处理:
(1)对于包含“小张非常喜欢小王”的文档,dstep小张,喜欢=2,dstep喜欢,小王=1,qstepall=3,利用式(6)可得Res=50%;
(2)对于包含“小王喜欢小张”的文档,dstep小张,喜欢=-1,dstep喜欢,小王=-1,qstepall=2,利用式(6)可得Res=-100%;
(3)对于包含“小张和小王都喜欢户外运动”的文档,dstep小张,喜欢=-4,dstep喜欢,小王=-2,qstepall=4,利用式(6)可得 Res=-37.5%.
可以设置阈值为零,经过预处理,包含“小王喜欢小张”和“小张和小王都喜欢户外运动”的文档被过滤掉,不进入检索阶段.
由此可见,通过给出的预处理算法可以优化过滤与检索期望相差较大的文档,最终可以提高检索结果的质量.
4 结语
本文提出了一种与检索关键词组合顺序相关的全文检索方法:考虑各检索关键词在整个查询中的权重,以及由检索词组合顺序不同而导致暗含的语义存在差异的问题,按照一定的规则对索引结果进行处理,约简掉不相关的文档,从而提高了检索结果的质量.今后我们将使用本体或语料库来支撑预处理算法,以期取得更好的结果.
[1] LEI Yuang,UREN Victoria,MOTTA Enrico.SemSearch:a search engine for the semantic web[C]∥15th International Conference,EKAW,2006:222-237.
[2] TRAN Thanh,CIMIANO Philipp,RUDOLPH Sebastian,et al.Ontology-based interpretation of keywords for semantic search[C]∥6th International Semantic Web Conference 2nd Asian Semantic Web Conference,2007:523-536.
[3] 赵军,金千里,徐波.面向文本检索的语义计算[J].计算机学报,2005(12):2 068-2 078.
[4] VALLET David,FERNONDEZ Miriam,CASTELLS Pablo.An ontology-based information retrieval model[C]∥2nd European Semantic Web Conference,2005:455-471.
[5] 梁斌.走进搜索引擎[M].北京:电子工业出版社,2007:132-140.
[6] 李晓明,闫宏飞,王继民.搜索引擎——原理、技术与系统[M].北京:科学出版社,2005:214-217.
[7] 宗成庆.统计自然语言理解[M].北京:清华大学出版社,2008:92-97.
