听力正常人普通话双音节半词与全词表检测结果分析△
2013-01-10王越张华郭珈彤郑中伟王硕佟佳梅
王越 张华 郭珈彤 郑中伟 王硕 佟佳梅
双音节词表是普通话言语测听词汇表(Mandarin speech test materials,MSTMs)中的一部分,主要用于临床评估言语识别能力,该词表均通过可靠性及有效性的测试,具有等价性[1,2],已在听力正常人中应用[3]。但临床应用中发现50个词的词表测试时间较长,受试者易疲劳,对测试效果可能产生潜在的影响,国外的听力学家也意识到词表过长会影响测试结果,曾尝试缩减词表,以解决全词表测试时间过长的问题,并比较用半词表及全词表进行言语测试的结果[4]。因此,本研究拟通过应用普通话双音节词表前半张表25个词(半词)及全词表50个词(全词),分别对45例听力正常人进行检测,对比分析其结果,探讨听力正常人应用普通话双音节半词表及全词表的识别-强度函数曲线(performance-intensity.P-I)之间的关系,为选用适合临床应用的普通话双音节词表提供参考。
1 资料与方法
1.1测试对象 45例受试对象均为医院工作人员,男25人,女20人,文化程度为中专以上学历,日常交流方式为汉语普通话。受试者均无耳疾史、无耳聋家族史,纳入对象的年龄分组及不同年龄组的气导听阈标准见表1,受试者至少有一耳达到气导听阈标准。全部对象鼓室导抗图为A型,同侧、对侧声反射阈75~95 dB HL。

表1 各年龄组不同频率气导听阈标准(dB HL)
1.2测试材料 选用MSTMs中难度等价性一致的9张双音节词汇表,每张表50个双音节词,共450个词,使用词表举例见表2。
1.3测试地点及设备 测试在双间隔声室进行,环境噪声<20 dB(A),测试设备为丹麦Madsen Conera临床诊断听力计。为降低音源输入信号干扰,言语测听材料转录成声音波形文件(wave格式)通过听力计内置播放器输出,直接由Conera听力计和TDH-39耳机传递给受试者,选取内置播放的声源A作为听力计中言语输出通道。将1 000 Hz纯音作为校准音,参考国际标准,将言语听力级(0 dB SHL)校准为20 dB的言语声压级(dB SPL)[5]。
1.4测试方法 听力检查:在言语识别阈测试之前,进行常规的电耳镜检查、纯音听阈(pure tone average,PTA)测试和声导抗检查,取500、1 000、2 000和4 000 Hz平均听阈,选取较好耳作为测试耳。
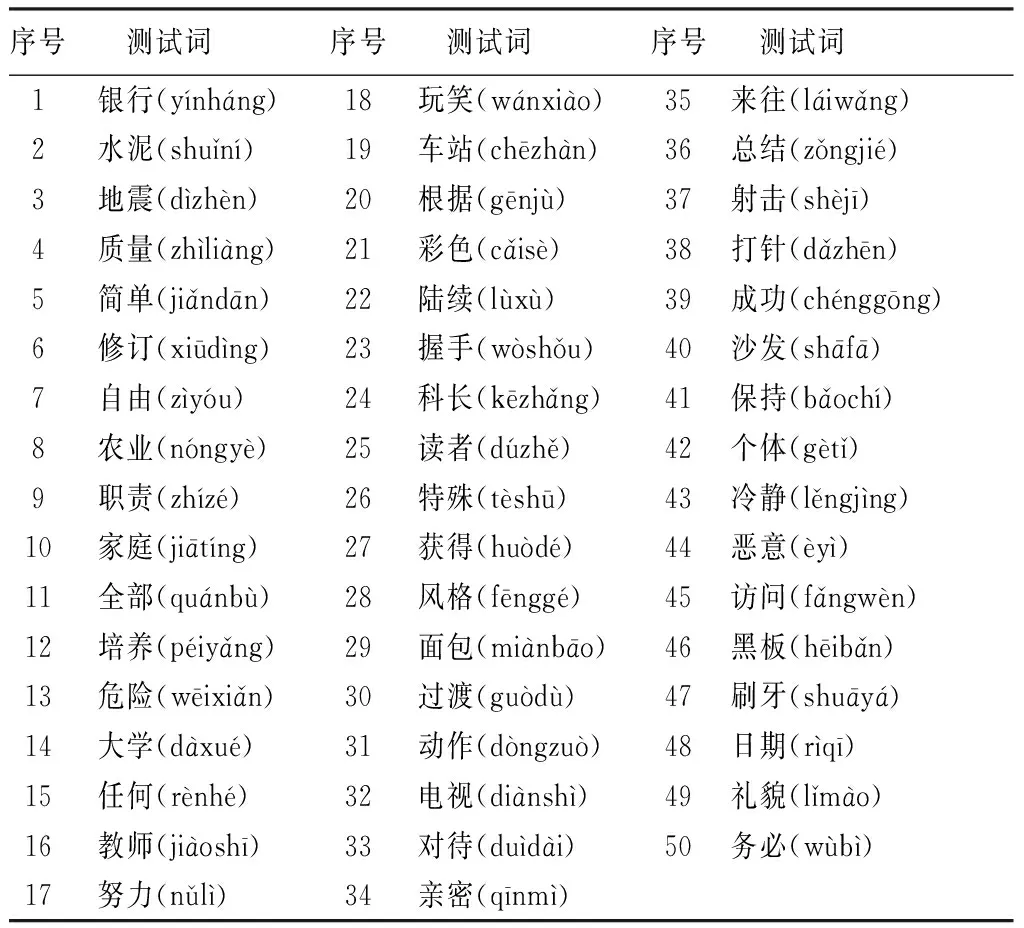
表2 双音节词汇表之五
言语识别阈测试:测试人员统一在首都医科大学附属北京同仁医院 北京市耳鼻咽喉科研究所言语测听课题组进行培训,掌握该9张双音节词汇表的测试方法及测试程序,进行言语测试之前,鼓励受试者精神放松,可以对词表进行猜测,疲劳时允许稍作休息。首先,使用练习表,让受试者理解具体测试过程及方法,以口头复述作为反应方式,随机选双音节词汇表,测试初始给声强度为PTA上20 dB,以5 dB为步距,逐步降低给声强度,每一给声强度下给出一个测试词语,当出现第一个错误反应时,将步距减小为2 dB,逐步升高给声强度,直至出现第一个正确反应,再以2 dB为步距降低给声强度,直至出现一个错误反应,再以2 dB为步距升高给声强度,以此步骤反复测试13次,第一次的下降趋势无效,取12次上升或下降的给声强度的平均值获得言语识别阈(speech recognition threshold,SRT)。
识别-强度函数测试:以本次得出的SRT为初始给声强度,完成一张词汇表测试后,以2 dB为步距升高或降低给声强度,进行下一词表的测试,每名受试者测试6张词表,在进行前半张词表(25个词)和全词表(50个词)测试时,分别记录各给声强度和所对应的言语识别率,最后得到识别率小于20%及大于90%所对应的给声强度。为降低由于对测试不熟悉和受试者疲劳对测试结果造成的影响,采用循环排列测试词表顺序法,以避免同一词汇表总是出现在测试的最初或最后。按照受试者测试词正确与否计分。
1.5统计学方法 全部资料录入Excel进行数据管理,使用SPSS16.0统计软件,计量资料符合正态分布用均值±标准差表示,差异比较采用配对t检验,用曲线拟合和线性回归分析的方法对所得数据进行统计分析,以P<0.05为差异有统计学意义。
2 结果
不同年龄组的P-I函数曲线见图1~4,不同年龄组的PTA、SRT及P-I斜率见表3,其中,P值为同一年龄组中半词与全词P-I斜率的比较。对其函数的线性部分进行线性回归分析,四个年龄组的半词与全词回归系数经同组比较差异无统计学意义(P>0.05)。

图1 18~30岁组半词与全词的双音节P-I函数曲线 图2 31~40岁组半词与全词的双音节P-I函数曲线
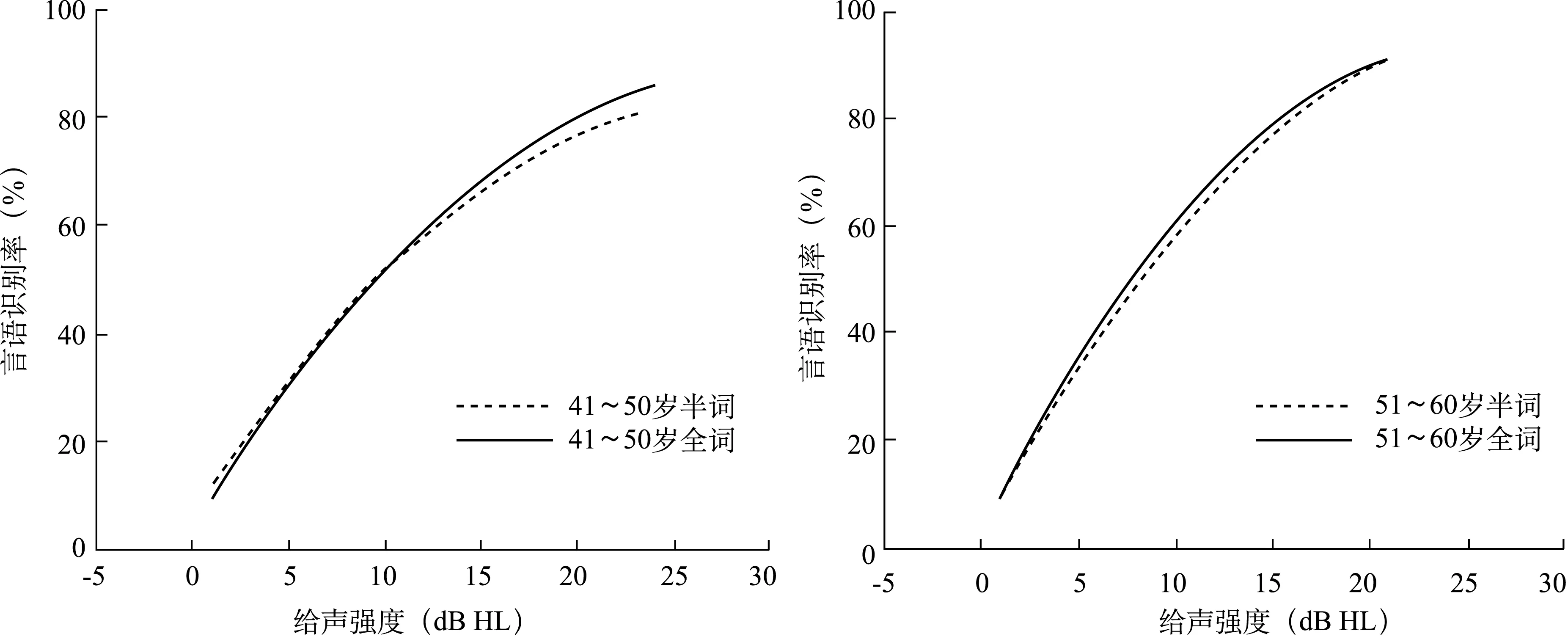
图3 41~50岁组半词与全词的双音节P-I函数曲线 图4 51~60岁组半词与全词的双音节P-I函数曲线
表3 不同年龄组PTA、SRT值及P-I斜率比较
3 讨论
言语测听(speech audiometry)是一种主观测试,诸多因素可以影响其结果。本研究所采用的普通话双音节词表共9张表450个词,测试时长约45分钟,由于给声强度较小,接近受试者纯音听阈,受试者较易感觉疲劳。研究表明受试者疲劳会造成言语识别率降低[6],针对该因素的影响,王硕等[7]采取在测试过程中允许受试者休息,从而缓解由于测试时间过长而产生的疲劳。为了减少临床检查时间,减轻疲劳对测试结果的影响,许多研究者尝试缩短词表,Deutsch等[8]随机选择128例受试者,比较CID W-22词表中25个词和全部词的言语识别曲线,结果曲线一致;同样应用PB-50词表,缩短的测试词得出的结果与全词表一样。Bose等[4]的报告中提到,将CID W-22词表再行缩短,其词表中前10个测试词可以用来作为筛选工具,决定是否需要做25个词或者50个词的测试。但也有异议,Thornton[9]指出减少词语数,测试得分的变异会加大,当应用25个词测试识别率为92%时,变异范围增大到72%~100%,应用50个词测试识别率为92%时,变异范围可降至78%~98%,所以用50个词的测试表得出的结果是比较可靠的[9]。Hurley等[10]应用NU-6词表的半词与全词对听力正常人和感音性听力损失患者进行测试发现,用10个词和25个词先期做筛查,都可以达到93%~100%的准确率,得出听力正常人言语测听只需要10~25个词的研究结论。
双音节词汇表是用于评价SRT的主要测试材料,从文中结果看在听力正常人中使用该词表,无论应用半词还是全词,不同年龄组受试者一般都可在测试25个词时获得言语识别阈,而同组的半词和全词测试所得的识别-强度函数曲线也基本一致。但对于听力障碍患者则需测试50个词才能获得可靠的结果[10]。
通常认为用于言语测听的每张测试词表包含测试项的数目会影响言语测听的信度和灵敏度,每张测试表内包含的测试项越多,标准误越小,结果变异越小,如果缩短词表以节约测试时间,会产生信度下降。如何在词表测试数量与信度之间找到一个平衡点,是重点关注的问题。目前如何截选词表,没有统一的标准,有些研究人员尝试只用单数、偶数或第一个、中间或最后的词表的排序来缩短测试时间,也有学者建议将词表中的词进行排列,把错误频率发生较高的10个最难的词列在词表最开始处,如果受试者对前10个词有了正确反应,则不需要行后面词的测试[4]。Thornton等[9]探讨了利用统计学的二项式模型预测来决定实际上需要测试的词表个数。本研究选择全词表的前半部分词(半词)对受试者进行测试,其测试结果显示同年龄组半词和全词测得的P-I函数曲线是一致的。可见对听力正常人进行普通话双音节词表测试时,使用前25个词测试可以获得可靠的结果。由于本研究所观察的例数较少,今后需扩大样本数来进行一系列的临床验证,以获得更有意义的临床数据。
4 参考文献
1 王硕,张华,王靓,等.双音节普通话言语测听词汇表的听力正常人评价标准[J].临床耳鼻咽喉头颈外科杂志,2007,21:18.
2 Wang S,Mannell R,Newall P,et al.Development and evaluation of Mandarin bisyllabic materials for speech audiometry in China[J].Int J Audiol,2007,46:719.
3 王越,张华,佟佳梅,等.普通话双音节测听词表在不同年龄听力正常人中的检测结果分析[J].临床耳鼻咽喉头颈外科杂志,2012,26:312.
4 Mendel LL,Danhauer JL.Audiologic evaluation and management and speech perception assessment[M].San Diego:Singular,1997.15~43.
5 Katz J.Handbook of clinical audiology[M].5th ed.Philadephia :Lippincott Williams & Wilkins,2002.96~110.
6 Katz J.Handbook of clinical audiology[M].2th ed.The Williams & Wilkins Company,1978.141~157.
7 王硕,张华,岳朋朋,等.双音节普通话言语测听词表的等价性评估[J].临床耳鼻咽喉头颈外科杂志,2006,20:590.
8 Deutsch LJ, Kruger B.The systematic selection of 25 monosyllables which predict the CID W-22 speech discrimination score[J].Journal of Auditory Research,1971,11:286.
9 Thornton AR,Raffin MJ.Speech discrimination scores modeled as a binomial variable[J].Journal of Speech and Hearing Research,1978,21:507.
10 Hurley RM,Sells JP.An abbreviated word recognition protocol based on item difficulty[J].Ear & Hearing,2003,24:111.
