基于语义相似度的主观题评分算法研究
2012-12-26张立岩张世民
张立岩,张世民
(河北科技大学信息科学与工程学院,河北石家庄 050018)
基于语义相似度的主观题评分算法研究
张立岩,张世民
(河北科技大学信息科学与工程学院,河北石家庄 050018)
主观题阅卷系统在目前较受人们的关注。主观题评分原则常见的是对比试卷答案与参考答案的相似程度,进而得出分数。利用自然语言处理分词技术将文本切分为词的组合,然后通过改进语义相似度算法,计算句子相似度,进而得到试卷答案和参考答案的相似程度,给出分数。
主观题;分词;语义相似度
考试在任何教育体系中都是不可缺少的重要环节,是考察、评估学生能否真正掌握相应知识、技术的较为有效的检验手段。在考试中主观题占有相当大的比例。主观题的分值评定较直观、全面地反映了学生掌握知识的程度,并且对于考试分数具有重要的影响。但人工阅卷对主观题评阅受到多种因素干扰,并不能高效、准确地完成。研究一种智能主观题阅卷系统取代人工阅卷成为教育系统的一个重要任务。笔者研究的主观题阅卷系统主要解决主观性很强的题目(例如论述题、简答题等)的评分算法问题。
1 主观题评分算法相关理论
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向[1]。主观题评分主要涉及中文分词理论和语义相似度计算问题。
1.1 中文分词理论
中文分词理论主要研究汉字中词与词的分隔。中文分词包括3种方法:1)基于字符串匹配的分词;2)基于理解的分词;3)基于统计的分词。
根据系统的要求和特点采用基于字符串匹配分词方法。它是按照一定的策略将待分析的汉字串与一个充分大的机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出1个词)[2]。考虑到逆向最大匹配法分词较为准确,所以系统采用逆向最大匹配法。
1.2 中文文本相似度
文本相似度是表示2个或多个文本之间匹配程度的一个度量参数,相似度越大,说明文本相似程度越高,反之越低。采用基于文本表面特征的相似度计算方法不需要大规模语料库的支持,也不需要长时间的训练,准确率较高。
对于文本A和文本B的相似度通常由词形相似度决定,词形相似度的计算公式[3]如式(1)所示。

其中number(A),number(B)代表文本A和B中分词的个数,Sim(A,B)代表文本A,B的相似度,但仅仅这样计算,精确度不高。需对算法进行改进。
1)将文档分成若干词条,由T={T1,T2,…,Tn}组成。计算词语Ti在文本中的权值Wi,加入评估参数δ。如果Wi≥δ,则词语Ti被提取出来并加入特征向量中,否则,不加入。评估参数δ决定文本特征向量维度的阈值,根据多次实验的数据获得。这样可降低计算效率,降低计算复杂性。
2)对于文本A和文本B,通过中文分词、特征向量提取和降维的步骤后得到词条向量分别为TA={A1,A2,…,An},TB={B1,B2,…,Bn},由式(1)可得到矩阵M(n,n)={|Sij|,即向量TA中第i个词与向量TB中第j个词的相似度}。引入评估参数δ,如果相似度矩阵中的元素Sij≥δ,2个词语相似度较高,这个元素就被保留下来用于在算法中构建最长公共子序列矩阵中的一个判断条件。评估参数δ是决定相似度高低的阈值,根据多次实验的数据获得。
3)利用2个文本得出的词条向量以及上述判断语义相似的条件构建2个文本的公共子序列矩阵,从而求2个文本的最长公共子序列长度,最后用求得的长度之比计算2个文本的相似度。
2 算法实现
基于语义相似度的中文文本相似度算法流程。
步骤1:读取2个需要比较的文本A,B,并对文本A,B进行分词。
步骤2:文本包含的词为T={T1,T2,…,Ti,…,Tn},计算Ti在文本中的权重Wi,得到权重向量W={W1,W2,…,Wi,…,Wn},其中Wi=n×log(M/m)。n为Ti出现的次数,m为其他文本中Ti出现的次数,M为文本的总数。
步骤3:依据上节算法2)对特征向量进行提取和降维,并根据式(1)生成降维后的相似度矩阵Sij。
步骤4:将2个特征向量存入数组arr(A)和arr(B)中,计算2个特征向量的长度L(A)和L(B)。
步骤5:构建最长公共子序列矩阵C[L(A)×L(B)],矩阵大小为L(A)×L(B)。

3 分数评定
在评阅系统设计中,对于某道题,相似度高于Hi的试卷给予最高分HighScorei,语义相似度低于Li的给予最低分LowScorei,相似介于最低与最高之间的,利用式(2)计算得分:

这样对于有m道试题的答卷,其总分由式(3)求得:

4 测试结果与分析
为检验算法分析文本的能力以及系统对试卷评阅结果的准确程度,进行计算机自动阅卷与人工阅卷方法的比较并计算其实际误差率。计算机自动阅卷方法总分表示为C(sum),人工阅卷总分表示为P(sum),试卷中的实际总分表示为R(sum),误差率η的计算公式:
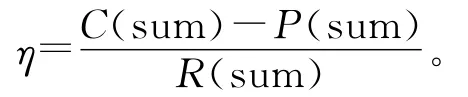
随机抽取500份语文试卷作为样本空间进行手工评分和计算机自动评分,并将结果进行比较,比较结果的部分样本如表1所示。
由表1可以看出计算机阅卷系统的自动评阅方法与人工阅卷方法相比,实际的误差率相对较小,并且计算机阅卷受人为干扰因素很少,在一定的允许误差范围之内,表明该阅卷系统具有较好的准确性和客观性,同时在时间上,系统评阅的优势更加明显。
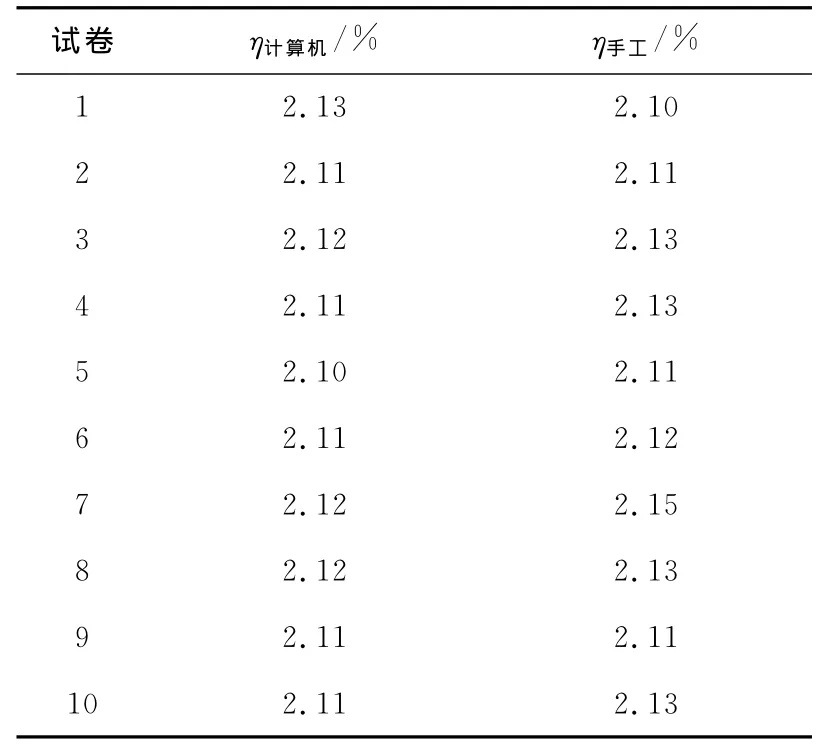
表1 手工评分和计算机自动评分结果比较Tab.1 Result comparison of manual score with auto-grade by computer
5 结 论
主观题的智能阅卷是计算机自动阅卷系统必然选择。模拟了阅卷评定主观题时的思维,对基于语义的相似度算法进行了改进,为主观题评分提供了计算公式。当然,测评科目不同,评估使用的参数设置会有所变化,算法在实际应用中参数修正方面还有待深入研究。
[1] 梁 娜,耿国华,周明全.自然语言处理中的语义关系与句法模式互发现[J].计算机应用研究(Application Research of Computers),2008,25(8):2 295-2 298.
[2] 付年钧,彭昌水,王 慰.中文分词技术及其实现[J].软件导刊(Software Guide),2011,10(1):18-20.
[3] 王常亮,腾至阳.语句相似度计算在FAQ中的应用[J].计算机时代(Computer Era),2006(2):24-26.
[4] 侯贵宾,曹卫东.一种面向自然语言表达的不确定时态数据的建模方法[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2010,31(5):463-467.
Algorithm of subjective item marking based on semantic similarity
ZHANG Li-yan,ZHANG Shi-min
(College of Information Science and Engineerning,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China)
Subjective item marking system has been a study focus.The common method is to contrast the answers with the reference answers to form a score.This paper uses the technology of natural language processing participle to divide a sentence into the assemble of phrases,and then get the score by computing a sentence similarity degree with improved semantic similarity algorithm.
subjective item;participle;semantic similarity
TP391
A
1008-1542(2012)03-0263-03
2011-11-21;责任编辑:陈书欣
张立岩(1970-),女,河北藁城人,副教授,硕士,主要从事分布式应用开发方面的研究。
