基于角色标注的中文POI名称语义分类方法
2012-12-11张福浩刘纪平
罗 安,王 勇,张福浩,刘纪平
(中国测绘科学研究院,北京100830)
一、引 言
当前,互联网已成为发布、使用地理信息的重要途径,据不完全统计,从事互联网地理信息服务的网站超过500家,按照每个网站每天产生500~1000条地理兴趣点标注,每月将产生近1000万条标注,每年将产生1亿多条标注信息。面对数量如此庞大的地理信息兴趣点标注,如何有效快速地对它们进行自动分类,是目前地理信息产业化面临的一个重要问题。
POI标注的信息结构主要包括POI名称、坐标位置及详细描述信息三种信息。由于坐标位置信息不带有文本描述属性,不具有文本分类的作用,详细描述信息作为POI属性特征的详细描述,具有一定的分类特征属性,但由于其篇幅比较长,特征属性偏少,使得整体噪声比较多,因此,本文将POI名称作为其主题分类的重要研究对象。
从词性的角度来看,POI标注的中文名称一般是以专有名词的形式出现,主要以地名、地址、事物名称、机构组织名称等形式表现,往往是特指或泛指某一事物的专用名称。然而专有名词是一个数量巨大、成分复杂、层出不穷的开放集,绝大多数无法收入普通的语文词典。因此,这就使得POI名称的识别和分类具有很大的难度。
目前,英文POI分类方法比较成熟,而中文POI标注信息的分类还处于研究性阶段。相比英文名称,POI中文名称的分类难点主要在于:①中文POI名称是个开放的类,数量巨大,且具有不稳定性,经常会出现很多新的名称或简称等;②名称中的具有复杂的嵌套关系,对其识别和分析造成一定的困难;③中文文本中没有空格等标注性词,使得对于未登录词的分词目前还没有一种成熟的方法。
现阶段,对于中文POI名称分类的方法还比较少,主要集中对POI名称的匹配和机构名的识别等方面,刘晓娟提出一种基于Lucene的中文POI名称的切分与匹配方法,能够根据POI的切分单元的角色不同而模糊匹配[1]。张小衡通过分析中文机构名称的结构而实现对中文机构名称的自动识别[2]。李军针对中文机构名中的未登录词,提出一种基于模板匹配的中文机构名称识别方法[3]。俞鸿魁则提出一种基于角色标注的中文机构名称识别方法[4]。对于中文POI分类一般只是将中文文本分类技术引用到对POI名称分类中,主要通过对名称的特征关键词进行提取,并构建SVM特征向量,然后通过特征向量的相似度计算来进行分类。这种方法主要存在以下两个不足:①没有考虑名称短语与长篇文本信息的区别,并没有专门针对名称短语的结构进行分类算法的设计;②只是简单地通过关键词进行划分,没有从语义的层次上对POI名称进行理解和分类。对于中文地名地址研究已经比较成熟,而对于事物名或机构名的研究还处于探索阶段。
本文根据中文POI名称结构特征,通过对POI名称的切分和不同角色的标注,并利用中文文本处理、语义相似度计算等方法,提出一种基于角色标注的中文名称语义分类方法,提高POI分类效率和精度。
二、POI名称短语的结构分析
从语言学的角度来看,POI名称主要是各种地名、机构名等实体名称,是具有许多特性的专有名词,其构成有一定的规律可循。通常来说,在不考虑简称的情况下,POI名称是一种偏正复合式名词短语。形式上,中文POI名称的构造是[修饰词+]+[中心词],其中修饰词可以是复合型词语,并且可以出现多个,中心词则一般为名词性的名称特征词。换句话说,POI名称是由一个或多个修饰词加上表示实体或机构等称呼的中心名词所组成的。POI名称短语从宏观上来看,属于一种偏正式复合名词,从其内部结构上来看,又属于一类特别的偏正式名词短语。
在POI名称中,最常出现,同时也是最难识别和分析的属于中文机构名称短语,目前对于中文机构名的组织规定分析已经有一些成果。一般都认为,中文机构名称的组织规律大体上是:[地名]+[前缀修饰成分]+[数词]+[经营内容说明]+[专名]+[中心词]。其中修饰语中的[地名]、[前缀修饰成分]、[数词]、[专名]等专用名称至少出现一个,其余的可以按需增加。例如:“北京联想计算机集团公司”、“中国第一汽车制造厂”、“上海人民广播电台”、“北京信息工程学院”、“江苏有色金属合金制造厂”等。并且对于离中心词越近的修饰语,其语义上关系就与整个名称短语的关系性越大,这也正符合中文短语中的多项式定心短语的基本格式和要求,即含两个或两个以上定语的短语,其前面修饰语的格式主要可以分为迭加式、顿加式和列加式三种,其定语之间遵行越是反映事物固定的内在本质的定语离中心词越近的基本语序规则。
三、基于角色标注的POI名称语义分类方法
本文提出的基于角色标注的POI名称语义分类的主要步骤为(如图1):首先利用文中分词引擎,对POI名称短语进行分词处理,将其分为不可再分的词语粒度单元;然后根据各个分词单元的词性特征,对其进行角色标注,确定其在整个名称短语中的地位;再根据角色标注确定名称短语中的中心词,并利用基于中心词的剪枝算法,去除不具有实际意义的词语标注;最后根据赋权重的语义相似度算法,设置修饰特征词与中心词的语义权重,计算POI名称与分类体系中各个类别的相似度,实现POI名称的自动分类。

图1 POI名称自动分类
1.POI名称的角色标注
根据POI名称结构的分析,能够发现POI名称中的各种词处于不同的位置,而使得其在POI名称中扮演的角色也不同,在名称分类中的作用也不相同。因此,本文首先根据POI名称中各种词的不同词性进行角色标注。
在角色标注时,本文主要通过对POI名称中的词性进行标注。其方法主要是根据带词性的分词词典进行对中文POI名称短语的分词和词性标引,而对于具有多种词性的词语的词性选择时,可以利用隐马科夫(HMM)模型方式进行词性组合的选择和确定。其具体方法如下:对于一个给定的中文POI名称短语W=w1w2w3…wm,首先通过带有词性标注的分词词典对词串W进行相应的角色标注,记录为T1=t11t12t13…t1m、T2=t21t22t23…t2m,…、Tn=tn1tn2tn3…tnm。然后根据计算T1,T2,…,Tn中哪种组合出现的概率最大,即求使得P(T|W)概率最大的那个角色标注串Ti
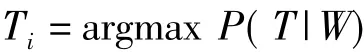
根据贝叶斯公式,有P(T|W)=P(T)P(W|T)/P(W)。
上述问题可以利用HMM模型进行求解,将POI名称短语wi作为观察值,角色标注系列ti作为状态值,则W为观察序列,T为状态序列。从而对角色标注序列T的求解就迎刃而解。从而实现中文POI名称的角色标注,如图2所示。

图2 POI名称角色标注
2.基于中心词的裁剪方法
通过对POI名称短语的角色标注,使得POI名称中各词的词性都具有标注信息,说明其在名称短语中的不同作用。从POI名称结构中,可以发现作为偏正式的名词短语,其中心词往往为名称的后部,为了简单和方便,本文选取POI名称角色标注中最后一个名词作为其中心词。例如:“华夏集团有限公司”其中心词为“公司”,“雷达表专卖商店”中心词为“商店”。然后根据POI名称短语中其余部分的不同角色标注,进行枝叶裁剪。
根据POI名称中各构成词的作用分析发现,其名称结构中的词可以大致分为地名、专名、业务名、修饰词、门类词、数字和通用名,其中的地名、修饰词、门类词和数字对于POI名称分类的作用不大,专名、业务名和通用名等相关名词就可以对POI名称进行分类。例如:“北京教育局”作为POI标注名称,其中北京作为地名来修饰教育局的,而对于整个名称短语的分类并没有影响。同时又存在一些修饰词并不是直接修饰中心词,而是修饰中心词的限定词,这类词对于POI名称分类也没有实际意义,如“上海大学嘉定校区”,上海是修饰大学的,而嘉定则是修饰校区的,这两个地名名称都不影响标注的分类,只有大学作为修饰校区的一个前缀修饰名词,用来说明该校区是指大学的校区,对分类是有一定的影响。
因此,本文采用以中心词为基础的枝叶裁剪方法,通过选定POI名词短语中的中心名词,然后根据中心词前面和后面不同位置进行不同方式的裁剪,其具体裁剪方法为:
1)对于位于中心词后面的部分,这部分内容主要以一些方位词出现,可以是对POI名称位置的说明,这类方位词对于POI名称的分类没有任何作用,如“北京大学东边”中“东边”是个方位词,其裁剪方法是直接去除。
2)对于位于中心词前面的部分,这部分内容可以是多重复合型名词定语,其中有些特征性名词、专用名词及表示作用的通用名词都对POI名称分类有很多作用,而对于非名词性词语、地名、人名、数字等对于POI名称分类作用不大,因此,该部分的裁剪方法主要是对于非名词性标注的词和地名性的名词可以直接去除,对于其他名词可以根据其内部语义关系进行选择性去除。
例如:北京海关驻顺义区办事处南面,通过上述裁剪方法如图3所示,将中心词“办事处”后面部分去掉,并将前面部分的地名性名词和动词去掉,最后剩下“海关/nd办事处/nc”。
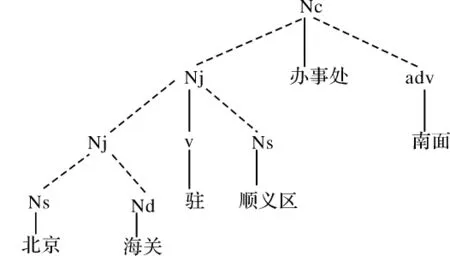
图3 基于中心词的裁剪算法
3.POI语义分类方法
通过对POI角色标注,根据POI名称中不同角色的划分进行语义相似度分类计算,其主要方法为:为中心词赋上比较高的权重,然后根据离中心词距离的远近分配不同的权值逐一对不同角色标注信息进行赋值,再通过计算每个名词角色之间的语义相似度,来实现整个POI名称短语的相似度的计算,最后通过相似度的选择实现POI的自动语义分类。
POI名称自动分类算法如下
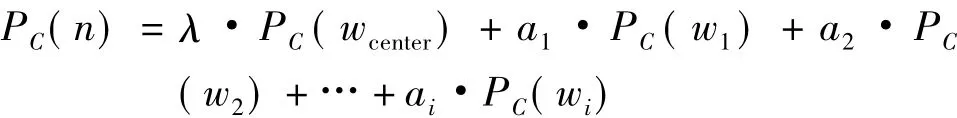
式中,PC(n)表示名称为n的POI属于分类C的概率;P(wcenter)表示POI名称中中心词属于C的概率;PC(wi)表示第i个修饰词属于C的概率;λ、ai为[0,1]之间的参数,并且∑(λ,a1,…,ai)=1。
对于POI中每个词语之间属于某一分类的概率则直接通过其与分类词语的语义相似度进行衡量。一般而言,两个词的语义距离是一个位于[0,∞)之间的实数。两个互不相关的词语之间的距离为+∞,两个相同词语或同义词语之间的距离为0。词语之间的语义相似度则跟其距离具有密切的关系。即:两个词语的距离越大,其相似度就越低;相反,两个词语的距离越小,其相似度就越大。二者之间可以建立一种简单的映射关系。这种映射关系需要满足以下几个条件:
1)两个词语距离为0时,其相似度为1;
2)两个词语距离为+∞时,其相似度为0;
3)两个词语的相似性与它们之间距离成反比。
然而词语的语义相似度,也并不是仅仅与其距离相关,还应该考虑其他一些相关因素,例如:词语所处语义树中的深度、区域密度等因素,因为如果某两个词语处于构建的语义树的顶层,就算其距离很小,但是由于其节点之间分类跨度很大,其相似性相对就很小,而当某两个词语处于语义树的底层,此时分类类型比较精细,使得其词语距离相同的情况下,相似性相对比较大。
因此,本文采用的词语W1与W2相似度计算算法为
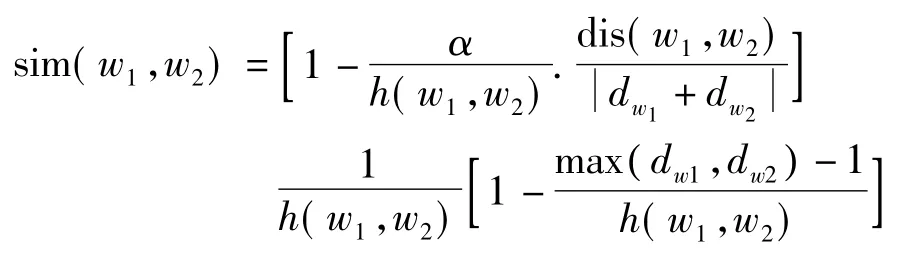
式中,sim(w1,w2)为两个词语之间的相似度;α是用于控制词语深度影响的可调节参数;dw1、dw2表示W1与W2的各自的语义距离;h(w1,w2)为词语W1与W2共同最小父类的深度值;dis(w1,w2)为W1与W2之间的词语距离。
四、试验与分析
为了对本文的POI名称分类方法进行验证,主要建立的分类包括军事、公共设施、组织机构等在内的15个一级类,33个二级分类以及72个三级分类,然后通过计算POI名称与各类之间的相似度进行自动分类。例如:以POI名称为“老式军事雷达”的POI分类为例,其分类结果如图4所示。
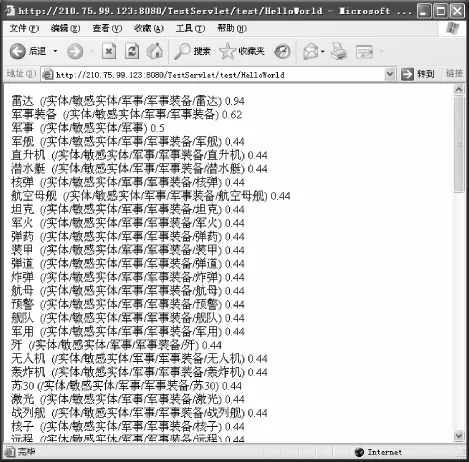
图4 试验分类结果
为了进行大量 POI名称分类的测试,选取meet99网站的1万条POI记录进行测试,通过对这1万条POI名称的自动分类,能够找到军事类的167条,其中遗漏POI数量为12条,错误归类的数量26条,说明了本文POI名称自动分类的准确度为84.4%,召回率为92.1%,如表1 所示。

表1 试验结果分析表
从上述的分类结果可以发现,本文的中文POI名称分类方法能够在分类准确率和召回率上有所提升,尤其是在召回率上面比较高,其原因可能主要分为以下几点:①一条POI根据其名称可能被分到多个类别中,也可能不能归类到任何类别,这就需要通过分类中相似度的阈值进行设置,在试验中,设置的相似度阈值为0.3,能够在确保一定分类准确率的基础上,提高分类的召回率;②从语义的层次上进行深入挖掘POI名称中的语义信息,使得其归类的数量就相对多了些,相应地提高了分类算法中的召回率。
五、结束语
本文介绍了一种基于角色标注的中文POI名称分类方法,首先对中文POI的组成结构进行了相关分析,然后针对其结构特征进行中文分词和角色标注,然后通过以中心词为依据进行名称中各种词性角色的裁剪,再通过对中心词和前置修饰名词的语义相似度计算,来实现POI名称的分类,最后通过试验进行验证和结果的分析。
从试验的结果来看,本文的分类方法具有一定的效率,但由于中文POI短语角色标注的不成熟及语义词典构建不完整等问题,使得POI自动分类还需要进一步的研究,这将是今后POI分类研究中需要重点解决的问题。
[1]刘晓娟.基于Lucene的中文兴趣点名称的切分与匹配研究[J].电脑知识与技术,2011,21(7):1009-3044.
[2]张小衡,王玲玲.中文机构名称的识别与分析[J].中文信息学报,1997,4(11):21-32.
[3]李军,王丁,王鑫.基于模板匹配的中文机构名识别[J].信息技术,2008,6(25):97-99
[4]俞鸿魁,张华平,刘群.基于角色标注的中文机构名识别[C]∥Proceedings of the 20th International Conference on Computer Processing of Oriental Languages.Shenyang:[s.n.],2003.
[5]万菁,姬东鸿,任函,等.汉语复合名词短语特征结构的标注研究[M]∥中国计算语言学研究前沿进展.北京:清华大学出版社,2011:94-99.
[6]朱嫣岚,闵锦,周雅倩,等.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,1(20):14-20.
[7]张雪英,朱少楠,张春菊.中文文本的地理命名实体标注[J].测绘学报,2012,41(1):115-120.
[8]张华平,刘群.基于角色标注的中国人名自动识别研究[J].计算机学报,2004,27(1):85-91.
[9]杨德来.SVM和最大熵相结合的中文机构名自动识别[D].大连:大连理工大学,2006.
[10]王红玲.基于特征向量的中英文语义角色标注研究[D].苏州:苏州大学,2009.
