母线负荷预测的实用算法
2012-12-05陈小平
陈小平
(四川电力送变电建设公司,四川成都 610051)
随着调度自动化系统与母线负荷量预测装置的不断完善,母线负荷预测能更好地实现分散式的负荷管理,对电网动态状态估计、安全稳定分析、无功优化、厂站局部控制等方面都有重要意义。母线负荷是电网各母线节点负荷,包括有功负荷和无功负荷。实际所指的母线负荷一般是有功负荷[1]。母线负荷具有基数小、稳定性不强、负荷变化的趋势不明显、有坏数据、母线间的差异较大等特点,所以母线负荷的预测难点是提高精度[2]。
目前,母线负荷预测主要有两大类方法:一类是基于母线负荷自身变化规律的预测方法[3]。这类方法认为:与全网负荷的分析过程类似,母线负荷自身具有特定的变化规律,可以用全网预测的某些方法来进行母线负荷预测。但由于母线负荷容易发生突变,稳定性比系统负荷差,因此如果简单借鉴系统负荷预测方法可能产生较大的误差;另外一类是基于系统负荷分配的预测方法,即分布因子法[4]。该类方法的思路是:首先由全网负荷预测取得某一时刻全网的负荷值,然后按照一定的比例因子将其分配到每一条母线上。国内外集成于能量管理系统(EMS)中的母线负荷预测功能大多是采用这种预测方法,其特点为便捷易用,准确性较高。但缺少独立的母线负荷规律性分析和预测手段,在精细化预测及可扩展性方面还有待提高。
在传统的基于母线负荷分配系数的基础上,提出一种考虑天气、节假日、企业生产变化、母线负荷转供等因素的母线负荷预测实用算法,利用该算法对某地区进行母线负荷预测,具有很高的准确率,分析其结果完全能够满足母线负荷考核的需求。
1 母线负荷建模与指标
1.1 母线负荷模型
结合调度一体化网络,所提的母线负荷结构采用分层树状结构,如图1所示。在图1母线负荷结构中,形成的负荷对象是区域、厂站的层次关系,第一层为系统负荷,第二层为区域负荷,第三层是变电站负荷,第四层是母线负荷。在实际的电网中,母线上的各种负荷交杂,且影响母线负荷的外在因素也不同,如天气、节假日、企业生产变化、母线负荷的转供等,所以静态模型的负荷成分比重是不同的。母线负荷预测中,要提高预测精度,需合理地确定母线的负荷成份比重。
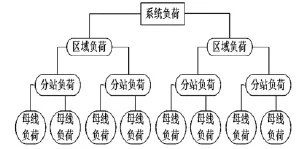
图1 母线负荷预测树型结构
1.2 母线负荷的预测指标
预测精度根据国家电网《电网母线负荷预测功能技术规范》中规定的准确率指标进行计算。采用每日96点负荷数据(每天00:15~24:00,每15 min一点),其主要考核指标如下。
(1)单母线负荷i每时段j的相对误差

(2)母线负荷预测准确率(%)

式中,Ai为时段k的区域统计误差
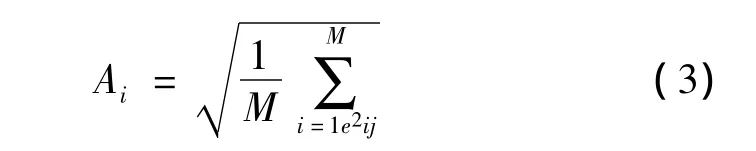
(3)母线负荷预测合格率

其中,M为区域内考核的母线负荷总数;N为日预报总时段数。
2 算法的主要思想
该算法的主要思路如下:确定需要使用的母线负荷模型后,通过对最近的D天历史样本数据进行模式匹配分析,计算所有历史日与待预测日的相似度,并对所有历史日的相似度进行排序,选择前面的n天作为相似日,在此基础上对预测日的母线负荷进行预测。下面以母线负荷的有功为例,其详细步骤如下。
1)相似日的选择
选择星期类型,天气类型,日最高气温,最低气温作为影响负荷变化的主要因素,根据文献[5]提供的思想和方法将相应的影响因素映射到特征量映射表中。根据映射以后的标准特征值确定日特征量的差异度、相似度,选取相似日。设预测日的标准特征向量为x0,历史各日的特征向量为 xi,其中 i=1,2,…,m,且
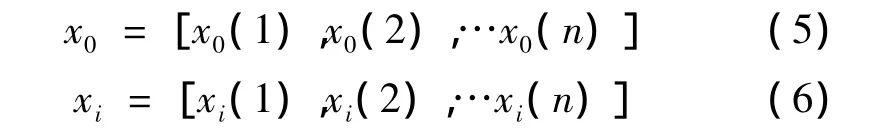
则定x0和xi在第k点的关联系数为ζi(k)。
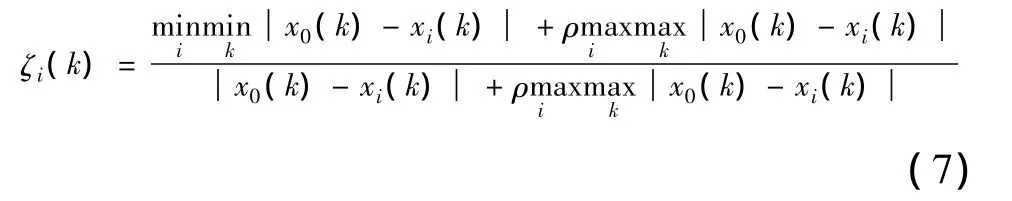
综合各点的关联系数可以得到整日的相似度si为
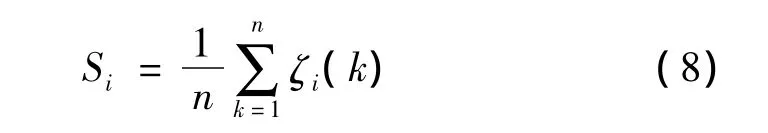
在相似日的选择中相似度Si越大,说明历史日与预测日在日类型上相似日度越大。另外,在相似日的选择中,将一年分为春夏秋冬四季,相似日只在同一个季节中选择。
2)对选取的D天的样本集,有相似度Si(i=1,2,…,D),进行归一化处理,如式(9)所示。

3)对其排序,选择其中相似度较大的n(n<D)天的样本数据作为相似日样本备用数据。假设一共有母线负荷N个,一天有T(T一般等于96)个点,则待预测日的母线负荷数据是这n天样本母线负荷的加权平均值,如式(10)所示,其中P0jt表示待预测日的第j(j=1,2,…,N)个母线负荷在一天的第t(t=1,2,…,T)个点母线有功负荷值,si为归一化后的第i天相似度。
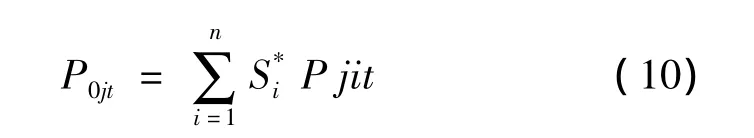
4)根据式(10)得到每点的所有的母线负荷数据求取其母线负荷分配系数,如式(11)所示。
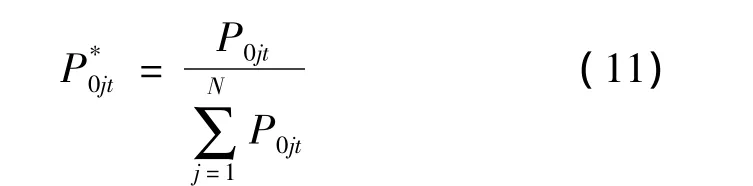
5)接入待预测日的所有T点的系统负荷预测值Lt(t=1,2,3…,T),则可以得到待预测日的所有母线负荷值。如式(12)所示。

3 关键技术
3.1 预测样本
在实际的电网中,母线负荷时间序列比系统的总负荷更具有分散性、波动性、非线性,母线负荷预测比系统的预测更为复杂,更具有不确定性。当前母线负荷预测的数据来源主要是15分钟的状态估计结果,在状态估计出现连续不收敛或厂站排除等情况下,母线负荷预测可能会出现某些时段样本数据缺失。可采用提高采样频率、增加SCADA数据源交叉验证等方式,来获取相对稳定可靠的样本数据。
3.2 数据预处理
母线负荷数据量大面广,属于海量数据管理的范畴。在面对海量数据的同时,母线负荷中出现不良数据的情形比较常见,对预测准确率有很大的影响。对于不良数据的处理,如完全依赖手工修正的方式几乎是不可能的,因此需要一种坏数据自动修补技术进行预处理。在该方法中,主要利用状态估计和SCADA数据双源热备机制来维护数据的完整性。一方面,利用特征分析等方法,通过符合数据的横、纵向的对比来分析、辨识和记录不良数据;另一方面,利用插值、虚拟预测和特征值提取等方法来修补坏数据。
3.3 预测结果校验
母线负荷对象都经过具体的设备进行传输,并实现等值负荷建模,如主变压器高压侧、线路等值,这些设备传输功率都可定义功率上下限,在预测结束后,对预测结果进行基本的合理性检验,可以避免预测结果中由于总负荷功率分配方式而出现越限的不合理现象。除了通过上述的静态限值方式,进行校验外,还需要根据负荷的历史变化规律,动态分析分析负荷的典型曲线和变化曲线,找出可疑的预测结果,并按照可疑程度进行分级显示,简化使用人员工作量。
4 仿真分析
为便于分析,算例以一周连续7日负荷预测的结果为例。为避免预测样本数据和待预测样本数据时间重叠,采用某省2010年9月10日至2010年10月10日期间某条220 kV母线负荷的历史数据,对2010年10月20日至2010年10月26日的负荷进行预测,每日预测点数为96点。
仿真过程中,结合前述关键技术,按照“提取样本数据—数据预处理—母线负荷预测算法—预测结果校验”等步骤,用MATLAB程序实现上述算法。选取平均日母线负荷预报准确率和平均日母线负荷预测合格率作为分析和评判的依据。结果如表1。
从表1分析可知。
1)从选取的7天的结果分析可知,所提的实用算法平均预测准确率达到了91.41%,平均合格率达到了89.68%,完全满足母线负荷预测考核的要求;
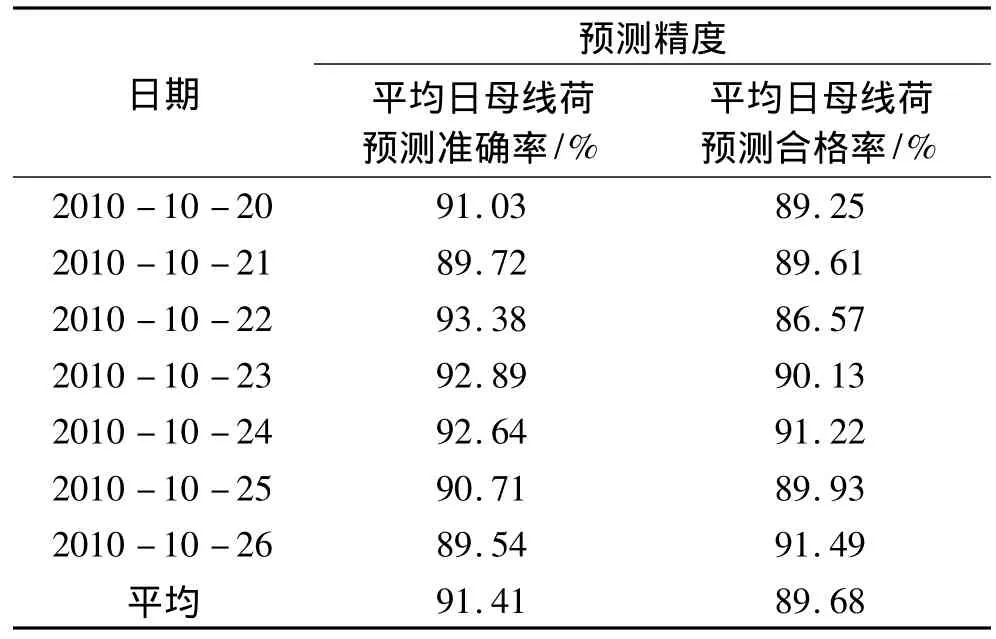
表1 平均日母线负荷预测准确率和合格率分析表
2)2010月22日的平均准确率相对较高,但其平均合格率却相对较低,10月26日则正好相反;可以说明平均合格率和平均准确率没有必然的联系;
3)由于天气预报提供的信息不准确等原因,可能造成某天准确率较低。所以算法在对天气等因素的考虑上仍需较多改进。
5 结论
在传统的基于母线负荷分配系数的基础上,提出了一种考虑多种不确定因素的母线负荷预测实用算法,该算法借鉴短期负荷预报中的成功应用经验,从历史样本数据中依照天气、节假日、企业生产变化等不同情况的负荷特性,选择相似日匹配,最后依照与待预测日模式的距离函数值的大小确定其间的权重关系。通过对某地区母线负荷进行实例仿真,分析发现该方法具有较高的精度和较强的工程实用价值。对外部因素考虑的还不够全面,今后当进一步加强这方面的信息,更大地提高母线负荷预测精度。
[1]辛丽虹.电力系统母线负荷预测研究[D].成都:四川大学,2000.
[2]康重庆,夏清,刘梅.电力系统负荷预测[M].北京:中国电力出版社,2007.
[3]Espinoza M,Joye C,Belmans R,et al.Short-term Ioad Forecasting,Profile Identification and Customer Segmentation:A Methodology Based on Periodic Time Series[J].IEEE Trans on Power Systems,2005,20(3):1622 -1630.
[4]鞠平,马大强.电力负荷系统建模[M].北京:中国电力出版社,2008.
[5]牛东晓,曹树华,卢建昌,等.电力负荷预测技术及其应用(第二版)[M].北京:中国电力出版社,2009.
