一种分布式数控系统的调度策略研究
2012-11-24冯宁
冯 宁
(广东机电职业技术学院,广州 510515)
0 引言
随着数控技术的不断发展,开放式、模块化和可重构是当前数控系统开发的一个热点研究内容。开放式数控系统以其资源的开放性、可重构和可共享等优点,成为数控系统发展的一个重要方向。本文提出了一种基于现场总线的分布式数控系统的架构,数控系统的各个功能节点通过现场总线连接通信,各功能节点之间耦合性低,系统具有良好的开放性和可重构性。针对该架构,分别为系统的主站和从站设计了不同的调度策略,充分发挥系统主站和从站的设备性能特点,保证系统具有良好的实时性和低的作业丢失率。
1 系统的模型
如图1所示,数控系统以PROFIBUS-DP现场总线作为中心,各个功能模块按照PROFIBUS-DP的规范要求插在总线上,各模块之间通过PROFIBUS-DP总线进行通信。系统采用主从结构,以带有CP5611卡的PC机作为单一主站,各个智能控制器作为从站。系统主站和从站之间通过PROFIBUS-DP现场总线交换加工数据信息、故障诊断信息、时间同步等信息。系统的参数设置、刀补功能、粗插补功能等在PC机内完成,精插补、位置控制、速度控制由各个智能控制器完成。系统从加工程序到粗插补过程所发生的数据交换都在PC机内部进行,从精插补到速度控制所发生的数据交换都在智能控制器内部进行,只有粗插补和精插补之间的数据交换是通过PROFIBUSDP总线在PC机和智能控制器之间进行,系统各模块之间数据交换量较小,通信额外占用资源较少。
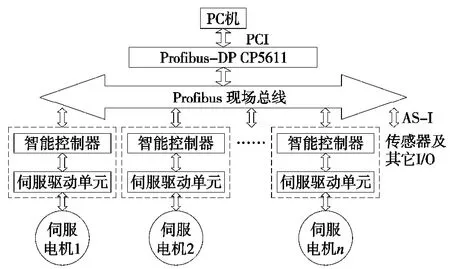
图1 系统硬件结构模型
2 系统主站与从站之间的信息交换与同步
系统的各个功能节点通过PROFIBUS-DP总线进行通信,实现主站和各个从站之间的信息交换和同步。系统各功能节点之间所要交换的信息包括加工数据信息、故障诊断信息、时间同步信息等,其中最主要的是加工数据信息。系统的加工数据信息流程如图2所示。从图2看出,从加工程序到粗插补过程所发生的数据交换都在PC机内部进行,从精插补到速度控制所发生的数据交换都在智能控制器内部进行,只有粗插补和精插补之间的数据交换是通过PROFIBUS-DP总线在PC机和智能控制器之间进行。从图2还可以看出,粗插补的结果送入精插补缓冲区,而并非立即进行精插补运算,也就是说粗插补和精插补并非同步,这就使得PC机的粗插补运算对实时性的要求不高,可以根据任务的负载情况合理安排,提高了系统主站任务调度的成功率。

图2 系统的加工数据信息流程
PC机粗插补运算所得的数据以报文的形式通过PROFIBUS-DP总线传送到各个智能控制器,独立完成各轴的控制。粗插补运算和精插补运算并非同步进行,但各个智能控制器的精插补运算必须同步进行,以保证各轴之间的正确联动。各轴的状态通过智能控制器反馈到PC机,PC机要完成故障的诊断并对智能控制器发出相应指令,这也对主站和从站有同步要求。PROFIBUS-DP通过MS3报文,主站将实时时间标记发送给所有的从站,将从站的时钟同步到系统时间,误差小于1ms,保证了系统具有高精度的同步性。
3 系统任务的调度策略
3.1 数控系统任务分析
系统各项任务被分配到主站和各个从站完成,主站完成的任务包括文件管理、参数设置、粗插补程序等非实时任务和实时任务,各个从站分别控制各轴,完成精插补、速度控制、位置控制等实时任务。由于从站具有高度的自治性,能够独立地完成自己的任务,主站的粗插补与各个从站的精插补、速度控制、位置控制不必同步进行,主站可以离线进行插补运算,然后将运算结果根据需要传送到从站,从而降低了主站的实时性要求,保证了系统任务调度的高成功率。系统的主站和从站都具有高度自治性,所需处理任务的性质不同,因此采用不同的调度策略。
3.2 系统从站的任务调度
系统从站的任务主要包括精插补、位置控制、速度控制、状态检测、与主站通信等,这些任务都是实时周期性任务,特别是位置控制、速度控制等任务在执行过程中,除系统故障外,不允许被其它任何任务中断。由于从站的任务比较稳定,且周期性强,各个任务执行的顺序和所需时间都是固定的,故采用时间片轮换调度的方法,系统的各个任务按照固定的顺序进入任务队列排队,在上一个任务完成后由调度程序将下一个任务转入运行状态,同时时间中断服务程序开始计时,该任务在规定的时间片内完成后,又转到下一个任务执行,如此不断循环执行。这是一种单调速率的调度算法,具有运行开销小、稳定性和可预测性好的优点。
3.3 系统主站的任务调度
3.3.1 主站的弹性周期调度策略
系统主站是一种混合任务系统,既包括周期任务,也包括非周期任务,其调度目标是:①周期性实时任务采用最早截止时间优先调度算法(EDF),所有周期任务能够在规定的结束时刻Ti之前完成,在周期性任务执行的间隙,能有足够的资源使得突发性实时任务和非实时任务得以调度执行;②通过动态调整重复周期Ti,使周期性任务执行间隔时间尽可能短,CPU的利用率和作业丢失率维持在一个合理的水平。
本文设计了一种弹性周期调度策略,其调度框架如图3所示。任务调度服务程序是整个调度框架的核心,它接受就绪任务的调度申请,并根据任务可调度性分析结果,判定是否有足够的CPU资源和内存资源,将该就绪任务由就绪等待状态变为运行状态。具体的调度算法如下:
(1)一个新的任务到来后,通过任务状态管理程序将其送入非实时就绪任务队列或实时就绪任务队列;
(2)非实时任务的优先级低,在CPU完成实时任务的间隙,采用分时调度策略处理。非实时任务在非实时就绪任务队列中排队,按先进先出的顺序等待调度;
(3)实时就绪任务在实时就绪任务队列排队,并动态设置优先级,实时任务采用抢占式调度策略,优先级最高的任务得以调度执行;
(4)为了提高调度的成功率,调度前进行可调度性分析,只有在CPU资源、内存资源、时序要求等运行条件满足时,任务才得以调度;
(5)当满足运行条件时,任务调度服务程序激活优先级最高的任务,将该任务由就绪等待状态变为运行状态,并分配运行所需要的资源。如果该任务是先前挂起的任务模块,则为该任务进行断点复原。
(6)由时间中断服务程序提供时间中断服务,运行任务必须在规定时限内完成。若任务完成,则在就绪任务队列中注销该任务。当前运行任务有可能在完成之前中断运行,转入挂起状态,进行断点保护,并进入挂起任务队列,这主要是以下3种情况导致:①就绪任务队列有比当前运行任务优先级更高的任务,中断当前任务的运行;②当前运行任务的运行条件变为不满足,被迫转入挂起状态;③当前运行任务的时限已到。对于第①种和第②种情况,当运行条件满足时,任务调度服务程序为其进行断点复原,重新运行;对于第③种情况,若该任务对后续任务处理无影响,则在就绪任务队列中注销该任务,否则该任务通过任务状态管理程序进入实时就绪任务队列重新排队;
(7)周期调节程序根据CPU的利用率和作业丢失率来调节观测周期Tt,若CPU利用率太低,则缩短观测周期Tt,若作业丢失率太高,则延长观测周期Tt。
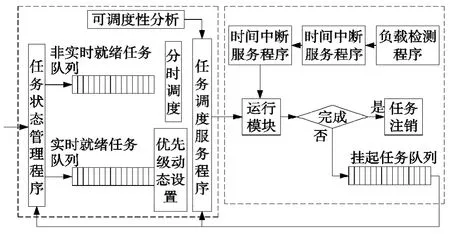
图3 弹性周期调度框架模型
3.3.2 运行周期的动态设定
定义1 观测周期Tt:观测CPU的利用率和作业丢失率时,以观测周期Tt为时间基准进行观测。为了尽量减少任务跨越观测周期,提高观测准确性,Tt取值为各周期性任务周期T的最小公倍数。
定义2 处理器利用率:为混合任务中所有任务对处理器的利用率之和。
处理器利用率U=UP+UN。
定义3 作业丢失率:作业丢失率L(k)为观测周期Tt内,超过时限的实时任务的数量与实时任务的总数之比。对于周期性任务,如果实际完成时间超过截止时间T,则该任务丢失;对于非周期任务,其实际执行时间为Ts=t-e,其中t为当前时刻,e为任务实际开始时刻,当达到条件Ts>Tmax,则该任务丢失。
理想情况下,只要满足U<1,则所有的任务都能够调度执行。但实际上在观测周期Tt内,不可能所有任务都按理想情况均匀发生,突发性任务的发生是随机的,当U越接近1,作业丢失的概率越高,为了保证任务调度的成功率,给出一个处理器利用率的上限参考值UH,当处理器的实际利用率U<UH时,就基本能够保证作业丢失率在一个合理的水平;同时,为了防止因周期任务的周期过长,处理器利用率过低而导致实时性变差,给出一个处理器利用率的下限参考值UL。
(1)当处理器实际利用率U>UH时,则处理器利用率过高,会造成过高的作业丢失率,这时可以采用延长周期性任务重复周期的方法,降低系统处理器的利用率到合理水平。为了防止频繁启动周期延长程序,每次当实际利用率U>UH时,通过延长周期任务的重复周期T而使处理器利用率达到U1,U1的取值为处理器的允许最高利用率UH和最低利用率UL之间的一个值。
为了将处理器利用率由U降到U1,则需要降低利用率ΔU=U-U1,如果使周期任务的处理器利用率降低ΔU,因为非周期任务的处理器利用率也会同时降低,则处理器的实际利用率会低于U1。理想情况下,周期任务都能够调度执行,在观测周期Tt内,所有周期任务的实际执行时间P是固定的,故周期任务的处理器利用率UP是确定的。在周期延长前,有:

延长周期后,假设对应的观测周期由Tt延长到Tt+ Δt,则有:UP-ΔU=P/(Tt+Δt) (2)
由式①和式②可得:

对于任一周期任务,假设其在一个观测周期内执行K个周期,在周期延长前,有:

在周期延长后有:

由式③和式④可得:

(2)当处理器实际利用率U<UL时,则处理器利用率过低,会造成系统实时性较差,这时可以采用缩短周期性任务重复周期的方法,维持系统处理器的利用率到合理水平。为了防止频繁启动周期缩短程序,每次当实际利用率U<UL时,通过缩短周期任务的重复周期T而使处理器利用率达到U2,U2的取值为处理器的允许最高利用率UH和最低利用率UL之间的一个值。
为了将处理器利用率由U升到U2,则需要升高利用率ΔU=U2-U,如果使周期任务的处理器利用率升高ΔU,因为非周期任务的处理器利用率也会同时升高,则处理器的实际利用率会高于U2。理想情况下,周期任务都得以调度执行,在观测周期Tt内,所有周期任务的实际执行时间P是固定的,故周期任务的处理器利用率UP是确定的。在周期缩短前,有:

缩短周期后,假设对应的观测周期由Tt缩短到Tt- Δt,则有:
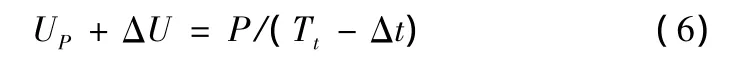
由式⑤和式⑥可得:

对于任一周期任务,假设其在一个观测周期内执行K个周期,在周期缩短前,有:

在周期缩短后有:

由式⑦和式⑧可得:

3.3.3 弹性周期动态设定算法验证
对弹性周期动态设定算法进行仿真验证,在验证中将 UL、UH、U1、U2分别设定为 15%、95%、80%、50%,验证方法为:每隔5ms采样一次CPU的利用率,统计数据如表1所示,数控系统在正常运行情况下CPU的利用率为60%左右,通过触发一个实时突发任务,该任务执行周期0.1s,检测到CPU在10ms时刻利用率接近95%,然后在弹性周期调节程序作用下,检测到CPU在20ms时利用率稳定在80%左右,系统能够快速从饱和状态收敛到稳定状态。

表1 CPU利用率统计表
4 结论
(1)系统采用基于PROFIBUS-DP现场总线的分布式结构,结构清晰,软硬件设计简单;分布式结构大大提高了系统的组态性能,增强了系统的柔性和开放性;由于每个智能控制单元控制一个轴,需要实时处理的任务少,可以达到更好的控制性能。
(2)系统从站自治性较强,主站和从站相对独立;由于系统的粗插补与精插补并非同步进行,从而降低了系统对主站实时性的要求。
(3)系统主站采取弹性周期调度策略,通过动态调整周期任务的重复周期,使主站CPU的利用率和作业丢失率维持在一个最佳平衡点;智能从站采取一种单调速率调度算法,主站周期任务重复周期的动态调整对从站基本上没有影响,而从站直接控制各轴,系统的加工质量直接取决于从站的实时性;因为系统根据任务的特点,主站和从站采取不同的任务调度策略,使得主站和从站均能充分发挥自身设备性能的特点,系统达到整体性能最优。
[1]周刚,邬义杰,潘晓弘.数控系统软件模块实时调度方法[J]. 机械工程学报,2009(1):162-166.
[2]秦承刚,于东,吴文江,等.一种面向数控系统的动态反馈调度模型[J].小型微型计算机系统,2010(4):788-792.
[3]梁宏斌,王永章.基于Windows的开放式数控系统实时问题研究[J].计算机集成制造系统,2003(5):403-406.
[4]郭伟.基于全分布式数控系统的自治式控制单元及关键技术研究[D].上海:上海交通大学,2008.
[5]谢经明,周祖德,陈幼平,等.基于现场总线的开放式数控系统体系结构研究[J].华中科技大学学报,2002(4):1-4.
[6]姚鑫骅,潘雪增,傅建中,等.数控系统的混合任务模型及其最优调度算法研究[J].浙江大学学报(工学版),2006(8):1315-1319.
[7]郑飞,王时龙,简毅.可重构分布式数控系统的设计与实现[J].计算机集成制造系统,2008(4):637-643.
