基于Web结构的网站新闻采集系统的设计与实现
2012-10-21陈建国
陈建国
基于Web结构的网站新闻采集系统的设计与实现
陈建国1,2
(1. 湖南大学软件学院,湖南,长沙 410082;2. 厦门理工学院,福建,厦门 361021)
在深入研究网络信息采集技术的基础上,提出一个基于Web结构的新闻采集模型。该模型加载采集入口地址后,通过信息采集和过滤算法确定新闻列表页,结合正则表达式技术自动识别新闻内容页的链接地址,访问目标新闻内容页,使用采集算法自动提取新闻信息数据。同时,它可以过滤在此页面中嵌入的广告等信息。实践结果表明,该模型工作良好,可以自动化、高效率地采集新闻信息。
信息采集;Web结构;正则表达式;数据挖掘;新闻采集
1 WEB信息采集和新闻采集
1.1 Web信息采集
Web信息采集是指通过Web页面之间的链接关系,从Web上自动地获取页面信息,并且随着链接,使用广度优先遍历算法不断地向所需要的Web页面查找、扩展的过程[1]。
1.2 新闻采集
新闻采集是Web信息采集在网络新闻领域的应用[2]。其核心实现过程如下:由采集入口URL开始,将这些URL放入一个采集队列,顺序读取URL以获取目标网页,调用采集和过滤规则在信息页面中进行信息识别和提取,最后将采集得到的新闻信息和相关数据保存到数据库或其他进一步加工。
1.3 研究现状
目前,国内外关于Web信息采集技术的研究已取得一定成果,总结如下:
基于自然语言处理[3]:主要适用于含有大量文本的Web页面,将Web文档视为文本进行处理的,抽取的实现没有利用Web文档独特于普通文本的层次特性.获得有效的抽取规则需要大量的样本学习[4]。
基于包装器归纳方式的信息抽取[5]:该系统语义和模式信息是用户附加的,通过感兴趣信息的左右边界实现信息的定位,该方法仅仅使用语义项的上下文来定位信息并没有使用语言的语法约束[6]。
基于本体的信息采集方法[7]:利用对数据本身的描述信息实现抽取,较少依赖网页结构。
基于查询的Web信息提取[8]:使用Web的相关技术解决Web的问题,由于Web抽取规则的形式和感兴趣信息的定位方式各不相同,因此均不具有通用性。
基于语义信息抽取技术[9]:由于HTML标志缺乏对数据本身的描述,又因为数据受描述语法,文化区域和应用领域等方面的限制,缺乏足够的语义信息,因此影响抽取效率和准确度。
1.4 本文工作内容
虽然网页类型和结构不同,但一个网站中的各页面结构具有一些特定规则,如页面内容往往是以一种结构化的方式来组织,所以我们可以根据web结构进行网络新闻信息的提取和采集,研究web结构,结合正则表达式,通过页面结构的模式匹配实现数据提取和收集。本文的主要任务:
(1)设计一个基于Web结构的新闻采集系统模型;
(2)页面采集算法,信息块采集算法和信息块过滤算法研究;
(3)实现基于Web结构的新闻采集系统。
2 基于Web结构模型的新闻采访
2.1 系统模型
本系统通过采集入口和页面采集算法进入新闻列表页,调用信息块采集方法确定新闻内容页的URL列表,然后自动加载URL列表中的目标页,调用信息采集和过滤算法反复采集新闻内容的信息,最后存放到相应数据库中。本系统支持采集入口设置,采集规则和过滤规则设置,并支持批量采集功能,采集时间和周期可调节。
2.2 信息采集和过滤算法
本系统所用到的信息采集和过滤算法主要包括以下三种:
(1)页面采集算法:通过URL加载一个页面,然后获得页面的源代码[10]。该算法将用于加载新闻列表页和新闻内容页。核心算法代码如下(C#):
(2)信息块采集算法:该算法接收三个参数:信息块代码、采集开始标志和采集结束标志;使用正则表达式技术进行信息匹配,以确定要采集的信息块。核心算法代码如下(C#):
(3)信息块过滤算法:该算法接收三个参数:信息块代码、过滤开始标志和过滤结束标志;使用正则表达式技术进行信息匹配,以确定要过滤的信息块[11]。
2.3 采集入口
在这里进行采集入口的设置,我们可以设置一个新闻网站的主页作为采集入口,调用页面采集算法提取新闻列表页路径代码。
2.4 新闻列表采集
从新闻列表页中采集新闻内容页的链接URL的工作有两个步骤。首先,删除无关信息,提取新闻列表信息块代码,然后从列表信息块代码中标识新闻内容页面地址,制定地址标准格式来修订和改善的新闻链接地址。
(1)获取新闻列表页代码
获取新闻列表页面代码,人工分析和识别页面代码,找到新闻列表信息块的起始标志和结束标志。调用采集算法,输入页面代码、信息块起始标志和结束标志,系统根据获得新闻列表信息块代码。
(2)新闻链接网址采集
对获取的信息块代码重新进行人工分析和识别,找到新闻链接信息的代码,标志起始和结束标记[12-13]。调用采集和过滤算法,输入信息块代码列表、新闻链接起始标志和结束标志,系统自动删除无关信息,准确读取新闻内容页链接URL列表。
2.5 新闻内容采集
(1)获取新闻内容页代码:调用采集算法从新闻链接URL列表中的各项找到新闻内容页,获取新闻内容页面代码。
(2)新闻信息采集:手动分析和识别页面代码,标记各新闻信息块的开始和结束标志,如标题、来源,内容,创建时间,调用信息采集和过滤算法,提取有关的新闻信息,然后保存到数据库或其他媒介中。
3 基于Web结构的新闻采集系统实现
3.1 应用程序概述
本文采用作者自主开发的“锐龙新闻采集系统”作为实现案例,“锐龙新闻采集系统”是新闻网站系统的一个子系统。该系统采用B/S模式,主要用于新闻发布网站的新闻信息采集工作,方便新闻稿件管理,大大提高新闻稿件编辑的效率和准确性,有很强的适用性和推广价值。
3.2 采集入口设置
通过友好的可视化界面进行采集入口地址的设置,界面如图1所示。本实例的采集入口设置如下:http://www.ruilongit.com/News_List.aspx?NT_ID=1。
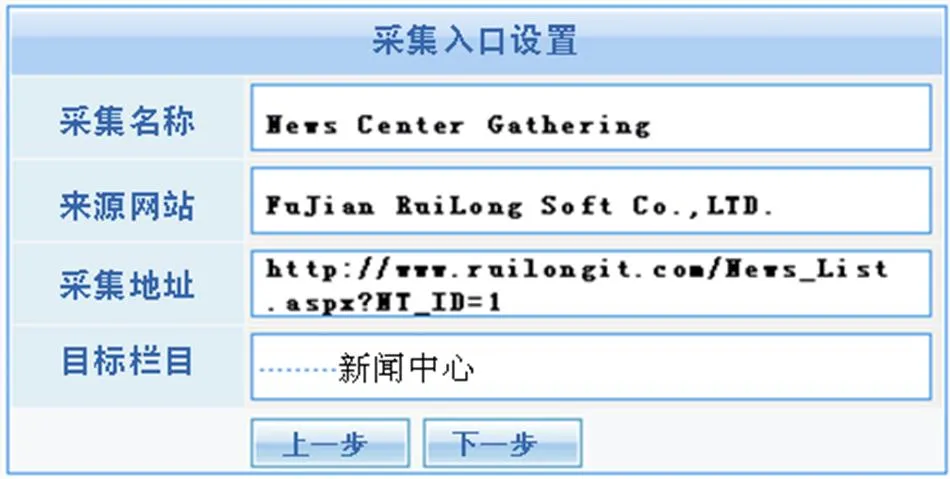
图1 采集入口设置
Fig.1 Acquisition entrances setting
3.3 新闻列表采集
(1)新闻列表页采集:分析和确定的新闻列表页中的代码,找到新闻列表信息块的开始和结束目标,提取新闻列表,作为新闻内容页链接网址的采集源。
新闻列表信息块的起始标志:
新闻列表信息块的结束标志:
(2)新闻内容页URL采集:通过链接地址采集算法进行分析和识别源代码,找到新闻内容页链接信息块的开始和结束标志,获取新闻内容页的URL列表。新闻内容页URL采集设置如图2所示。
新闻内容页链接信息块的起始标志: