基于SIFT算法的ATM视频人脸识别方法
2012-10-17陈春雨赵春晖
陈春雨,张 鑫,赵春晖
(哈尔滨工程大学 信息与通信工程学院,哈尔滨 150001)
0 引 言
随着银行业客户终端ATM自动提款机的不断推广使用,其安全防范工作越来越显重要,难度也越来越大。视频监控手段越来越受到广泛的关注,但是大多数监控手段都存在不同程度的缺点,主要表现在:①存取的大量视频信息没能得到及时的处理;②摄像机放置位置没有一个固定的标准,使得图像不便于处理。
因为ATM取款机视频人脸特征信息丰富,所以选用人脸识别方法作为监控方法。目前主要的人脸识别方法有以下4种:基于知识的人脸识别方法、基于特征的人脸识别方法、基于模板匹配的人脸识别方法、基于外观的人脸识别方法。其中基于知识的人脸识别方法是基于规则的方法,试图对人脸特征在直觉上建模,对先验知识依赖很大;基于特征的人脸识别方法包括人脸的器官的比例,灰度级和肤色的方法,该方法受光照、噪声要求较大;基于模板匹配的人脸识别方法通过人为定义模板进行人脸识别,该方法模板单一,模板不能随着外界环境的变化而变化;基于外观的方法是从图像中的样本学习,受样本影响大、计算繁琐[1]。
计算机人脸识别过程中,分为两个关键的技术,即人脸检测、人脸识别。针对ATM取款机视频的特点,选取尺度不变特征变换 (Scale-invariant feature transform,SIFT)算法[2]对人脸图像进行识别。该算法具有对缩放、旋转的不变性,同时还具有一定程度的仿射不变性。本文的人脸检测处理过程如下:①捕获视频,对视频进行处理成单帧图像;②对每幅图像运用肤色算法[3]进行肤色提取,计算肤色区域占整幅图像的比例;③取出肤色占图像比例最大的前100帧图像;④按照训练设定好的方法取出人脸特征信息丰富的10帧关键帧。
1 SIFT算法
SIFT特征不变匹配算法是David G.Lowe在2004年总结前人方法的基础上提出的一种在尺度空间中的局部不变特征匹配算法。
SIFT算法提取的特征向量具有如下特性:
1)SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
2)独特性好,信息量丰富,适用于海量特征数据库中进行快速、准确的匹配;
3)多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
4)高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
5)可扩展性,可以很方便的与其他形式的特征向量进行联合。
生成一幅图像SIFT特征向量分为4步:检测尺度空间极值点、确定关键点的参数、生成特征向量、匹配特征点。
1.1 建立尺度空间
尺度空间理论是检测不变特征的基础,有人通过不同的推导证明了高斯核是实现尺度变换的唯一变换核[4-5]。因此,尺度空间理论的主要思想是利用高斯核对原始图像进行尺度变换,获得图像多尺度下的尺度空间表示序列,对这些序列进行尺度空间特征提取。
均值为0,标准差为σ的二维高斯函数定义如下:
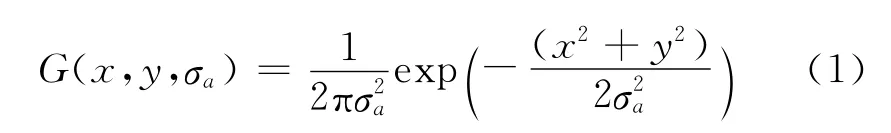
不同尺度下的尺度空间可以由图像与高斯函数进行卷积得到[6-7]:

I(x,y)为待处理图像,式 (1)中的标准差σa和尺度因子σ可以取相同大小的值。SIFT算法提出,在某一个尺度上对斑点的检测,可以通过相减2个相邻高斯尺度空间的图像,得到1个DoG (Difference of Gaussians)的响应值图像D(x,y,σ)[6],其中:

使用DoG对LoG (Laplacian-Gauss)近似带来的好处有3点:
1)DoG直接使用高斯卷积核,省去了生成卷积核的运算量;
2)DoG保留了各个高斯尺度空间的图像,这样,在生成某一空间尺度的特征时,可以直接采用式 (1)产生的尺度空间图像;
3)DoG对斑点进行检测稳定性更好,抗噪声的能力更强,也具有LoG相同的性质。
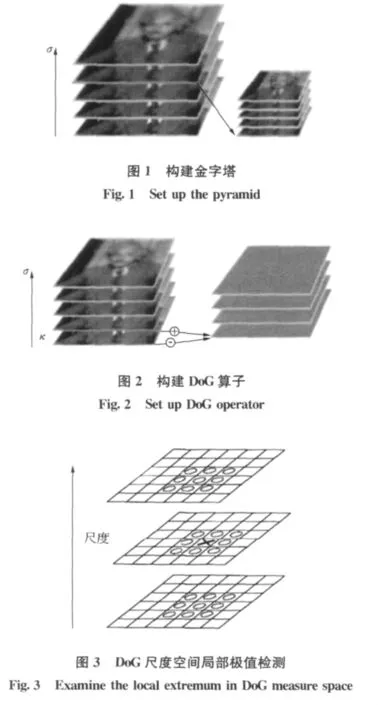
图像金字塔的构建:图像金字塔共O组,每组有S层,下一组的图像由上一组图像降采样得到[6]。图1由两组高斯尺度空间图像示例金字塔的构建,第二组是通过对第一组高斯尺度空间图像降2倍分辨率得到,意义与第一组相同。图2是DoG尺度空间构建的灰度图,是DoG算子的构建。
1.2 关键点的参数确定
通过同一组内各DoG相邻的层之间比较完成关键点的检测。为了寻找尺度空间的极值点,每个采样点都要与它周围所有的相邻点进行比较,如图3所示中间检测点要与它周围的8个点和上下相邻尺度对应的18个点共26个点进行比较。
因为DoG算子对图像中的边缘有比较强的响应值,为了得到稳定的特征点,一定要删除这些响应值。DoG响应峰值在横跨边缘的地方有较大的主曲率,在垂直边缘的方向有较小的主曲率。主曲率可以通过2×2的 Hessian矩阵H (x,y)求出:

式中D值可以通过求取临近点像元的差分得到。令α为最大特征值,β为最小特征值,可以通过H矩阵直接计算它们的和,通过H矩阵的行列式计算它们的乘积:
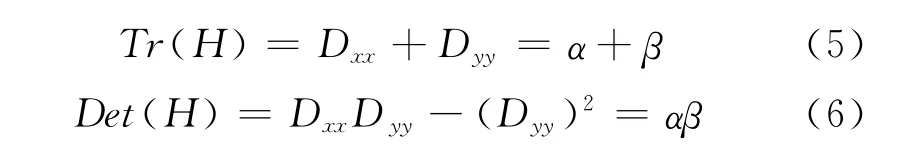
若γ为最大特征值与最小特征值的比值,则:
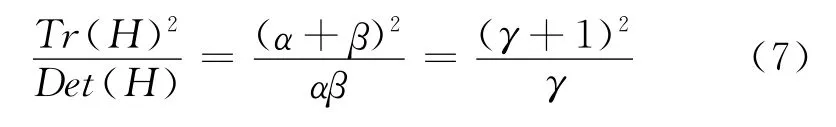
所以要想检查主曲率的比值小于某一阈值γ只要检查下式是否成立:
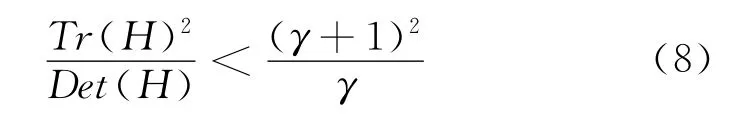
Lowe在论文[2]中给出γ=10。如果主曲率的比值>10的特征点被删除,否则保留。
1.3 生成特征向量
为了实现图像特征向量旋转的不变性,SIFT算法使用图像梯度的方法求该局部结构的稳定方向。对于已经检测到的特征点使用有限差分,计算以特征点为中心,以4.5σ为半径的区域内计算图像的梯度的幅角和幅值 (模值),计算公式如下:
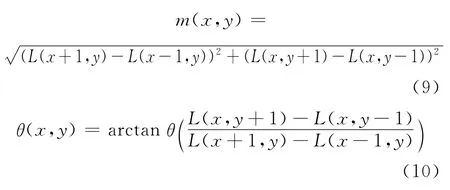
直方图统计出邻域像素的梯度方向和幅值。梯度直方图的纵轴是梯度方向角对应的梯度幅值累加值,横轴是梯度方向角。梯度方向直方图将0°~360°的范围分为36个柱,每10°为一个柱。直方图峰值代表该特征点处邻域内图像梯度的主方向,当存在另一个峰值相当于主峰值80%的能量时,则将这个方向规定是该特征点的辅助方向。辅助方向的设定可以增加鲁棒性。每个特征点有3个信息:位置、尺度、方向。
实际计算过程中,为了增强匹配的稳定性,对每个关键点使用4×4共16个种子点来描述,这样对于1个关键点就可以产生128个数据,即最终形成128维的SIFT特征向量,见图4。SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响[8]。
1.4 特征向量匹配
当两幅图像的SIFT特征向量生成后采用关键
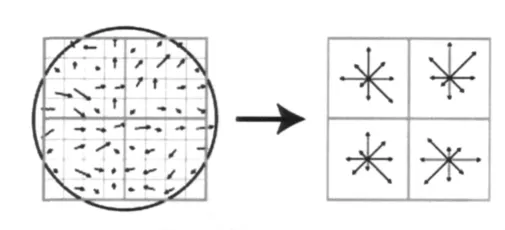
图4 特征向量生成Fig.4 Generate eigenvector
2 基于SIFT算法的ATM取款视频的算法流程
首先给出本文算法的实现流程图,见图5。
下面详细介绍本文算法流程:
1)视频输入:通过ATM取款机摄像头获取存在人取款视频;
2)视频处理:对视频进行处理,将视频分解成单帧图像,并对图像进行亮度补偿处理;
3)检测人脸:对每帧图像运用基于肤色的算法对人脸进行检测;
4)计算比例:计算所求人脸区域占整幅图像的比例x,将此比例值保存;
5)处理数据:对数据进行排序处理,取出前100帧人脸占图像比例最大的图像作为关键帧;
6)处理关键帧:按预先设定好的阈值选取10帧关键帧,对关键帧进行加权处理;
7)特征匹配:对所选取的10帧关键帧分别匹配处理;

图5 算法流程图Fig.5 Flow chat of the arithmetic
8)处理误匹配:运用随机抽样一致性RANSAC (Random Sample Consensus)迭代算法去除误匹配点,从而得到正确匹配点数N;
9)匹配加权:对消除完误匹配的关键帧按照大量样本训练好的阈值分别进行加权处理,如果正确匹配点数N与总匹配点数N总的比值R>0.5并且计算匹配点数N>45,则认为识别成功。
本文分别选取不同时间在不同地点取款的两个视频,录取格式是352×288的avi视频,帧速率为15帧/s。其中视频1为正常取款视频,视频2则为了说明算法的鲁棒性录制的具有不同表情的视频。
视频1在弱光下拍摄共548帧。表1是按照上述规则提取出的关键帧信息,表2是关键帧匹配信息。图6(a)是按照关键帧顺序的10幅初始图像匹配图,图6(b)是相应关键帧消除误匹配图。

表1 视频1关键帧信息Table 1 Message of key frame with video 1

表2 视频1关键帧匹配信息Table 2 Message of key frame matching with video 1

在关键帧提取中根据ATM取款机视频自身的特点,本文提出的算法相对传统的K-means关键帧提取算法克服了需要预先对N个数据对象设定任意K个初始聚类中心的缺点,同时也省去了多次迭代聚类的复杂算法。
依次选取人脸占整幅图像比例最大的5帧图像作为前5帧关键帧,将548帧图像掐去初始视频前100帧图像按求出比例值x从大到小排列,每5帧图像为一组,分别计算其对应的索引位置序号和比例值的方差和,求出与之和最小的5帧图像作为其余的5帧关键帧。归一化关键帧的比例值见表3。
根据训练经验分别对每帧关键帧以归一化比例值的第一非零位加权求和则有:
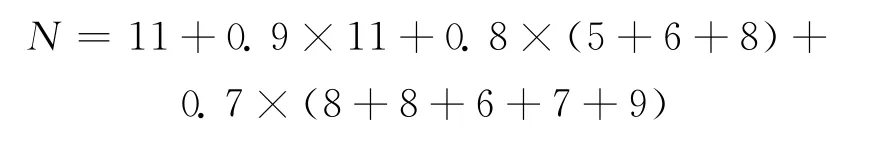
计算结果则有N=62.7,R=0.614 7>0.5且N>45;识别成功。
视频2在正常日光下拍摄并且为了满足实际需要拍摄视频时变换不同表情,下面给出视频2的详细匹配信息。视频2在正常日光下拍摄,图片格式为320×240,共613帧。表4是按照上述规则提取出的关键帧信息;表5是关键帧匹配信息;表6是归一化关键帧比例值。图7(a)是按照关键帧顺序的10幅初始图像匹配图,图7(b)是相应关键帧消除误匹配图。

表3 视频1归一化关键帧比例值Table 3 Normalized the proportion value of key frame with video 1

表4 视频2关键帧信息Table 4 Message of key frame with video 2

表5 视频2关键帧匹配信息Table 5 Message of key frame matching with video 2

根据训练经验分别对每帧关键帧以归一化比例值 (表6)的第一非零位加权求和则有:
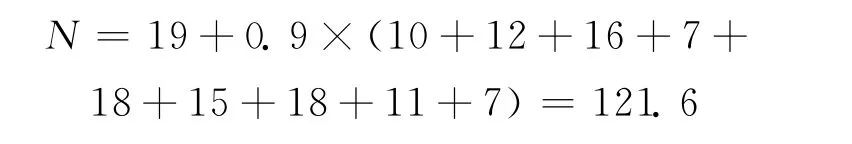
计算结果则有 N=121.6,R=0.643 4>0.5且N>45;识别成功。

表6 视频2归一化关键帧比例值Table 6 Normalized the proportion value of key frame with video 2
3 结 论
本文开发了基于SIFT算法的ATM取款机视频的人脸识别方法。它首先对采样到的视频进行分解,然后将分解出来的单帧图像进行人脸识别,计算出人脸在整幅图像的比例,最后通过计算得到的比例确定出关键帧匹配关键帧和标准人脸库图像,输出匹配结果。本实验克服了传统基于子空间人脸识别方法需要大量样本训练的缺点。
本实验以MATLAB为实验平台,在操作系统WIN7,处理器E7400,内存2.0GB的电脑上实验。通过大量视频训练、测试,根据上述训练阈值,在150个训练视频中,错误识别8个视频,识别正确率为94.5%,下面给出小部分测试样本结果 (表7、表8)。

表7 非目标识别Table 7 Identify the wrong object

表8 目标识别Table 8 Identify the object
本文为今后人脸识别系统在ATM取款机上应用提供了理论化的依据,进一步用硬件实现并缩短处理时间是今后研究的重点。
[1]赵丽红,刘纪红,徐心和.人脸检测方法综述 [J].计算机应用研究,2004,(9):1-4.
[2]David G Lowe.Distinctive image features from scale-invariant points [J].International Journal of Computer Vision,2004,60 (2):91-110.
[3]朱淑亮,王增才,王树梁,等.头部多角度的眼睛定位与状态分析 [J].重庆大学学报,2010,33 (11):20-26.
[4]Lindeberg J.Scale-space for discrete signals[J].IEEE Transactions PAMI,1980,207:187-217.
[5]Babaud J,Witkin A P,Baudin Metal.Uniqueness of the Gaussian kernel for scale-space filtering [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1996,8 (1):26-33.
[6]黄令允.基于自适应阈值的SIFT算法研究及应用[D].大连:大连理工大学,2011:13-15.
[7]王永明,王贵锦.图像局部不变行特征与描述 [M].北京:国防工业出版社,2010:79-88.
