Ant-Miner算法改进及在地震预测中的应用①
2012-10-16邵晓艳李玲玲胡欣茹
邵晓艳,刘 宁,李玲玲,胡欣茹
(郑州航空工业管理学院计算机科学与应用系,河南郑州 450015)
Ant-Miner算法改进及在地震预测中的应用①
邵晓艳,刘 宁,李玲玲,胡欣茹
(郑州航空工业管理学院计算机科学与应用系,河南郑州 450015)
首先阐述了Ant-Miner算法的原理,然后从不同角度对Ant-Miner算法进行研究分析,并针对该算法的不足之处提出了相应的改进和优化方案。最后将经过改进的Ant-Miner算法应用到地震预测中。结果证明优化后的Ant-Miner算法比传统C4.5分类算法能达到更好的效果。
蚁群算法;分类规则;地震预测
Abstract:The principle and realization of Ant-Miner algorithm are summarized firstly.Then the Ant-Miner algorithm is analyzed from different views,and an improving and optimizing method are proposed in order to overcome the problems existed in the algorithm.Finally,the improved Ant-Miner algorithm is used in earthquake prediction.The experiments show that,optimization algorithm can achieve better results than C4.5algorithm.
Key words:Ant colony algorithm;Classification rule;Earthquake prediction
0 引言
数据分类在数据挖掘中是一项非常重要的任务。基于蚁群算法的分类研究是一种新型的挖掘算法,该算法训练分类规则库的过程实质上也是从大的数据集中发现知识的过程。Parpinelli等人提出了最早的Ant-Miner系统[1],其后国内也有很多研究者对其进行了深入的研究[2-5]。
本文首先分析Ant-Miner算法的工作原理,然后针对Ant-Miner算法的不足之处进行改进,最后将该算法应用到地震预测中,以证明优化后的算法比传统C4.5分类算法能达到更好的效果。
1 基于蚁群算法的分类规则挖掘
求分类规则就是要求出IF<conditions>THEN<class>。其中规则的conditions部分的形式是:terml and term2and term3…..,每个term都是一个元组(attribute,operator,value)。
value是属性,attribute是值域中的某个值,operator是比较运算符;class部分则是预测满足该条规则conditions部分的记录所属的类别。
蚂蚁构造规则的过程分为三个阶段:第一个阶段是蚂蚁从一条空规则开始,重复选择属性节点到路径上,直到得到一条完整的路径,即一条分类规则;第二个阶段是进行剪枝,以解决过渡拟合问题;第三个阶段是进行信息素更新,对下一只蚂蚁施加影响。
1.1 路径选择策略
蚂蚁选择路径时依据两个因素,一是该term上与问题相关的启发函数值;二是与路径选择历史相关的信息素,即term以前被选择的越多,term上的信息素值越大。
如termij的形式为Ai=Vij。Ai是第i个属性,Vij是第i个属性的第j个值域,那么termij被选择加入当前的部分规则的概率由式(1)得到,每次都选择概率最大的term加入当前的部分规则:
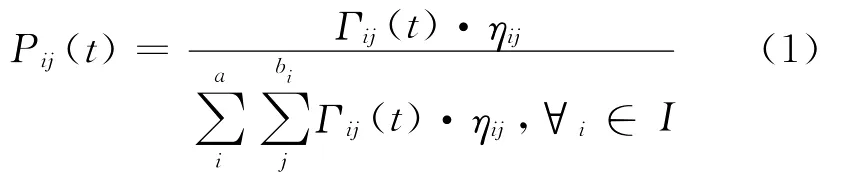
其中ηij是termij上与问题相关的启发函数值;Γij(t)是termij上的信息素(时刻t);α是属性数目;bi是属性i的值域个数;I是当前的蚂蚁所有未用过的属性集合。
(1)启发函数
式(1)中启发函数ηij的构造

其中,k是类的数目,a是分析对象中的属性个数;bi是对应属性i的值域个数。式(2)中infoTij的构造
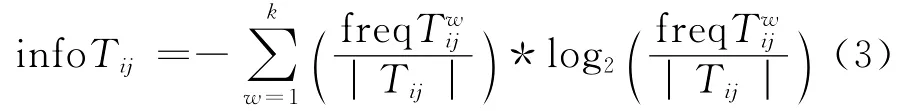
其中Tij是包含termij的记录的集合,也就是属性Ai的值为Vij的所有记录的集合;|Tij|是集合Tij包含的记录的数目;freqTij是集合Tij中所属类别为w的记录的数目。
从式中可以看到,每个termij的infoTij值自始自终都是定值,因此在初始规则构建时计算即可,不需要每次更新。还有特别要注意的是,如果Tij是一个空集合,也即不存在属性Ai的值为Vij的记录,那么此时应该尽量避免此termij(Ai=Vij)被选择加入规则。这里可以设infoTij的值为最大值,如设infoTij=log2(k),那么式(1)、(2)的值均为0,这就使termij成为最不可能被选中的term[1,5]。
(2)信息素
所有term的信息素都初始化为相同的值,式(1)中信息素的计算方法如下:
termij上的信息素初始化

其中a是挖掘对象中的属性个数;bi对应第i个属性的值域个数;t=0也即在t=0时刻信息素的值。
信息素的更新策略可以描述如下。每构造完一条规则后,需要修改所有term上的信息素,而下一个agent(ant)构造规则进行路径选择时依据的是本次修改过的新的信息素。修改信息素的过程包括两部分,即削减所有未在本次所构造规则中用到的term上的信息素,这步相当于蚁群中信息素的挥发;同时增加出现在规则中的term上的信息素。对两种情况的更新策略分别下:

其中,a是挖掘对象中的属性个数;bi是对应第i个属性的值域个数;Q是对所构造的规则优劣(quality)的一个衡量值,对规则所涉及到的所有term的信息素增加量与该规则的质量高低(quality)大小成正比。需要说明的是,这里假设时间t是离散的,以整数单位计算,t就表示t时刻,t+1即表示t的下一时刻。
1.2 规则构造与规则剪枝
规则的conditions部分构造完成后,接下来要构造规则的class部分,就是给满足规则conditions部分的对象定类名,完成规则的最初构建。为了尽量提高规则质量,并避免“过匹配”现象,还要对规则进行剪枝,去除一些冗余的term。这两步的完成要本着使规则的quality值达到最大的原则。
构造规则class部分的策略是:分别把所有的class赋给规则并计算规则的quality,最后确定使规则的quality达到最大值的class作为规则最终的class类标记。一条规则的quality的衡量标准如下:

其中,TruePos:被规则conditions部分覆盖,所属类与规则class相同的记录的数目;FalsePos:被规则conditions部分覆盖,所属类与规则class不同的记录的数目:FalseNeg:不被规则conditions部分覆盖,类别与规则class一致的记录的数目;TrueNeg:不被规则覆盖,类别也与规则class不同的记录的数目[3]。
对初步构造完成的规则进行剪枝的方法与其它分类分析方法类似:依次分别剪掉所有的term,分别计算剪掉之后规则的qualily,最终选择剪掉后使规则的quality提高最多的某个term进行剪枝,如此循环直到没有一个term剪掉后可以使规则的quality提高,则表示规则剪枝完成。
至此,Ant-Miner最终完成了一条规则的构造,然后进入下一次构造规则的过程。
1.3 训练集更新
当所有agent都各自构造规则完成后,有三部分工作要做:第一,选择一条最佳路径加入规则库,作为本轮构建规则所得的最终规则;第二,更新训练集,去除训练集中所有被该规则覆盖的记录,也就是用该规则进行分类预测,去除所有可以被规则正确分类的记录,然后把剩余的记录集作为下轮蚁群构造规则的初始训练集;第三,对该条规则所包含的term信息素进行更新,计算如式(6)所示。
2 算法优化
由Parpinelli等所提出来的这种Ant-Miner方法试验已经证明可以达到较好的分类效果。但是在信息素更新,路经选择方面还有不尽人意的地方。论文针对这些不足,提出了信息素更新策略的优化、规则库构建过程的优化以及该算法出现死锁问题的解决方案。
2.1 信息素更新策略的优化
Ant-Miner中信息素的更新是在agent每次创建完规则后完成的,对信息素的修改如式(5)和(6),其中式(6)是对在新构造的规则中出现的term信息素的修改方案,其中式中quality的计算如式(7)。这样做存在两个问题:
第一,一条规则构造完成后,不管规则的优劣(quality)如何,所有包含在规则中的term的信息素都会增长,那么这些term在以后构建规则时肯定更容易被选择。但是在实际应用中,如果当前构造的规则质量很差,就应该设法减少所有出现在规则里的term的信息素,以使下次构造规则时这些term不被选择才有道理。同时还会导致的一个问题是第一个agent构建规则时选择的term会被后来的ant重复选择,这样其它term被选择添加到规则中的概率极小,这就导致算法过早收敛,使规则的质量与ant的数目的关联不大。
第二,未知类别样本用构造好的规则库进行预测分类时,只要样本的各个属性符合规则的条件部分,就被划分为规则所预测的class。而那些不符合规则的条件部分的样本则继续搜索下一条规则,直到找到一条符合的规则为止。显然,被规则覆盖且确实属于规则所预测的类的样本所占的比率是最重要的,也是衡量规则质量的最重要的依据,而那些不被规则条件部分覆盖的样本数目其实是无关紧要的,所以我们在这里修改规则质量的衡量标准式(7)如式(7′),而修改式(6)如(6′):

式中Q1的计算方法:

式(6′)中,一个term被选择加入规则后并不一定信息素就会增加,这里限定了一个系数0.8,就是说规则的质量达到某个标准之后,该路径上所选择的tem的信息素才会增加;反之,如果所构造的规则质量很差,所选择的term上的信息素反而会减少,而且规则的质量越差,信息素减少的越多。
同时,式中用到的规则的衡量质量用式(7′)来计算,即被规则前项覆盖且被规则正确分类的记录的数目占所有被规则前项覆盖的记录数比率。这是因为一条规则构造完成后,能被规则的前项覆盖,并分类正确的准确率是最重要的.至于没有被规则前项覆盖的记录可以在后续挖掘中进行规则提取,以对其正确分类。所以这里强调了TruePos的作用。另外,式(6′)中,Q1-0.8的意义也就是用该规则进行分类正确率达到80%时才认为该规则是一条理想的可用规则,否则,削减出现在该规则里的所有term的信息素值。
修改后的算法一方面强调了规则质量,所构建规则的质量将决定规则中出现的term的信息素增加与否;另一方面也强调了能被规则condition部分覆盖并能被规则正确分类的样本百分比的重要性。这两部分优化都是合理有效的。
2.2 规则库构建过程优化
在Ant-Miner系统中,规则的构建主要分为三部分:根据信息素和启发函数值从高到低选择term添加到规则中构造规则的条件部分;选择一个可以使规则的质量达到最大值的类别作为规则的类标记;削减所有不包含在规则中的term上的信息素,并根据规则质量更新所有包含在规则早的term的信息素,以备下一次构造规则时作为路径选择历史信息使用,指导路径选择。
这样做会导致的一个问题是:term的信息素与各个类别之间没有直接关系。针对这个问题的改进分为两部分:
(1)信息素不再是全局的,每个类都对应一张信息素表来记录各个term与此类别的相关程度。
(2)每构造一条规则时不再从规则的条件部分,而是从结果部分开始。具体来说,一条规则的构造过程分为五步:
①从训练集中选择一个类别作为规则的后项。这步首先检验剩余样本数是否小于参数Max_Uncovered_Cases,如果小于,则规则提取完成,整个循环结束;否则,从样本库中选择一个包含样本数目最多的类作为当前要构造的规则的后项。
②根据该类别所对应的信息素表和启发函数值,不断选择term添加到规则的条件部分作为规则的前项。具体来说就是,检验该类对应的信息素表,按照式(1)计算各个termij被选择加入当前的规则的概率Pij。然后按照从大到小的概率依次添加到规则的条件部分,直到规则所覆盖的样本数小于Min_Cases_Per_Rule。
③用相似于第1.3节中所描述的方法对规则进行剪枝,依次剪掉规则中所有的term,并最终删除能使规则的准确度提高最多的term。但是,两种剪枝办法有个不同点:在第1.3节中,规则可以在剪枝过程中换类标记,只要令一个类标记可以使规则的质量提高,但是,这里不允许更改类标记,只限在当前类标记下能使规则提高的term,才会进行剪枝,以提高规则的质量。可以看出,更改后的剪枝办法与经典分类分析办法C4.5的剪枝策略类似。至此,一条规则构建完成。
④根据规则质量更新该类对应的信息素表。
⑤循环上边的过程直到所有agent都各自构造完规则,则选出一条最好的规则作为此次所有agent共同构造的虽好的规则,也相当于蚂蚁此次选择中所找到的最好路径。然后,修改规则所对应类标记的信息素表,并把被构造好的规则成功覆盖的样本从训练集中删除。
循环此构造过程直到训练集中的样本数小于参数Max_Uncovered_Cases,则整个规则库构造完成。
这样就解决了各个term上的信息素与各个具体的类标根本不相关的问题,某个termij因为构造了class1增长的信息素不会在构造下一条类标为class2的规则时,直接作用到class2上,这就解决了因为某个term与class1的关联比较大而默认为它与class2的关联也比较大的问题。
2.3 死锁问题及其解决方案
算法还有一个隐患就是可能会出现死锁。通过试验可以发现,如果有某几条记录属于同一类,而且它们对应的某几个特征属性的值比较一致,且与其他记录的值不同,如term:A1=V12,A3=V22,A4=V43,Class=classl,也就是说这几个term可能与它们共同的类标记class1具有极强的关联,这种情况下它们计算得到的启发函数值肯定会比较大,也就是说,它们更容易被选择加入下一条要构造的规则,期望的规则形式应该为
If A1=V12and A3=V22and A4=V43,then Class=classl
但是,如果这几条记录的条数本身就不能达到Min_Cases_Per_Rule,它们就不能被选出来构建规则,那么就会出现一直选出几个term,但是却总是不能构造规则的局面,算法陷入死循环,而无法继续构造规则。
本文采用逐步降低termij上的信息素的方法,以增加其他term被选择的概率,使规则构建的过程跳过这2条记录。即如果算法中出现这种情况,则降低term上的信息素,以避免这种“死锁”:
(1)在添加term时,规则所覆盖的记录数目小于Min_Cases_Per_Rule;
(2)出现情况"l"时,规则仍然为空。
这种情况下降低当前被选中的term的信息素,也就降低了下次选择时它们被选择的概率,算法可能转而选择别的term添加到规则的conditions中,有效地解决了“死锁”问题。
3 地震试验及性能分析
3.1 数据背景
本实验所选数据资料取自中国地震局编辑的“中国历史强震目录”、“中国近代地震目录”和全球强震记录。
全球强震主要分布在环太平洋地震带和欧亚地震带。根据全球的强震活动与板块边界的分布以及丁国瑜院士对中国及其邻近地区的活动边界的划分,我们将全球分为16个强震活动区,这些区域都分布在环太平洋地震带和欧亚地震带。
本文取1925-2003年的全球强震资料数据作为Ant-Miner算法的检验。选1925-1993年问的69个样本作为训练集,然后选1994-2003年间的10年作为检验样本。所选数据的每一行的前16项分别是这16个强震区域在一年中的M≥7.0的地震次数Ni/10,当Ni≥10时,取值为1;第17列是次年我国大陆是否发生7级以上强震的记录,如果次年中国大陆发生地震,则取值为1,否则为0。
3.2 地震数据处理
数据预处理过程如下:
(1)离散化数据
由于数据的1~16列每列的值域都分布在0~1之间,如果直接用蚁群算法处理就会使训练过于分散而影响训练效果,这里先对数据集进行分段处理:
IF dataset(i,j)==0.0THEN,
dataset(i,j)=0;
ELSEIF dataset(i,j)>=0.1AND dataset(i,j)<=0.2THEN,
dataset(i,j)=1;
ELSEIF dataset(i,j)>=0.3AND dataset(i,j)<=0.4THEN,
dataset(i,j)=2;
ELSEIF dataset(i,j)>=0.5THEN,
dataset(i,j)=3;
ENDIF
(2)添加噪声
这里,在数据集中加入了一行[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,2]作为干扰样本,设Max_Uncovered_Cases为1,Min_Cases_Per_Rule为2。
3.3 预报结果
这里列出了蚁群算法训练的规则库处理的分类结果并把它与C4.5算法进行比较。
部分规则:
[6,0,3,0,10,0,5,0,2,0,1,0,4,0,14,0,13,0,0]
[5,0,1,0,6,0,4,0,14,0,2,0,1]
[2,0,10,0,5,0,14,0,4,0,0]
[11,0,13,0,12,0,1]
[12,0,3,0,0]
[4,0,9,0,10,0,11,0,13,0,14,0,0]
其含义是,规则的2*m-1(m=1,2,…)位表示属性的位数,规则的2*m位表示第2*m-1个属性的取值,规则的最后一位表示若数据对象对应项的值分别与规则中表示的相同时,规则应该划分到的类。

表1 Ant-miner算法在地震预测上与C4.5算法的比较
表1表示了算法在地震数据上进行分类挖掘,建立规则库,并在训练样本上预测时与C4.5算法的结果比较。
由表1中可以看出,Ant-Miner与C4.5算法相比,预测准确率显然比C4.5算法要高,C4.5算法在这里的预测结果并不理想,而Ant-Miner算法则达到了较为满意的结果。同时,在大数据量计算中规则条数已经成为越来越引人注意的问题,因为太多的规则条数也会制约预测判断的速度。这里Ant-Miner算法的规则条数比C4.5也有很大优势。
4 小结
论文首先分析了Ant-Miner算法的工作原理,然后针对Ant-Miner算法存在的不足,提出了合理的改进方案。最后将经过优化的Ant-Miner算法应用到地震预测中,实验证明优化后的Ant-Miner算法比传统C4.5分类算法能达到更好的效果。
[1] Rafael S Parpinelli,Heitor S Lopes,Alex A Freitas.Data Mining With an Ant Colony Optimization Algorithm[J].IEEE transactions on evolutionary computing,2004,6(4):481-494.
[2] 朱庆保,杨志军.基于变异和动态信息素更新的蚁群优化算法[J].软件学报,2004,(2):185-192.
[3] 吴斌,史忠植.一种基于蚁群算法的TSP问题分段求解算法[J].计算机学报,2001,24(12):1328-1333.
[4] 吴庆洪,张纪会,徐心和.具有变异特征的蚁群算法[J].计算机研究与发展,1999,36(10):1240-1245.
[5] Rafael S Parpinelli,Heitor S Lopes,CEFET-PR,et al.An Ant Colony Algorithm for Classification Rule Discovery[M].Idea Group Publishing,2002.
[6] Dorigo M,Maniezzo V,Colorni A.The Ant system:optimization by a colony of Cooperating agents[J].IEEE Transactions on Systems,Man,and Cybernetics,l996,26(1):28-41.
[7] 平建军,冯向东,杨立明.地震影响空间危险度及危险区预测方法研究[J].西北地震学报,2010,32(2):162-168.
[8] 刘小凤,梅秀苹,冯建刚.青藏高原北部地区地震基本活动状态定量评价[J].西北地震学报,2011,33(2):130-136.
[9] 师旭超,郭志涛,韩阳.基于支持向量机的砂土液化预测分析[J].西北地震学报,2009,31(4):363-366.
Earthquake Prediction Using Improved Ant-Miner Algorithm
SHAO Xiao-yan,LIU Ning,LI Ling-ling,HU Xin-ru
(Department of Computer Science and Application,Zhengzhou Institute of Aeronautic Industry Management,Henan 450015,China)
P315.72
A
1000-0844(2012)03-0215-05
10.3969/j.issn.1000-0844.2012.03.0215
2011-07-11
教育部新世纪优秀人才支持计划(2009);河南省重点科技攻关计划项目(112102210024);河南省重点科技攻关计划项目(112102310082);2012年河南省科技发展计划122400450333
邵晓艳(1977-),女(汉族),河南西平人,讲师,研究方向:数据挖掘,地理信息系统.
