风力机叶片的图像跟踪与识别算法研究
2012-10-11沈继忱刘志杰邸建铭赵世荣
沈继忱,刘志杰,邸建铭,赵世荣
(东北电力大学自动化工程学院,吉林吉林132012)
0 引言
随着风力发电的大规模建设,风力发电表现出了面广、点多的特点。因此,随着风力发电系统并网技术不断深入,必须加强风力机叶片的跟踪与识别,以使风力机能够安全可靠运行,保证电网系统稳定并在出现故障时快速恢复稳定的供电能力[1]。
传统模式识别技术一般包括模板匹配法[2-5]、统计特征法等。在20世纪90年代前期,随着计算机视觉技术的快速发展,开始出现目标识别的系统化研究。1990年A.S.Johnson等运用图像处理方法实现了目标的自动识别。1990年R.A.Lotufo等使用视觉识别技术分析所获取的图像,实现了目标的跟踪[6]。这个时期应用在识别正确率方面有所突破,但还没有考虑到识别实时性的要求,识别的速度有待进一步提高。1994年M.M.M.FAHMY等成功地运用了BAM神经网络方法对目标进行自动识别。由于神经网络技术能够较好对处理和解决问题进行记忆、联想、推理,避免了繁重的数据分析和数学建模工作,大大提高了运行速度,因此越来越受到人们的广泛关注,但其没能力来解释自己的推理过程和推理依据、不能向用户提出必要的询问、理论和学习等缺点,制约着其发展。对此,本文利用Adaboost识别算法对风力机叶片进行了跟踪与识别的研究。
1 Adaboost跟踪与识别的原理
AdaBoost算法是在整个训练集上维护一个分布权值向量wt,用赋予权值的训练集通过弱分类算法产生简单分类器hi(x),然后计算出其错误率,用得到的错误率去更新分布权值向量wt,错误分类的样本赋予更大的权值,正确分类的样本分配更小的权值。每次更新后用相同的简单分类器产生新的分类假设,这些分类假设的序列构成多分类器。对这些多分类器用加权的方法进行联合,最后得到决策结果。AdaBoost算法的任务就是完成将容易找到的识别率不高的简单分类器提升为识别率很高的强分类器,在分类时,只要找到一个比随机猜测略好的简单分类器,就可以将其提升为强分类器,而不必直接去找通常情况下很难获得的强分类器,也就是给定一个简单分类算法和训练集,在训练集的不同子集上,多次调用简单分类器,最终按加权方式联合多次简单分类器的预测结果得到最终学习结果。
在Adaboost算法中,每一个训练样本都被赋予一个权值,表明它被某个简单分类器选入训练集的概率。如果某个样本点己经被准确地分类,那么在构造下一个训练集的过程中,它被选入的概率就被降低;相反,如果某个样本点没有被正确分类,那么它的权值就得到提高。在具体实现上,最初令每个样本的权值相等,对于第t次迭代操作,根据这些权值来选取样本点,进而训练分类器ht。利用这个分类器,提高被它错分的那些样本点的权值,降低被正确分类的样本权值,然后权值更新过的样本集被用来分类下一个分类器ht+1,整个训练过程如此进行下去[7],算法的示意图如图1所示。

图1 AdaBoost算法框架
1.1 AdaBoost算法框架[8]
设给出的样本图像集为(x1,y1),…,(xn,yn),yi={0,1}(i=1,2,…,n)对应负样本和正样本。对于第i个训练样本xi,其特征值为fi(xi)。yi=0时时;其中m表示负样本图像个数;l表示正样本图像的个数。重复以下过程T次,t=1,…,T。

2)选取具有最小的错误率的εt,并将其对应的弱分类器作为ht。
4)求得强分类器:

由上所述可以得出,如果每一次筛选出来特征ht+1的错误为εt+1≤0.5,否则下一次筛选出来的特征必为 ht,又得出 ε ≤1。因为t+1wt+1,i←wt+1,iβt+1,如果得到的被 ht+1分类的样本是正确的,那么所有的权值都变会变小。相反,被错误分类的样本权值都会变大,原因在于 w′t+1,i←对于新的 h一定是相对于t+2ht+1能更多地正确分类出弱分类器,因为所有分类器h的错误率ε只由错误分类的样本的权值来决定,所以,只有这样才能达到减小错误率的效果。
1.2 Adaboost训练耗时原因
在样本的训练过程中,样本数量非常多,因此需要的时间和空间比较大。对于每个样本特征值在每一轮循环中都要进行计算,此外,还要加上每轮循环运算中选择最佳阈值时必须进行的排序、遍历等运算时间,使得在训练过程中消耗大量的时间。
对于每个特征j,训练出其简单分类器hj的过程比较耗时,因为该过程中需要确定阈值θj,偏置pj,并使目标函数达到最小,从确定的简单分类器中,找出一个具有最小的错误εt的简单分类器ht。对于每个简单分类器都有上万个训练样本,而训练一个简单分类器需要对这些样本进行分析并确定阈值θj和偏置pj。提取完最优简单分类器后,训练样本的概率分布已经改变,那么下一次进行训练简单分类器时,所有的简单分类器必须完全重新训练,如此反复。
1.3 Adaboost训练的优化
针对训练样本耗时的缺点,本文提出了一种训练简单分类器快速训练算法,可以有效地避免迭代训练以及统计概率分布耗时的过程[9]。
若训练样本分别用(x1,y1),…,(xn,yn)表示,一共有n个。yi=0,1分别表示样本的负样本和正样本。设在训练样本中负样本有m个,正例样本l个。
计算特征fj的简单分类器hj时,同时计算出阈值偏置pj和θj。有前面的分析可知,简单分类器εj与 θj和 pj为函数关系,即 εj(θj,pj)。pj可分为 ± 1两种情况进行讨论。
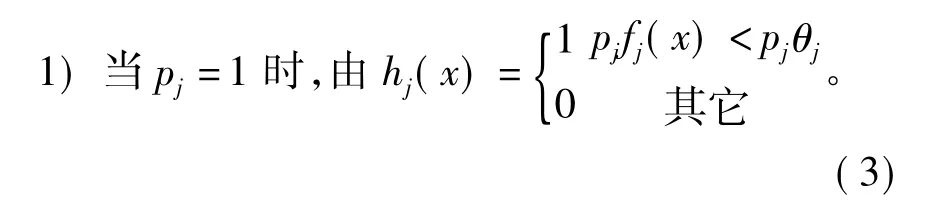
特征fj的值小于阈值θj时为真,则
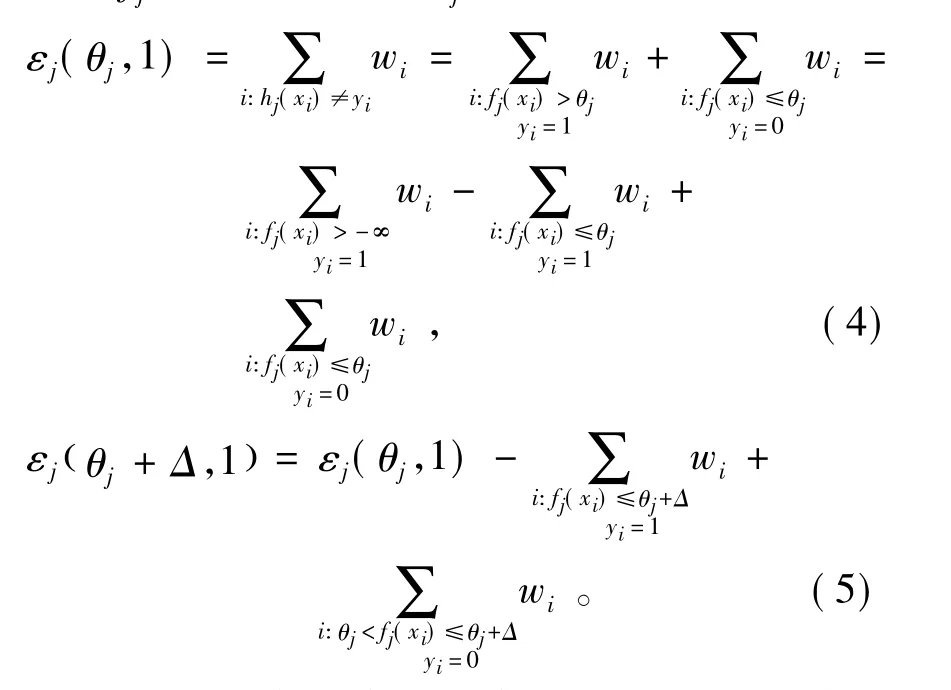
把所有的训练的特征样本fi按照从小到大的顺序进行排列,得到一个次序表S。最小的样本特征fi的值的序号用S(1)来表示,用fj(x(s(1)))来表示其相应的特征所得到的值,假设其所得的值就是该值的阈值,有:

特征fi的值次小的训练样本x(S(2)),根据式(5)得出:

由式(5)知,y(S(2))=1时,δ= -1;y(S(2))=0时,δ=1;可知:
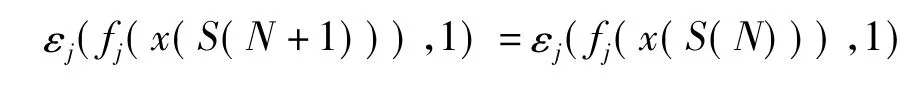

根据式(8),可以得出各个不同阈值下的εj(θ,1),最后筛选出最小的 εjmin(θ,1)。此刻 θ值定义为 θ1,有 θ1= θj|εj=εjmin(θ,1)的值就是对应特征 j分类器的最优阈值。
2) 当 pj= -1 时,可求得 εj(θ,1),εj(θ,1)的值和pj=1时互补,有 εj(θ,-1)=1-εj(θ,1),也就是 εjmin(θ,-1)=1 - εjmax(θ,1)。
由此可知,只要利用式(8)累加一次,再比较εjmin(θ,1)与1 - εjmax(θ,1),就能确定简单分类器的最优阈值、偏置和εj。

2 实验结果及分析
2.1 Adaboost算法训练过程
本实验在OpenCV平台上,对Adaboost原程序和改进后的算法进行了分类器的训练[10-11],在实验中共用到1 000幅40×40的叶片样本和不包含建筑物、大树、蓝天等图片中截取而来的1 000幅40×40非叶片样本,原算法和改进后的算法的训练样本数目、训练时间如表1所示。
在检测速度上,取大小为596×486图像50幅作统计,原算法的平均检测时间为1.426 s,改进后的平均检测时间为0.685 s。

表1 Adaboost算法训练结果
2.2 检测实例及结果
本实例对单个叶片和多个叶片进行了检测,图2是对单个叶片的检测结果,图3为多叶片检测结果,图4是在有干扰的情况下进行的检测。

图2 单个叶片的检测结果

从测试的结果来看,对于单个叶片的检测(图2)准确性相当好,对叶片的中心定位也相当准确。但存在的最大缺点就是算法复杂度太高,检测处理时间太长。在多个叶片存在的情况下也能准确的检测出来(见图3)。但是在图像模糊或有树木及其它情况下未能检测出来(见图4)。
由于本文在训练分类器时采集的样本不够多,可能造成检测的失败和漏检,要增加精确程度,还需要进一步增加样本的数目。
3 结束语
通过对Adaboost弱分类器中目标函数的直接求解,避免了统计和迭代训练长耗时过程,提高了训练和分类的速度,同时,利用少量的弱分类器构成的强分类器,较好地简化了系统结构,减少了训练时间,提高了检测速度,实现了对风力机叶片的实时跟踪与识别。另外,通过图像分析检测叶片运行状态,可以及时做出准确的操作,避免风机叶片损害。
[1]吴越明.发电机组对电网稳定的适应能力分析[J].华东电力,2004,32(10):646 -648.
[2]王哲峰.基于提升小波变换的图像匹配算法研究[D].吉林:吉林大学,2006:19-26.
[3]刘雅轩,苏秀琴,王萍.一种基于局部投影熵的图像匹配新算法[J].光子学报,2004,33(1):105-107.
[4]薛娇.基于改进遗传算法的图像匹配方法研究[D].太原:太原理工大学,2011:25-29.
[5]郑军,诸静.基于自适应遗传算法的图像匹配[J].浙江大学学报(工学版),2003,37(6):689 -692.
[6]王晗.基于Adaboost算法的车牌识别研究[D].太原:太原理工大学,2011:25 -29.
[7]严超,苏光大.人脸特征的定位与提取[J].中国图像图形学,1998,3(5):375 -380.
[8]李苏.基于Adaboost算法的人脸检测技术研究[D].哈尔滨:哈尔滨理工大学,2010:21-23.
[9]魏冬生,李林青.Adaboost人脸检测方法的改进[J].计算机应用,2006,26(3):619 -621.
[10]蒙丰博.快速人脸检测与跟踪[D].天津:天津大学,2010:32-36.
[11]秦小文,温志芳,乔维维.基于OpenCV的图像处理[J].电子测试,2011,7:39 -41.
